







1.outstanding,out-of-order,interleaving
outstanding:前一笔数据发送完之前就能发送别的地址的能力(针对ddr的bank interleaving)
out-of-order:回来的数据和发送的命令可以顺序不一样(针对读操作,效率提升同样是针对ddr)
interleaving:不同命令之间回来的数据可以相互交叉(针对读操作)
2.关于id的使用
一些基本的点:
outstanding可以通过id相同的方式来处理,out-of-order需要id不同;
一个transaction可以有多个transfer,transaction的不同transfer可以是相同的id,也可以是不同的id,但是transfer内部的数据一定是相同的id;一个master内部如果支持多线程,那么针对不同的线程其id应该不同;slave实际的id应该是可以配置的,也就是master的id+配置id,这个配置id主要反应了slave回应内容给master的时候返回路径+这个转换器上具体的哪一个master。
(1)多个master和多个slave之间的id使用(假设回来的数据和发过去的命令顺序是一致的)
(2)outstanding:可以针对读和写操作,写操作的化需要master有一个FIFO来存在BRESP,outstanding depth是8的化,那就需要8个FIFO,每隔FIFO的深度要保证一个outsanding回来的resp能够全部被存下来。这样做的目的是因为尽量将这种数据处理放在master内部,而不用valid或ready来反压总线,反压总线会导致效率下降。
(3)out-of-order:乱序的时候需要使用buffer存储,而不能仅仅使用fifo,由于顺序不一致。
(4)重排序的时候需要有两个缓冲区,分别是事务缓存区和数据缓冲区。事务缓冲区按照到达顺序存放读事务(存放的事务信息一般包含id和地址),就绪的数据与缓冲区中首个事务进行比较(比较地址是否相同),若地址匹配则直接输出,否则进入数据缓存区。
具体参考:https://zhuanlan.zhihu.com/p/149071260
(5)对于多个master和多个slave之间的互联:需要注意扩展id问题,id=master给的id+转换器的id+转换器上的具体那一个master标记,因此slave的id一般比master的id位数宽;支持仲裁机制,内部存在缓冲区;支持重排序 (由interconnect保证重排序的顺序)
具体参考:深入 AXI4 总线(五B)多主机传输事务场景 - 知乎 (zhihu.com)
3.原子操作(解决的是一次读写必须连续的问题):
一次的读写操作是被绑定的,其他的读写操作是不能插入这个读写过程的;
原子操作主要分为两种:lock access,exclusive access
lock access:(1)lock transaction传输前需要这个master没有其他的outstanding transaction还没有完成(2)总线会保证只有这个master才能访问这个slave,总线会在协议上提供一个ar block和aw block。总线通过这个信息告诉其他master有一个lock 的transaction正在进行,如果有其他master访问这个slave,总线会通过这两个信号将其反压住,直到lock被释放了才会继续进行访问(这个过程被这两个信号和arbiter等组件保证)(3)master必须保证在一次lock 传输过程中的ARID和AWID相同。
exclusive access
(1)transaction必须要有多个data transfer(2)transaction必须要有相同的地址通道信息(3)地址必须和此次传输的数据是对齐的(4)需要exclusive access monitor
关于monitor的工作原理:monitor有不同的种类,有的记录多种信息,有的可能只会记录id和address,根据实际需要来。读操作后,会将这个读操作的相关信息记录下,具有相同信息的写操作来的时候会将这部分记录的信息清除并且给exokay的回应。需要注意的是,清除是将monitor所有内容都清除,而不是仅仅针对某一个id的信息进行清除。
实际上exclusive access monitor属于global monitor,也就是会接在互联结构之后,除此以外在ARM体系中还存在一个lock monitor。
lock monitor主要针对cacheable属性的数据进行检测,这其中还分是否为shareable;
global monitor主要针对的non-cacheable和device类型的检测。
具体参考:
ARMv8之exclusive操作(三) exclusive monitor | 骏的世界 (lujun.org.cn)
4.一些设计过程中需要注意的点:
write issuing capablity:写的过程中,在没有收到response之间最多能往外发送多少transaction(也就是w通道的数据)
write interleave capabilty(axi3 only):没收到response之前就发送write的id的能力,从这个角度来说,master如果具备这种能力,那么相应的slave应该配置相应的buffer用来存储这部分命令。原因在于如果不设置相应的buffer,比如先发送了id0的数据,如果此时interleave了,那么会在id0没有发送完之前就会发送id1的相关内容,如果salve不设置这样的buffer,那么就会一致在等id0的信息,系统可能就会死锁。
write acceptance capability:slave在没有给respnse之前能接收数据的能力
write interleave depth(axi3 only):slave用来表征没有接收到response之前能接收多少个不同AWID的数据。
read issuing capablity:类似于write issuing capablity,针对master的读操作。
read acceptace capablity:类似于write acceptance capability,针对于slave的读操作,接收能力。
read data reorder depth:Slave可以用于存储乱序地址的地方,其数量表示能存储多少个,如果为1表示不能reorder
5.实际设计过程中重排序模型:
在axi3中针对写操作的乱序命令发送的模型如下:
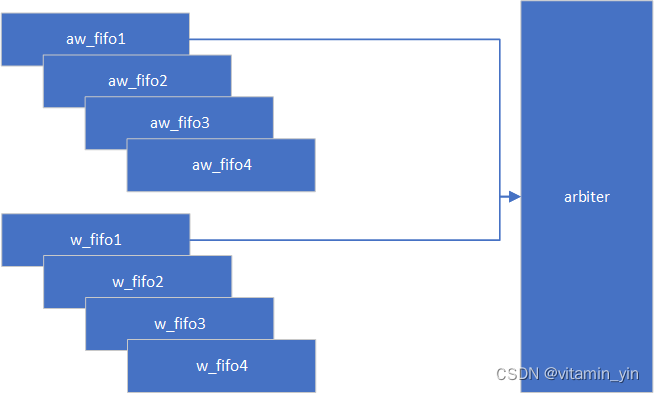
假设aw的id和w的id仅仅有两位,也就是针对aw和w的id每个都有一个FIFO,用来存相应的地址和数据,当这两个FIFO都满的时候,对应id的valid信号拉高,对于arbiter来说,输入有四个valid、data(这个data包含aw通道的信息和w通道的信息),通过仲裁输出唯一的valid和data。
从顶层上来看就是就是输入的id信息是乱序的,但是最终输出的id信息是对齐的。这种方式十分消耗资源,并且应用场景不多,因此axi4将其取消掉了。
针对读操作的乱序模型:首先读命令的id(ar-id)输入给slave的时候需要记录下来(存在id_write_fifo中),slave通过自己的调度机制实现往外发出对应的乱序的id,axi_slave通过自己调度机制实现对id重新排序的这个顺序,需要依次的存在id_read_fifo中。这里假设我发出去的1号命令,那么先回来的数据一定是1号命令对应的数据。而数据回来的时候,将id_read_fifo中的id号退出来作为buffer(也就是sram)的地址,将数据写道对应地址空间去。同时这个数据位还有一个有效位标志,当数据写入的时候该有效位拉高。对于id_write_fifo来说,将先进的id推出来(这个id是r_id),去检查buffer中对应地址的有效位是否为高,如果为高,那么就将数据送出去,并且id_write_fifo推出下一id。

