







 本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅!
本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅! 个人主页:有梦想的程序星空
个人主页:有梦想的程序星空 个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。
个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。- 关注微信公众号【有梦想的程序星空】,了解软件系统和人工智能算法领域的前沿知识,让我们一起学习、一起进步吧!
PPO(Proximal Policy Optimization)是一种用于策略优化的强化学习算法,由John Schulman等人在2017年提出,旨在提高训练的稳定性和效率。它的目标是找到一个策略,使得根据这个策略采取行动可以获得最大的累积奖励。
传统的策略梯度方法在每次更新策略时,可能会因为更新步长过大而导致策略崩溃,训练过程难以收敛。而 PPO 算法则通过引入一个“代理”目标函数,将策略更新限制在一个较小的范围内,从而避免了这个问题。
PPO算法论文:Proximal Policy Optimization Algorithms
TRPO是PPO的前身,叫做信任区域策略优化(Trust Region Policy Optimization),当策略网络是深度模型时,沿着策略梯度更新参数,很有可能由于步长太长,策略突然显著变差,进而影响训练效果。针对这个问题,TRPO考虑在更新时找到一块信任区域(trust region),在这个区域上更新策略时能够得到某种策略性能的安全性保证,TRPO 的公式如下所示:
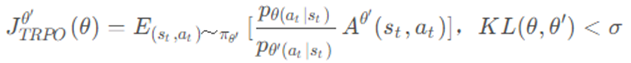
TRPO相当于给目标函数增加了一项额外的约束(constrain),而且这个约束并没有体现在目标函数里,在计算过程中这样的约束是很难处理的。
PPO 是 TRPO 的一种改进算法,它在实现上简化了 TRPO 中的复杂计算,并且它在实验中的性能大多数情况下会比 TRPO 更好,因此目前常被用作一种常用的基准算法。
PPO 算法可依据 Actor 网络的更新方式细化为:
- 含有自适应 KL-散度(KL Penalty)的近端策略优化惩罚(PPO-Penalty)
- 含有Clippped Surrogate Objective函数的近端策略优化裁剪(PPO-Clip)
近端策略优化惩罚(PPO-Penalty)
PPO-Penalty基于KL散度惩罚项优化目标函数,其目标函数如下:
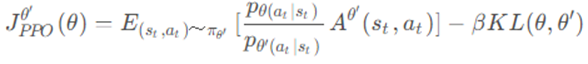
上面的式子我们可以理解为:训练一个累计回报期望更高但是又和θ'很像的θ。在实际中,我们会动态改变对θ和θ'分布差异的惩罚,如果KL散度值太大,我们增加这一部分惩罚,如果小到一定值,我们就减小这一部分的惩罚。
近端策略优化裁剪(PPO-Clip)
PPO算法还有另一种实现方式,PPO-Clip不将KL散度直接放入似然函数中,而是进行一定程度的裁剪,其目标函数如下:
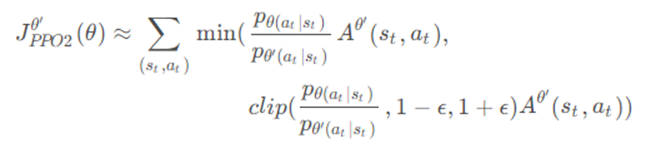
PPO-Clip的目标是在优化策略的同时,控制策略更新的幅度,以避免更新过大导致策略发生剧烈变化。这可以提供算法的稳定性,并且有助于收敛到一个比较好的策略。PPO-Clip 使用剪切函数来确保新策略更新不超过一个预定的范围,从而避免了过大的策略变化。这可以防止策略的不稳定性和发散,同时保证算法的收敛性。
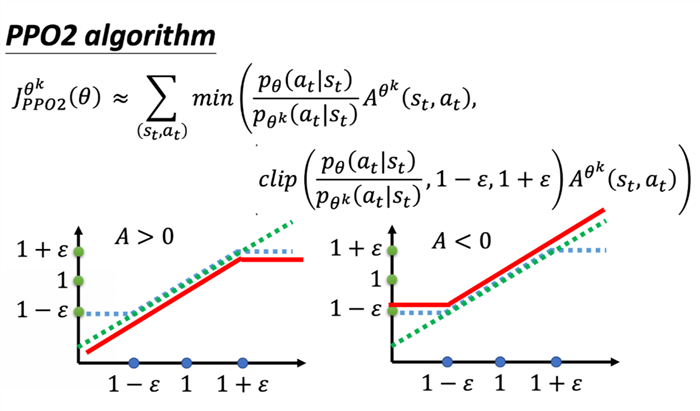
PPO 算法在大模型中的应用
(一)自然语言处理
