







1 大语言模型开发框架介绍
1.1 SDK和JDK介绍
-
什么是SDK(Software Development Kit,软件开发工具包)?
- 什么是 SDK?- SDK 详解 - AWS;
- 是一套工具集合,包含API、文档、示例代码、调试工具、库文件等,用于为特定平台或服务开发应用程序;
- 目标:简化开发流程,提供“一站式”解决方案(例如:Android SDK、iOS SDK);
- 本质:一个“工具箱”,可能包含多个API;
-
什么是API(Application Programming Interface,应用程序接口)?
- 是一套工具集合,包含API、文档、示例代码、调试工具、库文件等,用于为特定平台或服务开发应用程序;
- 目标:简化开发流程,提供“一站式”解决方案(例如:Android SDK、iOS SDK);
- 本质:一个“工具箱”,可能包含多个API;
-
区别:
特性 API SDK 范围 单一接口,仅定义交互规则 综合工具包,可能包含多个API 功能 实现特定功能调用(如数据请求) 提供开发所需的全套工具(如编译、测试) 使用场景 需要与其他系统交互时(如支付接口) 需要从头开发应用时(如开发微信小程序) 体积 轻量(仅代码调用规则) 庞大(可能包含IDE、模拟器等) -
关联性:
- SDK通常包含API:例如,Facebook SDK会封装其Graph API,方便开发者直接调用;
- API不依赖SDK:可以直接调用API(如通过HTTP请求访问RESTful API),但SDK会让调用更便捷(例如封装了认证、错误处理等);
-
类比解释:
- API像“点餐菜单”:你按菜单规则下单(调用),餐厅返回菜品(数据);
- SDK像“厨房套装”:不仅提供菜单,还附赠锅铲(工具)、菜谱(文档)、食材(库文件),让你能自己做饭(开发应用);
-
实际例子:
- API示例:调用Twitter的API发送一条推文;
- SDK示例:使用Unity SDK开发游戏,其中包含图形渲染API、物理引擎API等;
-
总结:
- 用API:当你需要快速集成某个功能(如地图、支付);
- 用SDK:当你需要为特定平台(如华为鸿蒙)或服务(如AWS)开发完整应用。
1.2 大语言模型开发框架的核心价值与特点
-
大语言模型开发框架(如 LangChain、LlamaIndex、Semantic Kernel 等)的核心目标是降低基于 LLM 的应用开发成本,让开发者能够更高效、稳定地构建 AI 驱动的应用;
-
核心价值:降低开发与维护成本
- 减少重复工作:封装通用模式(如对话管理、RAG 流程),避免开发者重复造轮子;
- 提升稳定性:处理底层复杂性(如 API 错误重试、流式响应),减少崩溃风险;
- 加速迭代:通过模块化设计,快速更换组件(如 LLM、数据库)而不影响整体架构;
-
主要功能分类:
- 第三方能力抽象
- 统一调用不同 LLM。例如:通过框架的
ChatModel接口,无缝切换 OpenAI GPT、Anthropic Claude 或本地部署的 Llama3,无需修改业务代码; - 集成外部工具。向量数据库(Pinecone、Milvus)、搜索引擎(Google、Bing)、知识图谱等,提供标准化操作方式;
- 多模态支持。封装文本、图像、语音等模型的调用(如 GPT-4V、Whisper);
- 统一调用不同 LLM。例如:通过框架的
- 常用工具与方案封装
- Prompt 管理。支持模板化、变量注入、版本控制(避免硬编码 Prompt);
- RAG(检索增强生成)流程。自动处理文档分块、向量化、检索、上下文注入等步骤;
- 记忆(Memory)与会话管理。自动维护聊天历史(如短期记忆、长期记忆存储);
- 底层实现封装
- 流式传输(Streaming)。直接提供逐字输出的接口,无需手动处理 SSE(Server-Sent Events);
- 容错与重试机制。自动处理 API 限流、超时、临时错误(如指数退避重试);
- 异步与并行。支持并发调用多个 LLM 或工具(如同时查询天气和新闻);
- 第三方能力抽象
-
优秀框架的特点:
- 可靠性 & 鲁棒性
- 输入合法性检查:非法输入触发明确错误,而非框架崩溃;
- 失败降级策略:例如 LLM 调用失败时自动切换备用模型;
- 可维护性
- 模块化设计:如更换向量数据库只需修改配置文件,无需改动代码;
- 清晰的文档:提供快速上手指南、最佳实践和故障排查方案;
- 可扩展性
- 自定义工具集成:允许开发者添加私有化工具(如内部知识库);
- 插件系统:社区可贡献扩展(类似 LangChain 的 Tools 生态);
- 低学习成本
- 直观的 API 设计:例如链式调用(
chain = prompt | llm | output_parser); - 可视化调试:提供日志、跟踪工具(如 LangSmith 的调用链路分析)。
- 直观的 API 设计:例如链式调用(
- 可靠性 & 鲁棒性
-
典型场景示例:
- 场景 1:快速切换 LLM 供应商
- 无框架时:从 GPT-4 切换到 Claude3 需重写 API 调用、参数调整、错误处理逻辑;
- 有框架时:仅需修改配置文件的
model_name字段;
- 场景 2:构建一个客服机器人
- 无框架:手动拼接 Prompt、管理会话历史、处理超时;
- 有框架:直接使用
ConversationChain,自动处理上下文记忆和流式响应;
- 场景 3:调试与测试
- 无框架:需要 Mock API 响应、手动验证 Prompt 效果;
- 有框架:内置测试工具(如 LangChain 的
LLMChecker检测有害输出);
- 场景 1:快速切换 LLM 供应商
-
主流 LLM 开发框架:
框架 特点 LangChain 生态丰富,支持链(Chains)、代理(Agents)、工具(Tools)等复杂逻辑。 LlamaIndex 专注 RAG 场景,优化文档检索与上下文注入。 Semantic Kernel 微软推出,深度集成 Azure AI,适合企业级应用。 Haystack 侧重搜索与问答系统,支持管道(Pipeline)式流程。
2 LlamaIndex
2.1 介绍
-
LlamaIndex(原名为GPT Index)是一个专为高效检索和增强大型语言模型(LLM)应用而设计的开源数据框架。它的核心目标是帮助开发者将私有或特定领域的数据与LLM(如GPT-4、Llama 2等)结合,构建基于知识的问答、聊天机器人或数据分析工具;
-
LlamaIndex是一个开源框架:LlamaIndex · GitHub;
-
主要功能与特点:
- 数据连接与索引:支持从多种数据源(PDF、Word、数据库、API、网页等)摄取数据,并自动构建结构化索引(如向量索引、关键词索引、树状索引等),加速查询效率;
- 检索增强生成(RAG):通过检索与用户查询相关的上下文信息,将其注入LLM的生成过程,显著提升回答的准确性和针对性,避免“幻觉”问题;
