







DDD 实践手册(1.Get Started)
近几年随着微服务的流行,领域驱动设计(Domain-Driven Design) 重新回到了主流视野中。我自己最早是在大约 2003 ~ 2004 年左右了解到 DDD 的概念,之后一些金融行业的业务系统中尝试运用了 DDD 的理念进行系统设计,期间的确感受到了 DDD 与其他架构设计不同之处,但也遇到了不少问题。之后的几年中,我的工作内容逐渐转移到了互联网行业以及与数据相关的工作,在项目中也不太有机会使用 DDD。不过凑巧的是最近的一个项目中,我重新回到了我比较熟悉的金融核心系统研发的领域,而客户的需求之一就是使用 DDD 对核心遗留系统进行重构与拆分。在经过了 10 年之后,无论是技术还是业务都发生了不少的变化,而我自己对系统架构与设计也有了新的认识,重拾 DDD 这把扳手对我而言发生了有趣的化学变化,促使我对以前的一些概念与解决方案做了细致的梳理,也因此有了这个系列的文章。
我希望通过这个系列的文章不仅回顾 DDD 核心的知识与概念,还能够分享我在实际项目中遇到的问题与对应的解决方案。我比较认同的一个观点是架构师最大的工作是做出取舍,也就是在技术,业务价值之间找到 trade-off。所以我在项目中给出的方案不一定是最优的,也不一定适合你的项目,但是我会把「为什么」这样做告诉你,接着就是你怎么在自己的项目中进行取舍了。
Why DDD
在开始详细分析 DDD 之前,我们先看一下 DDD 尝试解决什么样的问题。DDD 的相关文章与书籍中,被提及最频繁的关键字一定非「复杂性」莫属。对于复杂性的概念,我们先不展开讨论,把它的定义限定在所谓的「业务系统」的范围,那么「业务系统」又是个什么系统呢?说白了你可以认为就是个基于关系型数据库的 CRUD 系统 ?
**既然「业务系统」无非是对关系型数据库做 CRUD,那么复杂性体现在哪呢?**我的答案是:体现在繁琐的业务规则,以及未来不可知的业务变化。这么说你肯定觉得等于没说,所以我来举个栗子。很大概率你有过买保险的经历,不一定是你买,很可能是你父母为你购买保险,那么你购买保险在保险核心业务系统中是怎么实现的呢?
你想购买保险的这个行为称之为「投保」,而保险公司接受你「投保」请求,并出具保险单的行为称之为「承保」,简略描述从投保到承保的过程大致需要经历以下这些步骤。首先系统需要判断你投保的是个人保险,还是团体保险,这两个走的是两个截然不同的流程,这里我们只说个人保险的流程。对于个人保险,系统先要进行「核保」的流程,你可以认为是审核你有没有资格购买某项保险。而核保的规则一般分为基础规则与产品相关的规则。基础规则一般检查你的身份,国籍,年龄等信息,例如一定是本国公民,且已经成年等。而产品相关规则则是按照你需要购买的保险产品而定义的专有规则。
现在又提到了「保险产品」这个概念,保险产品按照不同的维度有不同的区分方式,例如按照保障期限划分,有极短期险,短期险,长期险和所谓的终身险。按照保障范围(国内一般称之为「责任」),会分为医疗,意外,重疾,寿险等。还有些特殊的产品,例如万能,投连,年金等。这些产品的核保规则都是不同的,可能对于你现在的职业,年收入,健康状态都有不同的要求。
在通过核保之后,就需要按照你的个人状况计算费率,也就是你应该缴纳的保险费用。计算费率的过程也很有意思,一般分为表定法与公式法。顾名思义,公式法最好理解,就是由保险公司的精算部门定义一个费率公式,把变量带入之后计算即可。而表定法是通过一张称为「费率表」的东西来计算费率,具体计算逻辑我就不谈了,你只需要知道每种保险产品都有自己对应的费率表或是公式。
计算费率的过程中需要来自各方面的信息,例如被保人的年龄,职业类型,缴纳保费的方式(一次性缴清,或是分期缴纳,称之为趸缴与期缴)等等。计算出保费之后还需要计算代理人(就是介绍你买保单的那个人)佣金,这也是个非常冗长的流程。之后还有大段的流程,例如生成财务的收费记录,各种单证,打印记录等。
写到这我就不继续了,再写下去就变成保险系统的科普文了,但是你可以发现上述的流程有两个特点:
1.涉及的节点非常多,且计算的逻辑牵涉到很多变量,且有很多的分支判断;
2.牵涉到很多专业术语;
事实上我已经省略了很多业务规则,如果你被要求实现这样一个核心业务系统(承保只是保险核心业务系统中一个功能,一般属于「新契约」模块),你该如何开始设计工作?以及怎么做设计工作?
