






本文是一篇论文阅读笔记,介绍一下一种全局布局的技术,即把待布局单元当成电荷,利用电场力优化布局的论文(FFTPL),其后续优化及用GPU实现的技术(ePlace,DreamPlace,Xplace)。
用静电力来优化布局的方法
最先提出使用静电力来做全局布局的貌似是这篇论文:
FFTPL: An Analytic Placement Algorithm Using Fast Fourier Transform for Density Equalization
意为使用快速傅里叶变换来对密度这个量进行优化。那么傅里叶变换和静电力有什么关系呢?
先看优化目标:
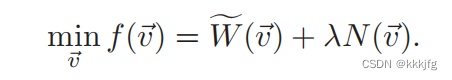
其中
v
⃗
\vec{v}
v代表当前布局的所有单元的位置。
W
~
\tilde{W}
W~就是HPWL了(HPWL是半周长线长,一种估计线长的方法,这篇博客中有介绍:https://blog.csdn.net/kkkjfg/article/details/128877914),
N
(
v
⃗
)
N(\vec{v})
N(v)则代表势能,
λ
\lambda
λ则代表这两个目标之间的比例。
优化目标是这个,但我们其实也并不需要知道具体的线长与势能,因为在优化过程中我们只需要对当前的布局算一个导数优化目标的导数就可以了,然后挪动各单元的位置,这个过程类似于梯度下降。
那么其实问题就在于每一步得把目标函数对各单元位置的导数求出来。首先这个导数是:
∇
f
=
∇
W
+
λ
⋅
q
⋅
E
\nabla f=\nabla W+\lambda·q·E
∇f=∇W+λ⋅q⋅E
∇
W
\nabla W
∇W等下再说,先说后面这项,即势能对电荷的导数,即
λ
⋅
q
⋅
E
\lambda·q·E
λ⋅q⋅E,其实很有道理,在电场中,想使势能最小,当然就是沿着电场走,且电场力越大,电势变化得越快。
q
⋅
E
q·E
q⋅E就是电场力。那么,如何求电场力呢?这里标题的“Fast Fourier Transform”,快速傅里叶变换就出用场了,它利用一个叫泊松等式(Poisson’s equation)的东西进行求解:
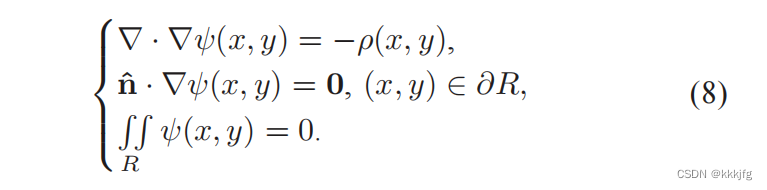
它的数值解是:
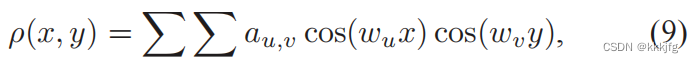
(
w
u
=
π
u
n
w_u=π\frac{u}{n}
wu=πnu
w
v
=
π
v
n
w_v=π\frac{v}{n}
wv=πnv)
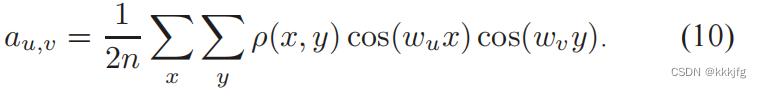

