





Complementary Prior 解决了多层网络中层间参数W无法计算的问题。
多层有向网络如下图,如果计算 W,我们需要知道第一个隐层的后验概率,那么会遇到几个问题:
1)后验概率几乎不可计算,因为所谓的“explaining away”或者“Berkson's Paradox”或者“section bias”[1]. explaining away是指比如p(hi|vi)与p(hj|vi)是彼此独立的条件概率,也就是hi和hj是独立的事件,但如果同时已知vi,hj,p(hi|vi,hj)会小于p(hi|vi).
 |
若求W则需要求出似然项 p(v|hidden variables on the first hidden layer). 在文章中给定的情况,有一个数据层和一个隐藏层,如果p(h|v)可以分解成各个p(hi|v)的乘积形式,则可以根据公式(1)求出系数W,但分解是无法实现的,因为:如果只有一个隐层,那么隐层各个变量的先验概率是独立的,而后验概率并不是独立的,
是似然项的不理想,或者说它的内含的相关性造成了后验概率无法分解,这种非独立性是输入数据中的似然项(p(hi|Data) and p(hj|Data) are correlated)中的相关性造成的.这也就导致了explaining away, 比如,给定d1,d2,...,dn, 我们根据后验概率推出h1,h2,...,hn, 但当推出h2之后,关于h1的后验概率变化了,也就无法根据概率方程

列方程组解出W.
2)我们需要上一层的 W,才能计算这一层的 W。也就是说,这个后验概率是依赖于上一层的先验和似然的。
3)我们需要上一层的所有变量的“integrate”才能作为第一个隐层的先验。
论文的Appendix A提出了一种特殊的多层有向结构,可以方便的求出后验分布。而这种结构最大的特点就是它有 Complementary Priors。事实上,这个有向结构是等价于无向结构的。它的思想来自于当马尔科夫链达到细节稳态平衡时,是可逆的。
为什么求complementary见下图,其中x-v,y-h

介绍一下马尔科夫过程的几个基本概念,本文将层数的加深看作是马尔可夫过程的逐渐收敛,也等价于Gibbs采样:
在达到稳态时(足够深的层对应稳态),概率分布和初始层的分布无关:

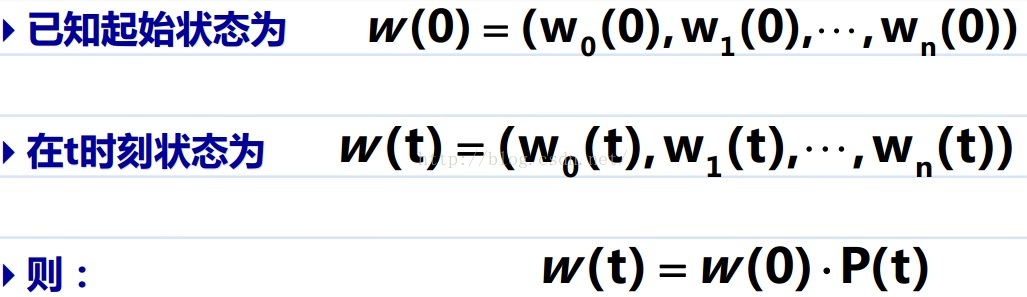
转移概率的性质:

转移概率的导数:

状态,转移概率及其导数之间的关系:

注意:以上字母都代表矩阵,状态的各个分量经过转移概率的重新分配,发生了此消彼长。
接下来我们开始加深层数,进行Gibbs采样的过程,在Gibbs中,已知的是条件概率,正如论文中的公式(14)和(15),虽然我们不知道(16)中的联合分布,但通过条件概率采样次数的曾多,我们渐渐得到了满足联合分布(16)的样本集合,每一次采样都是代表状态向量的一次更新,每一个状态向量也就是每一层中的随机变量集合。我们一层一层向上根据(14)和(15)交替推导,
x0-y0-x1-y1-...x0代表数据层,y0代表第一隐藏层,之后代表各个隐藏层。
当达到稳态的时候,相邻层的随机变量也就满足(16)中的联合分布。也就是说 Gibbs采样的目标就是公式(16).再根据(18,19,20)可以求出边缘分布,并进而可以开始从上面的层往下面的层推(29,30),

