






 该研究提出了一种无需额外训练的零样本视频编辑方法,利用预训练的文本到图像扩散模型。主要包含视频反转、跨帧建模和空间正则化三个模块,旨在解决逐帧编辑导致的闪烁问题和视频编辑资源消耗大的挑战。实验表明,视频反转模块通过DDIM逆向和空文本优化提高对齐,跨帧建模模块增强时间一致性,空间正则化模块则保持视频与原始输入的保真度。然而,由于缺乏时间运动先验,模型在处理动态动作编辑时存在局限性。
该研究提出了一种无需额外训练的零样本视频编辑方法,利用预训练的文本到图像扩散模型。主要包含视频反转、跨帧建模和空间正则化三个模块,旨在解决逐帧编辑导致的闪烁问题和视频编辑资源消耗大的挑战。实验表明,视频反转模块通过DDIM逆向和空文本优化提高对齐,跨帧建模模块增强时间一致性,空间正则化模块则保持视频与原始输入的保真度。然而,由于缺乏时间运动先验,模型在处理动态动作编辑时存在局限性。
Zero-Shot Video Editing Using Off-The-Shelf Image Diffusion Models(基于现成图像扩散模型的zero-shot视频编辑)
motivation: 解决逐帧编辑图像编辑有严重闪烁效果以及视频训练占用大量资源的问题

contribution: 直接使用预先训练的文本到图像扩散模型的zero-shot视频编辑方法,无需任何训练
method
包含三个组件:
video inversion module(视频反转模块):用于文本到视频对齐
spatial regularization module(空间正则化模块):用于video-to-video保真度
cross-frame modeling module(跨帧建模模块):用于时间一致性
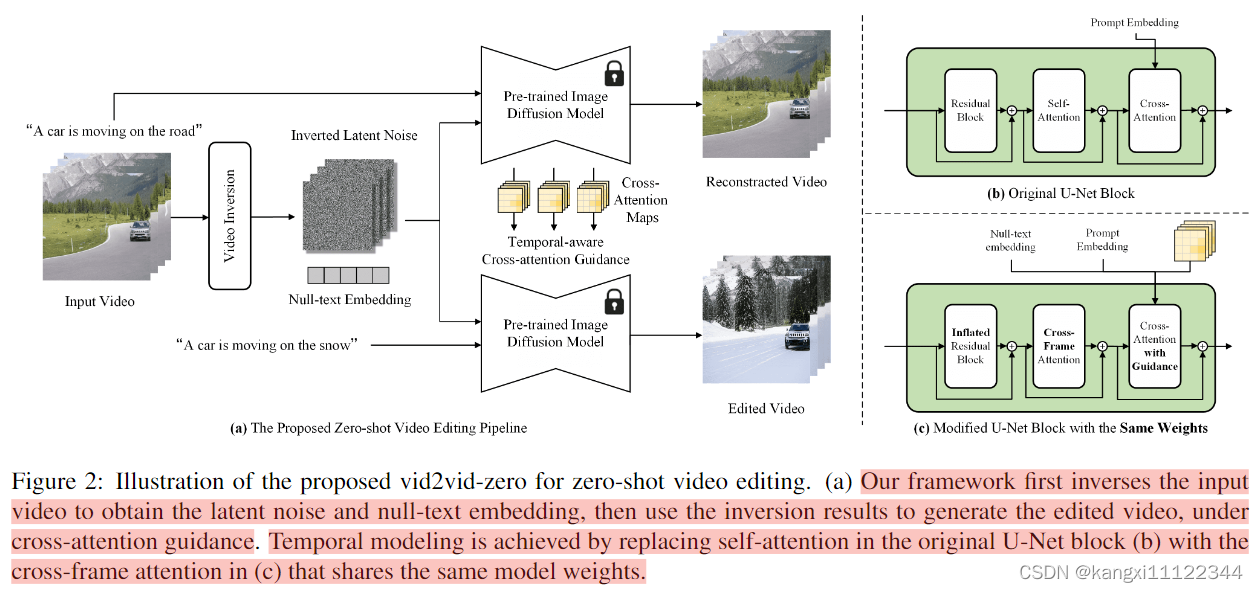
video inversion module(视频反转模块)
DDIM Inversion+Null-text Optimization(解决latent noise 无法与用户提供的文本描述c对齐的问题)
Null-text Optimization:解决latent noise 无法与用户提供的文本描述c对齐的问题
做法:优化一个null-text embedding
min
∅
t
∥
X
t
−
1
i
n
v
−
f
θ
(
X
‾
t
,
t
,
c
;
∅
t
)
∥
2
2
,
(1)
\min_{\varnothing_{t}}\left\|X_{t-1}^{\mathrm{inv}}-f_{\theta}\left(\overline{X}_{t},t,c;\varnothing_{t}\right)\right\|_{2}^{2},\quad\text{(1)}
∅tmin
Xt−1inv−fθ(Xt,t,c;∅t)
22,(1)
f
θ
f_{\theta}
fθ 表示DDIM采样,
X
‾
t
\overline{X}_{t}
Xt表示采样的latent code
为不同的视频帧共享相同的null-text embedding,以保持视频帧之间的一致信息
cross-frame modeling module(跨帧建模模块)
Q
=
W
Q
x
i
Q~=~W^{Q}x_{i}
Q = WQxi
K
=
W
K
x
1
:
T
K~=~W^{K}x_{1:T}
K = WKx1:T
V
=
W
V
x
1
:
T
V~=~W^{V}x_{1:T}
V = WVx1:T
spatial regularization module(空间正则化模块)
作用:保持对原始输入视频的保真度
重建过程中生成的cross-attention maps包含原始视频的空间信息
使用cross-attention maps作为空间正则化,并将其注入模型,迫使模型专注于与提示相关的区域。
z
^
t
=
ϵ
^
θ
(
X
^
t
,
t
,
c
^
;
∅
t
,
M
t
)
,
(
2
)
\hat{z}_t=\hat{\epsilon}_\theta\left(\hat{X}_t,t,\hat{c};\emptyset_t,M_t\right),\quad\quad\quad(2)
z^t=ϵ^θ(X^t,t,c^;∅t,Mt),(2)
experiments
ablation
不同模块的作用
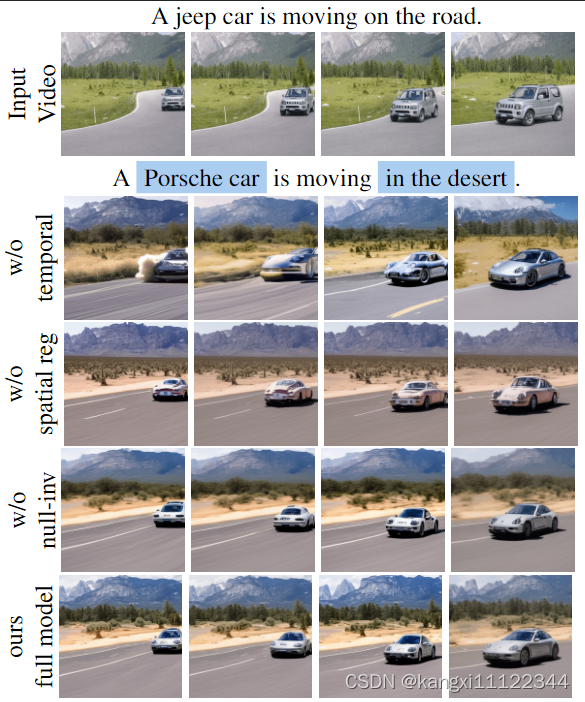
没有提出的temporal建模,前景汽车和背景山随着时间的推移都变得不一致
没有spatial attention guidance(空间注意力引导),编辑后的视频不够忠于原视频(车的颜色和树)
在没有null-text inversion的情况下,背景山和树变得模糊,因为优化的null-text embedding包含与输入视频对齐的细粒度细节
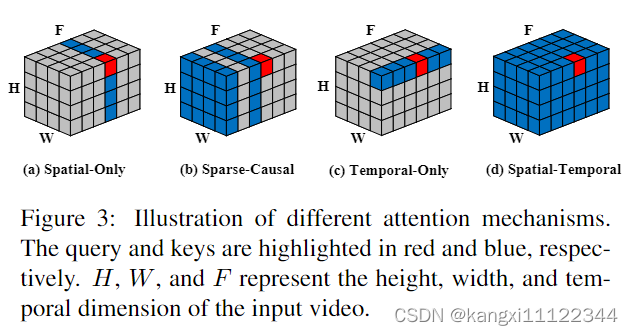
不同temporal attention

