









今天分享一个用Stable Diffusion零成本制作属于自己的数字人的教程。在这个充满创新与科技魅力的时代,每个人拥有自己的数字分身已经不再是遥不可及的事情了,而是触手可及的现实。

本文将会用到Stable Diffusion、Wav2Lip插件以及剪映。
Wav2Lip插件地址:https://github.com/numz/sd-wav2lip-uhq
1
Wav2Lip插件安装
在开始安装Wav2Lip插件之前,我们需要先进行一些准备工作。首先,确保Stable Diffusion已经升级到最新版本。其次,安装Wav2Lip所需的环境“FFmpeg”。最后,下载并安装所需的模型。
使用Wac2Lip插件,我们需要预先安装好“FFmpeg”:
- 打开“FFmpeg”官网(https://ffmpeg.org/download.html),滑到下方在“Get packages & executable files”选择你的操作系统。(网络不太稳定的,文末提供下载链接)

- 这里以Windows为例,选择Windows的图标,然后点击第一个选项“Windows builds from gyan.dev”。
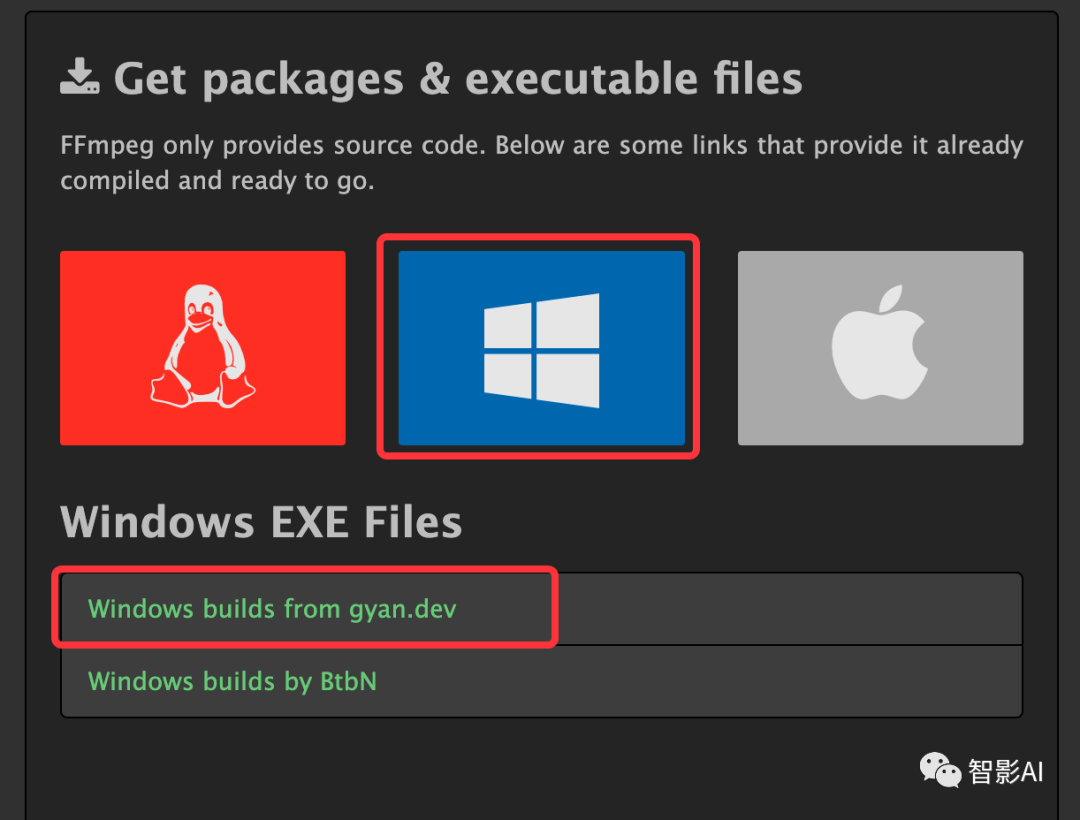
- 打开第一个选项之后,滑到下方,点击下载“ffmpeg-git-essentials.7z”文件。下载完成之后,可以解压到当前文件,或者解压到一个全英文的文件夹里面即可。
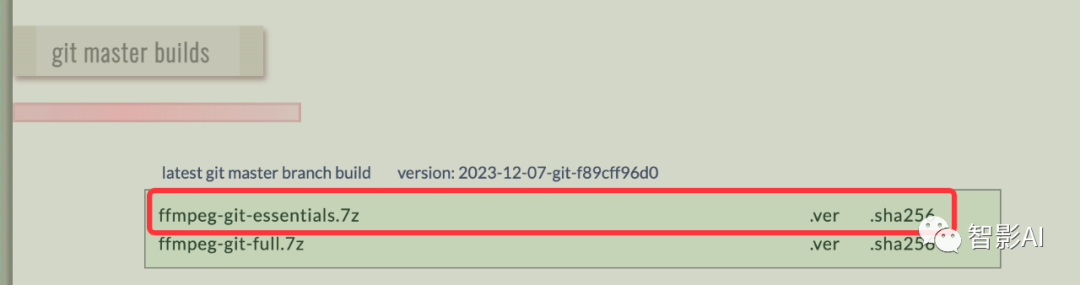
- 下载完成之后,就需要将“FFmpeg”添加到环境变量设置中。在“此电脑”图标上右击并点击“属性”,然后在右侧“相关设置”点击“高级系统设置”打开“系统属性”面板。
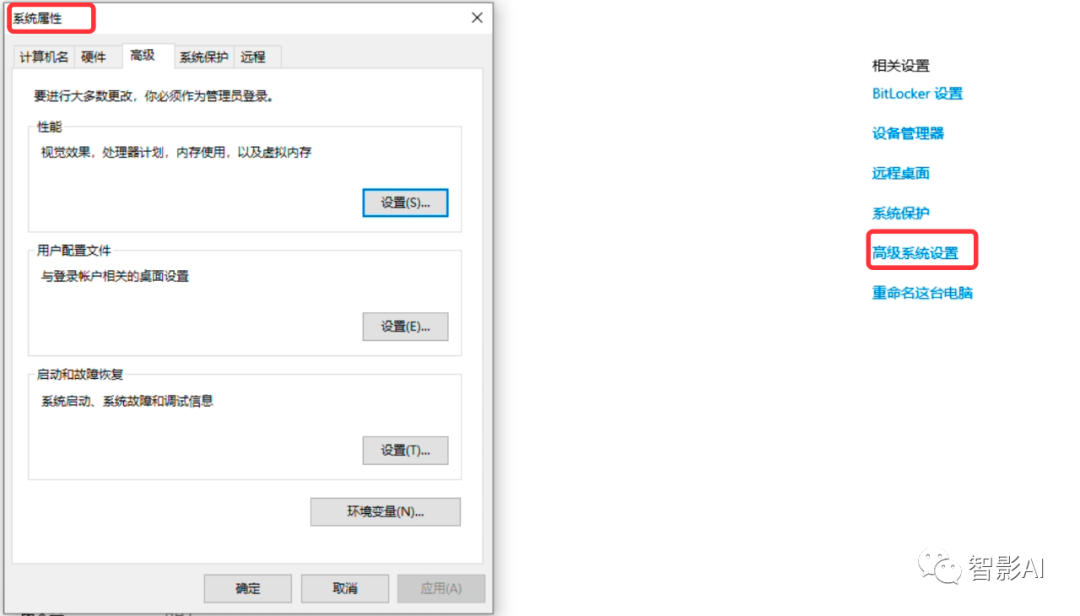
- 点击下方的“环境变量”,打开环境变量面板,然后在上方的“用户变量”,点击“Path”并点击“编辑”按钮。
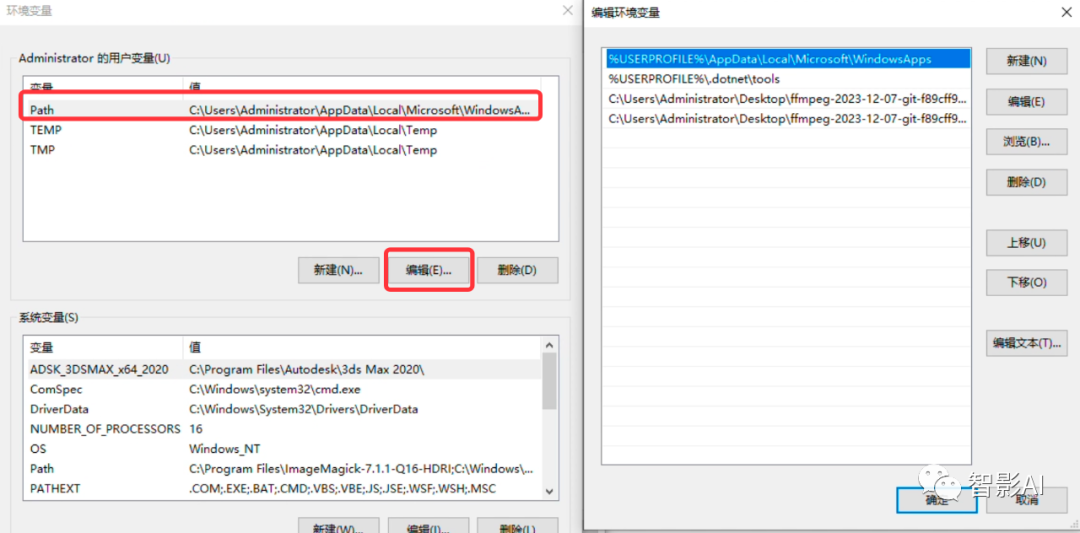
- 在“编辑环境变量”面板中,点击“新建”,然后在点击“预览”,找到刚刚下载好并解压好的文件夹下的“bin”文件夹,然后点击“确定”即可。
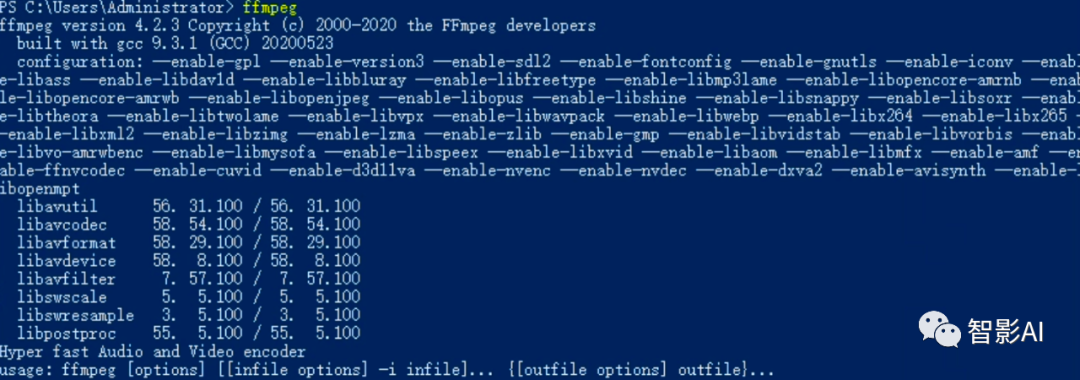