DDD 的核心价值就是解决这类复杂系统的设计(至少它是这么宣称的),如果你能理解并掌握 DDD 的话,在面对一个复杂的业务系统需求时应该能够给出一个合理,可行,具备可维护性与扩展性的设计方案。是不是很值得期待?那么我们继续往下看,DDD 是怎么做到这一点的。
分层
「分层」是广大工程师最熟悉的架构模式之一,特别是对使用 Java 的 CRUD Boy 而言,分层架构是伴随着 Java EE 一路走来的。在 DDD 中也引入了分层的概念,只是与传统的三层架构不同,将中间我们一般称之为 Business Logic Layer 的那层分为了 Application 与 Domain 两层,如下图:

对于分层 Eric Evans 的书中给出了一些说明,首先每一层只能依赖自己以下那一层的服务,而不能调用上一次的服务。可以理解为层与层之间的依赖关系是单向的,是自上而下的。其次 Application 与 Domain 是实现业务规则的核心,它们不应该依赖于某个特殊的框架或是技术,在 Java 中你的 Application 与 Domain 应该由 POJO 实现(Plain Old Java Object, 即普通的 Java 对象)。
Eric Evans 的书中给出了一些指导意见,但并没有给出相关的参考实现,那么问题就来了,项目中到底怎么实现分层?有的人会说这还有什么难的,不就是按照层级建几个 package 吗?其实问题的核心是如何管理层与层之间的交互。一些简陋的做法就是通过划分 VO(Value Object) ,PO(Persistent Object) 在几个层之间进行传递,但这远不是合理的分层架构实现。
我们先来看一个分层的参考实现,"The Clean “Architecture” 即整洁架构:

DDD 实践手册(2. 实现分层架构)
项目的目录结构

上图是项目的第一层目录,分为 application,domain,facade,infrastructure 四个部分。接下来分别介绍这四个层的作用。
Application Layer
英 [ˌæplɪˈkeɪʃn ˈleɪə®] 美 [ˌæplɪˈkeɪʃn ler]
应用层;应用层应用层;应用程式层;应用程序层;第七层 应用层
application 对应了 DDD 中的「应用层」,同时也对应了 Clean Architecture 中的 Application Business Rule。从项目中的实践而言,它作为「粗粒度」业务的入口,也有人喜欢称之为一个 Use Case。在这一层中不应该包含复杂的业务规则,而是对下层的 domain (领域层)进行协调,对业务逻辑进行编排。需要注意的是这一层只应该依赖于下层的 domain 层与 infrastructure 层。
我们再看一下 application 内部是怎么划分的:
dto 目录存放了的是 application 对上层暴露服务所接受的参数类型,也就是大家熟悉的 Data Transfer Object。
service 目录则是之前提到的「粗粒度」的服务接口,这些服务需要做的就是按照业务逻辑将 dto 对象转化为 domain 层的领域对象,并调用相关领域对象的方法完成业务逻辑。如果需要还会调用 infrastructure 的服务。再次强调,这部分的服务不应该涉及到复杂,核心的业务逻辑。

Domain Layer
英 [dəˈmeɪn ˈleɪə®] 美 [doʊˈmeɪn ler] 域层
domain 是 DDD 的核心层,具体的目录结构如下:

domain 之下的是名为 bc1 的目录,这里指代项目中某个业务的 Bounded Context(限界上下文),关于 BC 的概念会在后续的文章中详细讲解。在 bc1 之下的才是详细的领域分层。
- exception 目录中定义了领域层相关的异常,即一般称之为的 BusinessException,代表违反某些业务逻辑的异常,例如账户余额不足等。
- model 目录中定了领域对象,一般建议使用「充血模型」进行建模。
- repository 中定义了领域对象对应的「仓库」,关于 Repository 的概念也会在后续文章中专门讲解。
- service 则是定义了「领域服务」对象,如果认为 model 定义了业务模型,是名词,那么领域服务就是动词。
- event 目录。在一个完整的领域模型中,我们往往需要划分多个不同的 Bounded Context,但是不同的 BC 之间应该怎么交互呢?Eric Evans 的书中提供了集中不同的解决方案,例如自定义
DSL,防腐层等。而在我们具体的项目中,我们更倾向于使用基于「领域事件」的交互方式,这样不仅不会破坏各个 BC 间的封装,也移除了各自间的耦合。producer 中是事件的发送方,handler 是具体处理事件的对象。关于领域事件也会在后续专门介绍。
Facade Layer
英 [fəˈsɑːd ˈleɪə®] 美 [fəˈsɑːd ler] 外观层
