







1. 整体流程
第一步,加载视频/图片和音频/tts。用melspectrogram将wav文件拆分成mel_chunks。
第二步,调用face_detect模型,给出人脸检测结果(可以改造成从文件中读取),包装成4个数组batch:img_batch(人脸),mel_batch(语音),frame_batch(原图),coords_batch(坐标)
第三步,加载模型,进行计算。这个模型目前看下来就是简单的resnet,没有transfomer。另外mask也不是用分割模型,而是直接将图片下半部分全部作为mask😄,然后将mask图片拼接到原图片的色彩通道上作为输入。
第四步:预测出来的人脸拼接到原图上,输出位视频。
2. 优缺点
优点:极其简单,一个人脸检测模型+一个基于CNN的lipsync模型,速度很快。
缺点:嘴唇经常是歪的,而且有变形;牙齿不断在闪烁。经过图像增强后,我们取出截图如下:

3. 其他版本
3.1 Easy_Wav2Lip
这个版本相当好用。首先执行python install.py来下载模型文件。然后配置一下config.ini,执行python run.py即可。
生成配置文件的代码可以在目录下的Easy_Wav2Lip_v8.3.ipynb中来修改;也可以通过执行python GUI.py打开图形界面来修改:
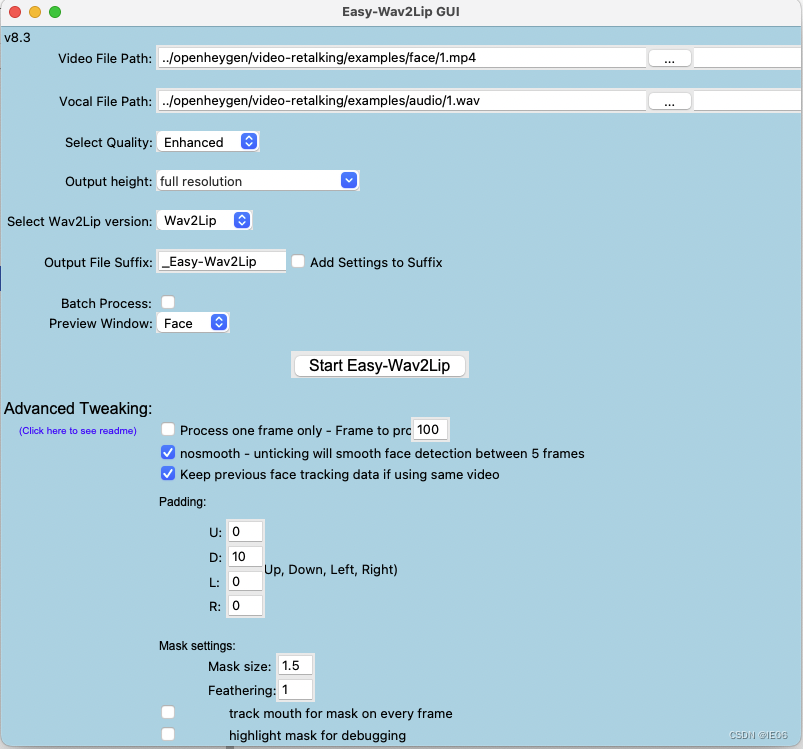
执行代码的入口仍然是inference.py。这里说明一下分支内容:
- 基础人脸检测模型为RetinaFace,模型文件为checkpoints/mobilenet.pth。
- 如果使用Imporved模式,会调用load_sr()方法加载sr_model(gfpgan做super resolution,参数文件);如果使用Enhanced,会进行upscale。具体的表现是:如果仅使用imporved模式,嘴部会比较模糊;使用enhanced模式会得到清晰度统一的视频。
- 如果mouth_tracking为true,则会调用复杂一些的create_tracked_mask;否则仅启用create_mask
- 模型可选用"Wav2Lip", "Wav2Lip_GAN"两种。
在github的项目文件里面有一个ipynb文件可供学习。
3.2 Wav2Lip-fast
使用如下代码执行:
python inference.py --checkpoint_path <ckpt> --face <video.mp4> --audio <an-audio-source> --multiplier <multiplier-to-fasten-process>
这里的multiplier,指的是每隔多少帧进行一次face detection。
简化版代码如下:
import cv2,audio,face_detection,subprocess,torch,platform,sys
from models import Wav2Lip
from tqdm import tqdm
import numpy as np
facefile = '../openheygen/video-retalking/examples/face/2.mp4'
audiofile = '../openheygen/video-retalking/examples/audio/1.wav'
checkpoint_path = 'checkpoints/wav2lip_gan.pth'
base_name = facefile.split('/')[-1]
device = 'mps'
fps = 25
mel_step_size = 16
multiplier = 1
img_size = 96
face_det_batch_size = 16
batch_size = 128
wav = audio.load_wav(audiofile, 16000)
mel = audio.melspectrogram(wav)
mel_chunks = []
mel_idx_multiplier = 80./fps
detector = face_detection.FaceAlignment(face_detection.LandmarksType._2D,flip_input=False, device=device)
def face_detect(images, multiplier=1):
predictions = []
batch_size = face_det_batch_size
for i in range(0, len(images), batch_size * multiplier):
predictions.extend(detector.get_detections_for_batch(np.array(images[i:i + batch_size]), multiplier))
results = []
pady1, pady2, padx1, padx2 = [0, 10, 0, 0]
for rect, image in zip(predictions, images):
y1 = max(0, rect[1] - pady1)
y2 = min(image.shape[0], rect[3] + pady2)
x1 = max(0, rect[0] - padx1)
x2 = min(image.shape[1], rect[2] + padx2)
results.append([x1, y1, x2, y2])
boxes = np.array(results)
results = [[image[y1: y2, x1:x2], (y1, y2, x1, x2)] for image, (x1, y1, x2, y2) in zip(images, boxes)]
return results
def datagen(frames, mels, multiplier):
img_batch, mel_batch, frame_batch, coords_batch = [], [], [], []
face_det_results = face_detect(frames, multiplier)
for i, m in enumerate(mels):
idx = i%len(frames)
frame_to_save = frames[idx].copy()
face, coords = face_det_results[idx].copy()
face = cv2.resize(face, (img_size, img_size))
img_batch.append(face)
mel_batch.append(m)
frame_batch.append(frame_to_save)
coords_batch.append(coords)
if len(img_batch) >= batch_size:
img_batch, mel_batch = np.asarray(img_batch), np.asarray(mel_batch)
img_masked = img_batch.copy()
img_masked[:, img_size//2:] = 0
img_batch = np.concatenate((img_masked, img_batch), axis=3) / 255.
mel_batch = np.reshape(mel_batch, [len(mel_batch), mel_batch.shape[1], mel_batch.shape[2], 1])
yield img_batch, mel_batch, frame_batch, coords_batch
img_batch, mel_batch, frame_batch, coords_batch = [], [], [], []
if len(img_batch) > 0:
img_batch, mel_batch = np.asarray(img_batch), np.asarray(mel_batch)
img_masked = img_batch.copy()
img_masked[:, img_size//2:] = 0
img_batch = np.concatenate((img_masked, img_batch), axis=3) / 255.
mel_batch = np.reshape(mel_batch, [len(mel_batch), mel_batch.shape[1], mel_batch.shape[2], 1])
yield img_batch, mel_batch, frame_batch, coords_batch
def load_model(path):
model = Wav2Lip()
print("Load checkpoint from: {}".format(path)) #torch.load(checkpoint_path)
checkpoint = torch.load(path,map_location=torch.device(device))
s = checkpoint["state_dict"]
new_s = {}
for k, v in s.items():
new_s[k.replace('module.', '')] = v
model.load_state_dict(new_s)
model = model.to(device)
return model.eval()
print('step1: read files...')
if facefile.split('.')[-1] in ['png','jpg','jpeg']:
full_frames = [cv2.imread(facefile)]
else:
full_frames = []
video_stream = cv2.VideoCapture(facefile)
fps = video_stream.get(cv2.CAP_PROP_FPS)
while 1:
still_reading, frame = video_stream.read()
if not still_reading:
video_stream.release()
break
full_frames.append(frame)
i = 0
while 1:
start_idx = int(i * mel_idx_multiplier)
if start_idx + mel_step_size > len(mel[0]):
mel_chunks.append(mel[:, len(mel[0]) - mel_step_size:])
break
mel_chunks.append(mel[:, start_idx : start_idx + mel_step_size])
i += 1
full_frames = full_frames[:len(mel_chunks)]
gen = datagen(full_frames.copy(), mel_chunks, multiplier)
print('step2: load model and predict lip...')
results =[]
model = load_model(checkpoint_path)
frame_h, frame_w = full_frames[0].shape[:-1]
for i, (img_batch, mel_batch, frames, coords) in enumerate(tqdm(gen,total=int(np.ceil(float(len(mel_chunks))/batch_size)))):
img_batch = torch.FloatTensor(np.transpose(img_batch, (0, 3, 1, 2))).to(device)
mel_batch = torch.FloatTensor(np.transpose(mel_batch, (0, 3, 1, 2))).to(device)
with torch.no_grad():
pred = model(mel_batch, img_batch)
pred = pred.cpu().numpy().transpose(0, 2, 3, 1) * 255.
for p, f, c in zip(pred, frames, coords):
y1, y2, x1, x2 = c
p = cv2.resize(p.astype(np.uint8), (x2 - x1, y2 - y1))
f[y1:y2, x1:x2] = p
results.append(f)
print('step3: write file with audio...')
import matplotlib.pyplot as plt
out = cv2.VideoWriter('temp.mp4', cv2.VideoWriter_fourcc(*'mp4v'), fps, (frame_w, frame_h))
for pp in results:
out.write(pp)
out.release()
command = 'ffmpeg -loglevel error -y -i {} -i {} -strict -2 -q:v 1 {}'.format(audiofile, 'temp.mp4', 'result.mp4')
subprocess.call(command, shell=platform.system() != 'Windows')
from IPython.display import HTML
display(HTML("""
<video height=400 controls>
<source src=result.mp4 type="video/mp4">
</video>"""))
如果需要的话,可以进行一次画质增强:
sys.path.insert(0, 'third_part/GFPGAN')
from third_part.GFPGAN.gfpgan import GFPGANer
restorer = GFPGANer(model_path='checkpoints/GFPGANv1.3.pth',
upscale=1, arch='clean', channel_multiplier=2, bg_upsampler=None)
final_results = []
for r in tqdm(results):
final_results.append(restorer.enhance(r, has_aligned=False, only_center_face=True, paste_back=True)[2])
import matplotlib.pyplot as plt
plt.imshow(cv2.cvtColor(final_results[0], cv2.COLOR_BGR2RGB))
out = cv2.VideoWriter('temp.mp4', cv2.VideoWriter_fourcc(*'mp4v'), fps, (frame_w, frame_h))
for pp in final_results:
out.write(pp)
out.release()
command = 'ffmpeg -loglevel error -y -i {} -i {} -strict -2 -q:v 1 {}'.format(audiofile, 'temp.mp4', 'result.mp4')
subprocess.call(command, shell=platform.system() != 'Windows')

















 4113
4113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









