







目录
内存交错技术(BANK interleaving)通过巧妙的分配地址线的映射方式,实现了内存颗粒内部不同BANK之间数据的交错访问,隐藏了各BANK的数据锁存时间和恢复时间,使得数据总线处于尽量饱和的工作状态,这显著提升了内存访问效率。
1.概述
在上一篇博文中,我详细讲述了DDR的内部组织架构、Burst和Prefetch的概念(详见:DDR知识一:关于Burst和Prefetch的理解)。本篇博文,我将详细阐述内存交错技术(BANK interleaving)的原理,以及这种操作带来的好处。
DDR的访问过程中,如果多条高速缓存行想连续获取数据,就需要内存交错技术(BANK interleaving)来提升访问效率,它本质上和CPU执行指令时的流水线操作类似。
我们知道,数据在DRAM和CPU之间是通过高速缓存行(Cash Line)一块一块的交互的。而现代DIMM的一次猝发就能塞满一条高速缓存行(8个64 bits,即64 Bytes),因此DRAM和CPU的交互速率就是数据的传输速度。为了提高CPU和DDR的交互速率,CPU中会设置多条高速缓存行(Cash Line)。
2.内存交错技术(BANK interleaving)
为了提高DIMM的吞吐量,同一颗IC内的各个BANK,被设计成可完全独立工作,可单独访问(即CPU访问颗粒以BANK为基本单位),也就是说,各个BANK可以处于读写周期的不同阶段。
一个简化的BANK模型如下:
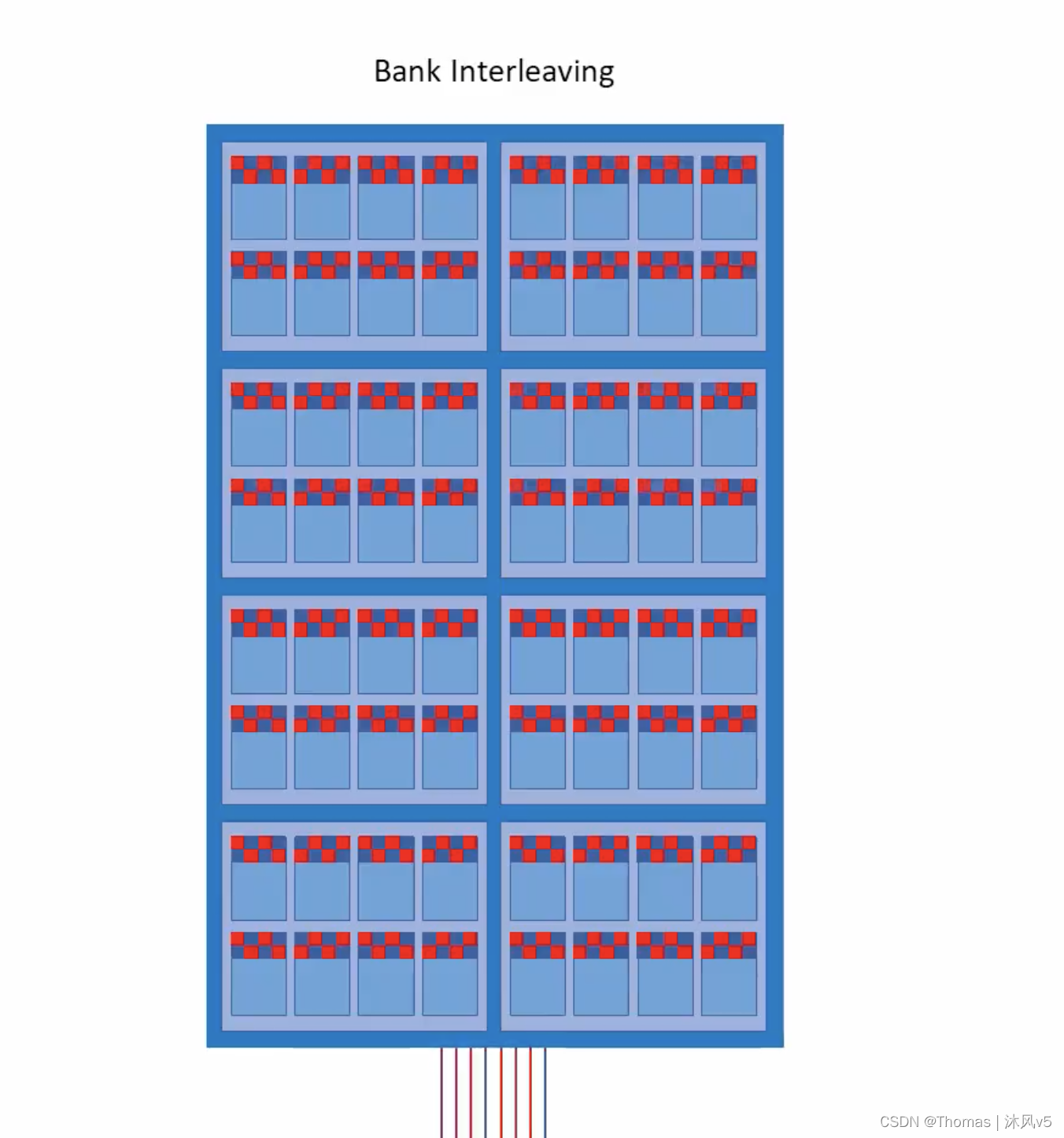
当一个BANK结束了一次猝发,下一个BANK可以立刻跟上猝发而不必等待第一个BANK恢复。然后下一个,再下一个......也就是说,当一个BANK正在泵出数据时 ,下一个BANK已经准备好泵出数据了。当一个IC的最后一个BANK猝发完成时,第一个BANK已经有足够的时间恢复初始状态了。
