







目录
一、研究背景
场景文本检测已广泛应用于在线教育、产品搜索、视频场景解析等领域。得益于深度学习技术,文本检测方法在文本为规则形状的图像上取得了很大的进展。近年来,因为任意形状文本检测能很好地适应实际应用,所以受到越来越多的关注。基于分割的方法引发了一波任意形状文本检测的浪潮,这一类方法通过像素级预测结果来分割出每个文本实例,很好地适应了文本形状的变化。但是基于分割的方法会有两个问题。第一个问题是基于分割的方法往往无法很好地分离图像中紧密相邻的文本实例,另一个问题是,现有的基于分割的方法中最终检测到的文本轮廓往往含有大量的缺陷和噪声。
二、研究的目的
任意形状的文本检查更适用于实际场景。
三、方法设计
1、网络结构
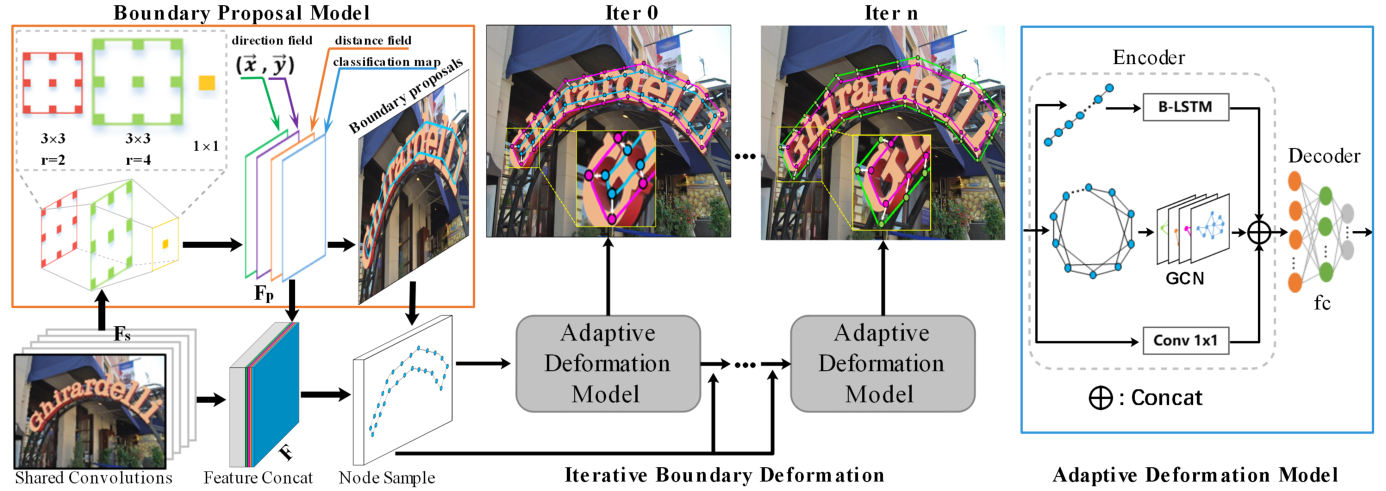
图1 TextBPN网络结果图
该网络结构包括以ResNet-50为骨干网络形成的类似FPN结构、边界建议网络和自适应边界形变网络三个部分:
1)特征提取(多层特征融合策略):在ResNet-50网络的多层卷积上通过上采样和拼接进行特征融合,生成共享特征 ;
2)边界建议模型:由多层膨胀卷积组成,包括两个不同膨胀率的3 x 3卷积层和一个1 x 1卷积层,使用共享特征生成分类图、距离场图和方向场图,即先验信息
;
3)自适应边界形变模型(编码解码网络):通过GCN和RNN对边界拓扑结构和序列上下文进行学习,通过迭代完成粗边框的细化。
(1) 特征提取(多层特征融合策略)
特征提取模块如图,基于ResNet50的类似FPN网络结构
输入:图片
输出:共享特征Fs