- FFmpeg添加完之后,打开“终端”,执行“ffmpeg”命令。执行“ffmpeg”后,如果出现以下信息,说明ffmpeg安装成功。
以上环境设置好之后,就可以打开Stable Diffusion安装“Wav2Lip”插件啦。
插件安装
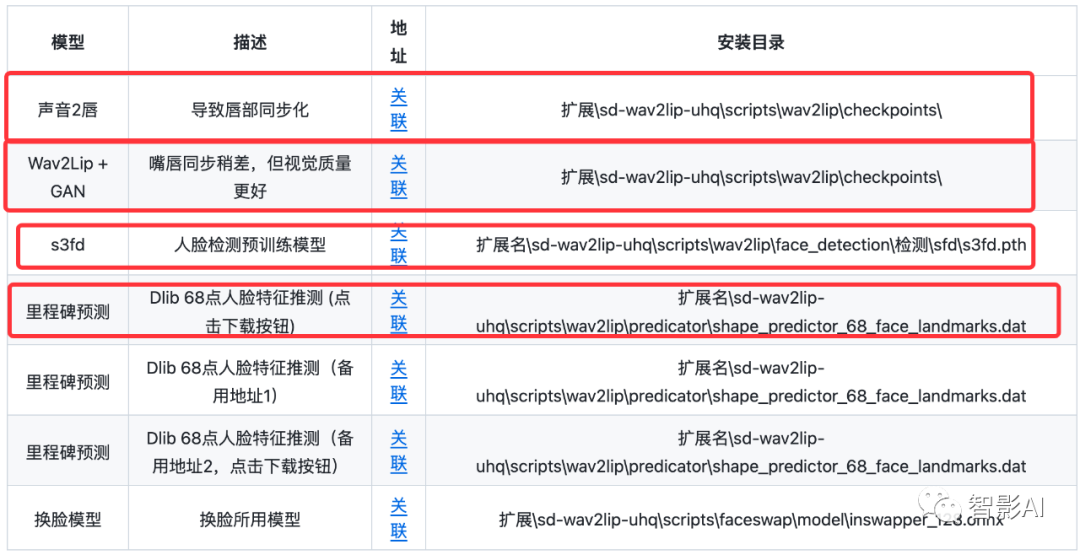
对了,在安装之前,记得先去Github下载“Wav2Lip”模型。(网络不太稳定的,文末提供下载链接)
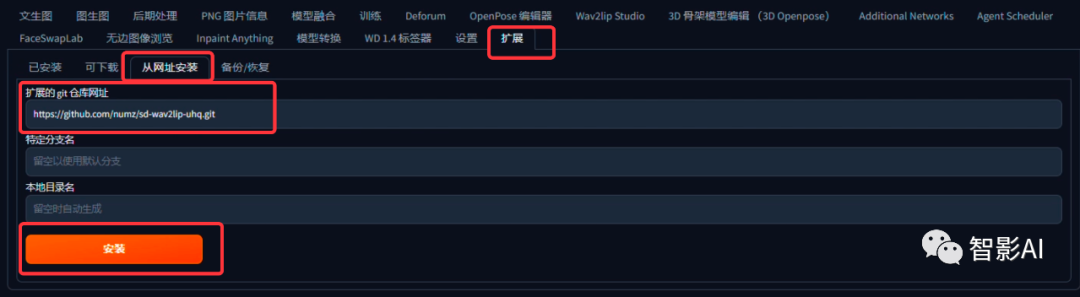
- 模型下载好之后,打开“Stable Diffusion”,点击“扩展”-“从网址安装”,然后将插件的URL粘贴到“扩展的git仓库网址”下并点击“安装”即可。
- 插件安装完成之后,关闭Stable Diffusion,将刚刚下载好的模型放到对应的文件夹里面,然后再重新打开“Stable Diffusion”,在上方就可以看到“Wav2Lip”插件啦。
Tips:如果需要使用“换脸”,需要安装和下载“FaceSwap”的模型以及环境。
模型在刚刚下载“Wav2Lip”模型下方就有换脸模型可以下载,下载完放到对应的文件夹即可。

2
数字人制作
以上的内容设置完成之后,就可以开始制作数字人啦!
