







 NVIDIA Jetson AGX Orin开发套件在性能上显著超越了Jetson AGX Xavier,尤其是在TOPS、CPU内核、内存和GPU核心数方面。基准测试显示,Orin在某些任务上速度提升可达2.66倍,尽管预览版软件稳定性稍逊。随着未来软件更新,性能有望进一步增强。Orin为边缘AI应用开辟了新的可能性,尤其适合需要更大、更准确模型的项目。
NVIDIA Jetson AGX Orin开发套件在性能上显著超越了Jetson AGX Xavier,尤其是在TOPS、CPU内核、内存和GPU核心数方面。基准测试显示,Orin在某些任务上速度提升可达2.66倍,尽管预览版软件稳定性稍逊。随着未来软件更新,性能有望进一步增强。Orin为边缘AI应用开辟了新的可能性,尤其适合需要更大、更准确模型的项目。

NVIDIA Jetson AGX Orin开发套件的官方价格为1999美金,而三年前发布的Jetson AGX Xavier开发套件的官方价格为899美金(现在已经停产买不到了),很多用户说居然贵了这么多,到底贵在哪里了?

今天Lady在网上发现了一篇评测文章,我就翻译节选了发在这里供大家参考。
文章的原文是——

是由SmartCow公司发布,这是一家人工智能工程公司,专门从事高级视频分析、应用人工智能和电子制造,成立于 2016 年。
该公司表示——
在整篇文章中,我们将与您分享新的 NVIDIA Jetson AGX Orin 模块如何成为边缘设备领域的游戏规则改变者。
规格比较

(点击图片可以放大观看,建议大家把图片保存)
将 Jetson AGX Orin 的规格与 Jetson AGX Xavier 进行比较,我们可以同意 Jetson AGX Orin 非常有前途。它拥有高达 275 TOPS,比 Jetson AGX Xavier 的 64GB/32GB 版本强大 8 倍。此外,它还拥有多达 12 个内核的新 Cortex CPU、LPDDR5 内存、64GB eMMC、2 个下一代 DLA,以及多达 2048 个内核的 NVIDIA Ampere GPU,具有 64 个张量内核。显然,TOPS 多 8 倍并不一定意味着推理时间快 8 倍。
事实上,在这份规格表中,NVIDIA 做了一个推理时间比较。
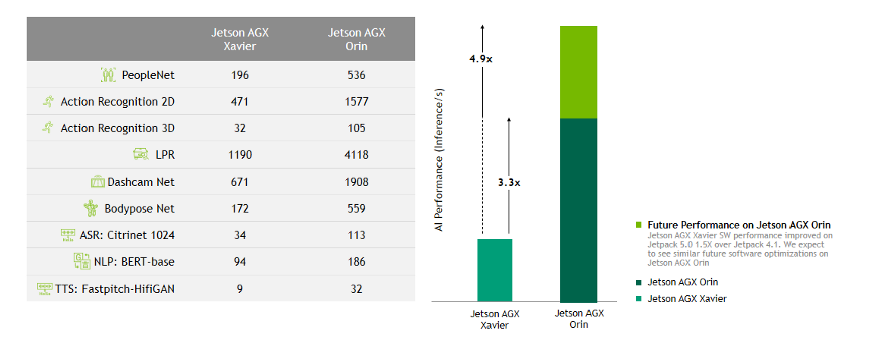
根据上表并使用当前可用的软件,与 AGX Xavier 相比,我们可以预期可以实现高达 3.3 倍的改进,并且我们可以期待在未来的更新中获得更好的性能。开发套件中包含的 Jetson AGX Orin 模块与生产的 Jetson AGX Orin 64GB 模块的规格相同,只不过内存除外:它具有 12 核 Cortex CPU 和 2048 核 GPU 以及 64 个张量核,但具有 32GB LPDDR5 内存而不是 64GB .
