






前言
这篇文章主要两个内容。
一,把上一篇关于requires_grad的内容补充一下。
二,介绍一下线性回归。
关闭张量计算
关闭张量计算。这个相对简单,阅读下面代码即可。
print("============关闭require_grad==============")
x = torch.randn(3, requires_grad=True)
print(x)
x.requires_grad_(False) # 关闭x的张量计算
print("关闭x的张量计算后的x:", x) # 没有requires_grad属性了
x = torch.randn(3, requires_grad=True)
print("新的带张量计算的x:", x)
y = x.detach() # 去出x的张量附加属性,返回普通张量
print("y没有张量属性:", y)
print("x还有张量属性:", x)
print("============区域内去除x的张量附加属性==============")
with torch.no_grad():
y = x+2
print("y没有张量属性:", y)
print("x还有张量属性:", x)一个有趣的例子
代码1如下,代码可以正常运行。
x = torch.tensor(1.0)
y = torch.tensor(2.0)
w = torch.tensor(1.0, requires_grad=True)
y_hat = w*x
loss = (y_hat-y)**2
print(loss)
loss.backward()
print(w.grad)代码2如下,下面代码不能运行。
x = torch.tensor([1.0,2.0])
y = torch.tensor([1.0,2.0])
w = torch.tensor([1.0,2.0],requires_grad=True)
y_hat = w*x
loss =(y_hat-y)**2
print(loss)
loss.backward()
print(w.grad)这是因为代码1的loss是个值,是个标量,所以它可以执行backward。
而代码2的loss是个向量,他不能执行backward。
线性回归 linear regression
很多视频或文章都说,深度学习要先理解线性回归。然后,大家一翻线性回归的视频,又是一堆。
其实,完全不用看那些课程,不用耽误那些时间。而且,你耽误了那些时间,也未必能理解。
线性回归是要学,但不用刷视频学,其实简单几句话就能讲明白的。只是没人好好讲而已,似乎都等着我们花费非常多的时间自己研究,自己开悟。
线性回归快速理解
首先理解线性是什么。
A=2,B=4,我们肉眼识别B是A的2倍,所以,我们就可以说A和B有关系,是什么关系呢?就是线性关系;线性就是这个意思,就说俩数有关系。
我们现在有了线性这个词了,今后遇到俩数有倍数关系,我们就直接说俩数有线性关系,这样就高大上了。
上篇文章提过,名词是我们学习阻碍,线性这个名词就是具体体现了。
回归就是我们找到B是A的2倍的过程。简单来说,线性回归就是找到一个数,这个数指明了A和B的关系。
找A和B关系,用函数表示,就是y=wx+b;A带入x,B带入y。肉眼推测结果w=2,b=0。
现在把A和B换成俩矩阵,然后w也就是一个矩阵,b还是一个常数。当我们求出w和b时,就是求出了A和B的线性关系。
到此,我们不用去看三四十个线性回归的视频,就已经对线性回归有概念了。
代码
我们直接看代码,x是特征值,y是目标值。
例如我们有一个青蛙A的图片,他的矩阵就是y,然后找一个青蛙B的图片,x就是青蛙B的矩阵。
然后通过线性回归算出,青蛙B与青蛙A的线性关系(w和b)。
这里输入特征x我们写死,不用读取青蛙B的矩阵;y也不用读取青蛙A,也写死。
然后定义w是一个跟x同型矩阵,然后定义b是一个0张量。
然后利用前面的知识使用backward求梯度,然后得到w.grad和b.grad。
w.grad和b.grad和w,b是同型张量,现在我们用w.grad和b.grad去修正w和b,修正时我们使用learning_rate学习率,确保一次只修改一点点。
然后反复迭代多次,就得到了我们的关系(w和b)。
代码如下:
# 输入特征和目标值
x = torch.tensor([1.0, 2.0])
y = torch.tensor([115.0, 21.0])