内存交错技术(BANK interleaving)使得数据高速输出,更重要的是使得数据通道在漫长的读写周期中保持饱和。
DRAM的设计者必须权衡好一颗IC内要有多少个BANK:更多的BANK意味着更高的并行度和更低的延迟(即数据总线利用率更高,访问速度更快),但在有限的硅片面积上,更多的BANK意味着更小的存储阵列(即“小而多”),而每个阵列都有一堆的外设器件,如解码器、感测放大器、选通器等。如果想设计尽可能大的DRAM容量,需尽量减少辅助器件的数量,把宝贵的空间留给存储单元。即:
更多的BANK=更高的并行度和更低的延迟、更快的访问速度;更小的存储阵列,更小的总容量。
更少的BANK=更低的并行度和更高的延迟、更慢的访问速度;更大的存储阵列,更大的总容量;更长的位线、更耗电。
内存交错技术(BANK interleaving)和Prefetch技术的结合,将极大地提高DIMM的访问速度,下面详细介绍它的实现原理。
如下图所示,从一个DRAM读取周期开始到它能输出数据会有个延迟,当数据猝发完成,该BANK需要时间恢复才能进行下个猝发。

由于BANK之间的访问是相互独立的,数据猝发可以在连续的BANK之间持续进行而不必等待,使得数据流除了一开始的延迟外一直能有输出,当最后一个BANK猝发结束时,第一个BANK已经可以再次猝发了,如下图所示。
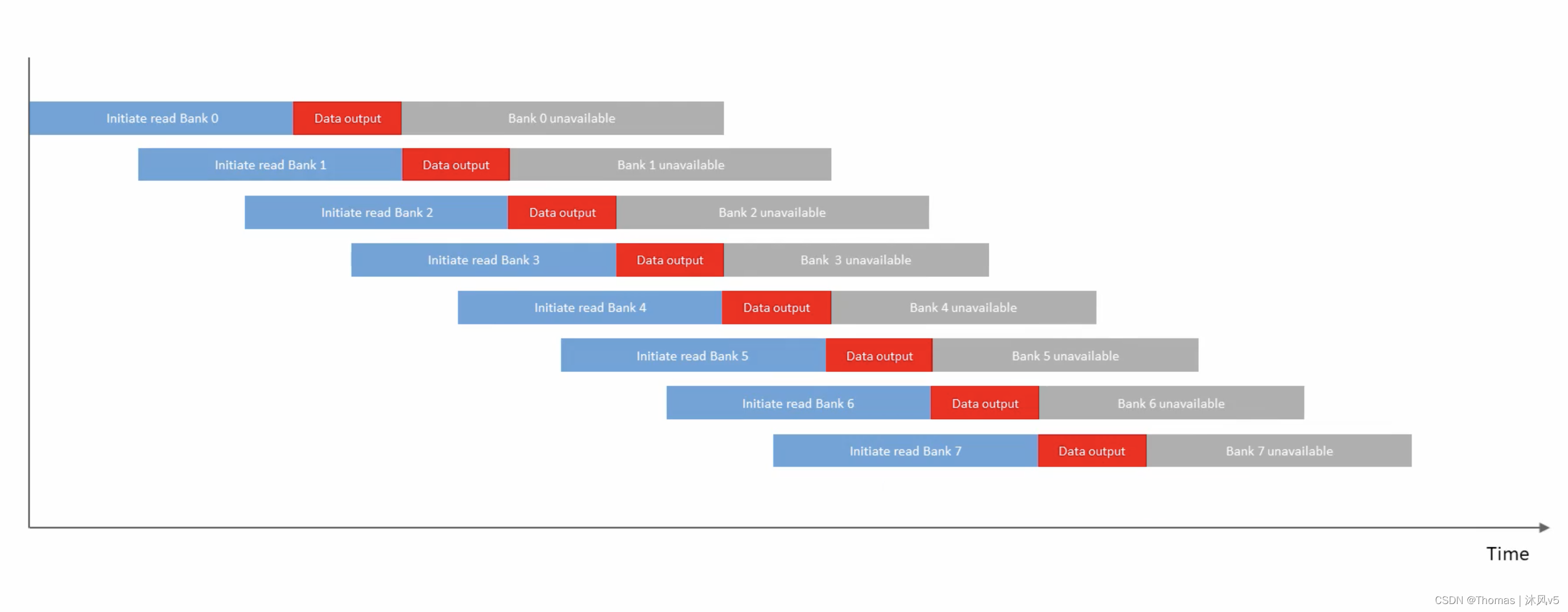
内存交错技术(BANK interleaving)与CPU的流水线操作极为类似,它把不同BANK的访问时间部分重叠,隐藏了不同BANK的数据锁存时间和恢复时间,使得数据能源源不断地从内存泵出来,极大地提升了DDR的访问效率。下面具体讲述如何利用内存地址到行、列、BANK地址的映射来实现内存交错访问。