运行 deviceQuery 可以让我们获得GPU 更详细的规格:
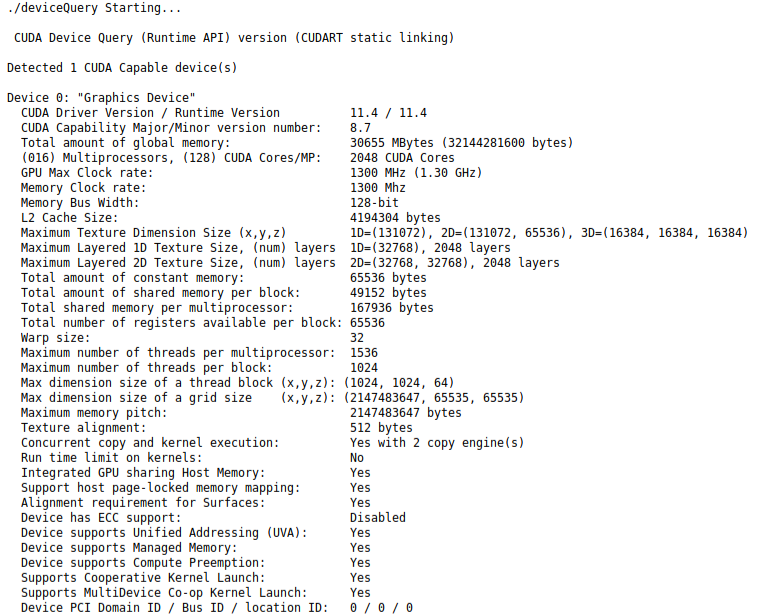
作为对照,我们将使用 Jetson AGX Xavier开发套件(配备 512 核 Volta GPU、32GB LPDDR4x 内存、32GB 内部存储、8 核 Carmel CPU 和 2 个 DLA V1 内核,AI 性能测量为 32 TOPS。)

Benchmarking
在本节中,我们将在两个设备上运行相同的脚本。在查看图表和实际指标之前,让我们看一下软件环境。我们的 Jetson AGX Orin 使用 Jetson Linux 34.0、CUDA 11.4 和 TensorRT 8.4.0 Early Access 运行 JetPack 5.0 Early Access。另一方面,Jetson AGX Xavier 使用 Jetpack 4.6 与 Jetson 32.6.1、CUDA 10.2 和 TensorRT 8.0.1 刷新。两者最大的区别在于可能会影响引擎构建过程的 TensorRT 版本。在解释结果时必须牢记这一点。
首先,我们将运行一个具有两个模型的口罩识别管道:一个人脸检测模型和一个分类网络,该网络接受检测到的人脸的输入并确定该人是否戴着口罩。 两种模型都在 fp16 模式下使用 TensorRT 运行。 别担心,int8 量化模型的测试即将推出。
,时长06:31
根据上述视频,我们无法轻易区分任何视觉差异。 然而,从 FPS 计数来看,很明显 AGX Orin 更能够在输入视频上生成推理。
