







本文为对https://github.com/baoguangsheng/fast-detect-gpt/tree/main代码仓库中数据集生成py文件的阅读理解
代码的主要作用是通过输入的模型和数据集名称先从huggingface上下载数据集和模型,然后调用huggingface上对应模型生成文本,形成1:1的人类文本:AIGC文本的数据,为后续模型的评测做准备
在sh文件中可以观察到使用xsum, squad, writing三个数据集,并且使用gpt2-xl opt-2.7b gpt-neo-2.7B gpt-j-6B gpt-neox-20b五种模型生成,最终得到15个json文件,对文件使用json.load方法就可以读取到一个字典,其中有两个键:“original”,“sampled”两个键分别对应一个长度为500的列表,其中每一个元素是一个字符串,original对应人类文本,sampled对应AI生成文本
数据效果如图所示
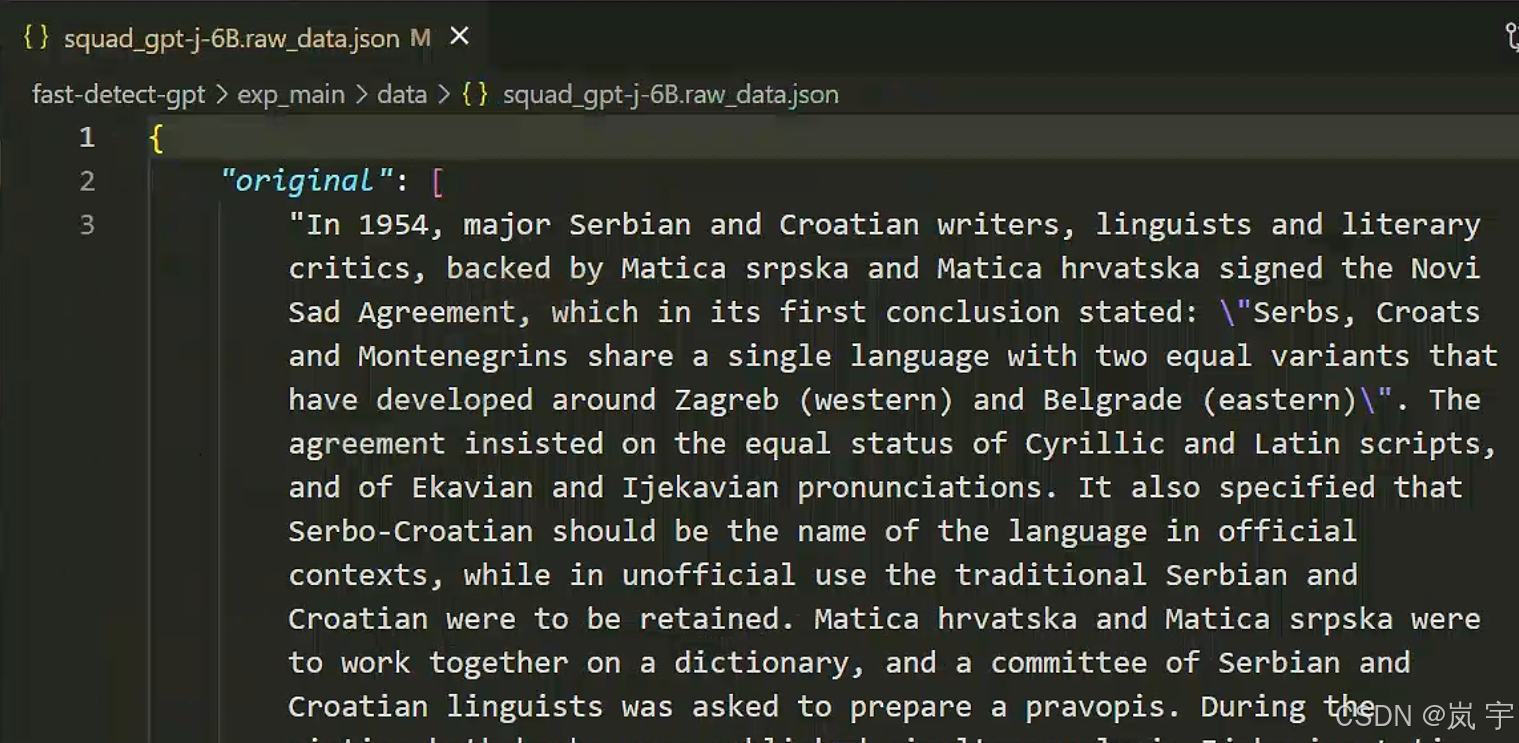
main.sh文件中对data_builder.py文件的调用
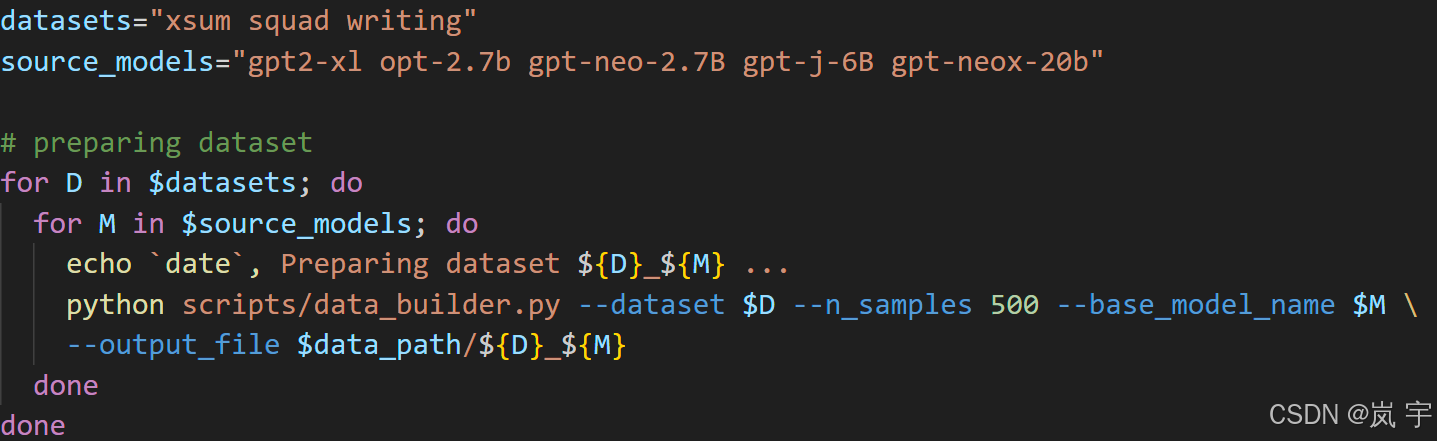
datasets和source_models排列组合得到最终15个json文件,最终的结果保存在fast-detect-gpt/exp_main/data文件夹内,对文件使用json