- 多模态支持:不仅处理文本,还可结合图像、音频等数据(需配合其他工具),扩展应用场景;
- 灵活的查询接口:提供高级API,支持复杂查询逻辑,如多跳问答、对比查询、结构化输出等;
- 轻量级与可扩展:可与其他工具链(如LangChain、Hugging Face)集成,适配不同规模的LLM和部署环境;
-
典型应用场景:
- 企业知识库:快速检索内部文档、手册或报告;
- 学术研究:基于论文或数据集构建智能问答系统;
- 个性化推荐:结合用户历史数据生成定制化内容;
-
与类似工具(如LangChain)的区别:
- LlamaIndex更专注于高效检索与索引优化,适合以数据为中心的RAG场景;
- LangChain提供更广泛的流程编排和模块化组件,适合复杂应用开发;
-
LlamaIndex 有 Python 和 Typescript 两个版本,Python 版的文档相对更完善;
- Python 文档地址:LlamaIndex - LlamaIndex;
- Python API 接口文档:API Reference - LlamaIndex;
-
Python 安装 LlamaIndex:
pip install llama-index
2.2 本质
- LlamaIndex 的本质:一个「上下文增强」的框架(SDK)
- 核心目标:解决大语言模型(LLM)的“知识局限性”问题。LLM 本身缺乏私有或实时数据(如企业文档、个人笔记、最新行业报告等),而 LlamaIndex 提供工具将这些数据高效整合到 LLM 的生成过程中;
- 技术逻辑:
- 索引(Indexing):将原始数据(文档、数据库等)转化为结构化、可快速检索的格式(如向量索引、关键词索引);
- 检索(Retrieval):根据用户查询,从索引中精准提取相关上下文片段;
- 增强生成(Augmentation):将检索到的上下文作为提示(Prompt)的一部分输入 LLM,使生成结果基于特定数据而非仅依赖模型预训练知识;
- 「上下文增强」的三大典型场景:
- Question-Answering Chatbots (RAG)
- 问题:通用 LLM 无法回答私有领域问题(如“公司今年的销售目标是什么?”);
- LlamaIndex 方案:
- 索引企业内部文档(PDF/Excel/数据库等);
- 用户提问时,先检索相关文档片段,再让 LLM 生成答案;
- 优势:答案精准、可溯源,避免“胡编乱造”(幻觉);
- 示例:客服机器人、技术文档助手;
- Document Understanding and Extraction(文档理解与信息抽取)
- 问题:从复杂文档(合同、论文)中提取结构化信息(如条款、关键数据)需要人工阅读,效率低;
- LlamaIndex 方案:
- 通过索引分割文档内容(如按章节/表格),结合 LLM 的语义理解能力,自动回答“这份合同的违约金条款是什么?”或“论文的实验结果有哪些?”;
- 优势:比传统 OCR/NLP 工具更灵活,适应非标准化文档;
- Autonomous Agents (智能体应用)
- 问题:让 AI 自动执行多步骤任务(如“调研某竞品的最新动态并总结”),需结合实时数据和行动能力;
- LlamaIndex 方案:
- 索引网络爬虫数据、内部知识库,作为智能体的“记忆”;
- 通过检索增强的 LLM 规划行动(如先搜索、再分析、最后生成报告);
- 优势:减少人工干预,动态整合最新信息;
- Question-Answering Chatbots (RAG)
- 与其他技术的区别:
- vs 传统数据库检索:LlamaIndex 不仅返回原始数据片段,还能让 LLM 理解并加工信息(如总结、对比、推理);
- vs 直接微调(Fine-tuning)LLM:上下文增强无需重新训练模型,成本更低,且支持动态更新数据(微调需反复训练)。
2.3 大语言模型(LLM)应用的数据交互流程图
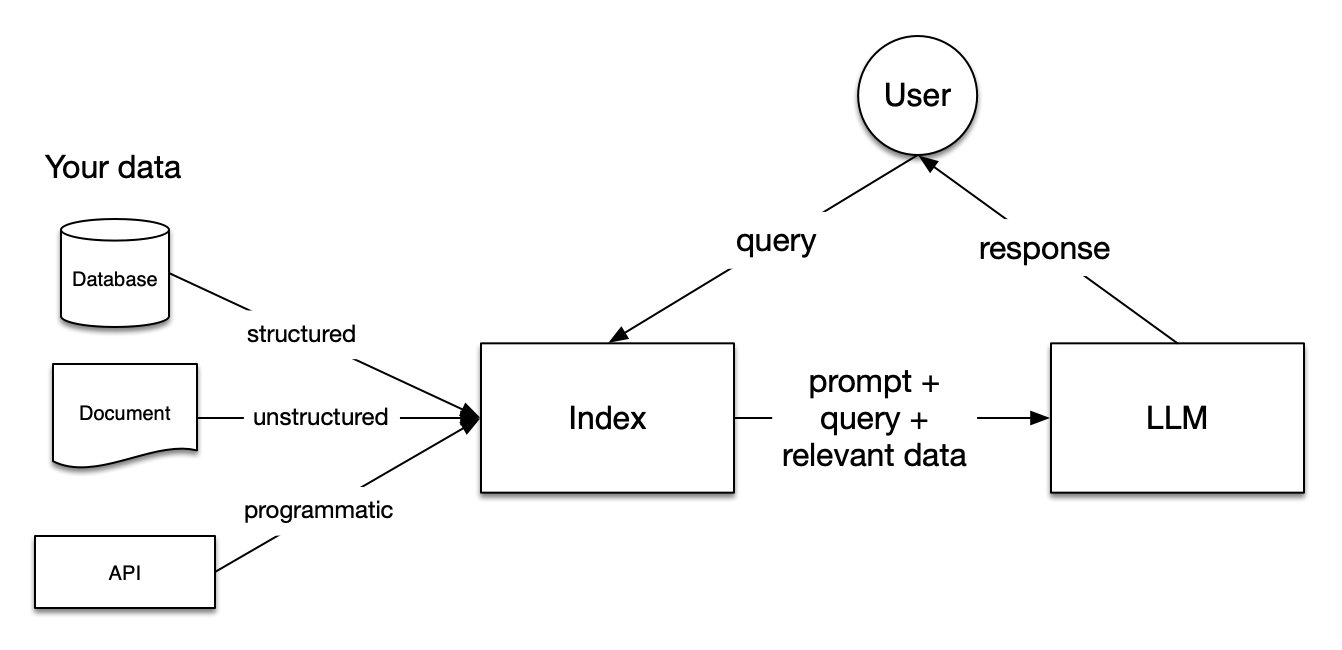
- 数据来源:
- Database(数据库):提供结构化(structured)数据 ,是一种有序、规整存储的数据形式,便于按照既定规则进行查询和管理;
- Document(文档):提供非结构化(unstructured)数据,像文本文件、报告等,数据缺乏预定义结构,需要进一步处理分析;
- API(应用程序接口):提供程序化(programmatic)数据,通过编程接口获取数据,可实现系统间灵活的数据交互;
- 核心组件:
- Index(索引):接收来自不同数据源的数据,对其进行处理整合,建立便于快速检索的索引结构 。当收到用户查询(query)时,能依据索引快速定位相关数据;
- LLM(大语言模型):接收由索引模块传来的提示词(prompt)、用户查询(query)以及相关数据,进行理解、推理和生成响应(response),返回给用户;
- 交互流程:
- 用户发起查询:用户(User)向系统发出查询请求(query);
- 索引处理:索引模块接收查询,从各类数据源整合相关数据,并将查询与相关数据组合成合适格式,传递给大语言模型;
- LLM 生成响应:大语言模型基于接收到的信息进行处理,生成响应内容(response),反馈给用户 。
2.4 LlamaIndex 的核心模块
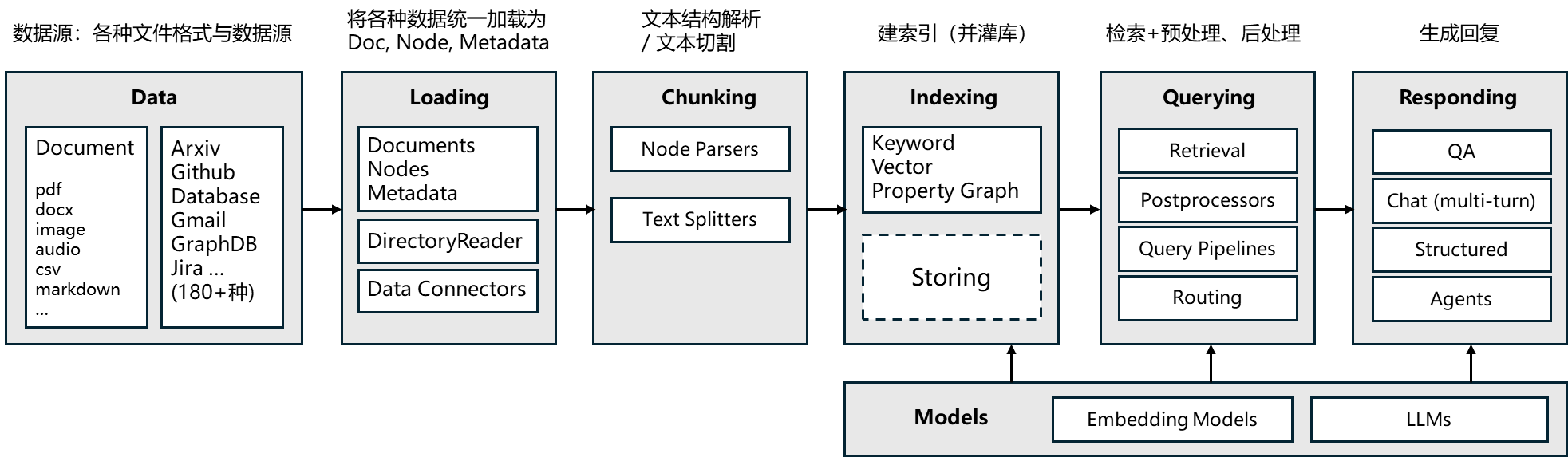
-
Data(数据):支持多种文件格式(如 pdf、docx 等)和数据源(如 Arxiv、Github 等 180 + 种) ,作为整个流程的数据输入基础;
-
Loading(加载):将各种数据源的数据统一加载为 Documents(文档)、Nodes(节点)和 Metadata(元数据) 。DirectoryReader(目录读取器)和 Data Connectors(数据连接器)辅助完成数据加载工作;
-
Chunking(分块):
- Node Parsers(节点解析器):对加载的数据进行文本结构解析;
- Text Splitters(文本分割器):将文本分割成合适的小块,便于后续处理;
-
Indexing(索引):
- Keyword(关键词):基于关键词建立索引;
- Vector(向量):生成向量表示,便于语义检索;
- Property Graph(属性图):构建属性图结构存储数据关系;
- Storing(存储):将索引后的数据存储起来(虚线框表示存储功能);
-
Querying(查询):
- Retrieval(检索):根据用户查询从索引中检索相关信息;
- Postprocessors(后处理器):对检索结果进行后处理;
- Query Pipelines(查询管道):定义查询执行的流程;
- Routing(路由):决定查询请求的流向;
-
Responding(回复):
- QA(问答):处理问答形式的交互;
- Chat (multi - turn)(多轮对话):支持多轮对话场景;
- Structured(结构化输出):以结构化形式输出结果;
- Agents(智能体):借助智能体执行更复杂的任务;