(稳态正转移的发生率等于逆转移的发生率)。Complementary Priors 其实就是马尔科夫链的平衡分布,Hammersley-Clifford 定理证明了这点[2]。Hammersley-Clifford 定理实际上是说,Gibbs分布和马尔科夫随机场是等价的。其等价条件是:一个随机场是关于邻域系统的马尔科夫随机场,当且仅当这个随机场是关于邻域系统的Gibbs分布。
至此,我们得到了联合分布(16),边缘分布(28)和逆条件分布(29,30),并可以将边缘分布乘上p(h|v)来抵消相关性进而得到独立的分布。总之,Complementary Prior 就是在第一层隐层上再加一层或多层 Sigmoid,并且拥有和 visible ->hidden 相反作用的 W (W <-> W^T)。目的是为了抵消 explaining away 现象,该现象使得 p(h|v) 对于不同的 h_i 不可分解。若假设有一个先验分布,使得其乘上似然之后得到的 p(h|v) 能够被分解为 p(h_i|v) 的乘积。这个先验就是complementary prior。
对于一个单层 Sigmoid Belief Networks,其补完先验就是无数多层的 Sigmoid Belief Networks,且相互之间互绑 W。这个单层模型也等同于一层的RBM。这样就可以把每一层网络都当做弱分类器,使得每一次可以只学习一层网络。
[1] http://www.cs.ubc.ca/~murphyk/Bayes/bnintro.html
[2] http://en.wikipedia.org/wiki/Hammersley%E2%80%93Clifford_theorem
[3] http://www.iro.umontreal.ca/~lisa/twiki/pub/Public/DeepLearningWorkshopNIPS2007/deep_learning_teh.pdf
2)我们需要上一层的 W,才能计算这一层的 W。也就是说,这个后验概率是依赖于上一层的先验和似然的。
3)我们需要上一层的所有变量的“integrate”才能作为第一个隐层的先验。
论文的Appendix A提出了一种特殊的多层有向结构,可以方便的求出后验分布。而这种结构最大的特点就是它有 Complementary Priors。事实上,这个有向结构是等价于无向结构的。它的思想来自于当马尔科夫链达到细节稳态平衡时,是可逆的。
为什么求complementary见下图,其中x-v,y-h
介绍一下马尔科夫过程的几个基本概念,本文将层数的加深看作是马尔可夫过程的逐渐收敛,也等价于Gibbs采样:
在达到稳态时(足够深的层对应稳态),概率分布和初始层的分布无关:
状态和转移概率的关系:
接下来我们开始加深层数,进行Gibbs采样的过程,在Gibbs中,已知的是条件概率,正如论文中的公式(14)和(15),虽然我们不知道(16)中的联合分布,但通过条件概率采样次数的曾多,我们渐渐得到了满足联合分布(16)的样本集合,每一次采样都是代表状态向量的一次更新,每一个状态向量也就是每一层中的随机变量集合。我们一层一层向上根据(14)和(15)交替推导,
x0-y0-x1-y1-...x0代表数据层,y0代表第一隐藏层,之后代表各个隐藏层。
当达到稳态的时候,相邻层的随机变量也就满足(16)中的联合分布。也就是说 Gibbs采样的目标就是公式(16).再根据(18,19,20)可以求出边缘分布,并进而可以开始从上面的层往下面的层推(29,30),
(稳态正转移的发生率等于逆转移的发生率)。Complementary Priors 其实就是马尔科夫链的平衡分布,Hammersley-Clifford 定理证明了这点[2]。Hammersley-Clifford 定理实际上是说,Gibbs分布和马尔科夫随机场是等价的。其等价条件是:一个随机场是关于邻域系统的马尔科夫随机场,当且仅当这个随机场是关于邻域系统的Gibbs分布。
 |
对于一个单层 Sigmoid Belief Networks,其补完先验就是无数多层的 Sigmoid Belief Networks,且相互之间互绑 W。这个单层模型也等同于一层的RBM。这样就可以把每一层网络都当做弱分类器,使得每一次可以只学习一层网络。
[1] http://www.cs.ubc.ca/~murphyk/Bayes/bnintro.html
[2] http://en.wikipedia.org/wiki/Hammersley%E2%80%93Clifford_theorem
[3] http://www.iro.umontreal.ca/~lisa/twiki/pub/Public/DeepLearningWorkshopNIPS2007/deep_learning_teh.pdf















 1303
1303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