这样通过buffer的操作是较为简单的,除此以外还可以强行使用fifo来实现,也就是将id_read_fifo推出来的id和id_write_fifo中推出来的id进行比较,只有相同id的情况下才会将数据给出,不同的化则需要将这个数据再用一个FIFO存起来,这种比较麻烦。
具体参考:深入 AXI4 总线(五A)单机多传输事务场景 - 知乎 (zhihu.com)
outstanding操作模型:针对aw通道,也就是aw通道的命令发送出去可以不用等待B通道的相应回来就直接发送下一个aw通道的命令。这种模型需要在axi_slave中例化一个buffer,这个buffer的地址是id,每个地址的数据是一个flag信息,对于不同的地址直接存到buffer里就可以了,对于相同的id需要保证当前id位置上的flag为低才能继续传输。而这个flag只有在B通道对于的相应的id回来以后才会将这个flag拉低。比如id为'b10,对于buffer的地址为3,在3地址的数据上写1,如果B通道的相应没有回来的时候,那么这个地址3的数据始终为1,只有回来的时候才会对这一位写0.而当地址3的数据为1,同时又来了一个id为'b10的命令,那么会反压master直到之前的那部分响应回来后才会接收这个数据。
总的来说,针对id需要有如下使用的准则:
(1)对于具有相同的awid,slave需要保证完成每个id的顺序是和master发出的地址顺序相同;对于不同的master但是id相同或者说不同id的情况,没有顺序要求(因为写过程存在地址,而axi4的master保证了发的数据和地址的顺序是一致的,直接根据地址来分配即可)。
??这里是不是指BID???
(2)对于ARID,由于返回读数据给master的时候需要辨别回给哪个master,因此存在两种情况,对于来自相同slave的相同arid,slave需要保证回地址的顺序一定是按照master发送地址的顺序,而对于不同slave但是具有相同id的情况,bus_matrix需要保证这一点(将id位进行扩展确保回来的数据知道是那个id)。

疑问:
1.乱序传输的时候回来数据实际上是通过返回的扩展id来区分是来自那个命令的吧,只是说由于回来顺序不一样master中我可能需要一个buffer把顺序不一样的数据处理一下,在进行操作是这个意思吗,我看网上强调如果有这种乱序的传输的时候master和slave都应该有相应的buffer来把这个数据存储一下,这个buffer该怎么理解呢?out of order处理的时候为什么一定要设置buffer用fifo不可以吗,你有ID不就能直接对应上吗,我用每个id做一个FIFO,对应的id的数据到这个id对应的FIFO去不就可以了吗,另外如果通过buffer来写的化,是不是就是相当于写一个存储器?
参考重排序模型。
2.exclusive monitor先读后写 为什么要先读后写 是模仿软件的操作吗 清除的时候是把所有内容都清掉吗?
3.interleave depth的概念,是不是只在读过程中起作用 ,在master和slave中的interleave depth是不是表示为没有接收response之前发送和接收AWID的能力?为什么是指存储ID的能力呢,interleave不是表示数据交错的情况的深度吗?
4.write acceptance capability:slave在没有给respnse之前能接收数据的能力,这里的接收数据的能力是指w通道的data吗?
是的
5.read data reorder depth:Slave可以用于存储乱序地址的地方,其数量表示能存储多少个,如果为1表示不能reorder?这个该怎么理解呢,是不是这个参数表示的是id相同的时候回来的数据顺序不同,需要slave或者bus matrix来实现对这个回来的数据重新排序?














 2230
2230











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