.load方法就可以读取到一个字典,其中有两个键:“original”,“sampled”两个键分别对应一个长度为500的列表,其中每一个元素是一个字符串,original对应人类文本,sampled对应AI生成文本
代码分析
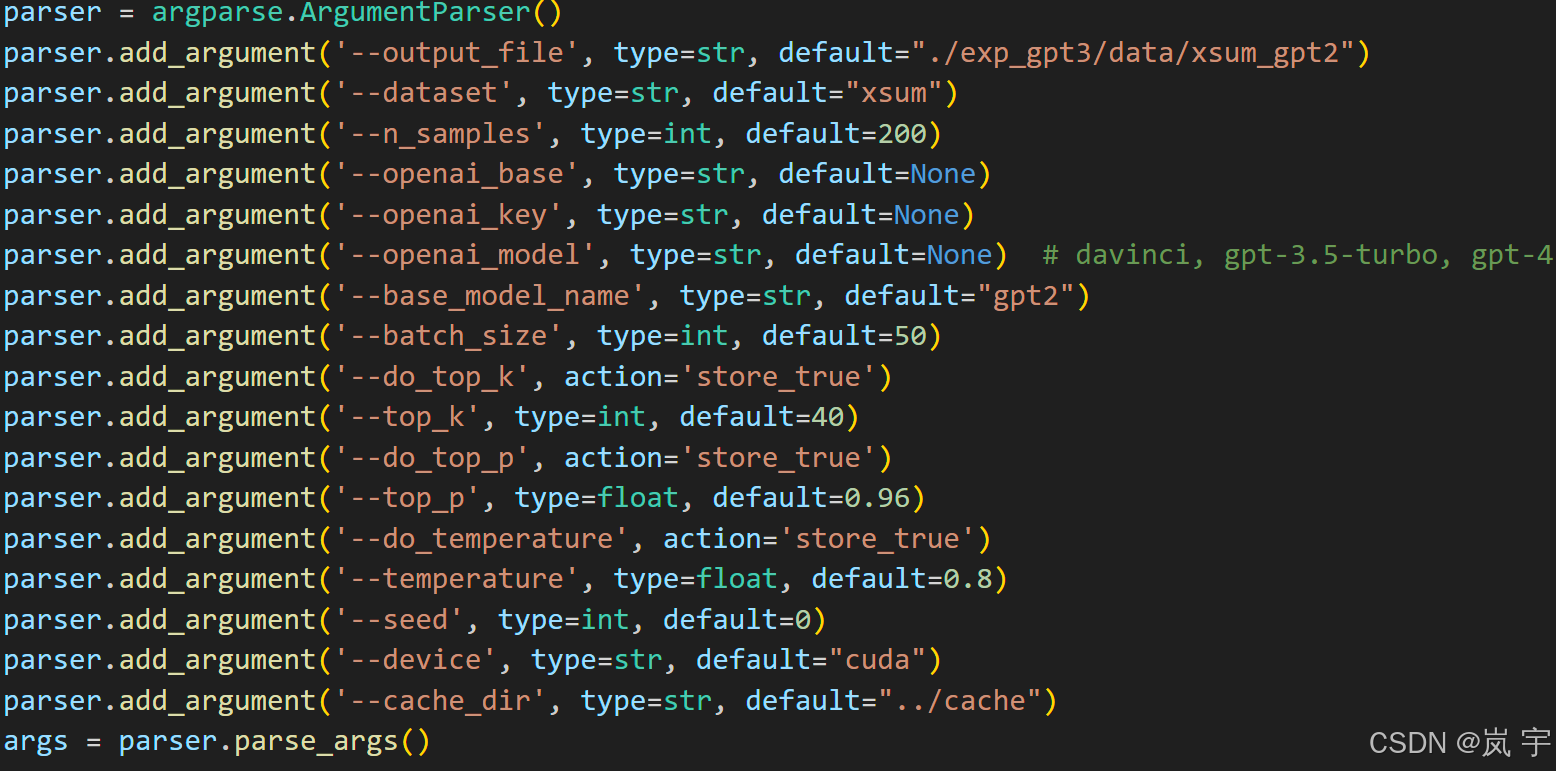
使用argparse模块,在运行代码的指令中可指定输入参数:
python data_builder.py --dataset xsum
可指定内容,在代码内可通过args.dataset参数来访问,其中action='store_ture’参数效果为:在运行py文件时有指定便为True,default=False