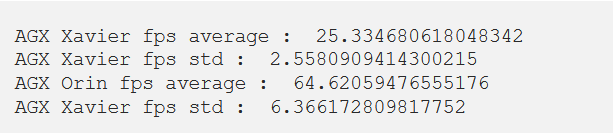
因此,我们可以得出结论,在这种情况下,Jetson AGX Orin 比 Jetson AGX Xavier 快 2.66 倍,但当前为预览版软件,稳定性也稍差一些。
下一个测试是纯基于 TensorRT 的分类模型推理基准。对于那些熟悉边缘分类的人来说,EfficientNet 系列可能会敲响警钟。众所周知,这个著名的分类模型以非常低的延迟提供了令人难以置信的良好准确性。众所周知的事实是,在量化后,vanilla EfficientNet 模型将导致精度损失,因为 Swish 激活函数和 SENet 将您的模型保持在 fp16 直到掌握 QAT。我们将考虑 fp16 和 int8 模型。对于这些测试,我们将使用两个不同的 EfficientNet 系列——从 B0 到 B4 的 vanilla 版本和从 lite0 到 lite4 的 lite 版本。如果您对这些网络的实现感到好奇,我强烈邀请您查看这个 EfficientNet-lite 存储库。此外,在现实生活场景中,量化方法与普通模型 (QAT) 和精简模型 (PTQ) 不同,因此我们决定使用相同的 PTQ 方法(相同的图像、参数……)对两个模型族进行量化。这将产生可比较的结果。
