






ResNet所使用的方法真的很大胆。我们知道,在神经网络当中,随着迭代次数越来越多,当我们大量使用Sigmoid,或者tanh函数的时候,由于两端的梯度几乎接近为0,这就使得梯度下降变得失效。(导函数小于1,叠加多次相乘梯度几乎为0)对此,很多人又提出了momentem,ReLu等方法。
根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。目前针对这种现象已经有了解决的方法:对输入数据和中间层的数据进行归一化操作(BatchNorm),这种方法可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再往深处走的时候,这种方法就无用武之地了。为了让更深的网络也能训练出好的效果,何凯明大神提出了一个新的网络结构——ResNet。
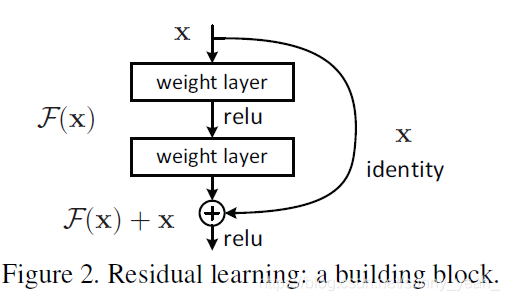
H(x) = F(x)+x,这里H(x)就是观测值,x就是估计值(也就是上一层ResNet输出的特征映射),残差:观测值与估计值之间的差。我们一般称x为identity Function,它是一个跳跃连接;称F(x)为ResNet Function。
如果是采用一般的卷积神经网络的化,原先咱们要求解的是H(x) = F(x)这个值对不?那么,我们现在假设,在我的网络达到某一个深度的时候,咱们的网络已经达到最优状态了,也就是说,此时的错误率是最低的时候,再往下加深网络的化就会出现退化问题(错误率上升的问题)。咱们现在要更新下一层网络的权值就会变得很麻烦,权值得是一个让下一层网络同样也是最优状态才行。对吧?
但是采用残差网络就能很好的解决这个问题。还是假设当前网络的深度能够使得错误率最低,如果继续增加咱们的ResNet,为了保证下一层的网络状态仍然是最优状态,咱们只需要把令F(x)=0就好啦!因为x是当前输出的最优解,为了让它成为下一层的最优解也就是希望咱们的输出H(x)=x的话,是不是只要让F(x)=0就行了?
当然上面提到的只是理想情况,咱们在真实测试的时候x肯定是很难达到最优的,但是总会有那么一个时刻它能够无限接近最优解。采用ResNet的话,也只用小小的更新F(x)部分的权重值就行啦!不用像一般的卷积层一样大动干戈!
特点:
1.超深的网络结构(超过1000层)。
2.提出residual(残差结构)模块。
3.使用Batch Normalization 加速训练(丢弃dropout)。
两种不同的residual
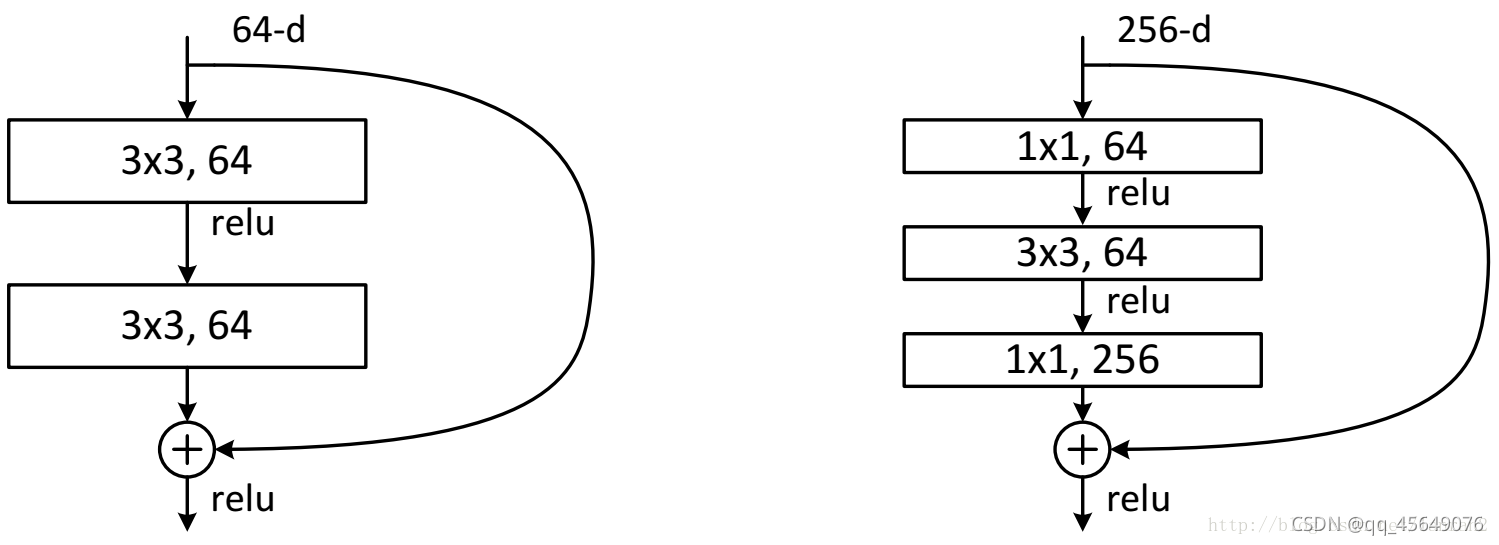
1.左侧残差结构称为 BasicBlock
2.右侧残差结构称为 Bottleneck(减少参数个数,深层次网络选这个)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