通过os指定下载文件存放位置并创建文件夹

为了保证实验结果的稳定性,设置seed

调用两个函数,首先使用模型生成数据,然后保存数据,下面就分别介绍这两个函数
generate_data:
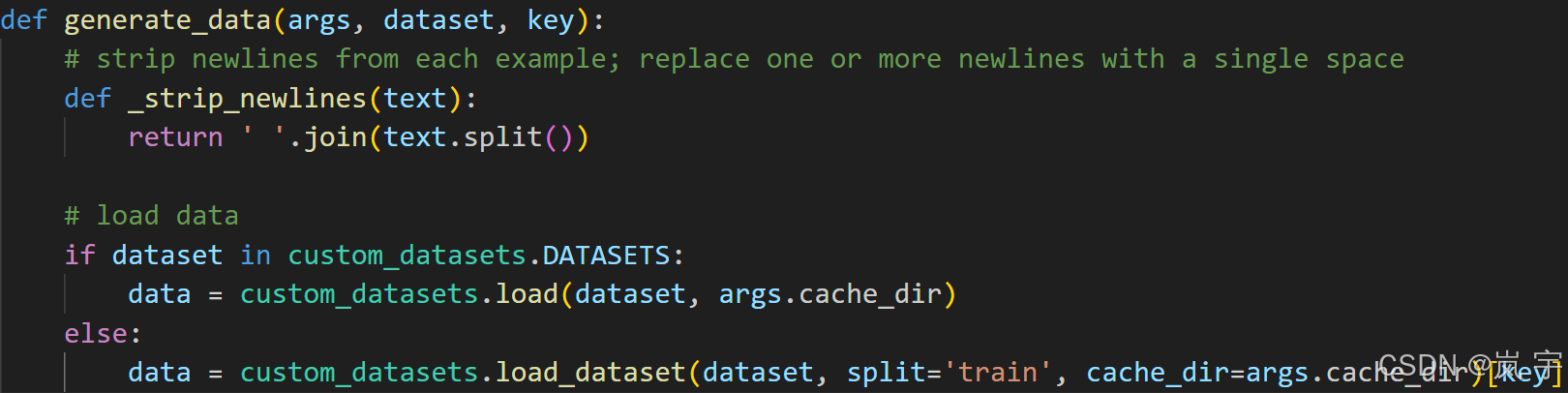
首先调用另一文件中的load_dataset方法

而另一文件中也就是如果文件已存在就从磁盘读取,否则调用dataset库中的load_dataset方法来下载数据

将读取到的data先转化成字典的key再转化回列表,可以除去其中重复的值。
使用strip方法删除字符串首尾的空格

通过将字符串分割再连接的方法可以将其中的多余空格除去

如果是在这三个数据集中,则筛选其中较长的数据,随机打乱排序并且取前5000条

创建DataBuilder实例并且加载分词器tokenizer,通过args.base_model_name的值调用:
from_pretrained(AutoTokenizer, model_fullname, optional_tok_kwargs, cache_dir=cache_dir)
在data中只保留通过tokenizer进行分词之后token数小于512的数据

进入generate_samples函数,取data的前n_samples条数据(sh文件中设置为500,batch_size设置默认为50)
generate_samples