facade 是整个系统对外暴露服务的部分,具体目录结构如下:
系统对外暴露两种协议的服务,即 RESTful 风格的 API 与 Web Service,对应的实现分别在 rest 与 ws 目录下。facade 层的工作是基于协议对客户端提供的数据进行校验,然后将数据转化为 application 层所需的 dto 对象,并调用 application 提供的服务。facade 中不应该有任何的业务规则与逻辑,只是完成数据对象的转换。
Infrastructure Layer
英 [ˈɪnfrəstrʌktʃə® ˈleɪə®] 美 [ˈɪnfrəstrʌktʃər ler] 基础设施层;基础层;基础建设层。
Infrastructure 层主要负责提供底层的纯技术服务,具体目录结构如下:

这一层的功能都比较直白,是大家熟悉的具体技术实现,与领域模型没有任何的依赖关系,这里就不再赘述了。
问题与思考
以上是我们实际项目中结合 Clean Architecture 与 DDD 的分层实现,它的好处很明显,能够比传统的三层架构更好的兼顾领域层的隔离,整个的依赖关系也非常清晰明了,方便开发人员理解,所以我着重谈一些遇到的问题与思考。
繁琐的数据对象转换
从系统的分层架构来看,一共有三种类型的数据对象,分别为 `DTO,Domain,PO(Persistence Object)`。
在实现一个业务功能时往往发生多次数据对象的转换,且大部分时间都是 getter 与 setter 的操作,非常的冗繁。
为了解决这个问题我们引入了 Model Mapper 作为对象映射框架,省去了一些多余的代码。但是依然存在着另一个问题。考虑到 DDD 中的另一个概念: Aggregate(聚合),当从 PO 转换为 Domain 时,需要以 eager (渴望的;热切的;渴求的)模式从存储中加载所有的数据,相对而言丧失了延迟加载的优化特性。
模糊的 Module 与 Bounded Context
在 DDD 理论中 Module 与 Bounded Context 是不同的东西,在上述的分层架构中,领域层有着明确的 BC 划分,但是在其他层却没有这些。最直接的现象就是随着系统功能的逐渐增加,业务规则日益复杂,application 目录下 dto,service 下的类会越来越多,由于缺乏进一层的抽象,导致后续的开发人员很难理解。
领域事件引入的事务问题
在引入领域事件之后,一部分的业务流程变为了异步调用,因此事务边界的管理变得更为复杂,在某些情况下无法达到事务一致性的要求。这无疑增加了开发者的心智负担,也提升了不少测试的难度。在这种情况需要进一步加深对业务的理解,尽量将事务特性从业务规则中移除或是绕开。
架构复杂性的提升
架构复杂性的提升带来的是开发人员学习的成本提升,在实践中,我们发现很多时候开发人员的代码中引入了错误的依赖关系,例如 domain 的方法签名中有来自于 dto 的对象,或是 facade 中引入了 domain 的领域对象。对于这种问题比较好的解决方案是加强 code review,加强开发人员对分层思想的理解,以及引入 Unit test your Java architecture - ArchUnit 这样的框架,在 CI 时对代码的依赖关系进行静态检查。
小结
本次介绍了项目中使用的 DDD 分层架构实现与遇到的问题,其实并没有一种完全正确或是适合任何项目的分层架构,掌握背后的思想与学会如何做出妥协才是一个架构师的工作。下一篇我会介绍项目中如何实现 Entity(实体),Value Object(值对象) 与 Aggregate(聚合)。
DDD 实践手册(3. Entity, Value Object)
上一篇我们介绍了如何在 Clean Architecture 与 DDD 的框架内划分一个项目的层级,而本篇文章中我们会聚焦在整个分层架构的核心部分,领域层中的关键概念: Entity(实体),Value Object(值对象)。
Entity 与 Value Object
当采用面向对象的设计方法对系统进行建模时,我们需要做的是从业务需求中找到那些关键的「业务对象」,而这些业务对象也是 DDD 中 Entity 与 Value Object 的基础。我们先来看一下 Entity 与 Value Object 有什么区别。
Entity 应该是我们在日常分析过程中最熟悉的部分,它也是业务逻辑的核心体现。它应该具备以下的特性:
* Entity 应该具唯一的「标识」
* 相比 Entity 所拥有的数据属性,我们更关注的是它的唯一「标识」
看一下我们的周围,我们的世界中充满了各种各样的 Entity。例如汽车就是一个 Entity,而它的唯一标识是「发动机编号」。iPhone 手机也是一个 Entity,「设备编号」则是它的唯一标识。需要注意的是在不同的业务场景中,同一个 Entity 的唯一标识是可能发生变化的,例如作为自然人,我们本身就是一个 Entity,在某些场景下,「身份证」就能作为我们的唯一标识。但是在另一些场景下则可能需要姓名,身份证,银行预留手机号这三个元素组成我们的唯一标识。