按这个解对(x,y)求导就是电场了。
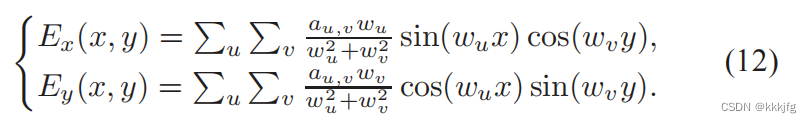
没看懂?我也没看懂。想看证明的FFTPL的参考论文[17]有详细证明:
G. Skollermo. A Fourier Method for the Numerical Solution of Poisson’s Equation. Mathematics of Computation, 29(131):697–711, 1975.(https://www.ams.org/journals/mcom/1975-29-131/S0025-5718-1975-0371096-4/S0025-5718-1975-0371096-4.pdf)
当然我刚刚说的是已知电荷分布,那么电荷分布是怎么求的呢?按面积来,面积越大电荷越大,所以一个单元格的density定义为所有与之相交的单元的面积和。(下图截图于Xplace,A代表面积, A b A_b Ab代表一个bin,即一个单元格的面积,V是全体标准单元、宏单元。)
总之我们知道这是一个用电荷分布求电场的手段就行了。虽然我挺纳闷的有电荷分布了为什么不直接拿E=kQ/r^2这种公式算,chatgpt说可能拿快速傅里叶变换会更快更精准。
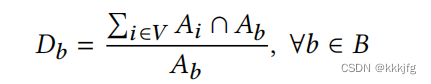
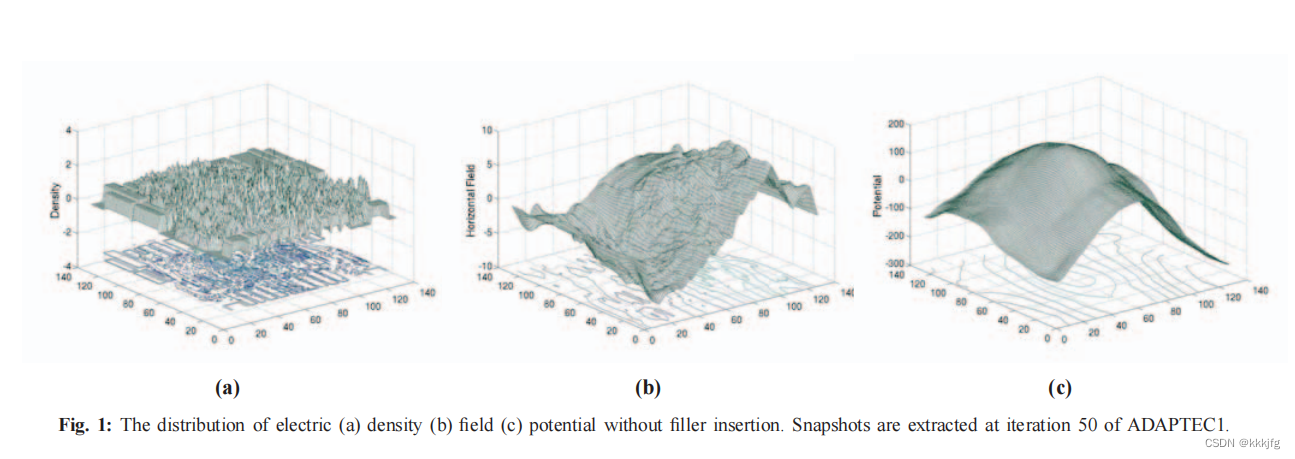
以下是一个电荷分布、电场分布和电势的例子,可以看到这种方案确实会把电荷向四周推开去(电势中间高周围低,势能想低就得往低走)
以下是算法流程:
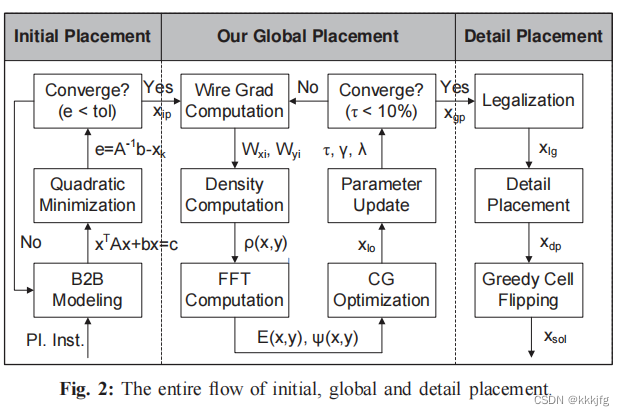
这图已经比较清楚了,就是在初始化之后,计算线长损失,密度损失,然后求梯度更新各单元的位置就完了,可能不太清楚的就是CG(Conjugate Gradient)Optimization是什么,我查了一下貌似是类似SGD,Adam这类的优化器,可以规划更新步长等策略。
还有就是前面一直没提的线长的问题,由于HPWL不好求导:
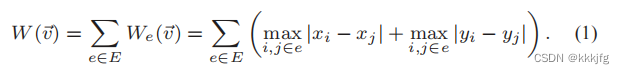