-
Models(模型):
- Embedding Models(嵌入模型):生成文本嵌入向量,用于相似性计算等;
- LLMs(大语言模型):作为核心语言模型,用于生成回复等任务 。
3 数据加载(Loading)
3.1 SimpleDirectoryReader加载本地数据
-
SimpleDirectoryReader是一个简单的本地文件加载器。它会遍历指定目录,并根据文件扩展名自动加载文件(文本内容);- **注意:**对图像、视频、语音类文件,默认不会自动提取其中文字。如需提取,参考下节介绍的
Data Connectors;
- **注意:**对图像、视频、语音类文件,默认不会自动提取其中文字。如需提取,参考下节介绍的
-
支持的文件类型:
.csv- comma-separated values.docx- Microsoft Word.epub- EPUB ebook format.hwp- Hangul Word Processor.ipynb- Jupyter Notebook.jpeg,.jpg- JPEG image.mbox- MBOX email archive.md- Markdown.mp3,.mp4- audio and video.pdf- Portable Document Format.png- Portable Network Graphics.ppt,.pptm,.pptx- Microsoft PowerPoint
-
先准备两个函数:
import json from pydantic.v1 import BaseModel # 用于展示json数据 def show_json(data): if isinstance(data, str): obj = json.loads(data) print(json.dumps(obj, indent=4, ensure_ascii=False)) elif isinstance(data, dict) or isinstance(data, list): print(json.dumps(data, indent=4, ensure_ascii=False)) elif issubclass(type(data), BaseModel): print(json.dumps(data.dict(), indent=4, ensure_ascii=False)) # 用于展示一组对象 def show_list_obj(data): if isinstance(data, list): for item in data: show_json(item) else: raise ValueError("Input is not a list") -
例:
from llama_index.core import SimpleDirectoryReader reader = SimpleDirectoryReader( input_dir="./data", # 目标目录 recursive=False, # 是否递归遍历子目录 required_exts=[".pdf"] # (可选)只读取指定后缀的文件 ) documents = reader.load_data() print(documents[0].text) show_json(documents[0].json()) -
结果:
Llama 2: Open Foundation and Fine-Tuned Chat Models Hugo Touvron∗ Louis Martin† Kevin Stone† Peter Albert Amjad Almahairi Yasmine Babaei Nikolay Bashlykov Soumya Batra Prajjwal Bhargava Shruti Bhosale Dan Bikel Lukas Blecher Cristian Canton Ferrer Moya Chen Guillem Cucurull David Esiobu Jude Fernandes Jeremy Fu Wenyin Fu Brian Fuller Cynthia Gao Vedanuj Goswami Naman Goyal Anthony Hartshorn Saghar Hosseini Rui Hou Hakan Inan Marcin Kardas Viktor Kerkez Madian Khabsa Isabel Kloumann Artem Korenev Punit Singh Koura Marie-Anne Lachaux Thibaut Lavril Jenya Lee Diana Liskovich Yinghai Lu Yuning Mao Xavier Martinet Todor Mihaylov Pushkar Mishra Igor Molybog Yixin Nie Andrew Poulton Jeremy Reizenstein Rashi Rungta Kalyan Saladi Alan Schelten Ruan Silva Eric Michael Smith Ranjan Subramanian Xiaoqing Ellen Tan Binh Tang Ross Taylor Adina Williams Jian Xiang Kuan Puxin Xu Zheng Yan Iliyan Zarov Yuchen Zhang Angela Fan Melanie Kambadur Sharan Narang Aurelien Rodriguez Robert Stojnic Sergey Edunov Thomas Scialom∗ GenAI, Meta Abstract In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, calledLlama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed- source models. We provide a detailed description of our approach to fine-tuning and safety improvements ofLlama 2-Chatin order to enable the community to build on our work and contribute to the responsible development of LLMs. ∗Equal contribution, corresponding authors: {tscialom, htouvron}@meta.com †Second author Contributions for all the authors can be found in Section A.1. arXiv:2307.09288v2 [cs.CL] 19 Jul 2023 { "id_": "93d1858c-8aab-4516-92a9-7678eb31c58e", "embedding": null, "metadata": { "page_label": "1", "file_name": "llama2-extracted.pdf", "file_path": "C:\\Users\\22263\\Desktop\\Project\\ai-full-stack-engineer\\7_LlamaIndex\\data\\llama2-extracted.pdf", "file_type": "application/pdf", "file_size": 401338, "creation_date": "2025-04-16", "last_modified_date": "2024-06-14" }, "excluded_embed_metadata_keys": [ "file_name", "file_type", "file_size", "creation_date", "last_modified_date", "last_accessed_date" ], "excluded_llm_metadata_keys": [ "file_name", "file_type", "file_size", "creation_date", "last_modified_date", "last_accessed_date" ], "relationships": {}, "metadata_template": "{key}: {value}", "metadata_separator": "\n", "text_resource": { "embeddings": null, "text": "Llama 2: Open Foundation and Fine-Tuned Chat Models\nHugo Touvron∗ Louis Martin† Kevin Stone†\nPeter Albert Amjad Almahairi Yasmine Babaei Nikolay Bashlykov Soumya Batra\nPrajjwal Bhargava Shruti Bhosale Dan Bikel Lukas Blecher Cristian Canton Ferrer Moya Chen\nGuillem Cucurull David Esiobu Jude Fernandes Jeremy Fu Wenyin Fu Brian Fuller\nCynthia Gao Vedanuj Goswami Naman Goyal Anthony Hartshorn Saghar Hosseini Rui Hou\nHakan Inan Marcin Kardas Viktor Kerkez Madian Khabsa Isabel Kloumann Artem Korenev\nPunit Singh Koura Marie-Anne Lachaux Thibaut Lavril Jenya Lee Diana Liskovich\nYinghai Lu Yuning Mao Xavier Martinet Todor Mihaylov Pushkar Mishra\nIgor Molybog Yixin Nie Andrew Poulton Jeremy Reizenstein Rashi Rungta Kalyan Saladi\nAlan Schelten Ruan Silva Eric Michael Smith Ranjan Subramanian Xiaoqing Ellen Tan Binh Tang\nRoss Taylor Adina Williams Jian Xiang Kuan Puxin Xu Zheng Yan Iliyan Zarov Yuchen Zhang\nAngela Fan Melanie Kambadur Sharan Narang Aurelien Rodriguez Robert Stojnic\nSergey Edunov Thomas Scialom∗\nGenAI, Meta\nAbstract\nIn this work, we develop and release Llama 2, a collection of pretrained and fine-tuned\nlarge language models (LLMs) ranging in scale from 7 billion to 70 billion parameters.\nOur fine-tuned LLMs, calledLlama 2-Chat, are optimized for dialogue use cases. Our\nmodels outperform open-source chat models on most benchmarks we tested, and based on\nour human evaluations for helpfulness and safety, may be a suitable substitute for closed-\nsource models. We provide a detailed description of our approach to fine-tuning and safety\nimprovements ofLlama 2-Chatin order to enable the community to build on our work and\ncontribute to the responsible development of LLMs.\n∗Equal contribution, corresponding authors: {tscialom, htouvron}@meta.com\n†Second author\nContributions for all the authors can be found in Section A.1.