与之对应的 Value Object 顾名思义,关注的是数据,因为它并没有唯一标识,如果两个 Value Object
的数据都一样,那么我们可以认为这两个 Value Object 就是同一个对象。反观 Entity,差异就很明显,两个相同数据属性的 Entity 不一定是同一个对象,应该查看它们的唯一标识。
例如有着相同姓名的「张三」两个人,就是完全不同的两个人,因为他们的身份证号码是完全不一样的。
项目中大家一定接触过 Code Table,也就是俗称的「码表」,例如存放性别类型的「男」,「女」等,这就是一个典型的 Value Object。
我们再来总结下 Value Object 具备的特性:
* 没有唯一标识
* 我们更加关注于它的数据属性
在此基础上我个人会再引申两个特性,具体的原因之后会详细说明:
* Value Object 不会「单独存在」,而是附属于某个 Entity
* Value Object 的生命周期会与所附属的 Entity 绑定在一起
最后需要注意的是,相同的对象在某个业务场景下是 Entity,而在另一个场景下可能就是 Value Object 了,具体的例子我会在后面解释。
系统实现
了解了上述概念之后让我们看看如何在代码层面实现这两者。
有许多面向对象的设计理论可以用来指导我们发现业务需求中的 Entity,我觉得在前期不用太纠结于是否会遗漏某些 Entity,将专注点更多的集中在业务的核心流程上,特别是那些专业的业务术语。同时需要耐心分析的是 Entity 之间的关联关系,例如是 1 - N,还是 N - M。
结合 Eric Evans 书中的例子,我们分别看一下 Entity 与 Value Object 是怎样的。

上图是汽车作为 Entity 的类图,可以很清楚的看到,汽车本身有许多的属性,例如颜色,座位数量,舵位(左舵车还是右舵车),我们将「生产序列号」作为它的唯一标识。同时它关联的两个对象,一个为发动机,另一个则为轮胎。同样的,发动机也是一个 Entity,它有着排量,生产日期等属性,而它的唯一标识则是发动机编号。不同的是汽车所关联的轮胎对象,它是一个 Value Object。汽车的例子中我们并不关心轮胎是否具有业务的唯一性,我们认为凡是具有相同品牌与尺寸的轮胎都是相同。接着让我们看一个轮胎作为 Entity 的例子。
假设我们正在处理一个更换轮胎的业务流程,那么我们就需要区分每条轮胎之间的差异了,因为汽车所使用的四条轮胎很可能具备相同的属性,但是在修理过程中更换为另一条轮胎,所以我们必须能够区分彼此的不同。如上图所示,轮胎的类中还是具有品牌与尺寸的属性,但是作为 Entity 多了一个生产编号作为它的唯一标识,而它也关联了另一个 Entity,即生产厂商。
如果你依然有些迷惑,我们直接看一下这两种对象模型在数据库中的展现形式:
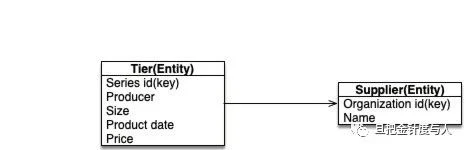


从数据库表结构的角度来看就很容易理解,Entity 有着自己的业务主键(实际项目中我推荐使用逻辑主键),而 Value Object 往往拥有一个指向所属 Entity 的外键,但是自己没有所谓的业务主键。图三则是 Value Object 的另一种映射方式,不用专门的表去映射一个 Value Object 对象,而是用 Entity 对应表上的几个字段(Car 表中 tier 开头的字段)。
Persistence Object - 持久化对象
上面提到了 Entity 与 Value Object 在数据库中的表现形式,现在我们再向上看一层,在 Java 中他们的存在形式又是如何的呢?此时我们有两个选择,是否需要引入 Persistence Object 即持久化对象(PO)。
PO 的概念是从 Hibernate(JPA) 等 ORM 框架中产生的,PO 是由这些框架管理的,数据库表在面向对象中的映射。我们先来看如果引入 PO 之后的好处与问题,参考下图:

引入 PO 的好处在于将 Entity,Value Object 等对象与持久化框架解耦,只需要使用 POJO 就能实现 Entity,Value Object,而无需引入第三方的接口。事实上 Eric Evans 的书中也提及到 Domain 层的对象应该保持简单,不依赖于任何的第三方外部框架。同时它还带来了额外的灵活度,可以按照不同场景的需求从持久层读取数据后组装不同的领域对象。
这也会带来另一些问题,其一是我们需要额外编写一部分 Entity,Value Object 等领域层对象与 PO 的转换逻辑。其二是在进行领域层对象组装时,需要完整读取所有 PO 的数据,不能进行延迟加载的优化,某些业务场景下可能存在隐藏的性能问题。