设置名字为data的字典,包含两个键:“original”,“sampled”对应两个空列表
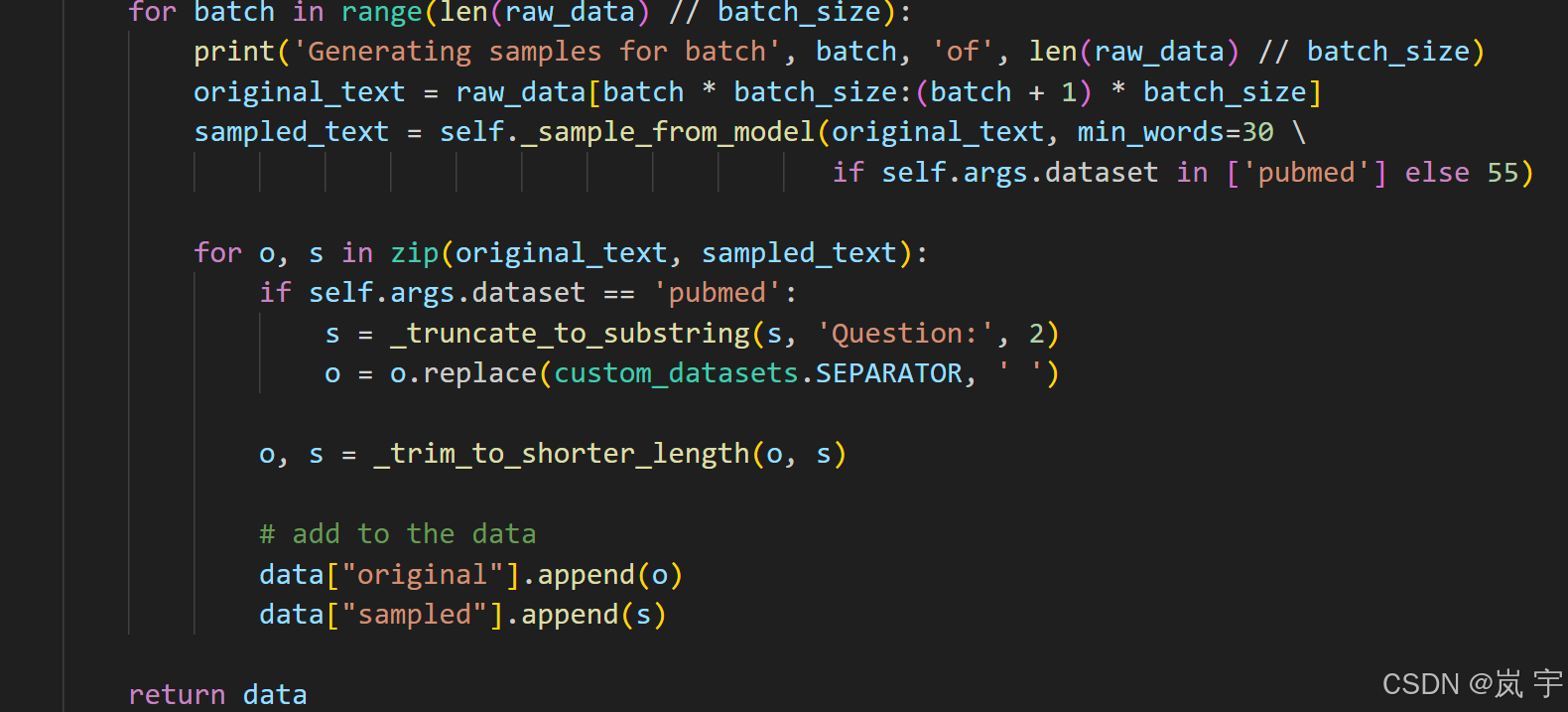
进行:数据量//批次大小=处理次数 次循环,每次取一个批次大小的数据然后调用_sample_from_model方法得到由模型生成的数据
_sample_from_model