图2 共享卷积
(2)边界建议模块
输入:共享特征Fs
输出:先验信息Fp + 粗边界
边界建议模型由多层膨胀卷积组成,通过多层膨胀卷积获得分类图、距离场图和方向场图,具体如图3所示。
分类图包含每一个像素(文本/非文本)的分类置信度。
方向场图(V):为每个像素点预测一个向量,指向它离得最近得的边界上的像素点。由一个二维单位向量 组成,如图3(c)所示,表示边界内每个文本像素到边界上最近像素的方向,对于文本实例T中的每个像素 p,在文本框T上找到最近的文本边界像素
,然后计算每个像素的单位向
,文本实例T以外的像素在方向场中设置为(0, 0)。

距离场图(D):为每个像素预测一个值,是方向场图对应的向量的值的归一化后的,即表示文本像素p到文本框T上找到最近的文本边界像素点的归一化距离
, 文本实例T以外的像素在距离场中设置(0, 0)。 其中L表示像素p所在文本实例T的尺度,即取
最大值。通过距离和方向可以从当前点的坐标导出边界框的坐标。

![]()

图3 先验信息特征图展示
在边框建议模块中,有了距离场图(D),可以通过设定一个固定的阈值thd(0.3)来生成一系列候选边框建议,在图4中,原图(a)通过距离场图得到可能的文本框,但是存在错误的检测,如图(b)所示,再根据分类图来计算每个候选边框的平均置信度,当得到的Proposal score低于设定的置信度阈值ths(0.875)就进行舍弃,最终得到所有的建议文本框。

图4 粗文本框的生成示意流程图
(3 )自适应边界变形模块
输入:特征矩阵
输出:控制点预测的偏移量
本模块主要的功能是通过文本框中的拓扑结构和序列上下文进行学习,并预测指向文本边界的逐顶点偏移,对于获得的粗边框进行迭代细化调整,以得到真正的文本框实例(类似完成了后处理的功能),这部分结构主要是在编码器部分引入了GCN和RNN,同时有一个分支使用一个1 x 1的卷积层形成了类似ResNet的残差结构,如图5所示,最后在译码器部分使用带有ReLU的三层1 x 1的卷积组成。为了对候选框进行细化,论文通过迭代处理(源码中将该模块代码进行循环拼接了3次)。

图5 自适应边界变形模型
在得到建议候选框之后,需要得到坐标点,本论文中通过对建议候选框使用候选框进行边界选择,并按照周长划分为20个等长部分,分别取得20个坐标点,作为候选框坐标点。(在源码的训练中,是通过标注文本框生成的建议候选框20个坐标点来进行迭代训练)
而如图6所示,通过坐标点需要生成Node feature matrix来作为自适应形变模块的输入,具体操作如下:在图2中,可以看到,由CNN骨干网络获得的32-D共享特征Fs和通过多层空洞卷积得到的4-D先验特征进行concat一起组成cnn_feature,即F。同时结合20个坐标点在F中对应的位置提取每一个控制点(坐标点)的特征,最终得到了候选边界特征矩阵X(size:N x C)。

图6 整个自适应候选框形变网络流程示意图
2、损失函数
TextBTN网络的损失函数定义为
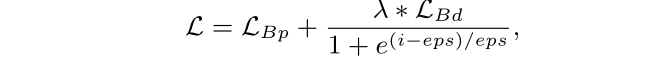
为总的损失,其中
为边框建议损失,
为自适应边界形变模型的损失,eps表示训练的最大epoch(200)数,而
设置为0.1,i 表示训练中的第 i 个时间。
包含像素分类的交叉熵分类损失
、距离场的L2回归损失
和方向场
的 L2 范数距离和角度距离组成
,而
=3:
![]()
为点匹配损失,主要是计算预测点和真实点之间的损失。p预测点集,p`为真实点集,因此每一个文本实例的损失为
,因为在一张图像中有多个文本实例,所以需要计算平均损失:

四 实验结果
1、消融实验
略
2、性能对比
略
















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











