










1. 摘要
尽管弱监督分割方法的精度有所提升,但是和全监督的图像语义分割的精度仍有很大差距,论文认为这种性能的差距主要来自弱/半监督方法在图像层次的监督下学习产生高质量密集像素点定位图能力的限制。论文为了消除这种差距,重新考量空洞卷积并将其应用到新方法中提升弱/半监督语义分割的性能。
首先论文发现不同空洞率的空洞卷积不但能够扩大核的感受野,更重要的是还能将环境的判别信息推广转换至类别不明确的区域。接着论文设计了一个通用的带有多个不同空洞率的卷积块以产生密集可靠的目标定位图,并且同时对弱监督和半监督的语义分割都有效的分类网络。论文在Pascal VOC 2012弱监督和半监督的测试集上都取得了state-of-art效果。[1.分别是60.8%和67.6%平均IOU;2.弱监督是知道数据和其对应的弱标签去学习强标签的方法、半监督是知道部分数据和其强标签去学习未知标签的方法]
2. 介绍
弱监督图像识别方法最大的优点在于不需要大量精细的人工标注,这些方法中从图像级别的标注中学习分割目标的方法收到了更多的关注,其中最大的需要应对的挑战在于如何精准地在像素级别定位目标的区域以获得高质量的目标边缘和如何改善分割模型的训练。
一些方法提出使用分类网络产生的特征图中的线索来获得目标位置的信息,但是这种方法只能映射到目标很小的一部分,并不满足分割模型进行密集预测和高效训练的需要。比如当前state-of-art方法CAM[Class Activation Mapping],在分割大的目标时在目标物体处不集中,如下图所示,其不足以从图像级别的标注中产生密集位置预测。

因此论文中提出将已经表明的区域的知识推广到相邻的不确定的区域以产生密集的目标定位预测。为了实现这个目标,论文重新思考空洞卷积,发现空洞卷积在扩张感受野的同时不会增加过多的计算代价,这种特性对于将已判明区域的指示推广至未判明相邻区域非常适合,由此文章设计了多空洞率的卷积块来增强标准的分类模型,如下图所示:
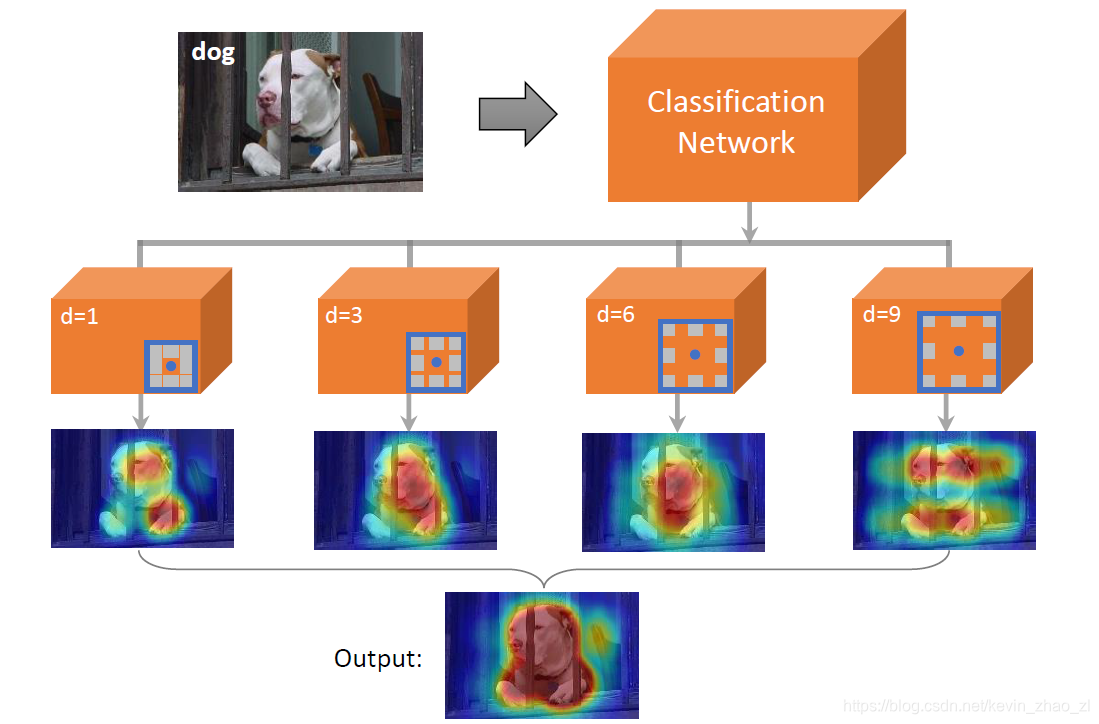
通常来说,分类网络能够识别一或多个热图相应程度较高的物体小区域,通过扩张感受野,低响应的区域能够通过相邻的高响应区域的语义信息提升自己的热图响应程度。论文利用CAM方法为每一个卷积块产生物体的定位热图[空洞率1],接着提高空洞率得到多个涉及物体的区域。