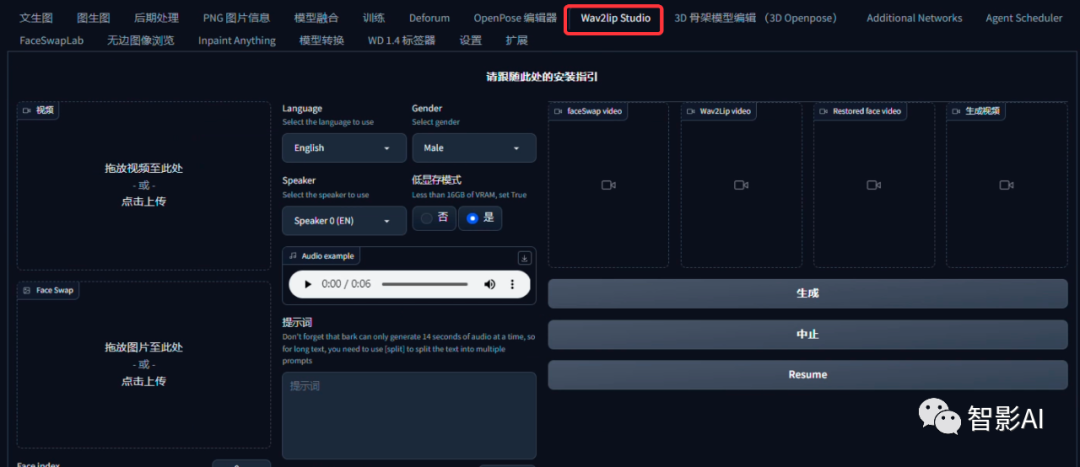
- 点击“Wav2Lip Studio”插件,然后上传一段每帧都包含人脸的视频(avi格式或者mp4格式均可,上传的视频一定要每帧都有人脸,如果有一帧没有人脸,就会报错),如果需要换脸的,可以在“Face Swap”框内上传一张有脸部的图片。(如果你上传的是avi文件,在界面上你看不见它,但不用担心,插件会正常处理视频。)
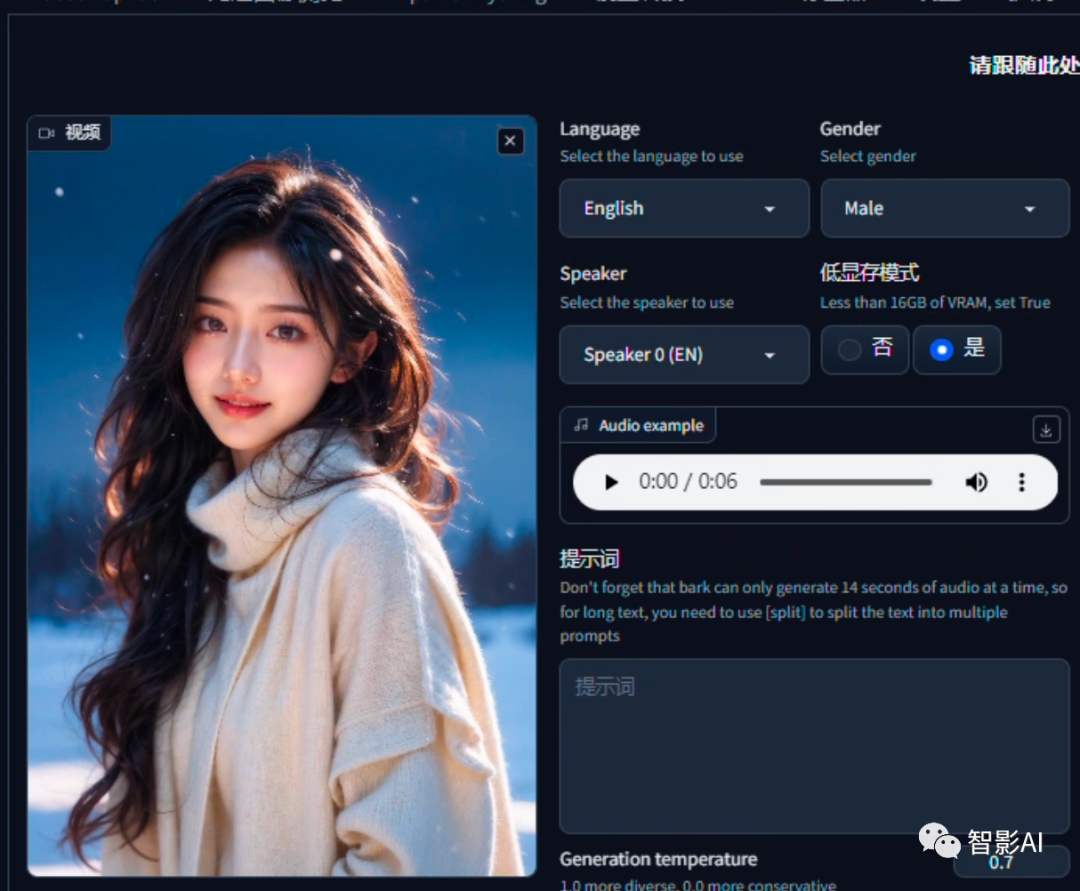
如果想用一张照片生成数字人,可以先将照片导入到剪映里面,然后设置时长,导出即可。
1.1 打开“剪映”,点击“开始创作”,然后将照片导入到剪映,设置一下照片的时长。
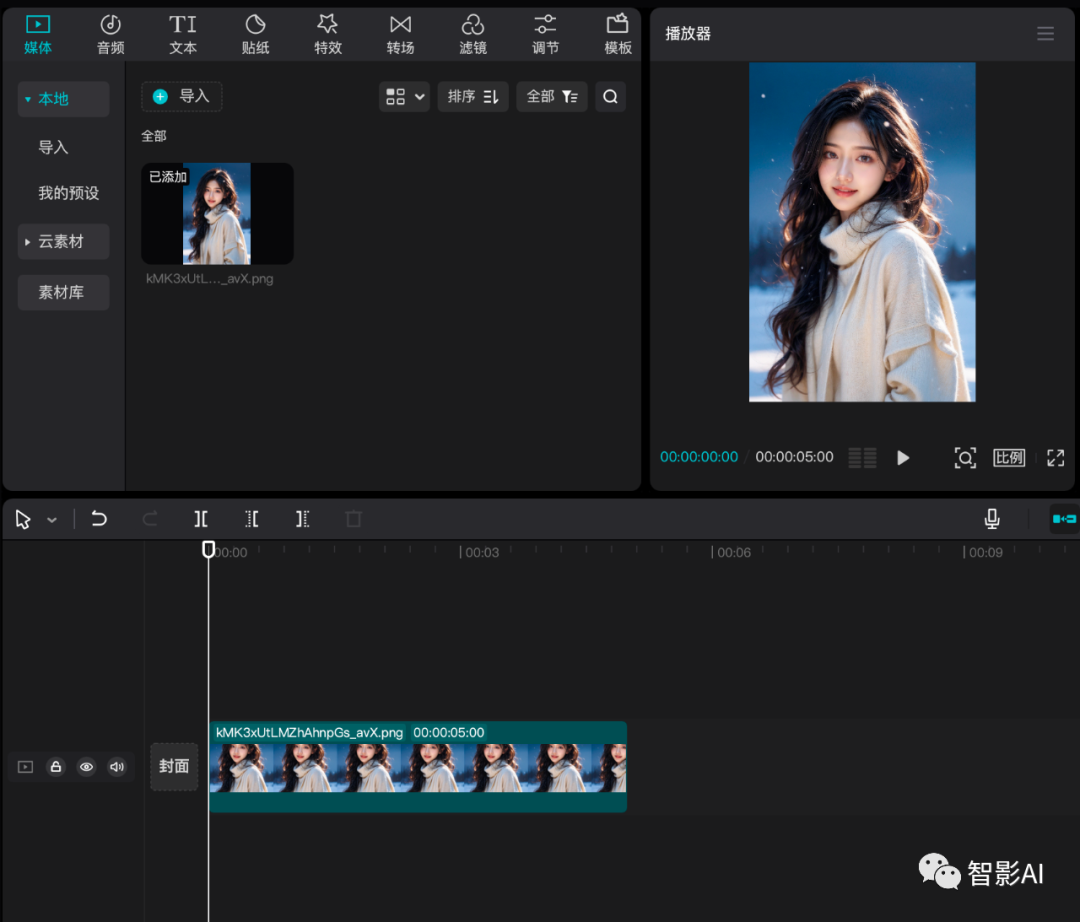
1.2 设置好之后,点击左上角的“文件”-“导出”,导出“MP4”格式即可。
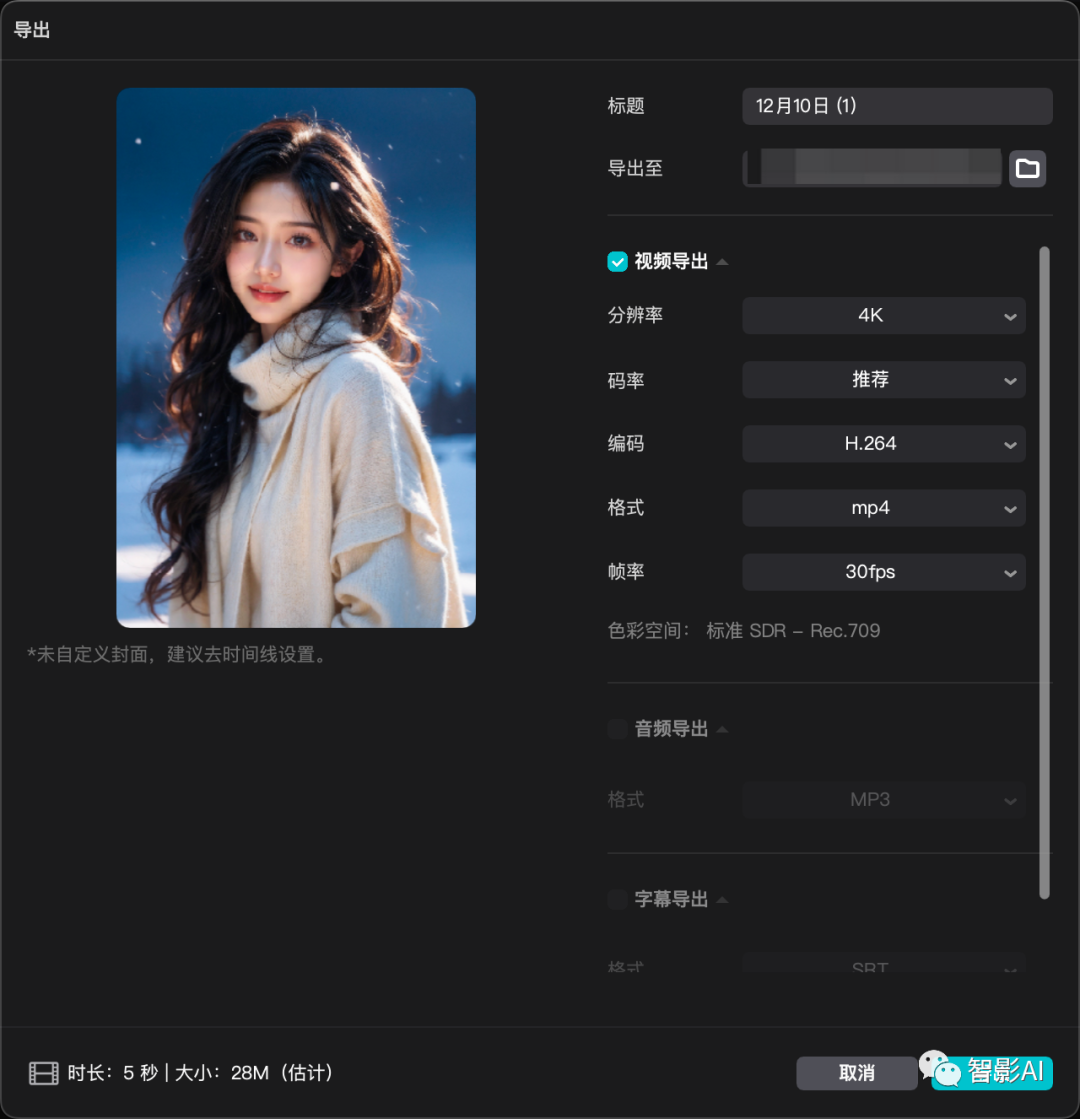