# 权重初始化(包括偏差项)
w = torch.tensor([1.0, 2.0], requires_grad=True)
b = torch.tensor(0.0, requires_grad=True)
# 学习率
learning_rate = 0.01
# 迭代多次进行优化
for epoch in range(100):
# 预测
y_hat = w * x + b
# 损失函数
loss = (y_hat - y).pow(2).mean()
# 反向传播
loss.backward()
# 更新权重和偏差
with torch.no_grad():
w -= learning_rate * w.grad
b -= learning_rate * b.grad
# 清零梯度
w.grad.zero_()
b.grad.zero_()
print(f'Epoch {epoch + 1}, Loss: {loss.item()}')
# 最终模型参数
print("Final weights:", w)
print("Final bias:", b)运行如下图: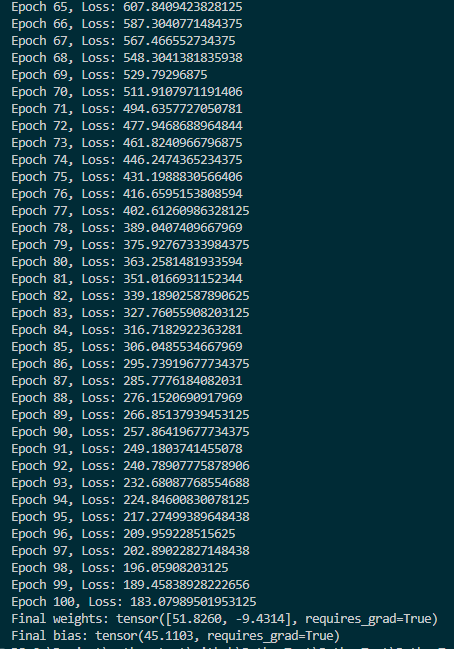
如图,我循环了100次,但loss的值还是比较大,loss的含义是,越接近0,这个w和b的值就越精确。
当然,如果青蛙A和B实在是不像,那可能循环了1000次,loss还是会很大。
这里我们循环100次后w=[51.8260,-9.4314] b=45.1103
现在我们使用y=wx+b带入x、w、b得到y_pred=51.8260 * 1 +45.1103= 96.9363。我们的y的第一项是115.0。
可以看到x通过wx+b得到的预测值,已经变的很接近y的真实值了。
现在修改运行2000次,运行如下图: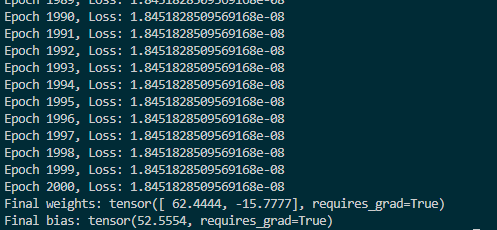
y=wx+b带入x、w、b得到y_pred=62.4444 * 1 +52.5554= 114.9998。
而我们的y的第一项是115.0。
可以看到,预测值已经非常接近真实值了。
Optimizer
下面是optimizer的使用,具体内容下一篇再讲解。
import torch
import numpy as np
import torch.nn as nn
X = torch.tensor([1, 2, 3, 4], dtype=torch.float32)
Y = torch.tensor([2, 4, 6, 8], dtype=torch.float32)
w2 = torch.tensor(0.0, requires_grad=True)
def forward(_x):
return w2* _x
learning_rate = 0.01
n_iter = 100 # 循环次数
loss =nn.MSELoss()
optimizer =torch.optim.SGD([w2],lr=learning_rate)
for epoch in range(n_iter):
y_pred = forward(X)#
l = loss(Y, y_pred)
l.backward() #执行完反向传播后,w2里就已经有w2.grad了
optimizer.step() #optimizer初始化时就接收了w2,现在w2有了grad,就可以执行step进行优化了,优化时会使用w2的梯度grad属性和学习率learning_rate
optimizer.zero_grad() #梯度清零
if epoch % 1 == 0:
print(f'epoch {epoch+1}:w2= {w2:.3f} ,loss = {l:.8f}')
print(f'f(5)={forward(5):.3f}')传送门:零基础学习人工智能—Python—Pytorch学习(一)零基础学习人工智能—Python—Pytorch学习(二)零基础学习人工智能—Python—Pytorch学习(三)
学习就先到这。
注:此文章为原创,任何形式的转载都请联系作者获得授权并注明出处!

若您觉得这篇文章还不错,请点击下方的【推荐】,非常感谢!
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