但是大空洞率中,真负的区域热图响应程度也很高,如下图所示,为了解决这个问题论文设计一个一个简单有效的抗噪音融合策略,这种策略能够有效的减少与物体不相关的区域被大空洞率卷积激活并且将多个定位图融合在一起得到高亮目标区域。

模型使用其产生的分割掩码图来进行训练,对于弱监督和半监督分割都适合。综上文章的主要贡献在于:
- 利用空洞卷积的特性,应对弱监督分割方法的要求
- 简单有效的通过相邻高响应区域提升低响应区域的响应程度
- 适用于弱监督和半监督的分割方法以及Pascal VOC 2012上的state-of-art平均IOU。
相关工作
实操的时候再研读~
- 使用粗糙标记进行分割
- 使用图像级别标注进行分割
3. 模型和方法
3.1 重新思考空洞卷积
现有的一些方法使用分类网络能够分割物体的部分区域,该论文进一步增强分类模型使其能够将判明区域的信息传送给邻近未判明区域来克服上面的问题。如下图所示,空洞卷积能够使信息传输:
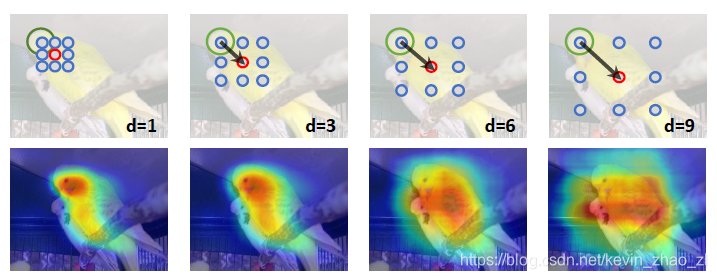
图片中鸟的头部是分类器给出的判明的区域,通过扩大空洞率,越来越多的区域也被判明。为了证明这个空洞卷积确实能提高热图中响应程度较低的区域的的分割效果,论文使用CAM产生了不同的定位图可以观察到在空洞率为1的定位图可以通过其他不同空洞率的卷积有效地提升响应程度。
3.2 多空洞率的卷积快以定位目标
由于3.1中的观察,论文提出了一个带有不同空洞率的空洞卷积模块[MDC blocks]来产生物体密集的位置预测,如下图所示:
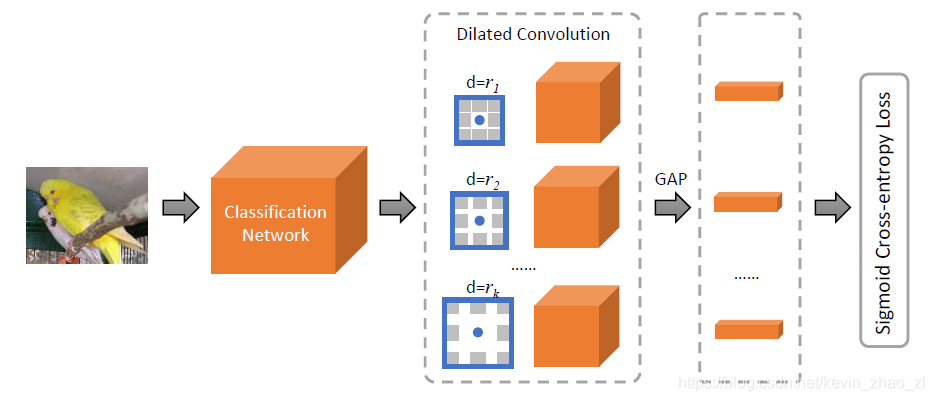
具体地,对主干网络VGG16的修改包括:
- 去掉后面的全连接层
- 去掉一个池化层
- MDC 块跟在conv5后
- 全局池化后进行经过一个全连接层进行图像级别的预测
- 使用sigmoid交叉熵损失函数优化分类网络
- 使用CAM方法为每一个卷积块产生热图
此外,MDC有两种不同的卷积操作: - 一是标准卷积,即空洞卷积率为1,通过这个得到精确的小区域的类别判明图,当然也有许多物体部分没有判明
- 二是多空洞率的空洞卷积来扩大感受野,将判明区域的信息传输给邻近未判明的物体区域