- 准备一段音频并上传。
如果没有音频,可以用“Wav2Lip”插件里面的“bark”插件生成音频,也可以用前面分享过的“TTSmake”生成音频,当然啦,也可以用“剪映”。下面介绍一下用“Wav2Lip”插件里面的“bark”插件生成音频。
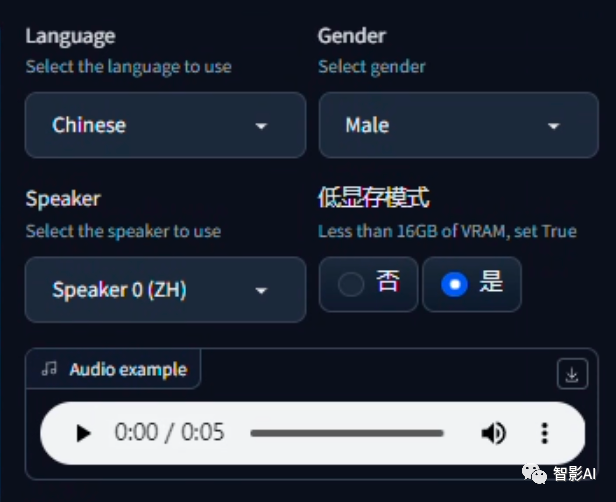
2.1 选择“语言”、“性别”以及“朗读者”。在“底显存模型”下如果显卡内存低于16GB,勾选“是”即可。(在“Audio example”可以试听朗读者的声音)。
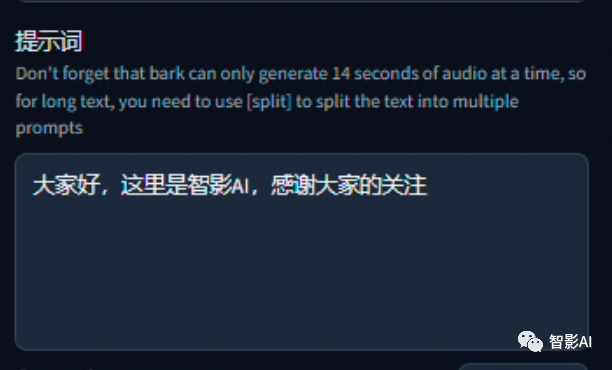
2.2 将需要朗读的文本粘贴到“提示词”的框内。
注意:bark一次只能生成14秒以内的音频,如果一句话超过了14秒,就需要使用[split]进行分割。
例如:“文本文本文本文本[split]文本文本文本文本”。
2.3 “Generation temperature” 参数为0.0时更接近声音,1.0更有创意。0.0会产生一些奇怪的结果,而1.0则与声音相距甚远。0.7是“bark”设置的默认值,可以自己尝试微调一下以达到效果更佳。
