








ReadPaper文章地址

文章名称风格飘逸。这个是解决视线追踪任务的文章,第一次接触。因此做一下笔记。
视线追踪任务很好理解,就是找出图中某个人物的视线焦点。
文章所提出的双阶段解决方案:
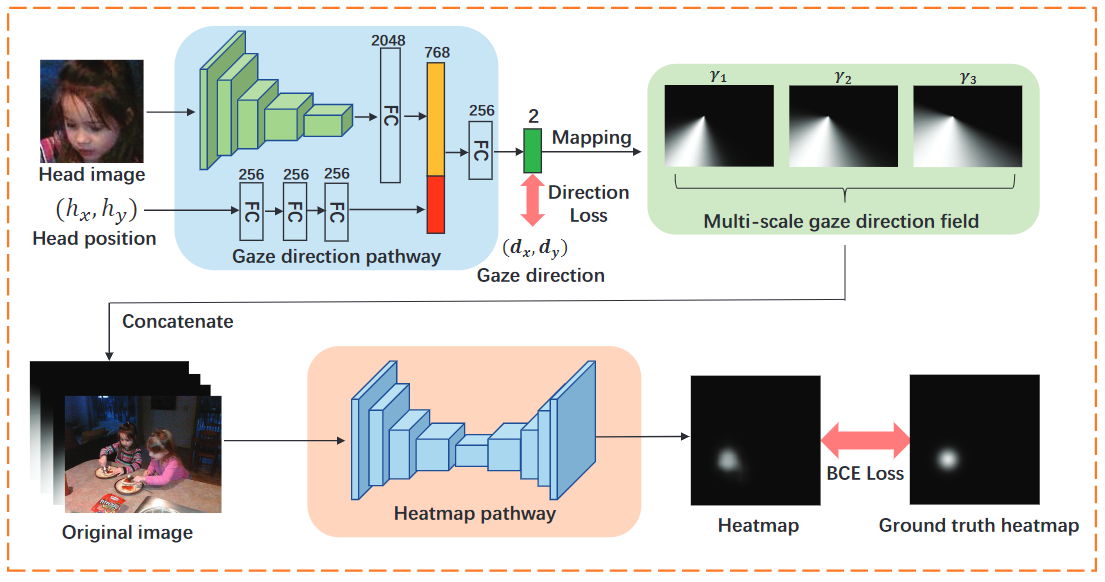
- 输入头部图像和头部坐标(可以认为是多模态输入),利用cnn和fc得到一个预测的视线方向,从而生成多尺度的视线方向场。
- 将多尺度的视线方向场与原图concatenate,再次使用cnn(FPN结构)得到视线焦点的热图。
一些细节:
- 如何生成多尺度的视线方向场?
h为头部坐标,p为图中任意点的坐标,那么由1式得到方向向量G:
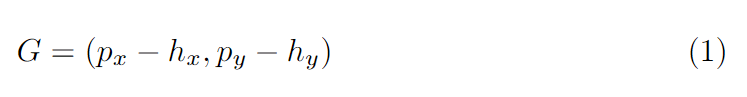
然后计算G与预测的方向 d ^ \hat{d} d^的相似度Sim§:
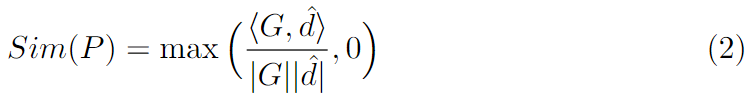
那么限制G在 d ^ \hat{d} d^正负90度范围内(向后看没意义),可以得到这样的视线场:

最后再做幂次运算,就可以得到多尺度的视线场(文中λ又取了2和5)。
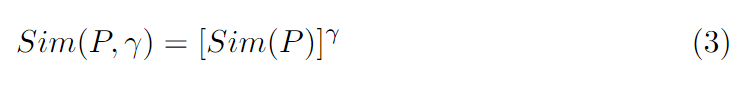
- ground truth 的Heatmap是用高斯核生成的:

网络训练
该网络是可以端对端训练的
-
视线方向损失:

d ^ \hat{d} d^是预测的坐标算出来的归一化后的方向,d是groundtruth方向。 -
热图的损失(BCE loss):
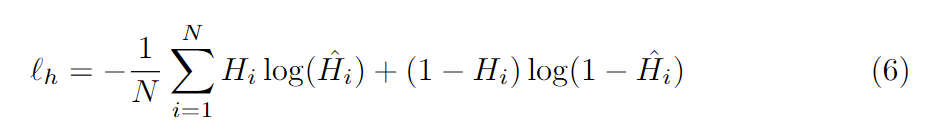
H ^ \hat{H} H^是预测的热图中的某个点的值。N是热图的像素数,文中为56*56个。 -
总损失:

文中平衡系数λ设置为0.5。
好了,网络介绍完了,还是很简单的。
评价指标
评价指标主要有AUC, Dist, MDist,Ang, MAng,基本都是 15年的Where are they looking这篇文章提出的,也都比较好理解。

















 4796
4796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