这样可能会导致许多不相关的区域被误判,所以模型选择了较小的卷积率,并且提出了一种简单有效的抗噪融合策略。
首先,从上面的观察中发现,真正例区域能够通过几个不同的热图确定,而不想关的真负例区域在不同热图中差别较大。所以我们先将3,6,9的热图求平均值然后和标准卷积的输出热图进行相加得到最终的定位热图,这样做不会丢失标准卷积的信息。
用形式化的额语言来讲即,使用 H 0 H_0 H0和 H i ( i = 1... n d , 其 中 n d 是 空 洞 卷 积 块 的 数 量 ) H_i (i=1...n_d,其中n_d是空洞卷积块的数量) Hi(i=1...nd,其中nd是空洞卷积块的数量)来代替不同卷积块产生的输出热图,最终的结果 H H H为:
H = H 0 + 1 n d ∑ i = 1 n d H i H=H_0+\frac{1}{n_d}\sum_{i=1}^{n_d}H_i H=H0+nd1i=1∑ndHi
得到 H H H之后,大于预设阈值 δ \delta δ的像素点被认为是前景,利用显著性检测的方法差生显著性热图将那些值较小的像素点视为背景,来训练模型。
3.3 弱监督和半监督分割的训练和学习
使用上面的方法产生的热图分别训练半监督分割模型和弱监督分割模型。
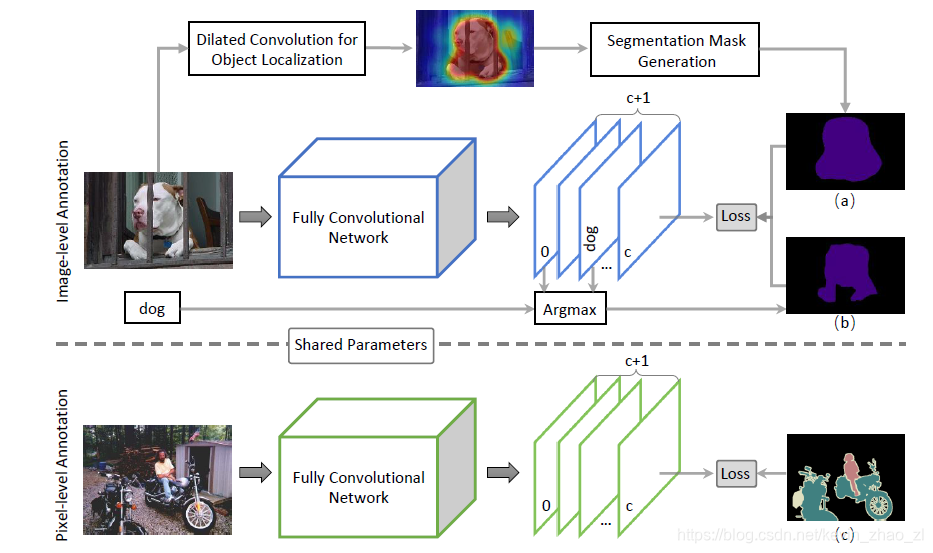
3.3.1 弱监督分割方法的学习
如图1上半部分所示,使用
i
w
i_w
iw表示弱监督训练集
I
w
I_w
Iw中的一幅图像,对于所有的
i
w
∈
I
w
i_w \in I_w
iw∈Iw,
m
w
m_w
mw是对应的伪掩码,即上面方法产生的密集位置预测热图,
C
C
C是包含背景信息的标签集合。
我们的目标是训练一个带有参数
θ
\theta
θ的分割模型(比如FCN)
f
(
i
w
;
θ
)
f(i_w;\theta)
f(iw;θ),这个模型计算在位置
u
u
u的每一个类别标签
c
∈
C
c \in C
c∈C的条件概率,得到一个类别信念图
f
u
,
c
(
i
w
;
θ
)
f_{u,c}(i_w;\theta)
fu,c(iw;θ)。使用
M
w
M_w
Mw代表
i
w
i_w
iw在线预测的分割掩码,这个掩码和
m
w
m_w