第二种方式是使用 PO 实现 Entity 与 Value Object,这也是一般项目,或是 Hibernate,JPA 等推荐的方式。它带来的优点很明显,可以省去一层抽象,不用编写那些冗繁的数据对象转换代码。这种方式的限制同样明显,首先是领域层的对象会依赖于某个具体的持久化框架(需要增加特定的 annotation),其次是在引入 Aggregate(聚合)后,不同业务场景,或是 Bounded Context(限界上下文)中,如果需要不同粒度的 Entity 映射相同数据库表时就会变的很麻烦,这个例子我会在介绍 Aggregate 时具体描述。
从项目实施的经验上来看,我更加建议分开 Entity,Value Object 与 PO 的关系,毕竟数据转换代码是可以通过框架减少很多,性能也是可以优化的,但是依赖关系在项目变得越来越庞大之后是没有那么容易解开的。
小结
我们介绍了 DDD 中 Entity,Value Object 的概念与具体实现,下一篇会更加的深入介绍 Entity 的一种特殊形式,Aggregate(聚合),以及 Entity 的整个生命周期的管理,Factory(工厂) 与 Repository(仓库)的概念与实现。
DDD 实践手册(4. Aggregate — 聚合)
上一篇中介绍了 DDD 中的核心概念,Entity 实体与 Value Object 值对象的概念,以及如何在项目中实现它们。而本篇文章我会介绍 DDD 中另一个核心概念,Aggregate 聚合。
什么是 Aggregate ?
aggregate 英 [ˈæɡrɪɡət , ˈæɡrɪɡeɪt] 美 [ˈæɡrɪɡət , ˈæɡrɪɡeɪt]
adj.总数的;总计的 n.合计;总数;(可成混凝土或修路等用的)骨料,集料 vt.合计;总计
其实 Aggregate 是一种模式,在代码中实现的具体形式很简单,分为两部分,
首先是定义一个 Entity,作为 Aggregate Root,一般称之为聚合根。
第二部分则是遵循 Aggregate 的完整性规则对领域数据进行操作。
在开始介绍具体的实现之前,我们先思考一下为什么要使用 Aggregate 这样的模式,它到底能为我们解决什么样的问题。
设想有这样一个业务场景,「客户增加保额」。从代码实现的角度来说,你可以这么做: 通过「保险单号」获取客户的保单信息,进而获取对应的保险产品信息,然后修改对应的「保额」,接着修改需要缴纳的「保费」,最后需要更新「被保险人」的信息。这样的需求实现起来其实不难,如果考虑使用 DDD 的方式,我们会设计 3 个不同的 Entity 对象,即保单(Policy),保险产品(Product),以及被保人(Insured)。然后类似的代码可能如同下面那样:
policy.increaseInsuredAmount(xxxx);
product.changePremium(yyyy);
insured.updateBill();
这样的代码在功能上并没有什么不妥,但是从设计角度出发确是值得探讨的。从「客户增加保额」的实现来看,需要牵涉到多个 Entity 的数据更新,而上面代码的问题在于将这些数据更新的逻辑零散的暴露在代码中,当后续业务需求发生变化时,开发人员很难从代码上理解业务,从而造成遗漏与错误。
在设计方法或是 API 上,我们知道方法或是 API 的颗粒度不能太细,有时候需要设计一个粗粒度的方法,将实现的逻辑隐藏在这个方法之下,而不是暴露给客户端。当 Entity 的数据发生变化时,同样应该遵循这样的理念。在许多业务场景下,Entity 之间的数据都需要遵循一致性,在上面的示例中,当进行增加保额这项业务操作后,保单,产品,被保人这些 Entity 的数据状态应该是按照业务规则保持一致的,不应该出现保额增加,但是保费不变的情况。
那么 Aggregate 又是如何解决这个问题的呢?这就需要了解一下 Aggregate 的完整性规则了。
Aggregate 的完整性规则
所谓的完整性规则又由下面两点组成:
- 所有的代码只能通过 Aggregate Root,即聚合根这个特殊的 Entity 访问系统的 Entity,而不能随便的操作任一的 Entity。
- 每个「事务」范围只能只能更新一个 Aggregate Root 及它所关联的 Entity 状态。
接下来让我们逐一解释这两项规则。
首先看第一条,这点很容易理解,单纯实现的话也很简单。参考之前的示例,我们可以把「保单」对象作为 Aggregate Root,而「产品」与「被保人」都作为这个 Aggregate Root 内部的成员变量。对外暴露的也只有「保单」对象上的方法。修改后的类图如下所示:

而代码也变为:
policy.increaseInsuredAmount(xxxx);
而 policy 的 increaseInsuredAmount 方法的内部实现则是:
public void increaseInsuredAmount(BigDecimal insuredAmount) {
this.product.changePremium(yyyy);
this.insured.updateBill();
}