这里采用了一个平滑策略:
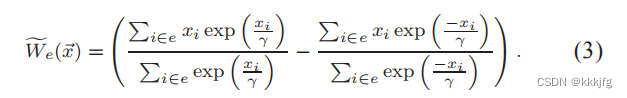
这里
λ
\lambda
λ越小越接近于HPWL。
线长与运行时间的结果:
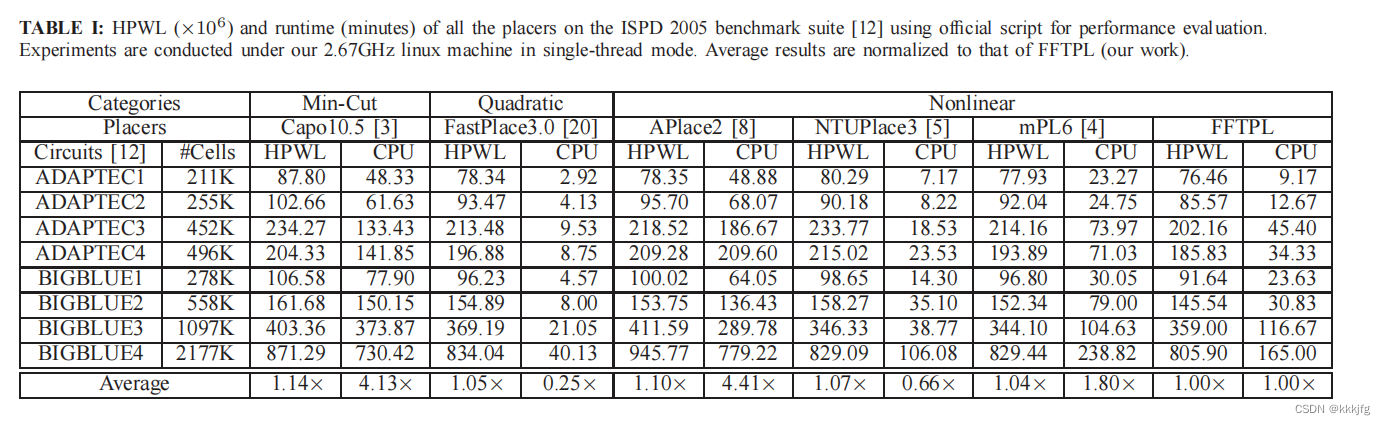
总结一下,如何用静电力来优化布局的方法?把各单元的位置当作一组参数,不断求线长损失和密度损失,其中密度损失用静电力建模,即把密度损失视为势能,先用各单元位置、面积求出不同bin的电荷密度,得到一个电荷密度map,然后使用快速傅里叶变换求出电场分布,最后就可以用电荷乘以电场得到电场力了,电场力就是密度损失的梯度。看上去就是提出了一种新的非线性目标函数罢了,而且把单元建模成电荷似乎很straightforward,但看上去就是有效果,质量和速度有着不错的结果。
ePlace
这里ePlace指ePlace-MS: Electrostatics-Based Placement for Mixed-Size Circuits
ePlace原文中说这篇工作是基于FFTPL这篇工作做的。看上去ePlace还进行了一定的扩展和微小的优化。
从流程上来说,ePlace把算法扩展到了detailed placement阶段。但在“Mixed-Size Global Placement”ePlace允许把宏单元无差别地一起进行计算,然后它有一个“Macro Legalization”阶段固定标准单元无视填充单元使用模拟退火优化宏单元位置,最后再插入填充单元,优化填充单元、同时优化填充单元与标准单元。
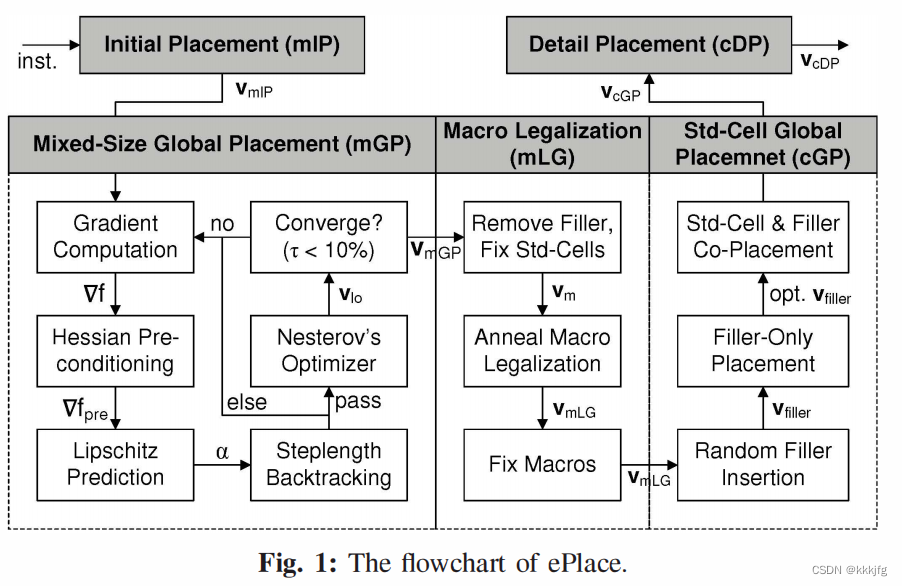
另外的一些优化包括ePlace使用了Nesterov’s method进行优化,而不再使用FFTPL的Conjugate Gradient优化策略了。
GPU的实现
这里介绍的是“DREAMPlace: Deep Learning Toolkit-Enabled GPU Acceleration for Modern VLSI Placement”这篇。这篇的原理是基于ePlace的,但是做了一些额外的优化。