在嵌入式设备上部署分类模型时,我们通常将它们转换为 fp16 或 int8 并更改输入大小。这样做是因为证明输入大小、准确性和推理时间之间存在相关性。这意味着输入的大小越大,模型可能越准确,但代价是推理时间显著延长。影响推理时间和准确性的另一个参数是模型本身的大小(B0、B1、...)。因此,在选择适合您需求的组合之前,最好先对所有组合进行基准测试。
例如,输入大小为 100x100 的 EfficientNet-B2 可以与输入大小为 224x224 的 EfficientNet-B0 一样快,但 B2 的准确度会提高 0.5%;推理时间和准确性之间的平衡是一个巨大的挑战。这就是为什么在本节中,我们决定展示基于相同结构的多个模型,具有多个批量大小和多个输入大小。
FP16

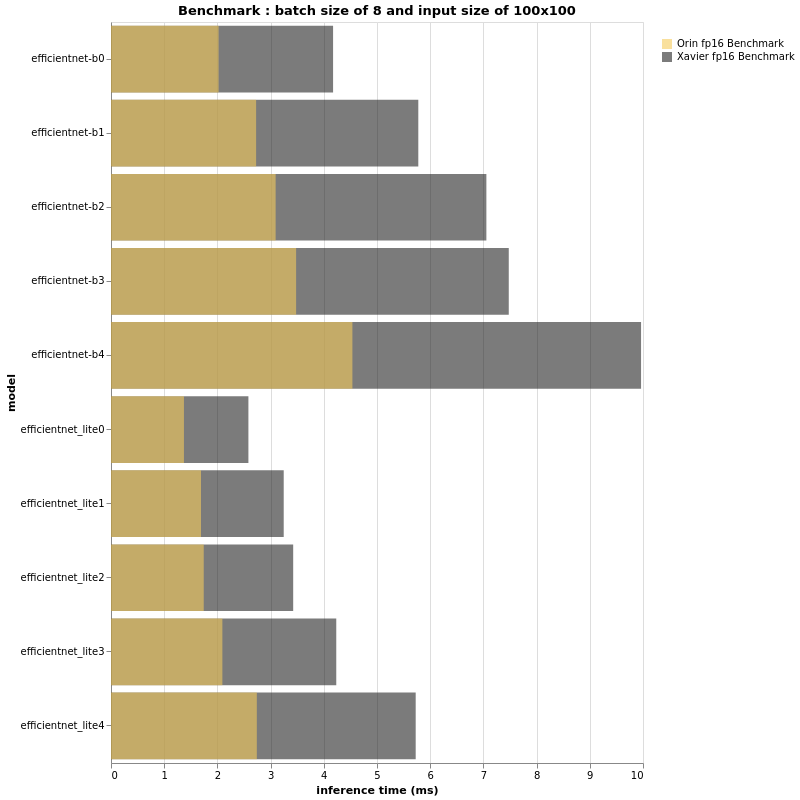
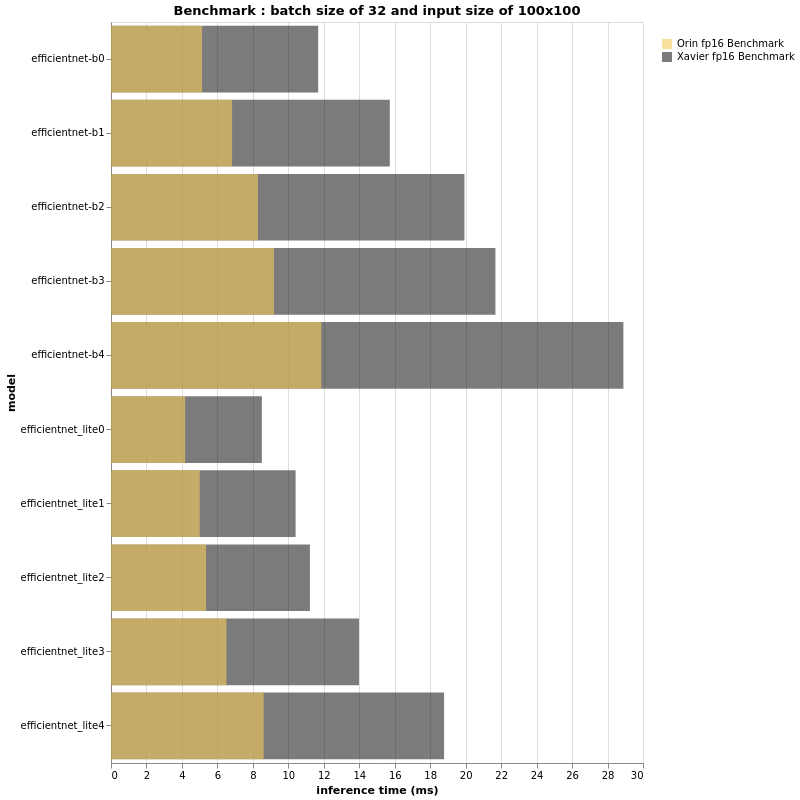
(更多评测结果可以阅读原文)
基于上述漂亮的条形图,我们绝对可以得出一些结论。首先,正如预期的那样,Jetson AGX Orin 比它的兄弟 Jetson AGX Xavier 快得多。
话虽如此,再次证明仅靠 TOPS 或 FLOPS 无法为我们提供真正的性能洞察力。
批量大小为 32 且输入大小为 224x224 的 EfficientNet-B4 在 Jetson AGX Orin 上的速度与在具有相同配置的 Jetson AGX Xavier 上运行的 EfficientNet-B0 一样快。
此外,B4 在 ImageNet 上的 top-1 准确率为 82.9%,而 B0 的准确率为 77.1%。