从代码中可以看到,我们不再逐个操作不同的 Entity 对象,而是只能通过 policy 对象完成整个业务逻辑,与业务规则相关的数据完整性则由作为 Aggregate Root 的 policy 对象保证。
在理解第一条规则的基础上,我们再来看一下第二条规则。第二条规则其实从字面意义上来说很好理解,就是在一个事务范围内,我们只能更新一个 Aggregate Root 以及和它相关的数据。为了简化问题,这里的事务特指是关系型数据库的事务。
但是这两条完整性规则会引出一些设计上的取舍,你必须在实际项目上想好如何解决这些设计问题。
Aggregate 的设计
当需要实现 Aggregate 模式时,你需要解决的第一个问题就是找个一个合适的 Aggregate Root。在这个问题上无论是 Eric Evans 还是其他有关 DDD 的书籍都没有给出一个明确的答案,它们都举了一些例子,但是缺乏一个清晰的方法论来帮助架构师设计 Aggregate Root。书中的建议是「既不能太大,也不能太小」,这其实说了和没说一样。如果 Aggregate Root 设计的过大,那么无论实现什么业务规则都要拼装相同的 Aggregate Root 对象,必然有很对代码是冗余无用的。但是如果设计的很小,例如每个 Entity 都是一个 Aggregate Root,那么就很难做到每个事务只能更新一个 Aggregate Root 的要求。
我在项目上的经验是设计初期,尽量控制 Aggregate Root 的大小,不要关联过多的 Entity,造成出现「上帝类」这样的 Entity。当发现业务逻辑发生变化,需要更新额外的 Entity 状态时再丰富 Aggregate Root 的关联关系。如果项目中将 Domain 与 PO 分离,在设计 Aggregate Root 时的优势就很明显,不需要和持久层的关系型数据结构相耦合,能够在 Repository 进行自由的装配。
而另一种设计 Aggregate Root 的方法则是最近几年兴起的「事件风暴」,作为一种方法论,它可以帮助架构师与业务人员一起从业务流程中找到那些适合作为 Aggregate Root 的对象。具体如何使用「事件风暴」我会在之后的文章中讲解。
第二个在设计上需要考虑的是在分层架构的哪个部分定义事务范围。按照之前我介绍的分层架构,建议将事务控制放在 application service 那一层,与一个业务用例的粒度保持一致。
实际项目中「每次事务只能更新一个 Aggregate」的限制会比较严苛,因为当你将事务控制放在 application service 那层时也就意味着每个用例只能更新一个 Aggregate,在这种限制下需要设计一个合理的 Aggregate 就很难了,有时甚至是不可能的。如果一定要在一个事务内更新多个 Aggregate 该怎么办呢?一般我建议有两种选择。
领域事件 — 最终一致性
这种是 DDD 书籍上推荐的一种方式,使用领域事件的方式将单个 Aggregate 更新的事件广播出去,有其他对应的 hadler 收到后更新自己负责的 Aggregate。由于打破了事务一致性,因此需要某种机制来保证多个 Aggregate 的数据一致性。
使用这种解决方案的问题在于需要引入事务最终一致性的解决方案,这无疑会增加系统的复杂性。其次如果单纯为了满足单个事务与 Aggregate 的限制而脱离业务规则写了很多处理事件的 handler,那么无疑有点舍本逐末,为了 Aggregate 而 Aggregate 了。
打破规则
第二种并不能算是什么解决方案,实现起来很简单,就是打破每个事务只能更新 Aggregate 的限制,在 application service 中的单个事务中可以更新多个 Aggregate。
但是这也不是完全没有限制的,我们依然要遵循只能通过 Aggregate Root 引用 Entity 的规则,并且控制 application service 中能够访问 Aggregate Root 的数量,按照项目经验 3 个以下是可以接受的。
小结
Aggregate 是 DDD 中非常重要且特有的概念,它对外封装了 Entity 数据一致性,由此也是系统代码层面对业务规则的最直接的体现。而从 Aggregate 开始,业务知识在分析中的价值也逐渐开始体现。如何设计一个粒度合理的 Aggregate 需要丰富的业务知识与系统分析经验,而且随着业务的发展 Aggregate 也应该不断的重构。
下一篇将会是 DDD 中有关领域对象的最后一篇,我会介绍如何在项目中如何使用 Factory 与 Repository 实现 Entity 生命周期管理,希望你不会错过。
DDD 实践手册(5. Factory 与 Repository)
之前的两篇文章中我们讨论了是领域的对象的核心概念,即什么是 Entity 实体与 Value Object 值对象。以及如何使用 Aggregate 聚合模式来封装 Entity,以保障它数据完整性。而本篇文章会讨论有关领域对象的最后一个部分,如何使用 Factory 工厂与 Repository 仓储模式来管理 Entity 的生命周期。