\narXiv:2307.09288v2 [cs.CL] 19 Jul 2023", "path": null, "url": null, "mimetype": null }, "image_resource": null, "audio_resource": null, "video_resource": null, "text_template": "{metadata_str}\n\n{content}", "class_name": "Document", "text": "Llama 2: Open Foundation and Fine-Tuned Chat Models\nHugo Touvron∗ Louis Martin† Kevin Stone†\nPeter Albert Amjad Almahairi Yasmine Babaei Nikolay Bashlykov Soumya Batra\nPrajjwal Bhargava Shruti Bhosale Dan Bikel Lukas Blecher Cristian Canton Ferrer Moya Chen\nGuillem Cucurull David Esiobu Jude Fernandes Jeremy Fu Wenyin Fu Brian Fuller\nCynthia Gao Vedanuj Goswami Naman Goyal Anthony Hartshorn Saghar Hosseini Rui Hou\nHakan Inan Marcin Kardas Viktor Kerkez Madian Khabsa Isabel Kloumann Artem Korenev\nPunit Singh Koura Marie-Anne Lachaux Thibaut Lavril Jenya Lee Diana Liskovich\nYinghai Lu Yuning Mao Xavier Martinet Todor Mihaylov Pushkar Mishra\nIgor Molybog Yixin Nie Andrew Poulton Jeremy Reizenstein Rashi Rungta Kalyan Saladi\nAlan Schelten Ruan Silva Eric Michael Smith Ranjan Subramanian Xiaoqing Ellen Tan Binh Tang\nRoss Taylor Adina Williams Jian Xiang Kuan Puxin Xu Zheng Yan Iliyan Zarov Yuchen Zhang\nAngela Fan Melanie Kambadur Sharan Narang Aurelien Rodriguez Robert Stojnic\nSergey Edunov Thomas Scialom∗\nGenAI, Meta\nAbstract\nIn this work, we develop and release Llama 2, a collection of pretrained and fine-tuned\nlarge language models (LLMs) ranging in scale from 7 billion to 70 billion parameters.\nOur fine-tuned LLMs, calledLlama 2-Chat, are optimized for dialogue use cases. Our\nmodels outperform open-source chat models on most benchmarks we tested, and based on\nour human evaluations for helpfulness and safety, may be a suitable substitute for closed-\nsource models. We provide a detailed description of our approach to fine-tuning and safety\nimprovements ofLlama 2-Chatin order to enable the community to build on our work and\ncontribute to the responsible development of LLMs.\n∗Equal contribution, corresponding authors: {tscialom, htouvron}@meta.com\n†Second author\nContributions for all the authors can be found in Section A.1.\narXiv:2307.09288v2 [cs.CL] 19 Jul 2023" }
3.2 其它文件加载器
-
若默认的
PDFReader效果并不理想,可以更换文件加载器; -
安装包:
pip install pymupdf -
例:
from llama_index.core import SimpleDirectoryReader from llama_index.readers.file import PyMuPDFReader reader = SimpleDirectoryReader( input_dir="./data", # 目标目录 recursive=False, # 是否递归遍历子目录 required_exts=[".pdf"], # (可选)只读取指定后缀的文件 file_extractor={".pdf": PyMuPDFReader()} # 指定特定的文件加载器 ) documents = reader.load_data() print(documents[0].text) -
结果:
Llama 2: Open Foundation and Fine-Tuned Chat Models Hugo Touvron∗ Louis Martin† Kevin Stone† Peter Albert Amjad Almahairi Yasmine Babaei Nikolay Bashlykov Soumya Batra Prajjwal Bhargava Shruti Bhosale Dan Bikel Lukas Blecher Cristian Canton Ferrer Moya Chen Guillem Cucurull David Esiobu Jude Fernandes Jeremy Fu Wenyin Fu Brian Fuller Cynthia Gao Vedanuj Goswami Naman Goyal Anthony Hartshorn Saghar Hosseini Rui Hou Hakan Inan Marcin Kardas Viktor Kerkez Madian Khabsa Isabel Kloumann Artem Korenev Punit Singh Koura Marie-Anne Lachaux Thibaut Lavril Jenya Lee Diana Liskovich Yinghai Lu Yuning Mao Xavier Martinet Todor Mihaylov Pushkar Mishra Igor Molybog Yixin Nie Andrew Poulton Jeremy Reizenstein Rashi Rungta Kalyan Saladi Alan Schelten Ruan Silva Eric Michael Smith Ranjan Subramanian