







 本文介绍了如何使用Mediapipe进行实时3D姿态估计,并解释了Mediapipe的3D坐标原理。作者还推荐了其他人体姿态估计模型如mmpose和DeepLabCut,以及如何获取实际3D坐标的方法。
本文介绍了如何使用Mediapipe进行实时3D姿态估计,并解释了Mediapipe的3D坐标原理。作者还推荐了其他人体姿态估计模型如mmpose和DeepLabCut,以及如何获取实际3D坐标的方法。
一、前言
大约两年前,基于自己的理解我曾写了几篇关于Mediapipe的文章,似乎帮助到了一些人。这两年,忙于比赛、实习、毕业、工作和考研。上篇文章已经是一年多前发的了。这段时间收到很多私信和评论,请原谅无法一一回复了。我将尝试在这篇文章里回答一些大家经常问到的问题。
二、绘制3d铰接骨架
我曾在之前的文章里讲过,可以使用Mediapipe推理得到的3d坐标绘制到3d画布上,使用的函数就是:mp.solutions.drawing_utils.plot_landmarks(),不过只能导出2d图,没法拖动交互,实现效果如下:
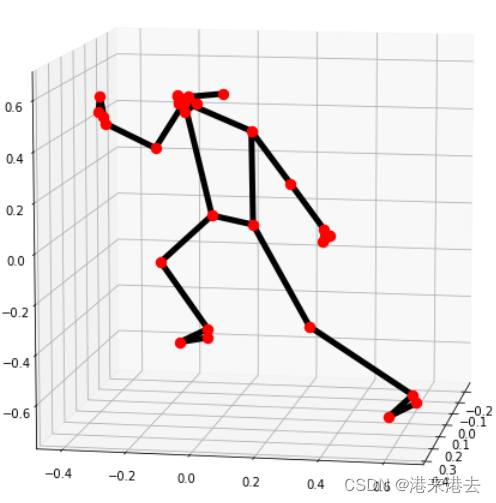
这个函数是官方自己封装的,我们可以利用matplotlib自行实现实时绘制3d铰接骨架图的需求,效果如下:
实时姿态估计
由于画在了3d画布上,这时候就能拖动画布,以不同角度查看实时的人体姿态。大家可以自行尝试。
三、关于Mediapipe的3d坐标
-
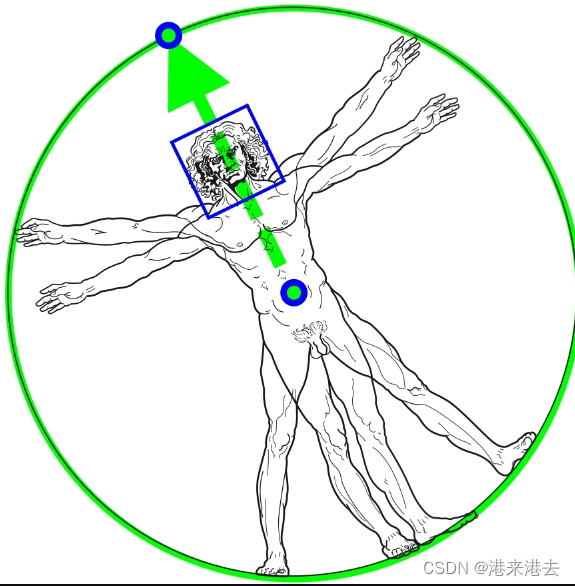
mediapipe可以推理得到3d坐标,但这个3d坐标并不是真实的3d坐标。这些坐标描述了一个以人体臀部为中心的人体外接圆,是虚拟的坐标。这一点可以从其官方描述得知。
-
在对每一帧图像做处理时,如果要获取某个keypoint(人体某个关节)在图像上的坐标时,可以这样转换:
results = pose.process(img)
X_ = results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].x * img_width
Y_ = results.pose_landmarks.landmark[mp_pose.PoseLandmark.NOSE].y * img_height
四、关于姿态估计的进一步学习
- 如果想获取实际的3d坐标,可以用相机标定,这里涉及的知识更多。Google搜索‘camera calibration’可以学习到更多。
- 其他好用的人体姿态估计模型,有mmpose、alphapose、openpose等。个人比较喜欢mmpose,从数据标注到模型训练都比较成熟。
- 曾经有人问过,如果要做动物姿态估计,那么毫不犹豫请用DeepLabCut,同样在数据标注和模型训练及导出上,非常成熟易用。
五、所有代码
要结束程序,请按ESC,或者ctrl+c
import cv2
import matplotlib.pyplot as plt
import mediapipe as mp
import time
import numpy as np
mp_pose = mp.solutions.pose
mp_drawing = mp.solutions.drawing_utils
mp_drawing_styles = mp.solutions.drawing_styles
colorclass = plt.cm.ScalarMappable(cmap='jet')
colors = colorclass.to_rgba(np.linspace(0, 1, int(33)))
colormap = (colors[:, 0:3])
def draw3d(plt, ax, world_landmarks, connnection=mp_pose.POSE_CONNECTIONS):
ax.clear()
ax.set_xlim3d(-1, 1)
ax.set_ylim3d(-1, 1)
ax.set_zlim3d(-1, 1)
landmarks = []
for index, landmark in enumerate(world_landmarks.landmark):
landmarks.append([landmark.x, landmark.z, landmark.y*(-1)])
landmarks = np.array(landmarks)
ax.scatter(landmarks[:, 0], landmarks[:, 1], landmarks[:, 2], c=np.array(colormap), s=50)
for _c in connnection:
ax.plot([landmarks[_c[0], 0], landmarks[_c[1], 0]],
[landmarks[_c[0], 1], landmarks[_c[1], 1]],
[landmarks[_c[0], 2], landmarks[_c[1], 2]], 'k')
plt.pause(0.001)
#端口号一般是0,除非你还有其他摄像头
#使用本地视频推理,复制其文件路径代替端口号即可
cap = cv2.VideoCapture(0)
with mp_pose.Pose(
min_detection_confidence=0.5,
min_tracking_confidence=0.5,
model_complexity = 1) as pose:
fig = plt.figure()
ax = fig.add_subplot(111, projection="3d")
while cap.isOpened():
success, image = cap.read()
if not success:
print("Ignoring empty camera frame.")
# If loading a video, use 'break' instead of 'continue'.
continue
# To improve performance, optionally mark the image as not writeable to
# pass by reference.
start = time.time()
image.flags.writeable = False
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
results = pose.process(image)
# Draw the pose annotation on the image.
image.flags.writeable = True
image = cv2.cvtColor(image, cv2.COLOR_RGB2BGR)
mp_drawing.draw_landmarks(
image,
results.pose_landmarks,
mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=mp_drawing_styles.get_default_pose_landmarks_style())
end = time.time()
fps = 1 / (end - start)
fps = "%.2f fps" % fps
#实时显示帧数
image = cv2.flip(image, 1)
cv2.putText(image, "FPS {0}".format(fps), (100, 50),
cv2.FONT_HERSHEY_SIMPLEX, 0.75, (255, 255, 255),3)
cv2.imshow('MediaPipe Pose', image)
if cv2.waitKey(5) & 0xFF == 27:
break
if results.pose_world_landmarks:
draw3d(plt, ax, results.pose_world_landmarks)
cap.release()
六、写在最后
如果有任何问题,欢迎在评论区讨论、赐教。

















 151
151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