关于如何创建对象的思考
在 Java 语言中我们可以很容易的使用 new 关键字配合构造函数来创建一个对象。但是这样的做法比较简陋,容易存在一些潜在的问题。这也就是为什么在 Java 的经典著作 「Effective Java」中的开篇就建议大家尽量使用 Factory 工厂模式来创建对象,而不是直接使用 new 关键字。
对于领域对象亦是如此,一个领域对象应该由数据与方法组成,在领域对象被创建时,如何对数据做必要的初始化,以及 Entity 之间的关联关系都是值得思考的。
假设业务系统有个前端用来录入保险被保人的详细信息,而在后端负责处理业务的逻辑中需要将前端页面填写的数据存入关系型数据库中。按照之前文章中提及的架构,从前端的 HTTP 请求中获取相关的参数后需要在 application 那一层将数据转化为领域对象,一般是作为 Aggregate Root 的 Entity。
那么我们该如何创建一个新的 Entity 呢?当然使用 new 在功能上是可行的,但在实际项目中会有两个问题。
缺少封装
在 application 层中进行数据装配时会产生许多的重复代码。例如上述例子中初始化被保人信息时,需要将被保人作为一个 Aggregate,而它会关联保险产品,付费信息,联系方式等 Entity 或是 Value Object,如果每次在初始化被保人这个领域对象时,可能都需要写一堆的像下面这样的 getter / setter 方法:
Insured insured = new Insured();
insured.setPolicyProduct(xxxxx);
insured.setBillingInfo(yyyyy);
insured.setContactAddress(zzzz);
更糟糕的是这种通过 getter / setter 方式初始化数据很容易造成开发人员的错漏。当一个对象结构较为复杂时,开发人员很容易遗忘调用某个 setter 方法而导致创建了一个数据不完整的 Aggregate。
可能稍好一点的方式是不用 getter / setter 方法,而是将这些关联对象作为构造函数的参数传进去,在构造函数中完成数据结构的装配。这从某种程度上解决部分的问题,但是它依然存在缺陷。
缺少业务语义
如同上面所说的,我们可以通过构造函数来保证 Aggregate 数据初始化的完整性。但是这种方法带来了第二个问题。想一下,在不同业务场景下 Aggregate 初始化所需要的参数可能是不同的,如果通过自定义构造函数的方式来控制数据初始化,那就需要定义多个参数不同的构造函数,即所谓函数重载(Overload)。例如这样:
public class Insured {
public Insured(PolicyProduct product) {
……
}
public Insured(PolicyProduct product, BillingInfo billingInfo, ContactAddress contactAddress) {
……
}
}
上述两个构造函数有着不同的参数列表,应该在不同的业务场景中使用,但是因为方法名是相同,无法表达业务含义,因此开发人员还是无法确定到底应该使用哪一个都早函数进行数据初始化。
Factory Pattern
为了解决这个问题,DDD 比较推荐的一种方式使用经典的 Factory Pattern(工厂模式)。工厂模式作为最简单的设计模式之一,被广大的开发人员所熟知,在 GOF 的书中,工厂模式也是第一个介绍的设计模式。简单来说,工厂模式通过一个特定方法,封装了对象数据初始化的逻辑。而这个方法其实就是个普通的方法,因此可以自由的定义方法名,而不必像构造函数那样受限,所以可以自由的表达业务含义。在项目中具体的实现方式也有两种选择,让我们依次来看一下。
由领域服务提供的 Factory Method
我们之前在分层架构中提到过领域服务的概念,如果说领域对象从某种程度上代表了领域知识中的名词,那么领域服务就对应了动词。我们可以在领域服务中定义所需要的方法来返回一个 Aggregate。
public class PolicyIssueService {
public Insured createInsuredFrom(PolicyProduct product, BillingInfo billingInfo, ContactAddress contactAddress) {
……
}
}
上述的代码中我们定义了一个领域服务类,用来实现新保单承保的逻辑,其中的方法 createInsured 会返回一个 Insured 的实例,这就是我们定义的用来创建 Aggregate 的工厂方法。通过这样在领域服务中定义专门的方法,可以很好的封装领域对象的初始化逻辑,保证数据完整性的同时也不丢失业务含义。
由另一个 Aggregate 提供的 Factory Method