mw一起用于监督。用于优化弱监督FCN的公式为:
m
i
n
θ
∑
i
w
∈
I
w
J
w
(
f
(
i
w
;
θ
)
)
min_{\theta}\sum_{i_w \in I_w} J_w(f(i_w;\theta))
minθiw∈Iw∑Jw(f(iw;θ)),
其中,
J
w
(
f
(
i
w
;
θ
)
)
=
−
1
∑
c
∈
C
∣
m
w
c
∣
∑
c
∈
C
∑
u
∈
m
w
c
l
o
g
f
u
,
c
(
i
w
;
θ
)
−
1
∑
c
∈
C
∣
M
w
c
∣
∑
c
∈
C
∑
u
∈
M
w
c
l
o
g
f
u
,
c
(
i
w
;
θ
)
J_w(f(i_w;\theta))=-\frac{1}{\sum_{c \in C}|m_w^c|}\sum_{c \in C}\sum_{u \in m_w^c}log f_{u,c}(i_w;\theta)-\frac{1}{\sum_{c \in C}|M_w^c|}\sum_{c \in C}\sum_{u \in M_w^c}log f_{u,c}(i_w;\theta)
Jw(f(iw;θ))=−∑c∈C∣mwc∣1c∈C∑u∈mwc∑logfu,c(iw;θ)−∑c∈C∣Mwc∣1c∈C∑u∈Mwc∑logfu,c(iw;θ)
其中,|·|用于计算像素的数目。
通俗的来说,就是使用多空洞率空洞卷积网络从图片级别的标注的得到图1中的粗糙掩码a,用作监督信息;作者还用一个正在训练的模型在线预测一个掩码b来辅助a,但在文章中没有验证这一项的作用。
3.3.1 半监督分割方法的学习
图1中的下半部分是半监督分割的学习过程,即使用少量精细的标注图来训练模型。通过共享弱监督模型的参数结合少量的强标记的掩码来提升分割的性能。
使用
i
w
i_w
iw表示强监督训练集
I
w
I_w
Iw中的一幅图像,对于所有的
i
w
∈
I
w
i_w \in I_w
iw∈Iw,
m
w
m_w
mw是人类的标注,半监督的损失函数如下所示:
m
i
n
θ
∑
i
w
∈
I
w
J
w
(
f
(
i
w
;
θ
)
)
+
∑
i
s
∈
I
s
J
s
(
f
(
i
s
;
θ
)
)
