







部分主流优化函数讲解(SGD,AdaGrad,RMSProp,Adam)
参考自(https://blog.csdn.net/weixin_42398658/article/details/84525917)
之所以出现了这么多的优化函数就是因为病态曲率的存在,也就是梯度下降容易进入鞍点。
这样的话我们就很容易想到牛顿法了,一阶导数指出的是运动方向的问题,二阶导数指出的就是加速度的问题。但是由于牛顿法会用到黑塞矩阵和二阶导数,计算量太大了,所以实际工程中一般不会用。
随机梯度下降( Stochastic Gradient Descent,SGD )
随机梯度下降法:
给定数据集X = \ left \ {x ^ 1,x ^ 2,…,x ^ n \ right },数据集标记为:Y = \ left \ {y ^ 1,y ^ 2,…,y ^ n \ right },学习器为F(X; W)的,学习率α

下面是具体的学习率调节策略:通常ķ的取值和训练次数有关,如果训练次数为上百次,则ķ要大于100,而b的值可以粗略的设置为百分之一的初始学习率,学习率初始值一般作为超参数进行设置,一般采取尝试策略。
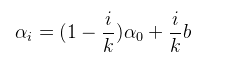
SGD算法在训练过程中很有可能选择被标记错误的标记数据,或者与正常数据差异很大的数据进行训练,那么使用此数据求得梯度就会有很大的偏差,因此SGD在训练过程中会出现很强的随机现象。如何解决呢?
可以多选择几个数据在一起求梯度和,然求均值,这样做的好处是即使有某条数据存在严重缺陷,也会因为多条数据的中和而降低其错误程度。
动量学习法

AdaGrad(自适应梯度算法)

从上式可以看出,AdaGrad使的参数在累积的梯度较小时(\ theta <1)就会放大学习率,使网络训练更加快速。在梯度的累积量较大时(\ theta> 1)就会缩小学习率,延缓网络的训练,简单的来说,网络刚开始时学习率很大,当走完一段距离后小心翼翼,这正是我们需要的。但是这里存在一个致命的问题就是AdaGrad容易受到过去梯度的影响,陷入“过去“无法自拔,因为梯度很容易就会累积到一个很大的值,此时学习率就会被降低的很厉害,因此AdaGrad很容易过分的降低学习率率使其提前停止,怎么解决这个问题呢?RMSProp算法可以很好的解决该问题。
RMSProp(均方根支柱)

Adam(自适应动量优化)

这里有一个问题就是开始时梯度会很小,R和v经常会接近0,因此我们需要初始给他一个?合适的值,这个值怎么给才合适呢先看下面的公式:
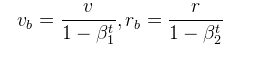















 1236
1236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