Xiaoqing Ellen Tan Binh Tang Ross Taylor Adina Williams Jian Xiang Kuan Puxin Xu Zheng Yan Iliyan Zarov Yuchen Zhang Angela Fan Melanie Kambadur Sharan Narang Aurelien Rodriguez Robert Stojnic Sergey Edunov Thomas Scialom∗ GenAI, Meta Abstract In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed- source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs. ∗Equal contribution, corresponding authors: {tscialom, htouvron}@meta.com †Second author Contributions for all the authors can be found in Section A.1. arXiv:2307.09288v2 [cs.CL] 19 Jul 2023 -
更多的 PDF 加载器还有
SmartPDFLoader和LlamaParse,二者都提供了更丰富的解析能力,包括解析章节与段落结构等。但不是 100%准确,偶有文字丢失或错位情况,建议根据自身需求详细测试评估。
3.3 飞书文档 API 访问权限申请
-
下面讲解飞书文档 API 访问权限申请,便于
3.4 Data Connectors的讲解; -
申请地址:开发者后台 - 飞书开放平台;
-
点击【创建企业自建应用】创建应用:
-
填写创建应用的相关信息:
-
创建成功后,在【凭证与基础信息】中可以看到【AppID】和【AppSecret】;
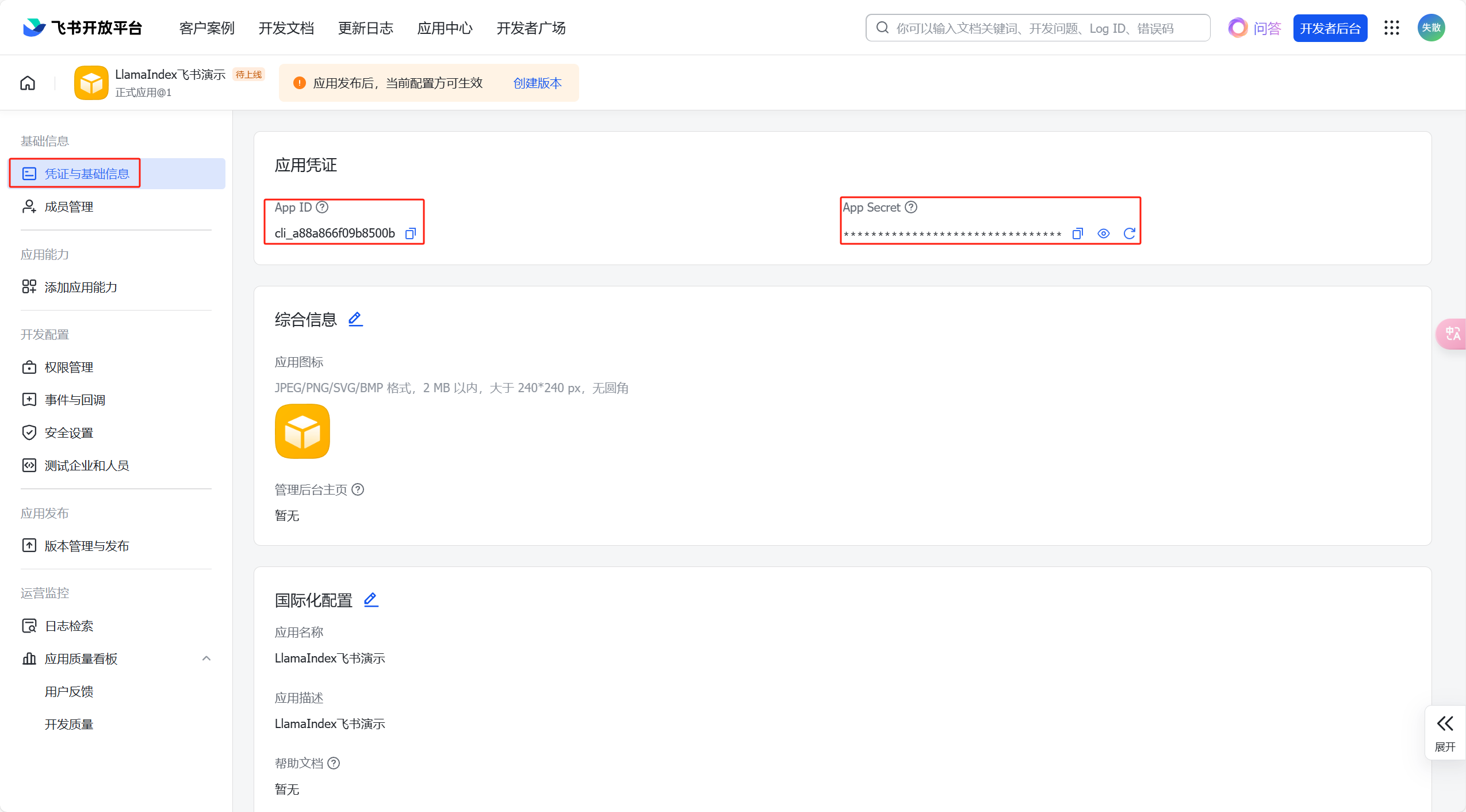
-
选择【添加应用能力】,点击【机器人】;
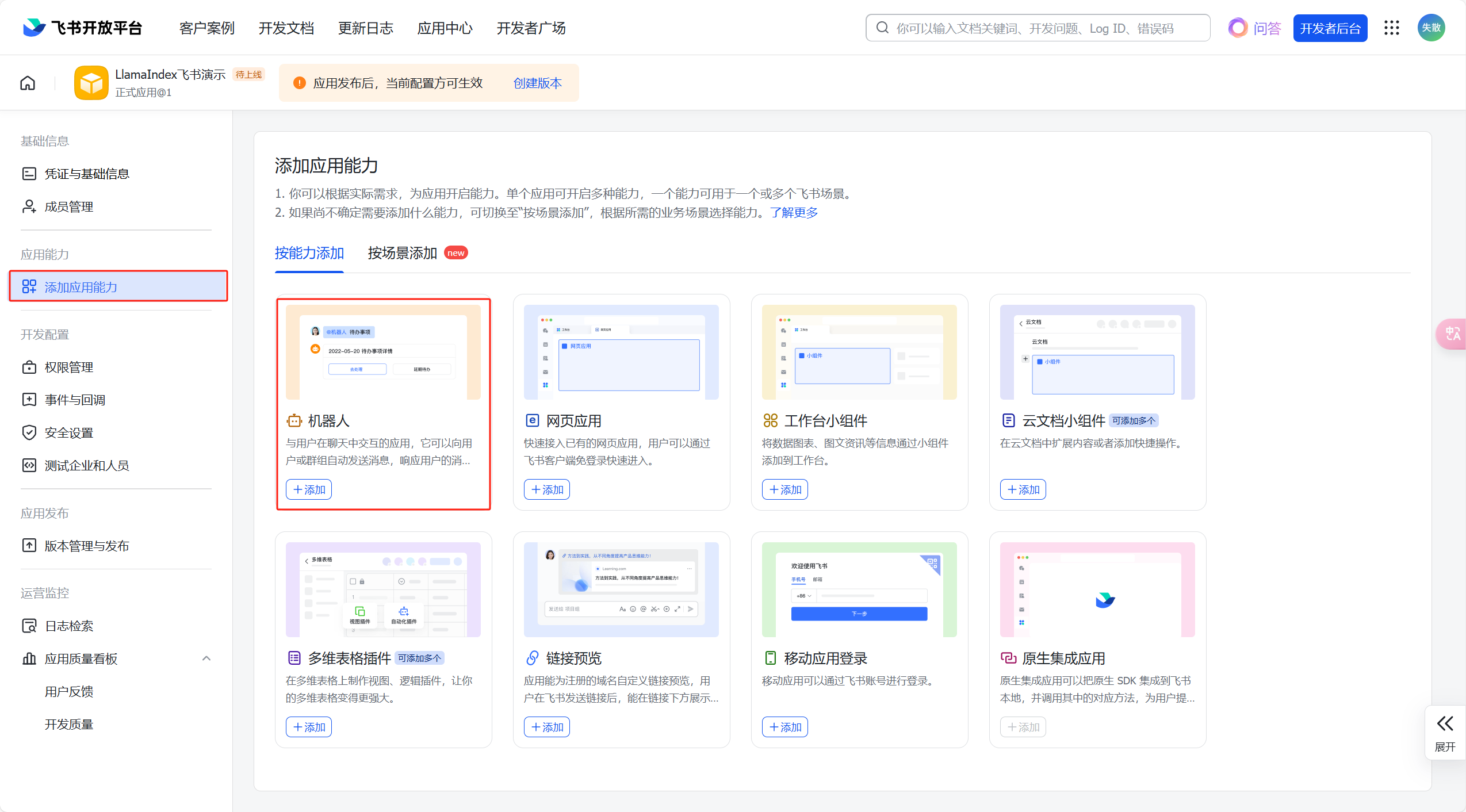
-
然后左侧的【添加应用能力】会多一个【机器人】;

-
-
点击【权限管理】—>【开通权限】—>搜索【查看新版文档】—>【确认开通权限】;
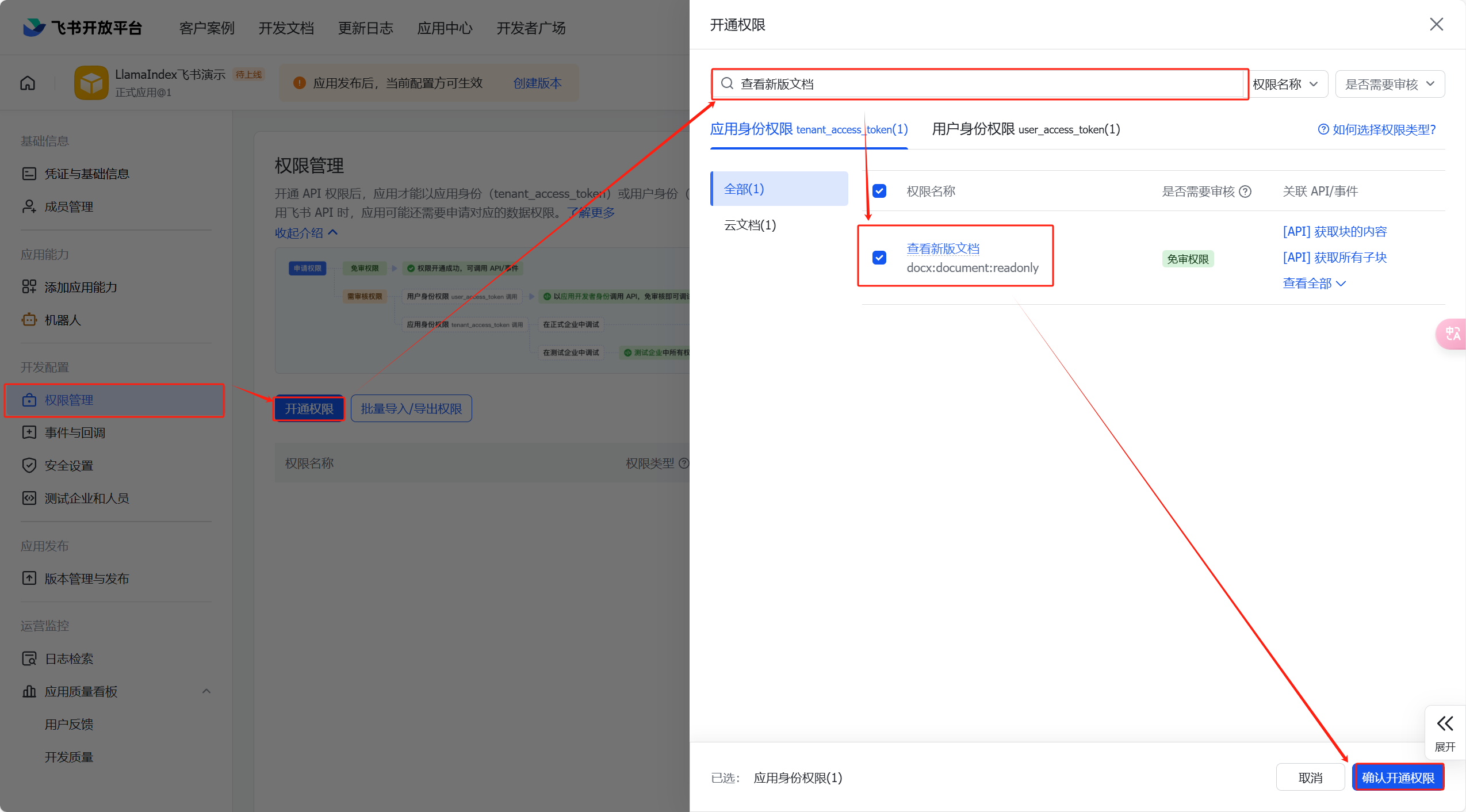
-
将【权限类型】切换成【应用身份权限】即可看到:
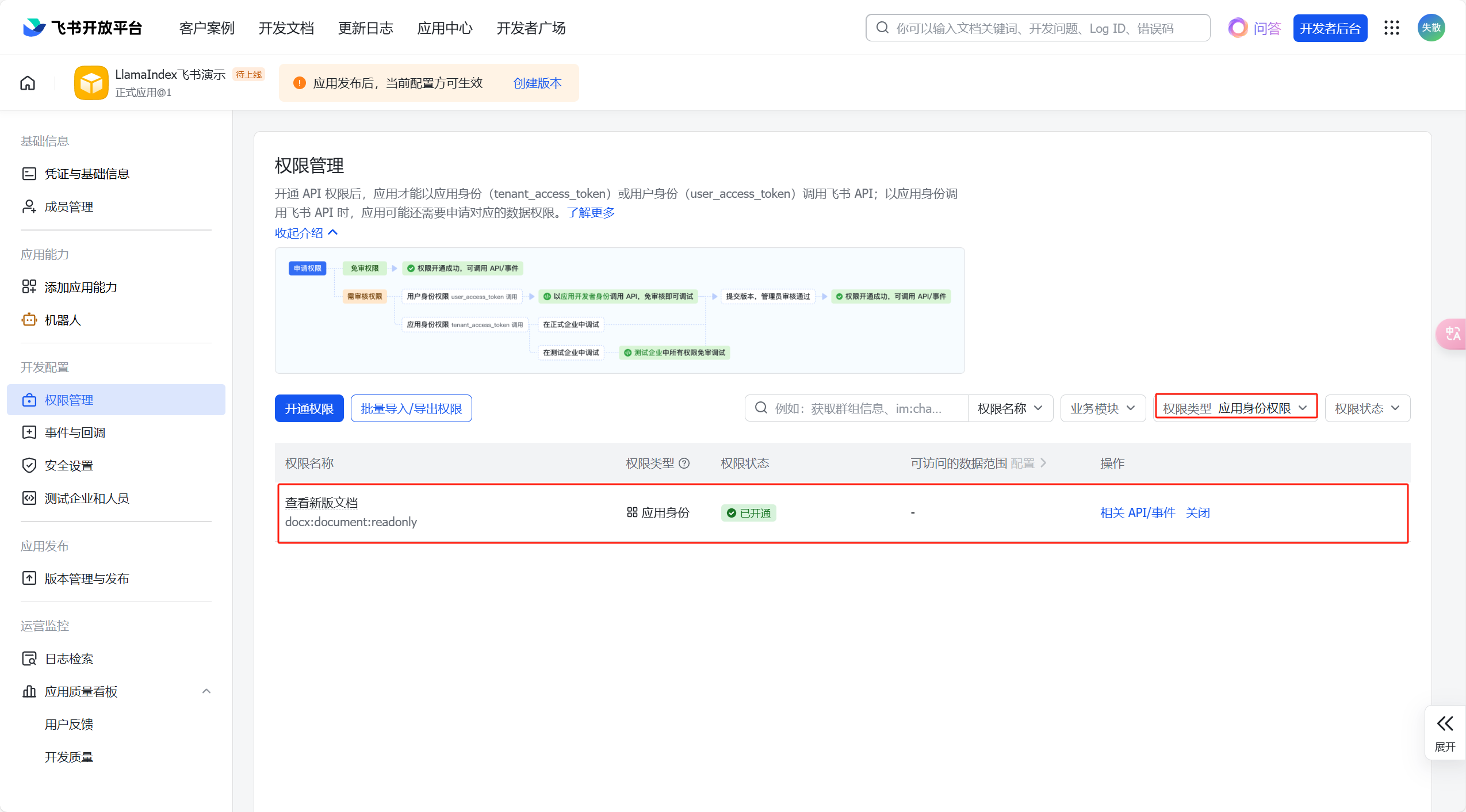
-
-
点击【版本管理与发布】—>【创建版本】:
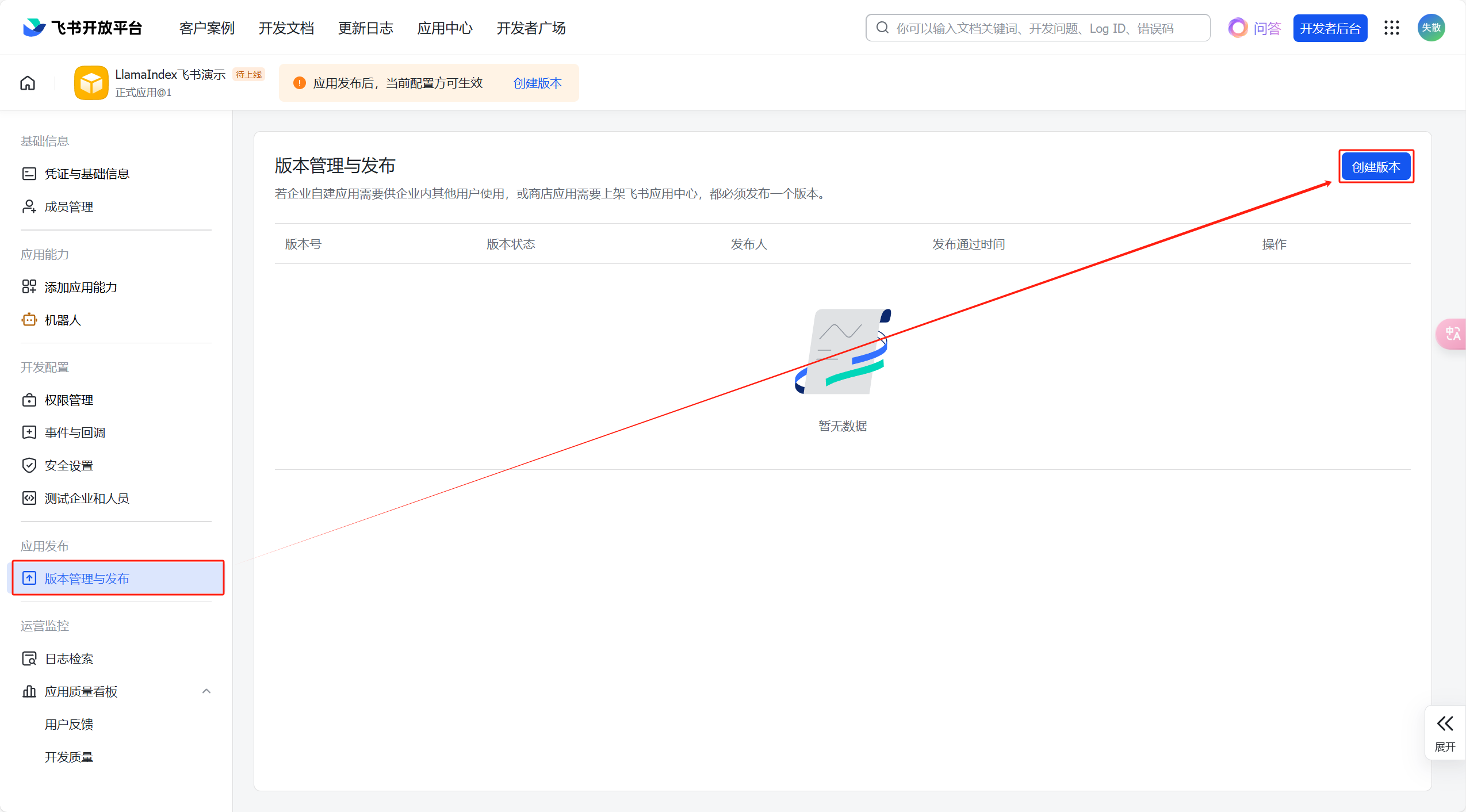
-
输入相关信息后,滑动鼠标滚轮,点击最下面的【保存】;
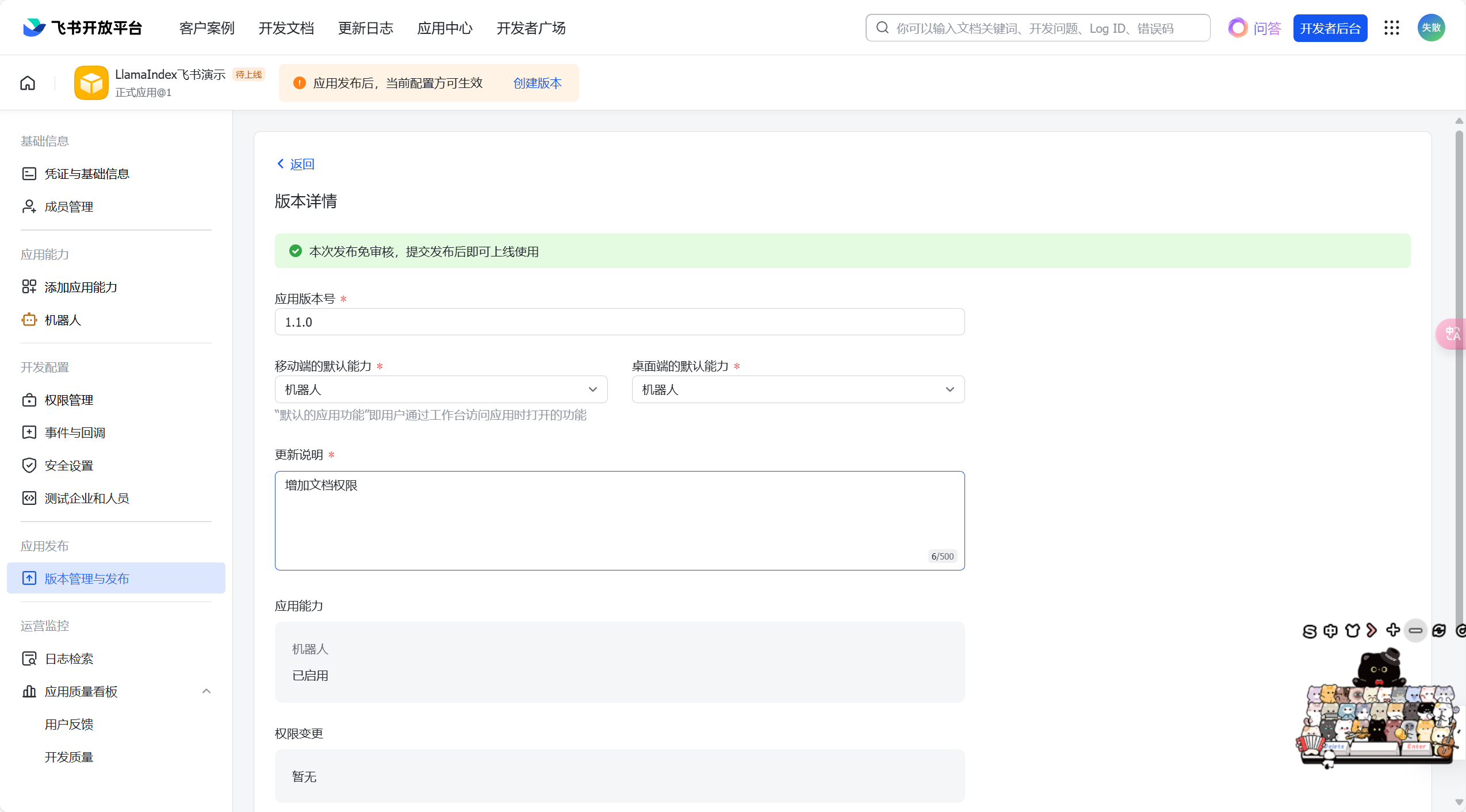
3.4 Data Connectors
-
若要处理更丰富的数据类型,并将其读取为
Document的形式(text + metadata),可以使用Data Connectors; -
例如:加载一个飞书文档;
- 飞书文档 API 访问权限申请,参考
3.3 飞书文档 API 访问权限申请;
- 飞书文档 API 访问权限申请,参考
-
安装包:
pip install llama-index-readers-feishu-docs -
例:
from llama_index.readers.feishu_docs import FeishuDocsReader app_id = "cli_a88a866f09b8500b" app_secret = "VO2mW3Lr3pz4IGuurqwRVeLZ7emGmtgr" # https://agiclass.feishu.cn/docx/FULadzkWmovlfkxSgLPcE4oWnPf # 上面链接最后的 "FULadzkWmovlfkxSgLPcE4oWnPf" 为文档 ID doc_ids = ["FULadzkWmovlfkxSgLPcE4oWnPf"] # 定义飞书文档加载器 loader = FeishuDocsReader(app_id, app_secret) # 加载文档 documents = loader.load_data(document_ids=doc_ids) # 显示前1000字符 print(documents[0].text[:1000]) -
结果:
AI 大模型全栈工程师培养计划 - AGIClass.ai 由 AGI 课堂推出的社群型会员制课程,传授大模型的原理、应用开发技术和行业认知,助你成为 ChatGPT 浪潮中的超级个体 什么是 AI 大模型全栈工程师? 「AI 大模型全栈工程师」简称「AI 全栈」,是一个人就能借助 AI,设计、开发和运营基于 AI 的大模型应用的超级个体。 AI 全栈需要懂业务、懂 AI、懂编程,一个人就是一个团队,单枪匹马创造财富。 在技术型公司,AI 全栈最懂 AI,瞬间站上技术顶峰。 在非技术型公司,AI 全栈连接其他员工和 AI,提升整个公司的效率。 在公司外,AI 全栈接项目,独立开发变现小工具,赚取丰厚副业收入。 适合人群 学习本课程,可以在下述目标中三选一: 成为 AI 全栈:懂业务、懂 AI 也懂编程。大量使用 AI,自己完成 AI 应用从策划、开发到落地的全过程。包括商业分析、需求分析、产品设计、开发、测试、市场推广和运营等 成为业务向 AI 全栈:懂业务也懂 AI,与程序员合作,一起完成 AI 应用从策划、开发到落地的全过程 成为编程向 AI 全栈:懂编程也懂 AI,与业务人员合作,一起完成 AI 应用从策划、开发到落地的全过程 懂至少一门编程语言,并有过真实项目开发经验的软件开发⼯程师、⾼级⼯程师、技术总监、研发经理、架构师、测试⼯程师、数据工程师、运维工程师等,建议以「AI 全栈」为目标。即便对商业、产品、市场等的学习达不到最佳,但已掌握的经验和认知也有助于成为有竞争力的「编程向AI 全栈」。 不懂编程的产品经理、需求分析师、创业者、老板、解决方案工程师、项目经理、运营、市场、销售、设计师等,建议优先选择「业务向 AI 全栈」为目标。在课程提供的技术环境里熏陶,提高技术领域的判断力,未来可以和技术人员更流畅地沟通协作。学习过程中,如果能善用 AI 学习编程、辅助编程,就可以向「AI 全栈」迈进。 师资力量 首席讲师 - 王卓然 image.png 哈尔滨工业大学本硕,英国 UCL 博士,国际知名学者、企业家,师从统计机器学习理论奠基人之一 John Shawe-Taylor 教授,是最早从事人机对话研究的华裔学者之一,至今已超 20 年。 他就是 AI 全栈,仍在研发一线,单人销售、售前、开发、实施全流程交付多个数百万金额 AI 项目,全栈实战经验 -
更多 Data Connectors
4 文本切分与解析(Chunking)
4.1 介绍
