







 DenseNet结合ResNet和Inception优点,通过稠密连接最大化信息流动,优化梯度消失问题。它采用特征融合方式concat,减少模型参数,使用Bottleneck层提升计算效率,同时采用dropout防止过拟合。
DenseNet结合ResNet和Inception优点,通过稠密连接最大化信息流动,优化梯度消失问题。它采用特征融合方式concat,减少模型参数,使用Bottleneck层提升计算效率,同时采用dropout防止过拟合。
代码地址:Pytorch版本DenseNet
论文
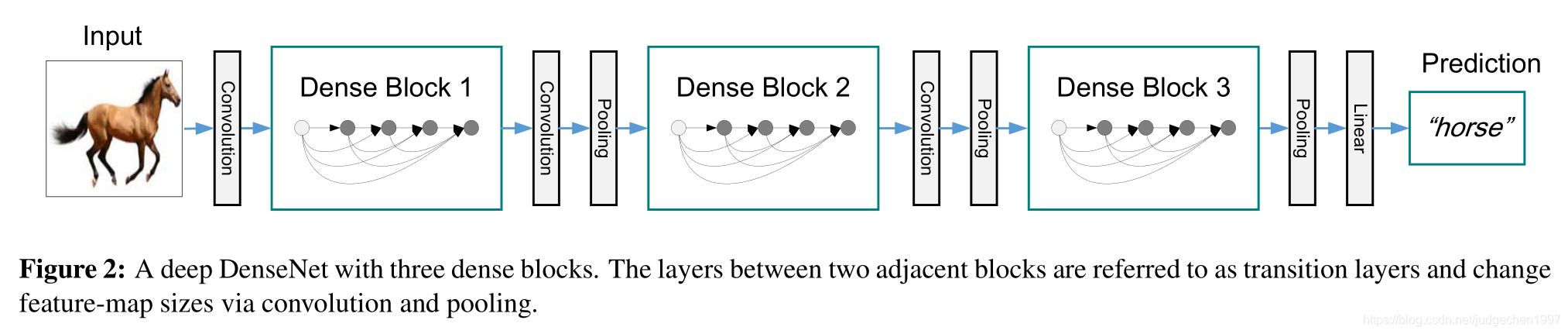
DenseNet可以说是结合了ResNet和Inception结构的优点,建立了稠密的连接,最大化信息流动,进一步优化了梯度消失的问题
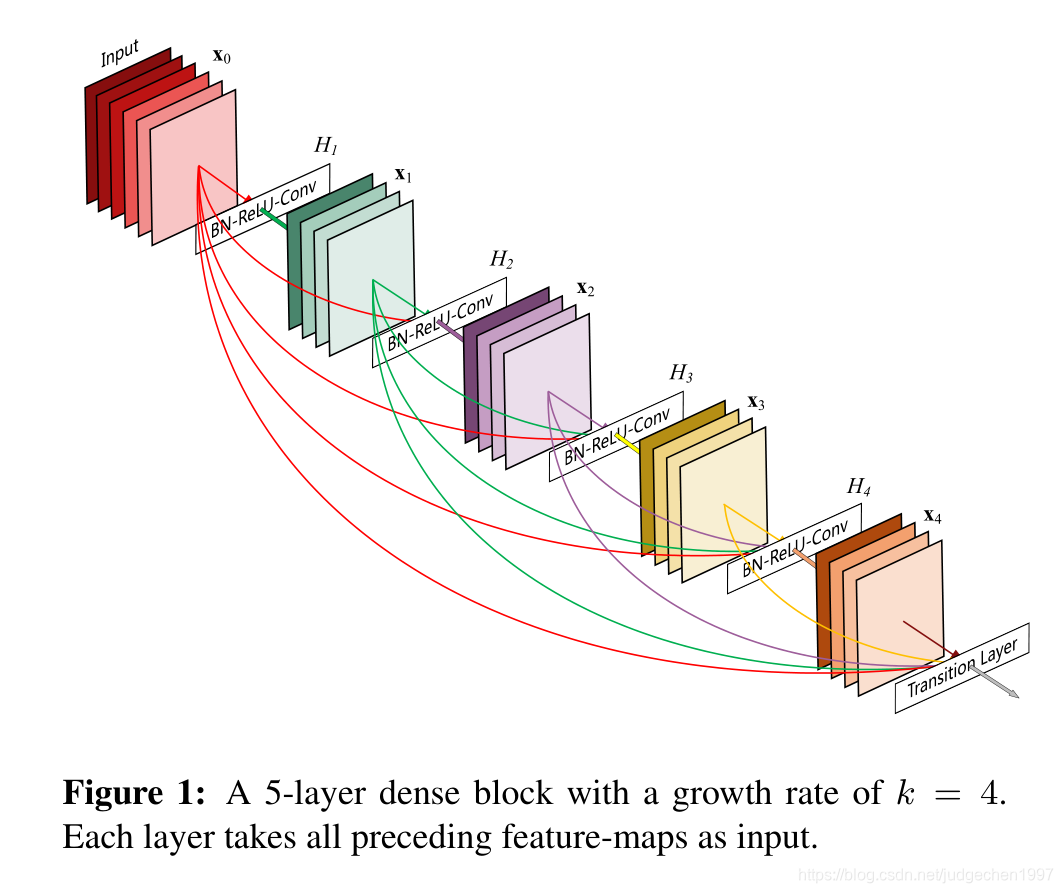
densenet论文中,认为resnet帮助解决了梯度消失问题,梯度消失有一部分原因确实是网络过深:传播经过的层数越多,梯度越容易消失,而shortcut的结构使得梯度传播跳过了一层。但是相加后,信息无法继续传递了

densenet保证层与层之间最大化的信息流动,只是通道融合feature,梯度可以流向更前的层。
特征融合的方式是concat

代码中,也是先将feature append进来,然后在dim=1 torch.cat
(N,C,W,H) dim=1 对应 channels堆叠
这种稠密的连接方式,有一个反直觉的影响是:减少了模型参数,因为不需要反复学习那些冗余的feature map:

本文用k来表示输出feature的channels数量,相比于ResNet,channels少了很多。虽然输出channels比较少,但是输入由于有很多feature,而且在末级会累积前面很多级的feature,大概有
k
0
+
k
×
(
l
−
1
)
k_0+k\times(l-1)
k0+k×(l−1)个,所以会使用Bottleneck layers层减少输入数量,提升计算效率


稠密连接实在太多,本文还使用了dropout随机去掉一些连接,防止过拟合
缺点
个人感觉,DenseNet应用受限的一大原因是内存占用恐怖,毕竟层之间相互融合交流传递的idea虽好,但是在bp时,某个节点需要缓存后面很多级网络的梯度参数,才能计算该参数的梯度。所以他虽然比ResNet有着更少的参数,但是内存占用反而非常严重。
代码
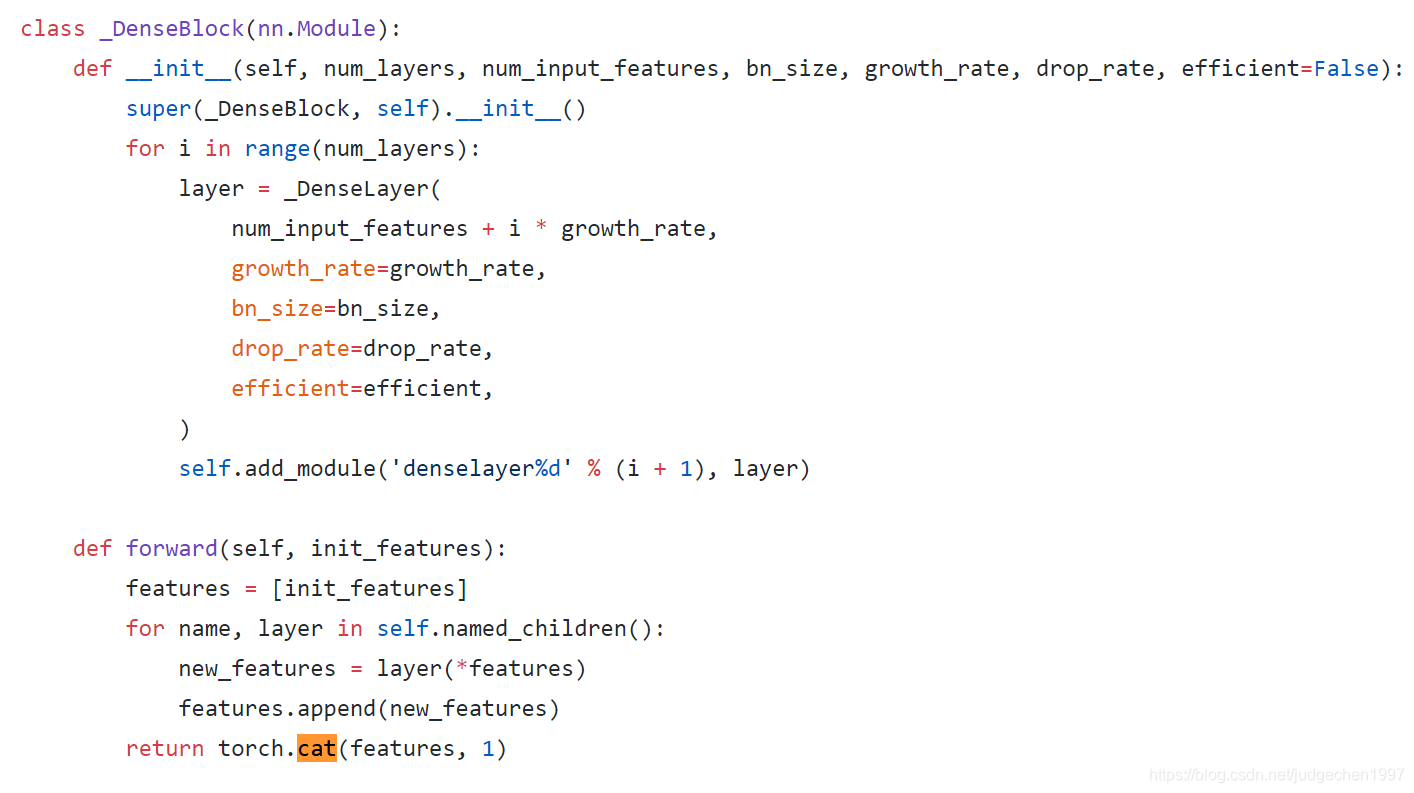
可以看到,核心的DenseBlock模块,使用一个列表feature,来保存之前所有的feature,这些feature会在每一层,也就是_DenseLayer()函数中的一开始_bn_function_factory中进行融合,再进行后续操作。DenseBlock的最后,也是返回一个在dim=1融合后的feature,然后经过transition layers,降低feature size,然后进入到下一个block


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









