







摘要:得益于GPU的快速计算,DNN在大量计算机视觉任务中取得了最先进的结果。但算法要落地就要求其能在低功耗的设备上也可以运行,即DNN的运行速度要更快,并且占用内存更少。这是我读的关于二值网络的第一篇文章,中心思路是在DNN的训练阶段用1bit的二值权重代替浮点数权重,可以将硬件的乘法操作简化为累加操作,可以大量节省存储空间,同时提高运行速度。
介绍
当前CNN网络主要的运算集中在实数权值乘以实数激活值或者实数权值乘以实数梯度。论文提出BinaryConnect将用于前向传播和后向传播计算的实数权值二值化为 ( − 1 , 1 ) (-1,1) (−1,1), 从而将这些乘法运算变为加减运算。这样即压缩了网络模型大小,又加快了速度。论文提到,SGD通过平均权重带来的梯度来得到一些小的带噪声的步长,尝试更新权重去搜索参数空间,因此这些梯度非常重要,要有足够的分辨率,sgd至少需要6—8bits的精度。如果对权重进行量化,就会导致无法对权重直接求导,所以我们可以把二值化权重看成是带噪声的权重。论文认为,带噪声的权重往往能够带来正则化,使得泛化能力更好,类似Dropout,DropCconnect这种就是对激活值或者权重加入了噪声,它们表明只要权重的期望值是高精度的,添加噪声往往是有益处的,所以对权重进行量化理论角度是可行的。
这篇论文的贡献如下:
- 尽管模型在测试集上的精度(指的是用二值weight测试)降低了非常多,但是训练效果却不比全精度的网络差,有时候二值网络的训练效果甚至会超越全精度网络,因为二值化过程给神经网络带来了noise,像Dropout一样,反而是一种regularization,可以部分避免网络的overfitting。
- 二值化网络可以把单精度乘法变成位操作,这大大地减少了训练过程中的运算复杂度。这种位运算可以写成gpu kernel, 或者用fpga实现,会给神经网络训练速度带来提升。
- 存储神经网络模型主要是存储weights. 二值化的weight只要一个bit就可以存下来了,相比之前的32bit,模型减小了32倍,那么把训练好的模型放在移动设备,比如手机上面做测试就比较容易了。
方法
这一节开始详细的介绍BinaryConnect,考虑选择哪两个值,如何离散化,如何训练以及如何进行推理。
+1 or -1
DNN主要由卷积和矩阵乘法组成。因此,DNN的关键运算是乘加操作。BinaryConnect在传播期间将权重限制为+1或-1。 因此,许多乘加操作被简单的加法(和减法)所取代。 这是一个巨大的收益,因为定点加法器在内存和功耗方面比定点乘法累加器少得多。
确定式二值化和随机式二值化
二值化将float类型权重转换为两个值,一个非常简单直接的二值化操作基于符号函数:
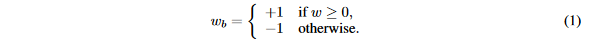
其中
w
b
w_b
wb是二值化权重,
w
w
w是实值权重。这是一个确定式的二值化操作,另外一种方案是随机二值化,即以一定的概率更新值:
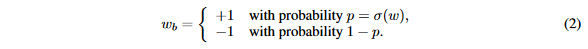
其中
σ
(
x
)
=
c
l
i
p
(
x
+
1
2
,
0
,
1
)
=
m
a
x
(
0
,
m
i
n
(
1
,
x
+
1
2
)
)
\sigma(x)=clip(\frac{x+1}{2},0,1)=max(0,min(1,\frac{x+1}{2}))
σ(x)=clip(2x+1,0,1)=max(0,min(1,2x+1))
第二种方法比第一种方法更合理,但在实现时,每次生成随机数会非常耗时,所以一般使用第一种方法。
参数传播与更新
考虑使用SGD进行反向传播的更新。在这些步骤的每一步(前向传播,反向传播,参数更新) 中是否仍然行得通。
BinaryConnect的一个关键是,我们只在前向和反向传播期间对权重进行二值化,而不是在参数更新期间进行二值化,如算法Algorithm1所示。在更新期间保持良好的精度的权重对SGD是必不可少的。原因如下:
- 梯度值的量级很小。
- 梯度具有累加效果,即梯度都带有一定的噪声,而噪声一般认为是服从正太分布的,所以多次累加梯度才能把噪声平均消耗掉。
另一方面,二值化相当于给权重和激活值添加了噪声,而这样的噪声具有正则化的作用,可以防止模型过拟合。

Clipping
由于权重量化只取决于符号,浮点权重大于正负1对结果没影响,为了限制浮点权重不会增长太大以及提高正则性,使用clip函数将浮点权重限制在[-1,1]。
其他训练技巧
这篇论文使用了BN层,不仅可以加速训练,还因为它减少了权重缩放的整体影响。使用ADAM算法优化。
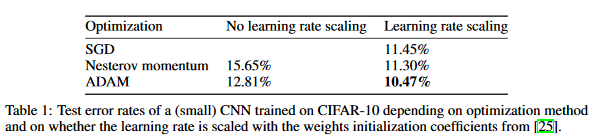
测试推理阶段
如何前向推理,大致可以分为以下几种方法:
- 使用二值化weight。
- 使用浮点数weight。
- 从浮点权重和随机二值化可以采样出很多二值网络,将它们的预测输出平均一下作为输出。
这篇论文使用了第3种方法,训练过程中用随机二值权重,测试时用浮点权重可以提升性能,证明了论文前面认为的带噪声的权重具有一定的正则性。在MNIST/CIFAR10/SVHN上的实验说明了这点:

总结
总结一下,这篇论文提出将浮点权重量化到1bit,提出了完整的量化权重训练/测试流程,并且从带噪声权重的角度来解释了量化权重。但这种方法还有一个缺点,即并没有对激活函数进行量化,所以后面BNN出现了,请看下节。
附录
- 论文原文:https://papers.nips.cc/paper/5647-binaryconnect-training-deep-neural-networks-with-binary-weights-during-propagations.pdf
- 代码:https://github.com/MatthieuCourbariaux/BinaryConnect
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
















 3408
3408











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