- 在信息检索和自然语言处理领域,为了更高效地处理和检索文档内容,通常会将大型文档(Document)分解为更小的、可管理的片段。LlamaIndex 中的 Node 就是这个过程中的核心概念;
- 文档切分(Document Chunking)的背景
- **为什么需要切分?**原始文档可能很长(比如一本书、一篇论文或一份报告),直接处理或检索效率低下。切分为小块后可以:
- 提高检索精度(返回最相关的片段而非整个文档);
- 降低计算开销(例如嵌入模型对短文本处理更高效);
- 支持细粒度分析(如段落级别的语义理解);
- 常见切分方式:按段落、句子、固定长度(如每 512 个字符)或语义边界(如标题)划分;
- **为什么需要切分?**原始文档可能很长(比如一本书、一篇论文或一份报告),直接处理或检索效率低下。切分为小块后可以:
- LlamaIndex 中的 Node
- 定义:Node 是文档的一个逻辑「块」(chunk),包含:
- 文本内容:切分后的实际文本(如一个段落);
- 元数据(可选):来源、位置、作者、时间等;
- 关系(可选):与其他 Node 的链接(如上下文顺序);
- 类比将文档视为一本书,Node 就是其中的章节或页面,既独立又可组合;
- 定义:Node 是文档的一个逻辑「块」(chunk),包含:
- Node 的核心作用
- 检索优化:检索时直接匹配相关 Node,而非全文扫描,提升速度和准确性;
- 灵活的结构化:支持层级化组织(例如父 Node 表示章节,子 Node 表示段落);
- 扩展性:可为 Node 添加自定义属性(如重要性评分、嵌入向量);
- 高级特性
- Embedding 优化:每个 Node 可单独生成嵌入向量,适合语义搜索;
- 跨 Node 关系:通过
relationships定义 Node 间的逻辑连接(如上一篇/下一篇); - 混合粒度:不同 Node 可代表不同粒度(如摘要 Node + 细节 Node)。
4.2 使用 TextSplitters 对文本做切分
-
例:从飞书文档中提取内容,并将其分割成适合后续处理(如嵌入或索引)的小块文本
from llama_index.readers.feishu_docs import FeishuDocsReader from llama_index.core.node_parser import TokenTextSplitter import json from pydantic.v1 import BaseModel # 用于展示json数据 def show_json(data): if isinstance(data, str): obj = json.loads(data) print(json.dumps(obj, indent=4, ensure_ascii=False)) elif isinstance(data, dict) or isinstance(data, list): print(json.dumps(data, indent=4, ensure_ascii=False)) elif issubclass(type(data), BaseModel): print(json.dumps(data.dict(), indent=4, ensure_ascii=False)) app_id = "cli_a88a866f09b8500b" app_secret = "VO2mW3Lr3pz4IGuurqwRVeLZ7emGmtgr" doc_ids = ["FULadzkWmovlfkxSgLPcE4oWnPf"] # 定义飞书文档加载器 loader = FeishuDocsReader(app_id, app_secret) # 加载文档 documents = loader.load_data(document_ids=doc_ids) # 显示前1000字符 print(documents[0].text[:1000]) node_parser = TokenTextSplitter( chunk_size=100, # 每个 chunk 的最大长度 chunk_overlap=50 # chunk 之间重叠长度 ) nodes = node_parser.get_nodes_from_documents( documents, show_progress=False ) show_json(nodes[0].json()) show_json(nodes[1].json()) -
结果:
AI 大模型全栈工程师培养计划 - AGIClass.ai 由 AGI 课堂推出的社群型会员制课程,传授大模型的原理、应用开发技术和行业认知,助你成为 ChatGPT 浪潮中的超级个体 什么是 AI 大模型全栈工程师? 「AI 大模型全栈工程师」简称「AI 全栈」,是一个人就能借助 AI,设计、开发和运营基于 AI 的大模型应用的超级个体。 AI 全栈需要懂业务、懂 AI、懂编程,一个人就是一个团队,单枪匹马创造财富。 在技术型公司,AI 全栈最懂 AI,瞬间站上技术顶峰。 在非技术型公司,AI 全栈连接其他员工和 AI,提升整个公司的效率。 在公司外,AI 全栈接项目,独立开发变现小工具,赚取丰厚副业收入。 适合人群 学习本课程,可以在下述目标中三选一: 成为 AI 全栈:懂业务、懂 AI 也懂编程。大量使用 AI,自己完成 AI 应用从策划、开发到落地的全过程。包括商业分析、需求分析、产品设计、开发、测试、市场推广和运营等 成为业务向 AI 全栈:懂业务也懂 AI,与程序员合作,一起完成 AI 应用从策划、开发到落地的全过程 成为编程向 AI 全栈:懂编程也懂 AI,与业务人员合作,一起完成 AI 应用从策划、开发到落地的全过程 懂至少一门编程语言,并有过真实项目开发经验的软件开发⼯程师、⾼级⼯程师、技术总监、研发经理、架构师、测试⼯程师、数据工程师、运维工程师等,建议以「AI 全栈」为目标。即便对商业、产品、市场等的学习达不到最佳,但已掌握的经验和认知也有助于成为有竞争力的「编程向AI 全栈」。 不懂编程的产品经理、需求分析师、创业者、老板、解决方案工程师、项目经理、运营、市场、销售、设计师等,建议优先选择「业务向 AI 全栈」为目标。在课程提供的技术环境里熏陶,提高技术领域的判断力,未来可以和技术人员更流畅地沟通协作。学习过程中,如果能善用 AI 学习编程、辅助编程,就可以向「AI 全栈」迈进。 师资力量 首席讲师 - 王卓然 image.png 哈尔滨工业大学本硕,英国 UCL 博士,国际知名学者、企业家,师从统计机器学习理论奠基人之一 John Shawe-Taylor 教授,是最早从事人机对话研究的华裔学者之一,至今已超 20 年。 