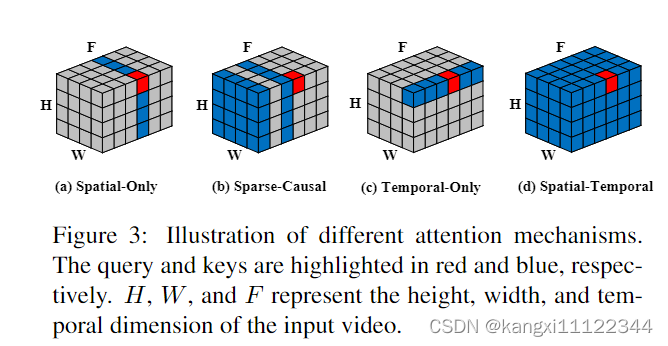
ours:dense spatial-temporal attention(密集时空注意力模块)
第一行:对应(b)前几帧视频变形,SC-Attention过分强调视频的前一帧,前几个视频帧中的编辑错误传播到后续帧,导致严重的伪影。
第二行:对应(c),只关注时间建模,忽视了其他空间位置。
limitations
直接使用图像扩散模型的预训练权重,因为现成的图像扩散模型没有在任何视频数据上进行训练,缺乏时间和运动先验,不能直接用于编辑视频中的动作,这反映在无法有效编辑prompt中的动词

















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