这张图解释了DreamPlace怎么使用pytorch加速placement,
正常的神经网络的用法在左边,网络权重w是与输入无关的参数,会对输入(比如各种坐标)做处理和变换,预测出一组值f,再与标签y比对做loss,最后反向传播更新权重。
而DreamPlace更像是利用了这个GPU的框架做反向传播而已。DreamPlace里,各单元的x,y坐标就是神经网络的可学习参数w,对每个布局来说都要重新初始化。输入是各单元的特征信息e,可能是面积,引脚位置之类的信息,损失函数就是线长,反向传播的时候更新各单元位置即可。DreamPlace中,密度损失作为正则项出现(虽然感觉好像线长也可以作为正则项)。
总而言之,就是把单元位置当作权重不断更新,最后得到解。
然后DreamPlace有一些优化,比如作者发现算线长的时候有一些中间变量会重复计算。
先定义一个表,定义如下。
这里面规定了一些
a
+
,
a
−
,
b
+
,
b
−
a^+,a^-,b^+,b^-
a+,a−,b+,b−之类的值,然后这些值会在前向然后自动求导的过程中被重复计算。

其中前向与反向的一些依赖关系如下 :

可以看到WL的前向反向基本上大部分值都是需要算的,那么理清楚关系之后,可以先把中间变量a,b,c算出来,然后一起得到前向反向的结果,也可以在线长这项上直接算反向,反正前向算了也没用。改完之后的算法流程如下:

第二个优化是在算密度损失的时候引入了多线程和负载均衡。
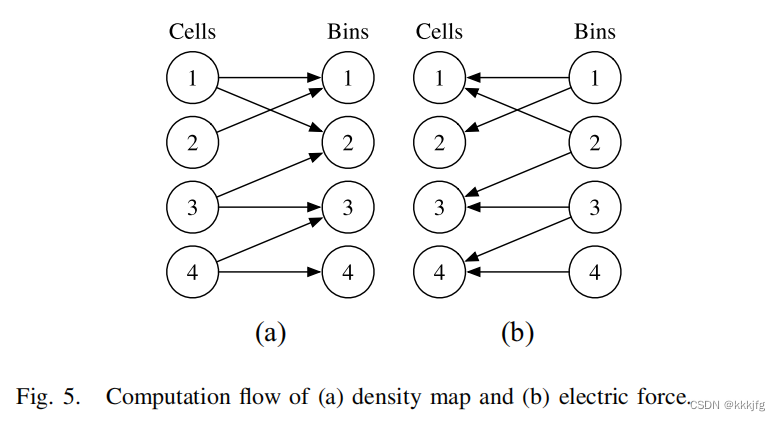
如图是算密度损失的时候各元件和各区域的相互关系,首先要让各单元与每个区域算重叠面积并累积,然后得到密度图,由密度图算出电场图后,各区域再根据重叠面积和场强对它上面重叠的单元施加一个作用力。
由于不同大小的单元能重叠的区域数不尽相同(10-1000),所以如果单纯的一个线程做一个cell的模拟是会造成负载不均衡,而影响性能的,所以这里作者使用了排序,让负载相近的模块一起计算,以平衡各线程的计算量。最后线程数作者是选择了32。
对于一些较大cell,这么做似乎还是不够,作者又尝试使用多个线程更新一个cell,发现22的配置是最好的(这里22与1*4有什么区别?可能是同时计算的区域的相对位置不一样?)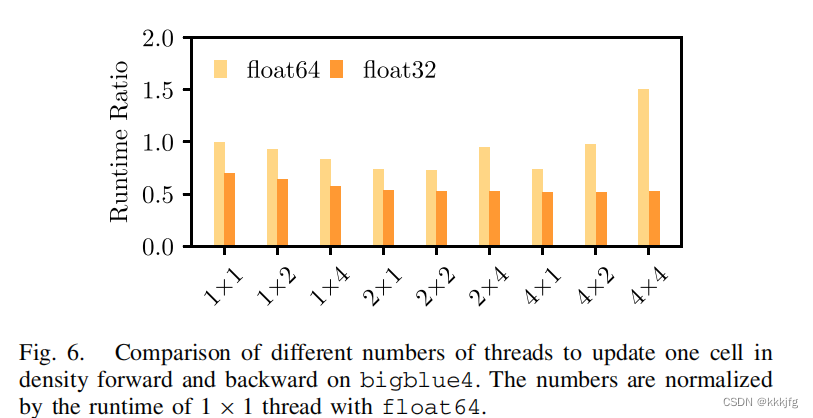
再后面就是介绍快速傅里叶变换求电场相关的优化了,这里没有看太懂。
GPU上进一步的优化
这里介绍:Xplace: An Extremely Fast and Extensible Global Placement Framework这篇文章。
Xplace在DreamPlace之上又做了更多优化。
-
Xplace采用了合并操作符的操作,把线长相关工作量的三个运算符WA线长、WA梯度和HPWL组合成一个运算符。
-
Xplace为了减少内核启动次数,采用了以下两点优化:
- 直接计算前向反向结果,不调用autograd进行计算(这点和DreamPlace似乎很像)。
- 尽可能使用PyTorch的“in-place operators”直接在张量内存上操作避免复制内存。
- 把同步操作放在操作队列队尾防止对GPU执行的中断。
-
“操作跳过”的优化,在密度损失和线长损失的梯度比 r = λ ∣ ∇ D x , y ∣ ∣ ∇ W l x , y ∣ r=\frac{\lambda |\nabla D_{x,y}|}{|\nabla Wl_{x,y}|} r=∣∇Wlx,y∣λ∣∇Dx,y∣过小或者是线长损失的梯度占主导地位的时候,所以直接不算了,节省计算量。
一套组合下来加速效果还是不错的:

能节省38%的时间。
Xplace还提出了一个架构:

在图下方的框里,求密度梯度
∇
D
p
\nabla_Dp
∇Dp的地方可以替换成一个神经网络算电场,而不是使用快速傅里叶变换进行运算。而且这个架构里求梯度的过程也能换成用户自定义的损失函数+自动求导的模式,相当于这里是一个可替换模块,这体现了这个工作的可扩展性。
图中的神经网络是“pixel-wise”的和输入密度图等大小的预测,且中间使用了pytorch自带的快速傅里叶变换和逆变换的算子,根据FNO(https://zhuanlan.zhihu.com/p/533488795)的介绍,这种操作可以提高模型在不同分辨率下的泛用性。
从上面的结果图来看,使用这个神经网络使得线长有些许的提升,虽然运行时间变长了,但这说明了使用神经网络代替某些操作提升精度的可行性,若后续还能有更好的网络还可以在这里进行替换以达到更好的效果。
总结
- 用静电力来建模单元之间的关系可行度很高
- global placement涉及很多优化,比如CG,Nesterov’s Method等,以及建模的时候涉及一些比如快速傅里叶变换之类的操作,对于数学功底不好的人来说(比如我)这些内容会有些吃力,不知道我碰到这些问题的时候是否还能一下子把正确快速的解给想出来。
- 机器学习在global placement上似乎还大有可为,不仅可以用GPU并行计算和加速已有的建模方法(DreamPlace,XPlace只是加速ePlace,不知其他的先进方法是否也适合使用gpu加速?),而且从混乱到有序的过程看起来挺像扩散模型的,感觉以后有可能会出现直接用模型预测global placement的作品?















 1424
1424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