对输入数据使用分词器并且进行裁切,保留前prompt_tokens30个token用来作为模型提示词
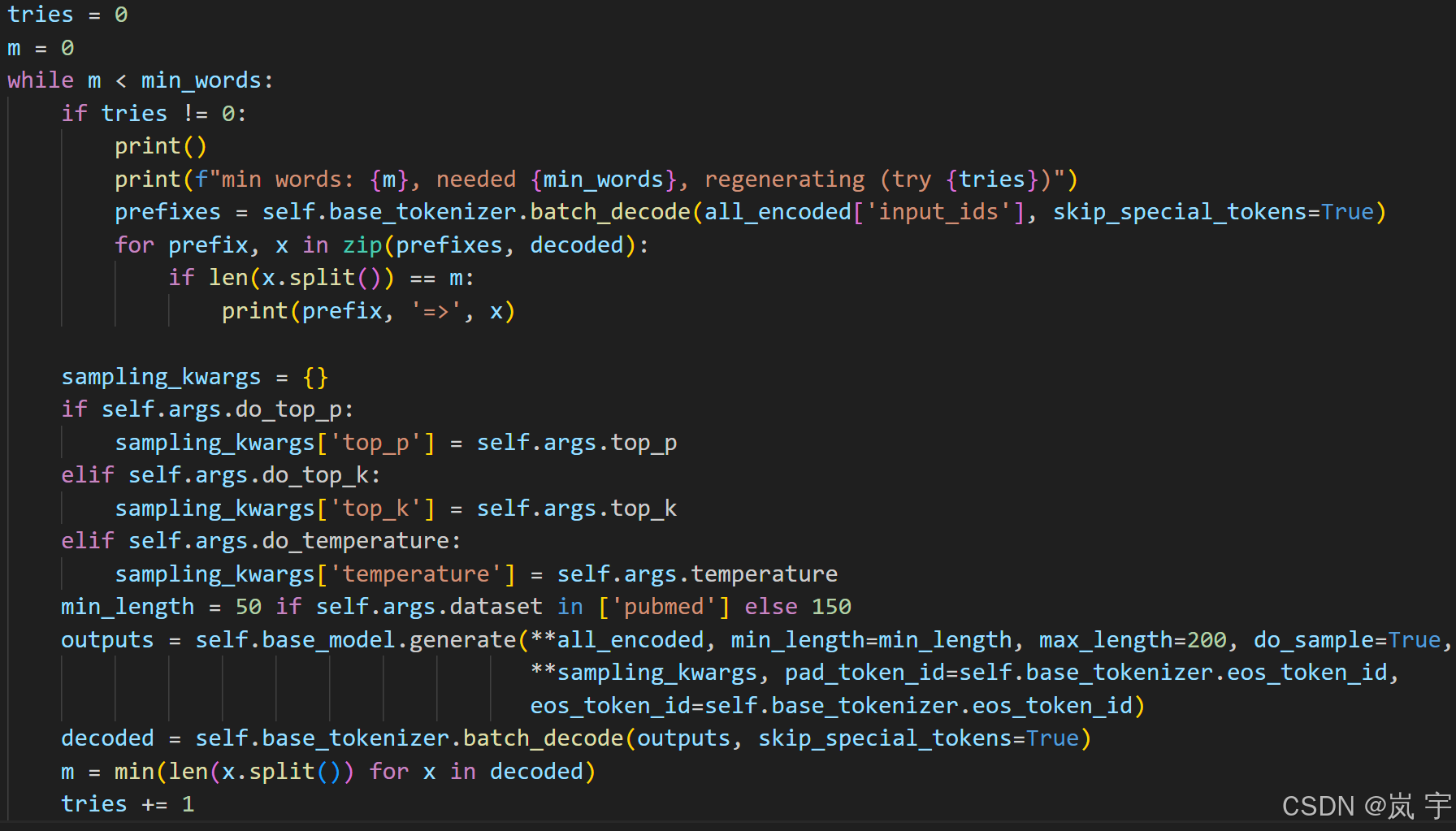
不断使用模型生成,最后返回decoded字段
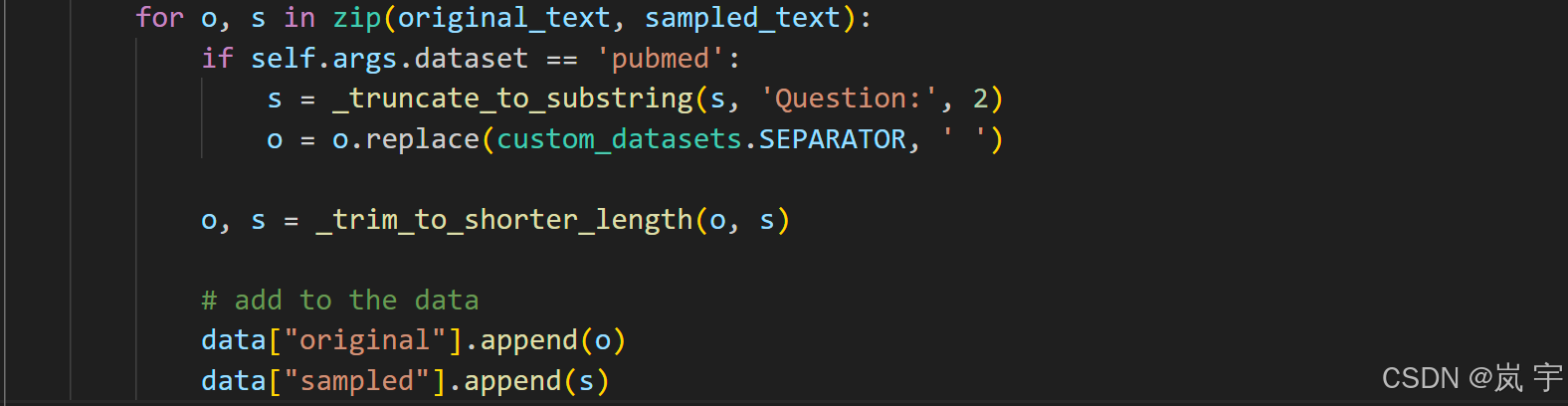
这样我们就得到了sampled_text的内容,后面调用_trim_to_shorter_length方法将里面的字符串裁切,保留成为与最短的一个字符串长度相同的部分
最后在data字典中"original","sampled"两个键对应的空列表中添加这些数据
save_data
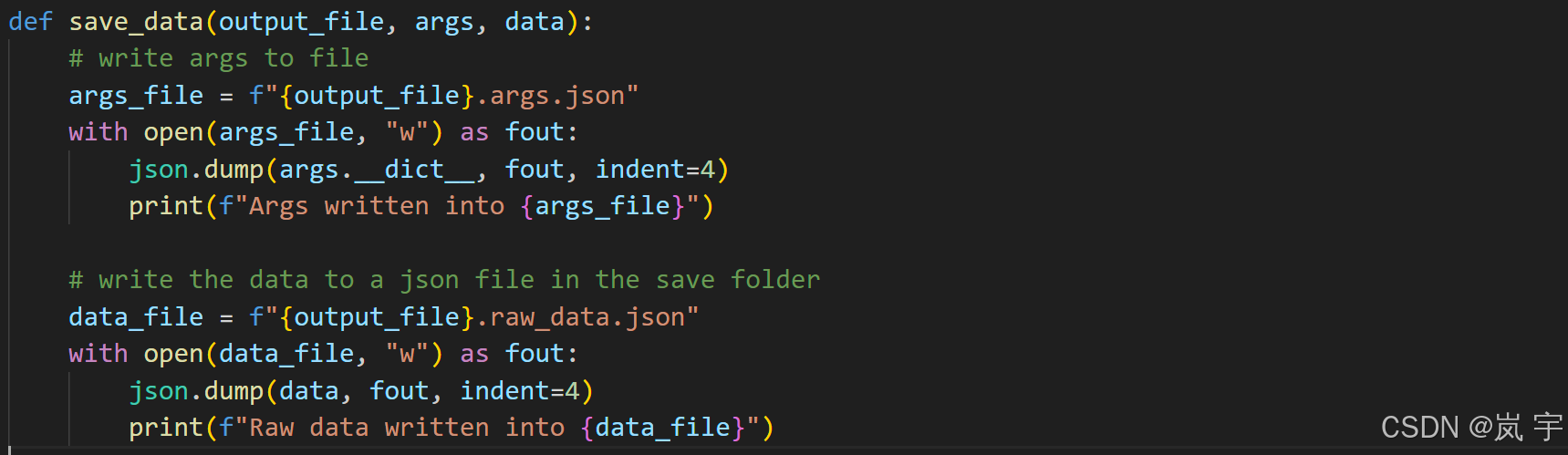
json.dump(data, fout, indent=4):使用 json.dump() 函数将 data(一个 Python 数据结构,通常是字典、列表等)转换成 JSON 格式,并写入到 fout(即上面打开的文件)。indent=4 使得输出的 JSON 数据格式化,每个嵌套层级缩进 4 个空格。
后续数据使用:
对文件使用json.load方法就可以读取到一个字典,其中有两个键:“original”,“sampled”两个键分别对应一个长度为500的列表,其中每一个元素是一个字符串,original对应人类文本,sampled对应AI生成文本

















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