2.4 Silence是在用[split]分割后的停顿时间,默认是0.25。设置好以上的参数之后,点击“生成”就可以生成音频啦。
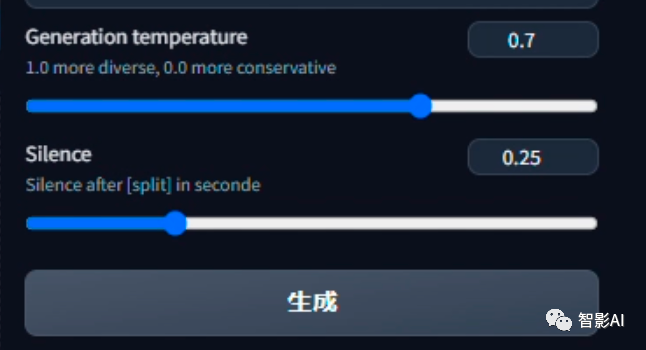
关于bark更多的使用细节可以查看bark文档:https://github.com/suno-ai/bark/
- 选择一个模型,然后调整一下参数,然后点击“生成”即可。
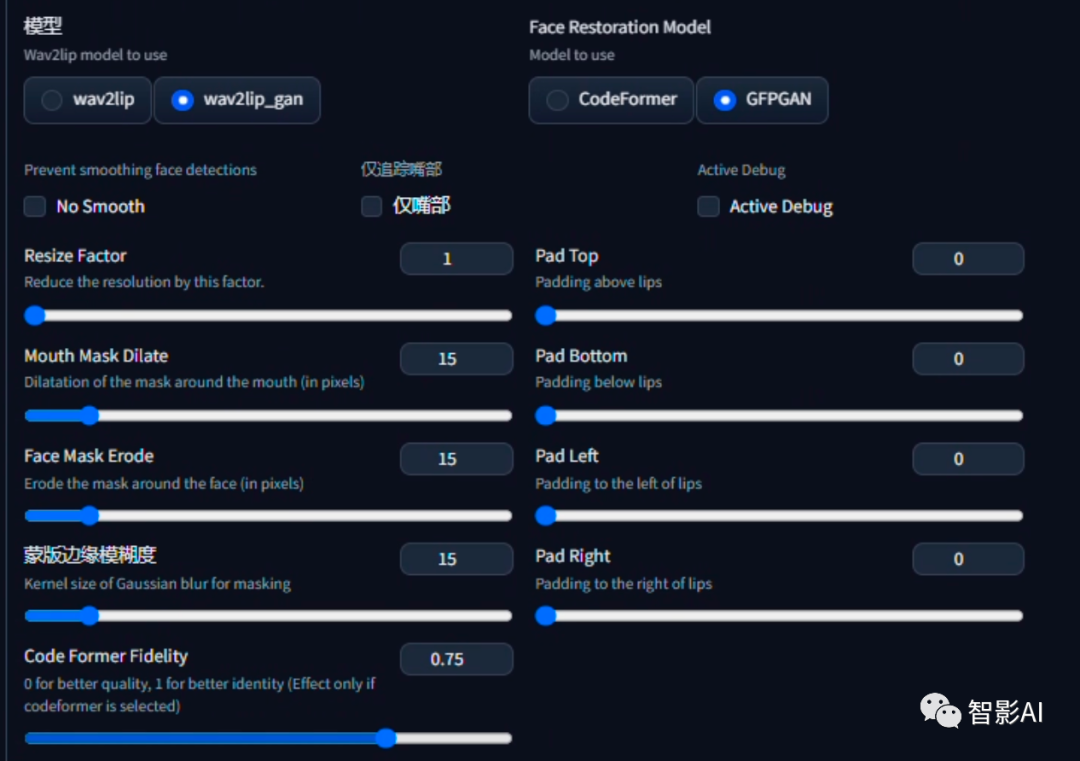
模型我选择了“wav2lip_gan”,其他的参数我都保持了默认。模型这里如果要高精度的嘴唇同步,可以选择“wav2lip”模型,如果要视觉质量更好,嘴唇同步稍差可以选择“wav2lip_gan”。
- 生成视频需要等个几分钟,耐心等待一下。(根据不同时长的视频生成的时间不同)
,时长00:04
