









利用q-q plot检验样本数据分布
什么是q-q plot
在统计学中,q-q plot(又叫quantile-quantile plot)是一条曲线,利用这条曲线我们可以判断一个样本数据是否是从某个理论分布抽样而得。比如,我们想对某一个样本数据进行统计分析,并且假设这个样本数据来自一个正态分布(normal/Gaussian distribution),那么我们就可以用q-q plot来直观得检测这个假设,参考 [1]。
值得注意的是,q-q plot只为我们提供了一个目测样本数据是否来自某个理论分布的工具,并没有为我们提供一个严格意义上的证明。
具体来说,q-q plot是一个散点图。图的横坐标是一组数据的升序分位数(quantile),图的纵坐标是另一组数据的升序分位数。如果这两组数据都是从同一个理论分布中抽样所得,那么这个散点图就会近似于一条直线。如果散点图偏离直线较多,那么我们就可以认为这两组数据不是从同一个理论分布中抽样所得。如果我们只有一组数据并且想检测这组数据是否服从某个理论分布,那么我们的横坐标就选作这个理论分布的分位数的值。当然,我们横坐标的个数应该与纵坐标的个数相同。比如如果我们的样本数据有 n n n个,我们想检测这 n n n个数据是否是抽样自正态分布,那么我们的横坐标就选取标准正态分布的 n n n个分位点。
举例
检测正态分布(Normal distribution)
我们先生成一组服从正态分布的随机数,然后用q-q plot来检测这组数据是否服从正态分布。我们希望得到的q-q plot近似于一条直线。
Python代码如下:
import numpy as np
from scipy.stats import norm
from scipy.stats import uniform
import matplotlib.pyplot as plt
mu = 1 # expectation of the normal distribution
sigma = 1 # standard deviation of the normal distribution
N = 100 # number of data points
sample01 = np.random.normal(mu, sigma, N) # generate random numbers from N(0, 1)
sample01.sort() # sort sample01
x = np.linspace(0.01, 0.99, N)
normal_quantile = [norm.ppf(c) for c in x] # generatating the N(0, 1) distribution quantile values
# make the q-q plot
plt.figure(figsize=(8, 6), dpi=100)
plt.scatter(normal_quantile, sample01)
plt.xlabel("quantile values for standard normal distribution", fontsize=20)
plt.ylabel("sorted sample values", fontsize=20)
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
 我们看到得到的q-q plot近似为一条直线。在上面代码中
我们看到得到的q-q plot近似为一条直线。在上面代码中norm.ppf(q, loc=0, scale=1)是percent point function,用来求正态分布的分位数。默认的参数loc=0中loc为正态分布的期望(平均值),scale=1中 scale为正态分布的标准差。如果我们求标准正态分布的分位数,我们可以省略loc和scale,直接用norm.ppf(q)即可。
值得指出的是,如果我们知道 X ∼ N ( μ , σ 2 ) X \sim N(\mu, \, \sigma^2) X∼N(μ,σ2), 那么我们有 X − μ σ ∼ N ( 0 , 1 ) \displaystyle \frac{X - \mu}{\sigma} \sim N(0, \, 1) σX−μ∼N(0,1). 于是,如果我们已知标准正态分布的分位数 Z α Z_{\alpha} Zα,即 P ( Z ≤ Z α ) = α , 0 < = 1 < = α , Z ∼ N ( 0 , 1 ) \displaystyle P(Z \leq Z_{\alpha}) = \alpha, \, 0 <= 1 <= \alpha, \, Z \sim N(0, \, 1) P(Z≤Zα)=α,0<=1<=α,Z∼N(0,1)。