下面是一颗IC中的一个BANK示意图,以BANK0为例进行说明。该BANK包含8个存储阵列,每个阵列包含8行8列共64个存储单元。为了实现猝发长度为4的、8个BANK之间的内存交错访问,将9 bits列地址进行如下拆分:行地址(3 bits)、列地址MSB(1 bit)、BANK地址(3 bits)、列地址LSB(2 bits)。
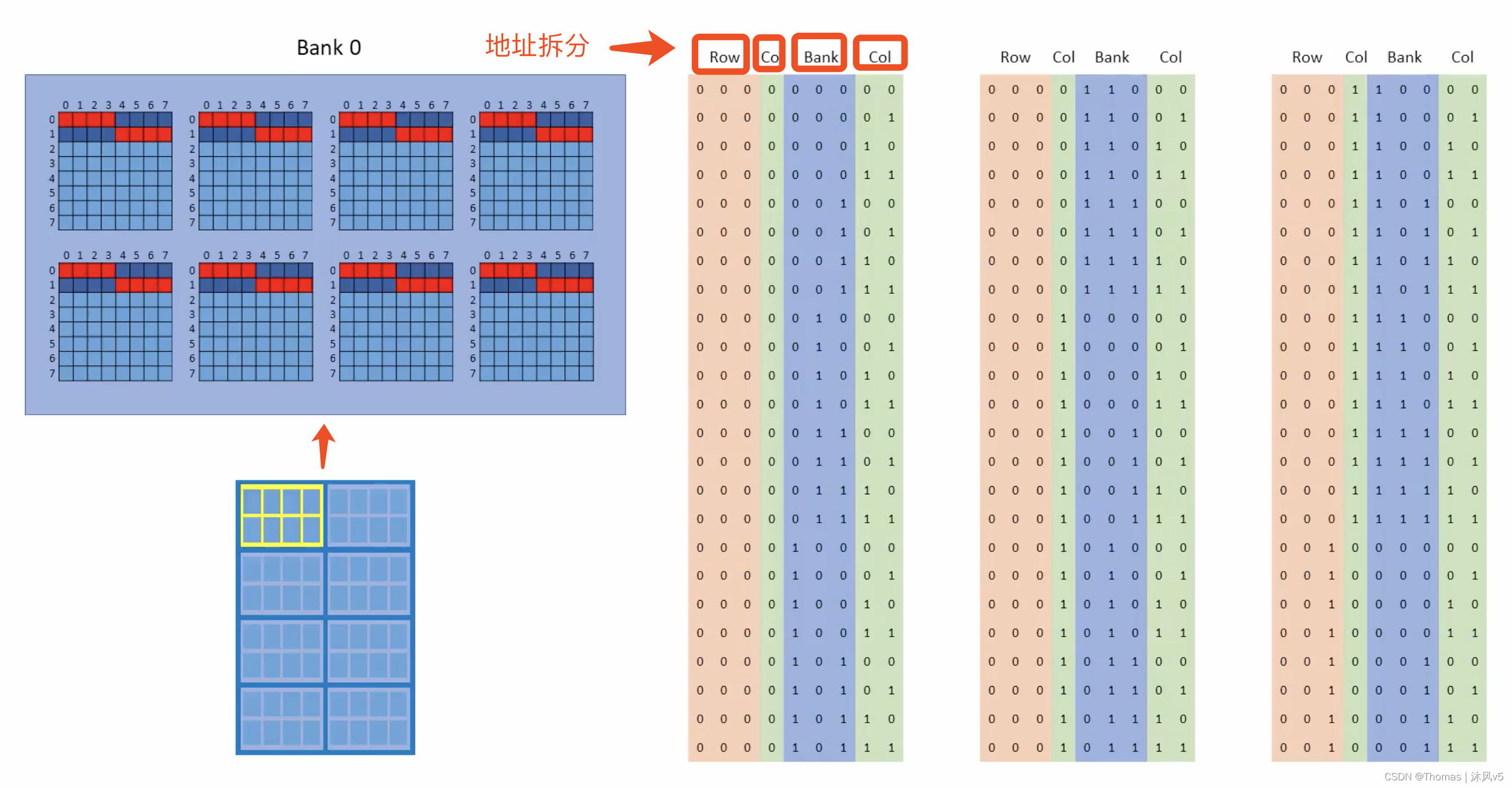
把列地址这样拆分看起来有点奇怪,但是你将会知道,这个非常聪明的小窍门,是实现内存交错技术(BANK interleaving)的精髓。
如下图所示,在读写操作周期中,内存地址会传送给DIMM,这里猝发的起始点是全0(0 0000 0000b),代表行0、列0、BANK0。