min_{\theta}\sum_{i_w \in I_w} J_w(f(i_w;\theta))+\sum_{i_s \in I_s} J_s(f(i_s;\theta))
minθiw∈Iw∑Jw(f(iw;θ))+is∈Is∑Js(f(is;θ)),
其中,
J
s
(
f
(
i
w
;
θ
)
)
=
−
1
∑
c
∈
C
∣
m
s
c
∣
∑
c
∈
C
∑
u
∈
m
s
c
l
o
g
f
u
,
c
(
i
s
;
θ
)
)
J_s(f(i_w;\theta))=-\frac{1}{\sum_{c \in C}|m_s^c|}\sum_{c \in C}\sum_{u \in m_s^c}log f_{u,c}(i_s;\theta))
Js(f(iw;θ))=−∑c∈C∣msc∣1c∈C∑u∈msc∑logfu,c(is;θ))
4.实验
4.1数据集和设置
数据集和评估矩阵Pascal VOC 2012分割数据集,进行数据增广。仅使用图像级别的标签作为监督,和其他state-of-art方法进行对比,结果都输入验证服务器得到结果。
训练和测试集设置使用预训练的VGG16初始化除了MDC之外的分类网络。分割部分使用DeepLab-CRF-LargeFOV模型作为基础网络,参数也由VGG16初始化。mini-batch 30;321x321 pixels+随机切割;epochs 15;lr 0001;
4.2对比
4.2.1 弱监督语义分割
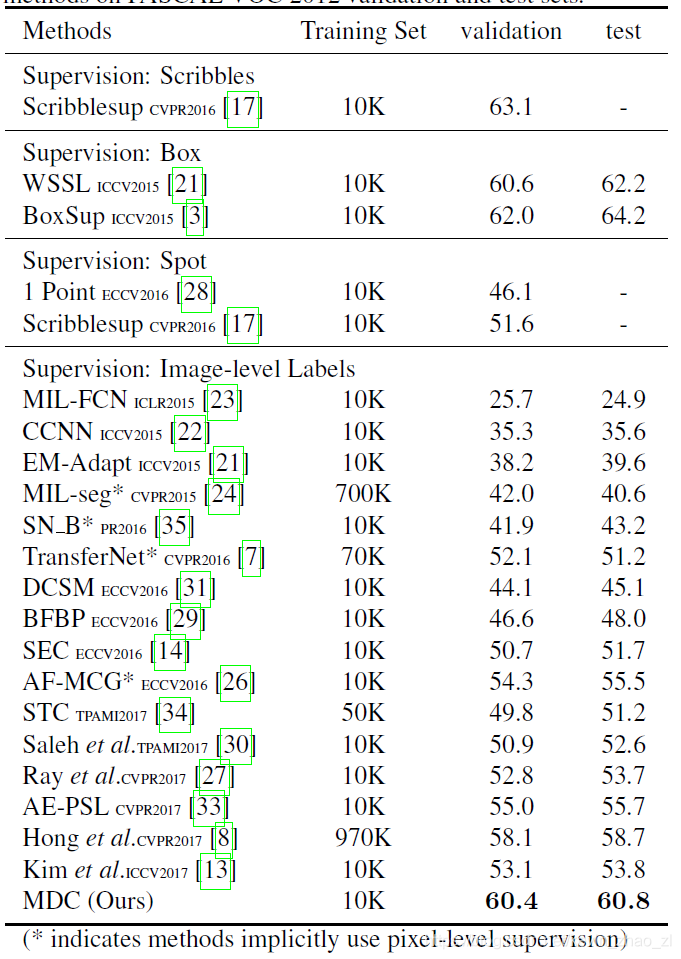
4.2.2 半监督语义分割

4. 结论
该篇论文重新思考空洞卷积提出MDC块来产生物体位置的密集预测。方法易于实现,训练对于弱监督和半监督的方法都比较简单。但是最终在二者都取得了state-of-art效果。未来的方向在错误判别方向上的纠正和应用在大规模数据集上的效果。
欢迎扫描二维码关注微信公众号 深度学习与数学 [每天获取免费的大数据、AI等相关的学习资源、经典和最新的深度学习相关的论文研读,算法和其他互联网技能的学习,概率论、线性代数等高等数学知识的回顾]
















 9660
9660











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