等了大概五六分钟,生成了一个4秒的视频。这是用“wav2lip_gan”模型生成的,接下来再用“wav2lip”模型试一下。
,时长00:04
我们可以看到,用“wav2lip_gan”模型生成的数字人,虽然在视觉上质量更好了,但是在嘴唇同步上稍微有一些差,然后“wav2lip”模型生成的则是嘴唇同步的很好,而视觉质量则更差。这里用的都是默认的参数,再调一下参数,效果会更好。
参数介绍
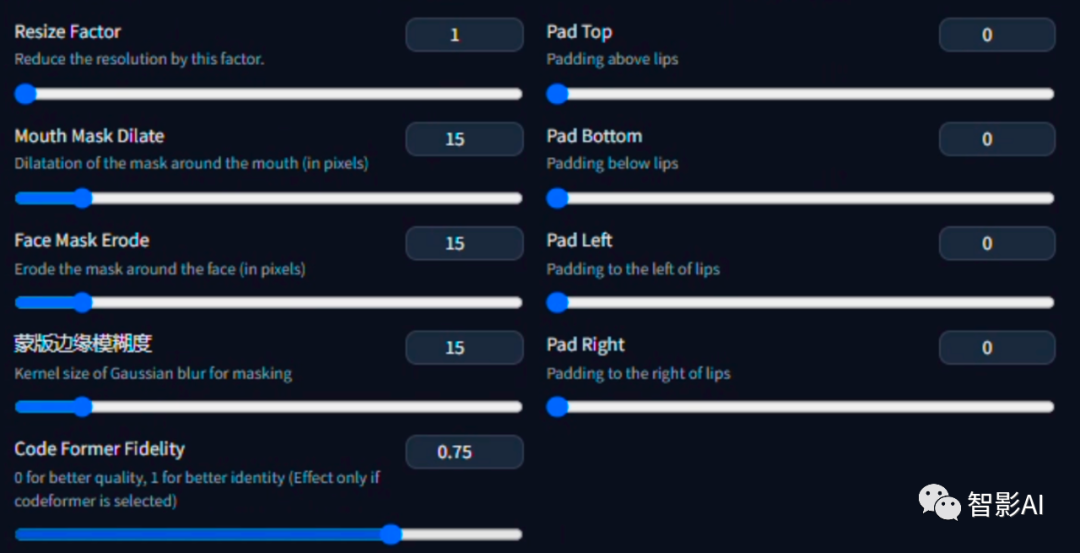
-
Resize Factor:这是一个用于调整视频分辨率的参数。例如,如果resize factor设置为0.5,那么视频的分辨率将被降低为原来的一半。
-
Mouth Mask Dilate:这个是用于控制嘴巴的覆盖区域。增加这个参数的值会使嘴巴的蒙版向外扩张,而减少这个参数的值则会使蒙版收缩,可以根据嘴巴的大小来作出调整。
-
Face Mask Erode:与上一个参数相反,这个参数是用于控制面部蒙版的腐蚀程度。增加这个参数的值会使面部蒙版向内收缩,而减少这个参数的值则会使蒙版扩张。
-
蒙版边缘模糊度:这个参数用于控制蒙版边缘的模糊程度,使其变得更平滑,建议尽量使该参数小于等于 “Mouth Mask Dilate”参数。
-
Code Former Fidelity:
当该参数偏向0时,虽然有更高的画质,但可能会引起人物外观特征改变,以及画面闪烁。
当该参数偏向1时,虽然降低了画质,但是能更大程度的保留原来人物的外观特征,以及降低画面闪烁。
不建议该参数低于0.5。为了达到良好的效果,建议在0.75左右进行调整。
- 右侧的“Pad Top”、“Pad Bottom”、“Pad Left”、“Pad Right”是用于调整移动嘴巴的位置,如果嘴巴位置不理想,可以用它来微调,通常情况下,不必刻意调整。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 211
211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