由于猝发长度为4,故4列(列0--3)会被连续读取,该BANK中有8个存储阵列,它们共用相同的行列地址,所以是个4 Bytes的猝发。这4列对应的地址不需要内存控制器提供,DIMM能自动完成这个操作。
虽然每一列都有一个对应的地址,但只有最低2 bits的地址在改变,换句话说,列地址的这个部分是从0--3递增的。
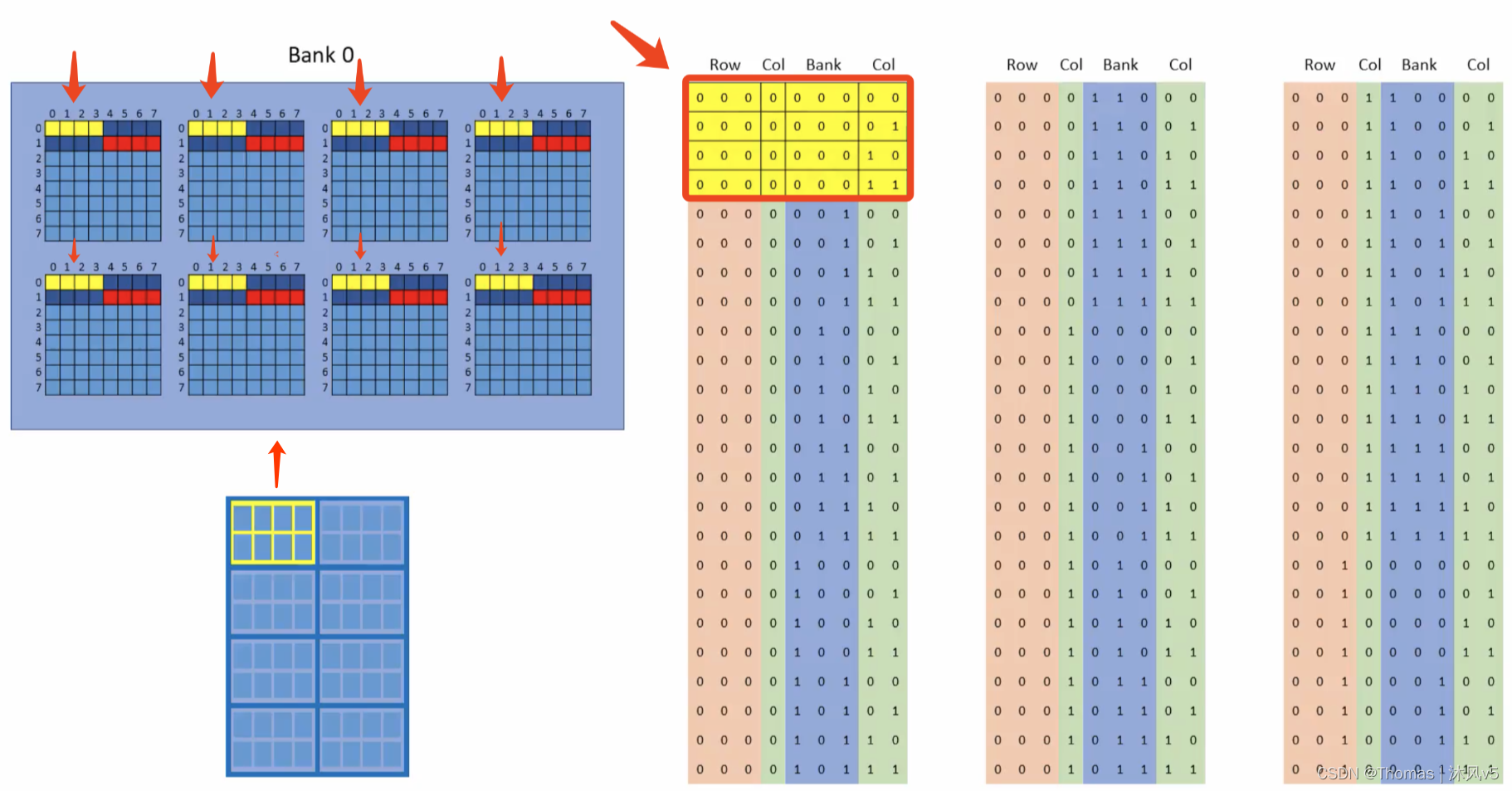
为了匹配猝发长度,下一个传递给DIMM的地址比前一个增大了4,这里行列地址还是和前一个一样,但是BANK地址增加了1。这样另一个4 Bytes猝发,不过这次是在不同的BANK(即BANK1)上发生,如下图所示。
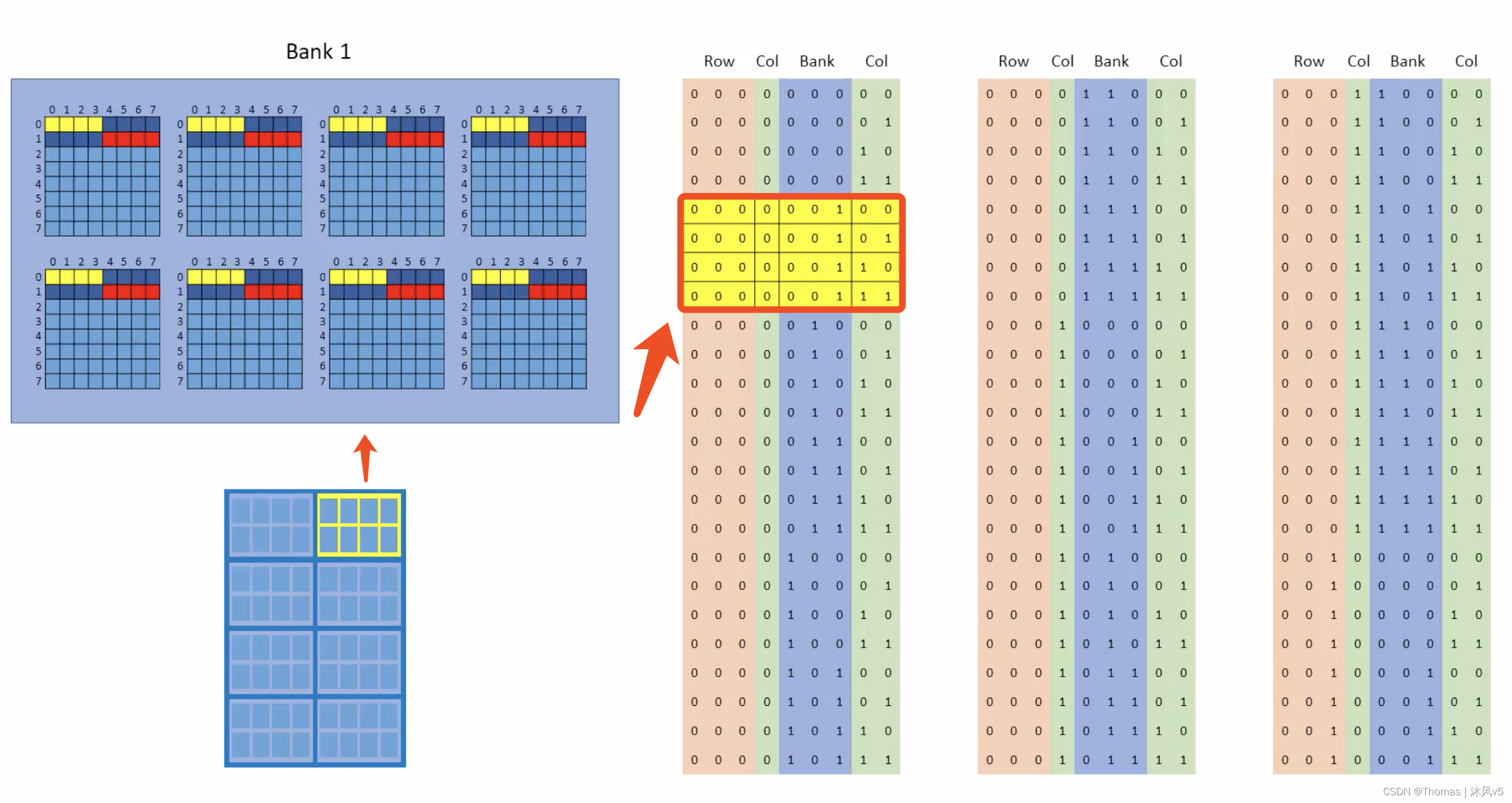
再下一个传递给DIMM的地址又比上一个增大4,在BANK2上猝发下一个4 Bytes,如下图所示。
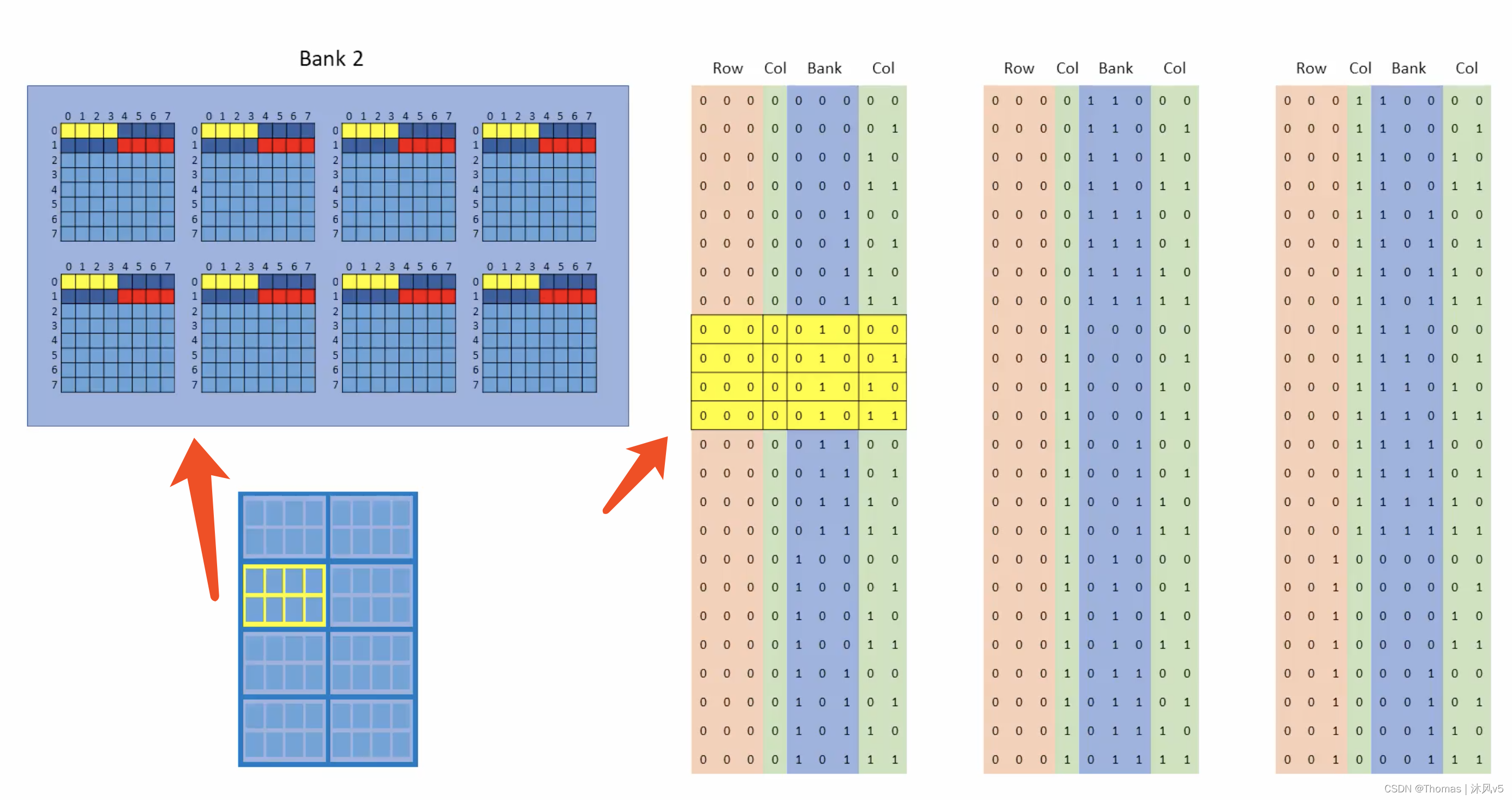