因此,如果您在 Jetson AGX Xavier 上运行的项目的 FPS 性能可以接受并且不需要更多功能,那么您可以在使用 Jetson AGX Orin 时部署更大的模型并拥有更准确的管道。
INT8
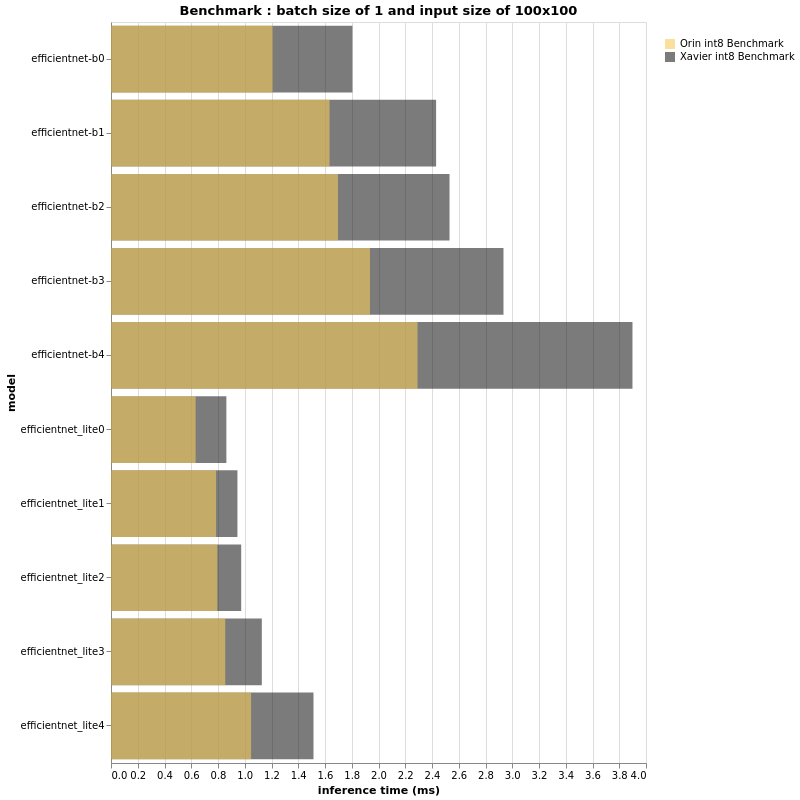
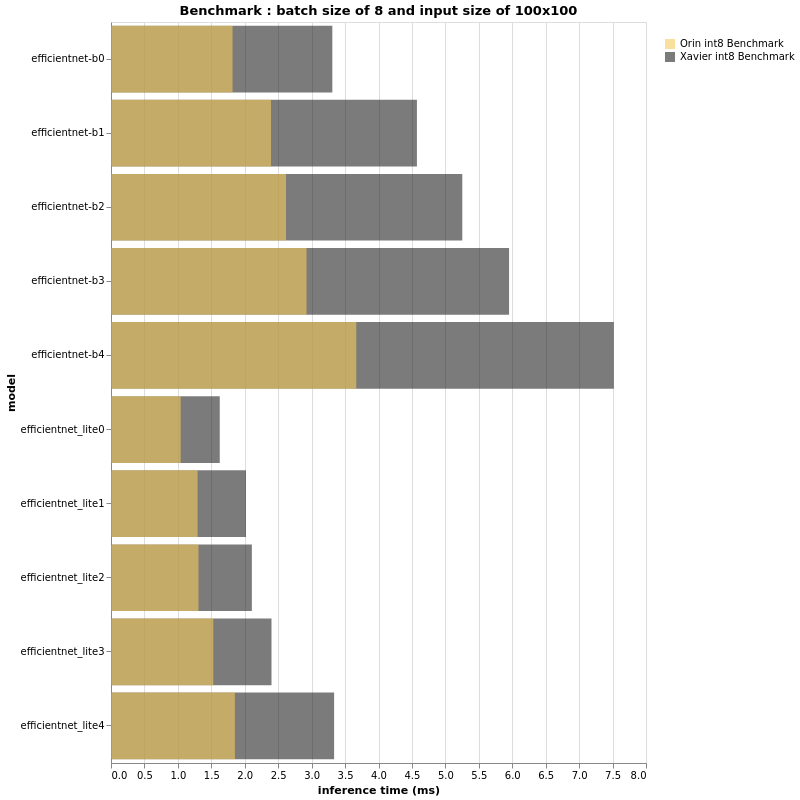
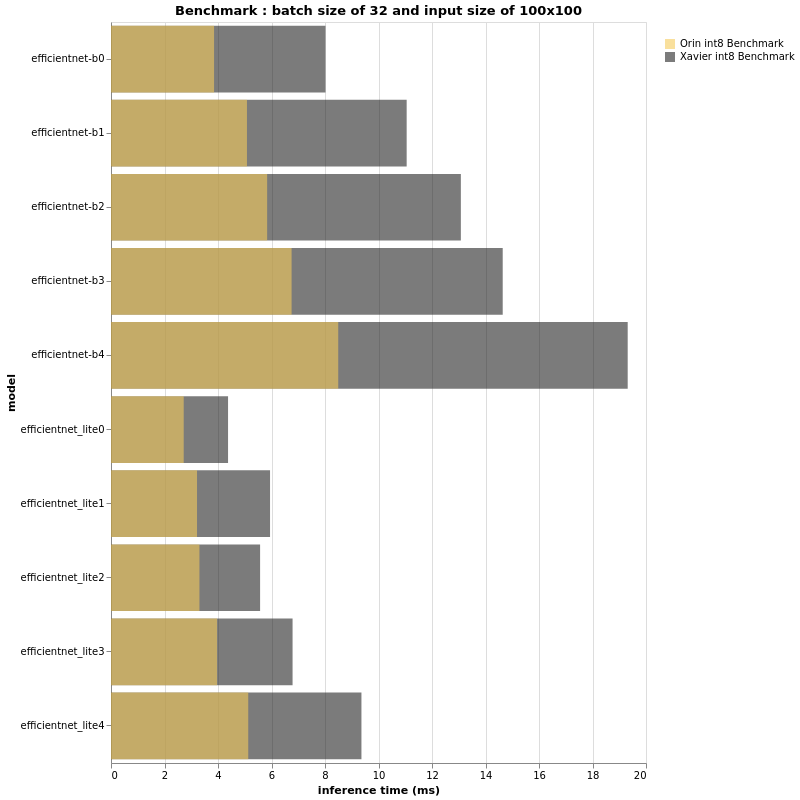
(更多评测结果可以阅读原文)
上面的图表看起来和 fp16 的结果非常相似,不是吗?事实上,Jetson AGX Orin 和 Jetson AGX Xavier 在这个 int8 上下文中的性能比率似乎与 fp16 相同。然而,如果性能比大致相同,则仔细观察,测量推理时间的横坐标轴预计会有所不同,特别是当批量大小和/或输入大小更大时。对于 fp16 和 int8,越大 输入大小和批量大小,Jetson AGX Xavier 和 Jetson AGX Orin 之间的差距越大。总之,小输入大小和小批量大小可能不会向我们展示 3 倍的性能差异。我们通过实验看到,在更大模型的情况下,与 AGX Xavier 相比,Jetson AGX Orin 的性能可以达到甚至超过 3 倍。
根据我们迄今为止的测试,Jetson AGX Orin 似乎是 Jetson 家族中非常有前途的新成员。然而,我们还没有进行最后一次测试。由于 DLA 内核不同,我们将尝试使用 NVIDIA AI IOT jetson_benchmarks 进行公平可靠的比较。虽然不是为支持 AGX Orin 而设计的,但对脚本进行一些修改后,我们就可以运行基准测试并获得以下结果:
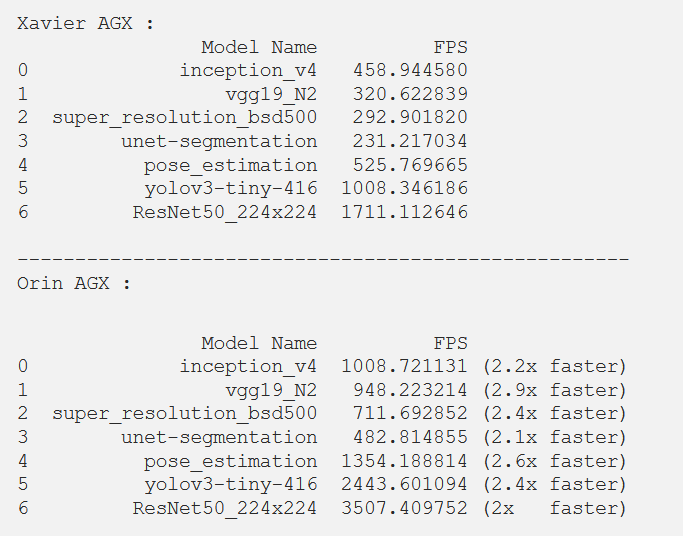
结论
我们通过这些基准测试表明,Orin 是 Jetson 系列的一个非常有前途的新成员,我们可以期待在不久的将来通过软件更新获得更好的结果。通过发布 NVIDIA Jetson AGX Orin,NVIDIA 无可争议地让嵌入式 AI 世界向前迈出了一大步。Jetson Xavier 设备已经非常强大且充满潜力,Orin 现在为嵌入式 AI 的持续增长铺平了道路。我们现在可以计划和开展我们以前甚至无法想象的更大、更复杂的项目。对于那些受任务数量限制的人,NVIDIA 将标准推得更高。事实上,在使用 Jetson AGX Orin 仅仅几天之后,我们 SmartCow 已经在重新考虑我们的嵌入式解决方案,以提出更多的功能、更好的准确性和可靠性;这是一个很大的改变游戏规则。
原文:
https://medium.com/@Smartcow_ai/is-the-new-nvidia-jetson-agx-orin-really-a-game-changer-we-benchmarked-it-b3e390f4830a


















 553
553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