文本生成优化
在大模型的文本生成任务中,PPO 算法可用于调整模型生成文本的策略。例如,通过对生成文本的流畅性、逻辑性、与给定主题的相关性等多个维度设定奖励机制,PPO 能够引导模型生成更高质量的文本。它可以在保持语言多样性的同时,减少生成文本中的错误、重复或不连贯现象,使得生成的文章、对话、故事等更加符合人类的语言习惯和阅读需求。
对话系统增强
对于对话系统,PPO 有助于提高模型与用户交互的能力。模型根据用户的输入生成回复,并依据回复是否准确理解用户意图、是否提供有效信息、是否符合对话语境等给予奖励反馈。PPO 算法通过不断优化策略,使对话模型能够生成更恰当、更个性化的回复,增强对话的连贯性和用户体验,无论是在智能客服、智能语音助手还是虚拟聊天机器人等应用场景中,都能显著提升系统的性能。
(二)机器人控制与决策
在机器人领域,大模型结合 PPO 算法可以实现更智能的控制与决策。机器人在不同的环境状态下需要采取合适的动作,如移动、抓取、避障等。PPO 算法根据机器人的动作所带来的结果(如成功完成任务、避免碰撞、节省能源等)给予奖励,通过训练使机器人学习到最优的动作策略。这种基于强化学习的方法使得机器人能够适应复杂多变的环境,自主地做出决策并执行任务,提高机器人在实际应用中的灵活性和适应性。
(三)游戏与模拟环境
在游戏开发中,大模型利用 PPO 算法可以训练出强大的游戏智能体。游戏环境提供了丰富的状态信息和多样化的动作空间,PPO 能够让智能体在游戏中学习到有效的策略,如在棋类游戏中选择最佳的落子策略、在竞技游戏中制定合理的战术等。通过在模拟环境中的大量训练,游戏智能体可以在不同的游戏场景下做出快速且准确的决策,提升游戏的挑战性和趣味性,同时也为游戏开发中的人工智能应用提供了新的思路和方法。
PPO 算法的优化与改进
(一)自适应学习率调整
在 PPO 算法的训练过程中,学习率的选择对训练效果有着重要影响。固定的学习率可能导致训练初期收敛过慢或训练后期因更新幅度过大而无法收敛。因此,采用自适应学习率调整策略是一种有效的优化方法。例如,可以根据训练过程中的梯度变化、策略性能的提升情况等动态地调整学习率,使得算法在不同的训练阶段都能以合适的步长进行参数更新,提高训练的稳定性和效率。
(二)与其他算法的融合
为了进一步提升 PPO 算法的性能,可以将其与其他算法进行融合。例如,与基于模型的强化学习算法相结合,利用模型预测未来状态和奖励,为 PPO 算法提供更准确的信息,从而加速策略优化过程。或者与进化算法融合,通过引入进化策略中的种群概念和遗传操作,增加算法的探索能力和全局搜索能力,避免陷入局部最优解,使得 PPO 算法在复杂的大模型训练任务中能够找到更优的策略。
(三)分布式训练与加速
随着大模型规模的不断增大,单机训练的效率和资源限制愈发明显。采用分布式训练框架可以有效解决这一问题。通过将训练任务分配到多个计算节点上并行执行,PPO 算法能够显著缩短训练时间。同时,针对分布式训练中的通信开销、数据同步等问题,开发高效的通信协议和数据处理机制,进一步提高分布式训练的效率,使得 PPO 算法能够在大规模集群环境下高效地训练大模型。
结论
PPO 算法在大模型的训练与优化中具有不可忽视的重要性。其基于近端约束的策略梯度优化机制为大模型在多个领域的应用提供了强大的支持,无论是自然语言处理、机器人控制还是游戏开发等。通过不断地对 PPO 算法进行优化和改进,如自适应学习率调整、与其他算法融合以及采用分布式训练等手段,能够进一步提升其性能和效率,推动大模型在更广泛的场景下实现更智能、更高效的应用。随着技术的不断发展,PPO 算法有望在大模型领域继续发挥核心作用,为人工智能的发展带来更多的突破和创新。



















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