如此重复,依次猝发BANK3,BANK4,...,BANK7,每次猝发可读取/写入4 Bytes。
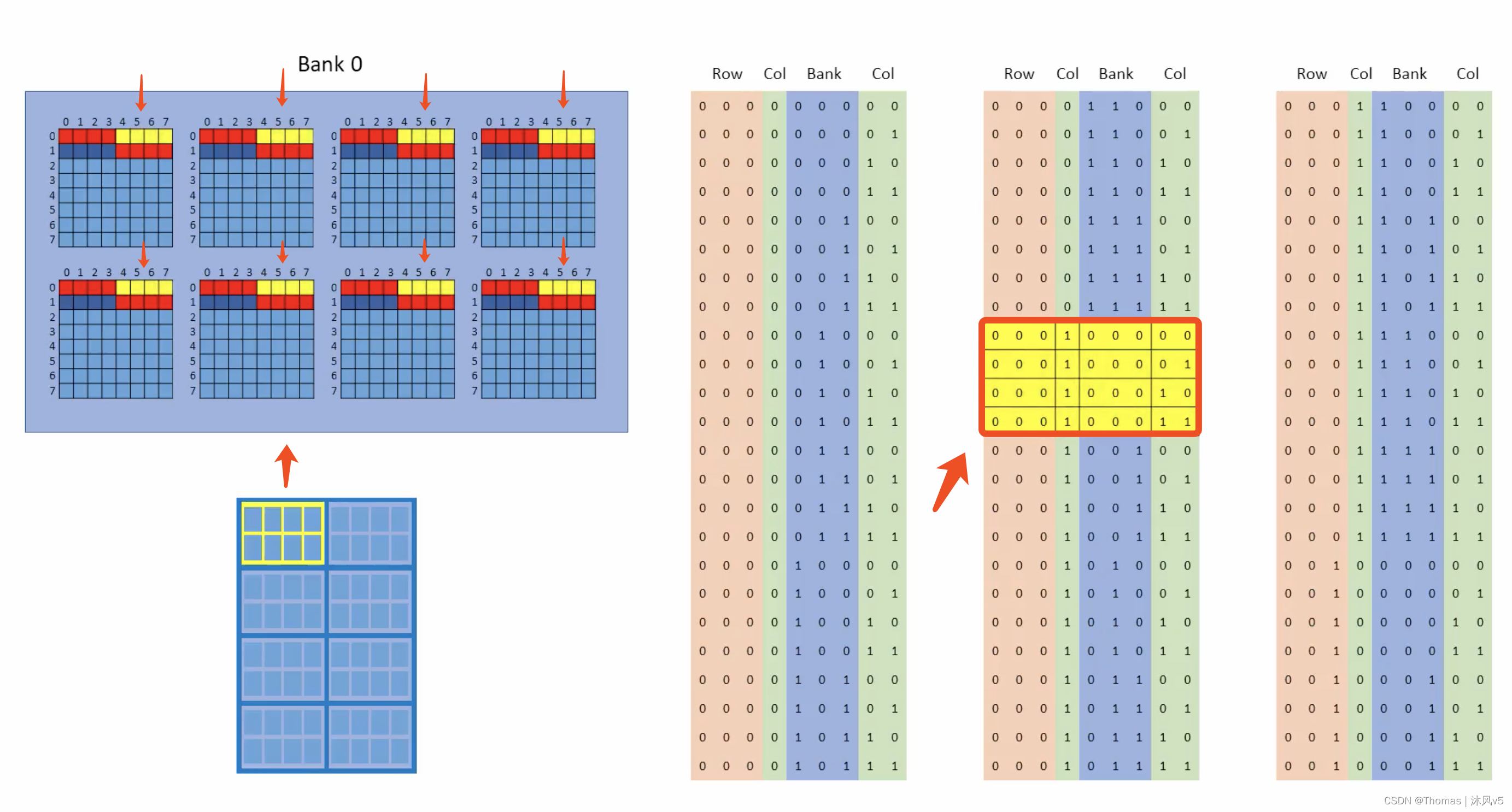
这个设计的精妙之处在于猝发回到BANK0再次猝发时,此时列地址MSB变成了1,列地址变成100b(即4)。猝发将从BANK0再次发生,只不过从一行中的不同列开始(列4--7),如下图所示。
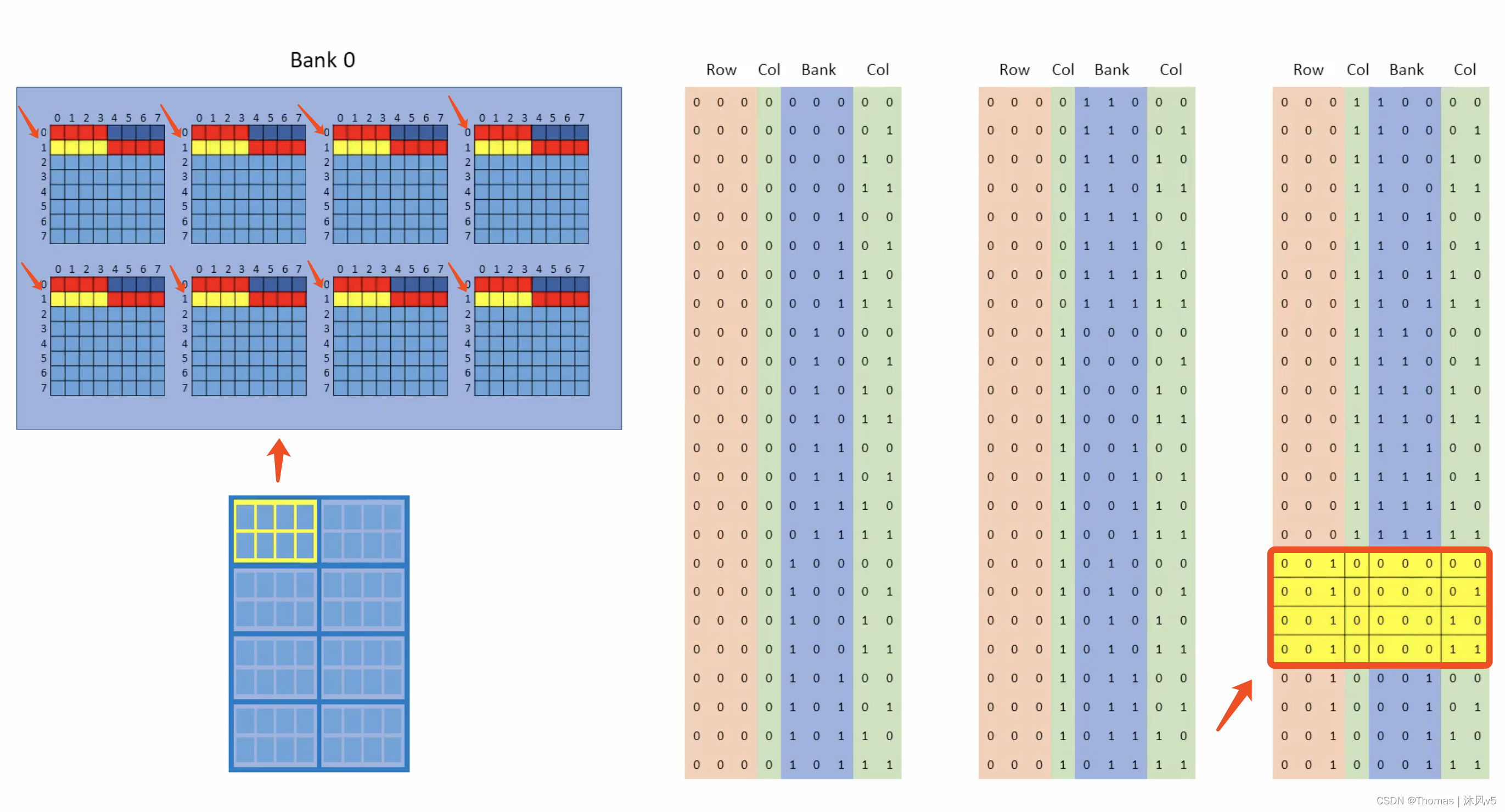
它会再次完成BANK0--BANK7的猝发,最终又回到BANK0。但这次行地址LSB变成1,而列地址MSB再次变成0。下一次猝发从行1开始,列和BANK都是0,重复以上的猝发过程,如下图所示。
以上只是个简化模型,但对于更大的存储阵列,以及长方形阵列,原理是一样的。根据设计,DIMM可能有或多或少的BANK,以及或长或短的猝发长度。由于BANK数量和猝发长度(BL)一定是2的指数次幂,故内存地址的映射方式就能控制BANK之间数据交错访问。
3.总结
内存交错技术(BANK interleaving)通过巧妙的分配地址线的映射方式,实现了内存颗粒内部不同BANK之间数据的交错访问,隐藏了各BANK的数据锁存时间和恢复时间,使得数据总线处于尽量饱和的工作状态,这显著提升了内存访问效率。
===========================全文完毕=====================================
欢迎留言讨论,批评指正。码字不易,求关注点赞收藏,一键三连,给予我继续创作的动力,感谢!


















 2819
2819

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