除了在领域服务上定义相关的工厂方法之外,在 Aggregate 上也能定义专门的方法来管理另一个 Aggregate 或是 Entity 的初始化。我们通过一个保险业务上的例子来说明这种情况。当被保人发生意外,如果在保险单的保障范围内,可以申请理赔。在申请理赔时需要录入许多事故相关和保险单相关的信息,因此可以将理赔申请设计为一个 Aggregate。而初始化这个 Aggregate 的方法可以交给另一个 Aggregate,即保险单的 Aggregate。具体代码可参考如下:
//代表理赔申请的 Aggregate
public class ClaimApplication {
……
}
//代表保险单的 Aggregate
public class Policy {
//创建 ClaimApplication 的工厂方法
public ClaimApplication applyClaimWith(Accident accident) {
……
}
}
上面的方法很好理解,在 Policy 上有个方法,applyClaimWith,它接受一个事故信息 Accident 对象,返回另一个 Aggregate ClaimApplication 。当采用这种解决方案时,我们需要更多的分析领域对象之间的关系,在合理的对象上定义工厂方法,切忌在一个 Aggregate 上定义过多的工厂方法,这样也就丢失了相关的领域知识。
Repository Pattern
工厂模式能够帮助我们控制对象的初始化,这些对象创建之后还是处于内存之中,而作为一个业务系统不可避免的需要一种持久化的机制,能够将这些领域对象对应的数据存储起来,最常见的一种持久化机制就是关系型数据库。也由此我们可以看到,初始化对象数据来源并不仅仅来源于外部的输入,还可能来源于某种持久化机制。所以我们会引入领域对象生命周期的概念,参考如下的图片说明:

一些开发者可能会把 Repository 与 DAO 混淆在一起,由于 Spring JPA 这样的框架在命名方面把两者交织在一起,更加容易加深大家的误解。Repository 从字面以上来看更加偏重业务的含义,作为一个「仓库」它所要做的是将领域对象重新拿出来,但是不必关心底层的细节。例如我们是使用一种关系型数据库,还是 NoSQL 数据库,作为领域层其实是不关心的,它们关心的是领域对象是否被正确的还原出来。而 DAO 在实际项目中往往会更底层些,它抽象的是不同关系型数据库的异同,你可以使用 MySQL,也可以使用 Oracle,但是对于 DAO 层暴露的接口应该是相同的。我们来看一个具体的例子。
public interface InsuredRepository {
public void save(Insured insured);
public Insured findBy(Long id);
……
}
public interface ProductRepository {
public void save(Product product);
public Product findBy(Long id);
……
}
以上的代码中我们对两个领域对象,Insured 与 Product 定义了两个 Repository 接口,用以与某种存储机制进行交互。接下来看我们的实现。
public abstract class InsuredDBDAO implements InsuredRepository {
……
}
public class MySQLInsuredDBDAO extends InsuredDBDAO {
……
}
public class MongoDBProductRepository implements ProductRepository {
……
}
我们使用关系型数据库存储 Insured 的数据,同时为了保证不耦合到特定的关系型数据库,我们定义了一个额外的 DAO 抽象类,然后提供了基于 MySQL 实现的具体类。而在 Product 这方面,我们更希望使用 MongoDB 这样一个 NoSQL 存储数据,因此我们直接使用了一个具体的类实现了 ProductRepository 的接口。但是这两个接口在领域层暴露的几口都是一致的,所以需要牢记的是 Repository 是属于领域层的,而具体存储机制的实现,无论是 DAO 还是其他的实现,都应该属于 infrastructure 层,属于具体的实现机制。
小结
这篇文章中我们谈论了领域对象生命周期的概念以及如何使用 Factory 与 Repository 模式来管理,封装领域对象。如何在一个业务规则复杂的系统中保证领域对象数据的完整性是非常重要但也是困难的,因此希望通过这次的文章你能从中获得一些启发。下次我们会讨论 DDD 中另一个很重要的概念,限界上下文和对应的代码实现,希望你不会错过。
















 3901
3901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