如果我们须要求 X X X 的分位数,即 P ( X ≤ X α ) = α \displaystyle P(X \leq X_{\alpha}) = \alpha P(X≤Xα)=α。 利用 X − μ σ ∼ N ( 0 , 1 ) \displaystyle \frac{X - \mu}{\sigma} \sim N(0, \, 1) σX−μ∼N(0,1), 我们有 P ( X ≤ X α ) = P ( X − μ σ ≤ X α − μ σ ) = α \displaystyle P(X \leq X_{\alpha}) = P \left( \frac{X - \mu}{\sigma} \leq \frac{X_{\alpha} - \mu}{\sigma} \right) = \alpha P(X≤Xα)=P(σX−μ≤σXα−μ)=α,于是我们知道 X α − μ σ = Z α \displaystyle \frac{X_{\alpha} - \mu}{\sigma} = Z_{\alpha} σXα−μ=Zα。所以,一般正态分布 X X X的分位数 X α \displaystyle X_{\alpha} Xα 与标准正态分布的分位数 Z α \displaystyle Z_{\alpha} Zα同样存在一个简单的线性关系。这也就是为什么我们可以用标准正态分布的分位数来当作x-axis的数据,来对标我们须要验证的样本数据(y-axis)。
检测均匀分布(uniform distribution)
对于同样的数据sample01,如果我们想检测数据是否是从均匀分布
U
(
0
,
1
)
U(0, 1)
U(0,1)中抽样所得,那么我们的q-q plot中的横坐标取值应该为
U
(
0
,
1
)
U(0, 1)
U(0,1)的分位数。这时候的q-q plot就如下图所示。
uniform_quantile = [uniform.ppf(c) for c in x] # generatating the N(0, 1) distribution quantile values
# make the q-q plot
plt.figure(figsize=(8, 6), dpi=100)
plt.scatter(uniform_quantile, sample01)
plt.xlabel("quantile values for uniform distribution", fontsize=20)
plt.ylabel("sorted sample values", fontsize=20)
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
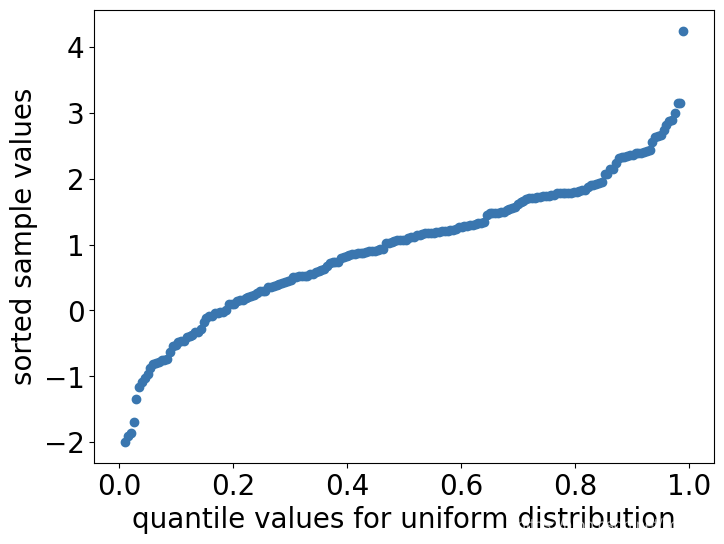
我们可以看到,这时的q-q plot偏离直线较多。因为我们的样本取自正态分布,而不是均匀分布。
如果我们从 U n i f o r m ( 0 , 1 ) \mathrm{Uniform}(0, 1) Uniform(0,1)分布中抽取样本,然后对这个样本做 U ( 0 , 1 ) U(0, 1) U(0,1) 分位数的q-q plot,则q-q plot如下图所示。
# Generate the random sample from a uniform distribution.
sample02 = np.random.uniform(0, 1, N) # generate random numbers from Uniform(0, 1)
sample02.sort() # sort sample01
# make the q-q plot
plt.figure(figsize=(8, 6), dpi=100)
plt.scatter(uniform_quantile, sample02)
plt.xlabel("quantile values for uniform distribution", fontsize=20)
plt.ylabel("sorted sample values", fontsize=20)
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
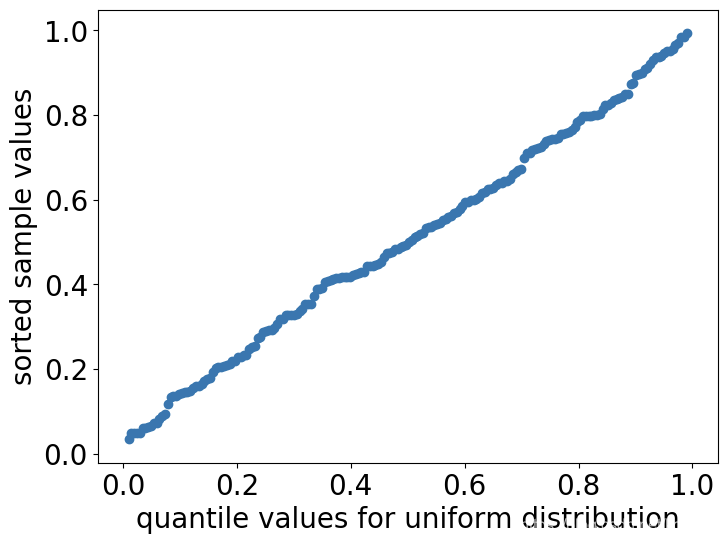
我们发现这时的q-q plot又接近于一条直线。
参考文献
[1] http://data.library.virginia.edu/understanding-q-q-plots

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