他就是 AI 全栈,仍在研发一线,单人销售、售前、开发、实施全流程交付多个数百万金额 AI 项目,全栈实战经验 { "id_": "ad1ef0e4-bea8-4592-9dab-1da9475ed597", "embedding": null, "metadata": { "document_id": "FULadzkWmovlfkxSgLPcE4oWnPf" }, "excluded_embed_metadata_keys": [], "excluded_llm_metadata_keys": [], "relationships": { "1": { "node_id": "4819aa9f-9e66-4b9b-b648-c81c185fc4e3", "node_type": "4", "metadata": { "document_id": "FULadzkWmovlfkxSgLPcE4oWnPf" }, "hash": "960af2b3efcfca43cad2171e71596019857c5214dc1e77c41cf264b3226cc719", "class_name": "RelatedNodeInfo" }, "3": { "node_id": "f3b29acf-877b-4fd3-aaa2-ae544c5362eb", "node_type": "1", "metadata": {}, "hash": "654c6cbdd5a23946a84e84e6f3a474de2a442191b2be2d817ba7f04286b1a980", "class_name": "RelatedNodeInfo" } }, "metadata_template": "{key}: {value}", "metadata_separator": "\n", "text": "AI 大模型全栈工程师培养计划 - AGIClass.ai\n\n由 AGI 课堂推出的社群型会员制课程,传授大模型的原理、应用开发技术和行业认知,助你成为", "mimetype": "text/plain", "start_char_idx": 0, "end_char_idx": 76, "metadata_seperator": "\n", "text_template": "{metadata_str}\n\n{content}", "class_name": "TextNode" } { "id_": "f3b29acf-877b-4fd3-aaa2-ae544c5362eb", "embedding": null, "metadata": { "document_id": "FULadzkWmovlfkxSgLPcE4oWnPf" }, "excluded_embed_metadata_keys": [], "excluded_llm_metadata_keys": [], "relationships": { "1": { "node_id": "4819aa9f-9e66-4b9b-b648-c81c185fc4e3", "node_type": "4", "metadata": { "document_id": "FULadzkWmovlfkxSgLPcE4oWnPf" }, "hash": "960af2b3efcfca43cad2171e71596019857c5214dc1e77c41cf264b3226cc719", "class_name": "RelatedNodeInfo" }, "2": { "node_id": "ad1ef0e4-bea8-4592-9dab-1da9475ed597", "node_type": "1", "metadata": { "document_id": "FULadzkWmovlfkxSgLPcE4oWnPf" }, "hash": "b08e60a1cf7fa55aa8c010d792766208dcbb34e58aeead16dca005eab4e1df8f", "class_name": "RelatedNodeInfo" }, "3": { "node_id": "186825b8-8a84-4851-a80b-e72193fc1ebf", "node_type": "1", "metadata": {}, "hash": "06d6c13287ff7e2f033a1aae487198dbfdec3d954aab0fd9b4866ce833200afb", "class_name": "RelatedNodeInfo" } }, "metadata_template": "{key}: {value}", "metadata_separator": "\n", "text": "AGI 课堂推出的社群型会员制课程,传授大模型的原理、应用开发技术和行业认知,助你成为 ChatGPT 浪潮中的超级个体\n什么是 AI", "mimetype": "text/plain", "start_char_idx": 33, "end_char_idx": 100, "metadata_seperator": "\n", "text_template": "{metadata_str}\n\n{content}", "class_name": "TextNode" } -
LlamaIndex 提供了丰富的
TextSplitter,例如:SentenceSplitter:在切分指定长度的 chunk 同时尽量保证句子边界不被切断;CodeSplitter:根据 AST(编译器的抽象句法树)切分代码,保证代码功能片段完整;SemanticSplitterNodeParser:根据语义相关性对将文本切分为片段。
4.3 使用 NodeParsers 对有结构的文档做解析
-
例:使用
MarkdownNodeParser解析 markdown 文档from llama_index.readers.file import FlatReader from llama_index.core.node_parser import MarkdownNodeParser from pathlib import Path import json from pydantic.v1 import BaseModel # 用于展示json数据 def show_json(data): if isinstance(data, str): obj = json.loads(data) print(json.dumps(obj, indent=4, ensure_ascii=False)) elif isinstance(data, dict) or isinstance(data, list): print(json.dumps(data, indent=4, ensure_ascii=False)) elif issubclass(type(data), BaseModel): print(json.dumps(data.dict(), indent=4, ensure_ascii=False)) md_docs = FlatReader().load_data(Path("./data/ChatALL.md")) parser = MarkdownNodeParser() nodes = parser.get_nodes_from_documents(md_docs) show_json(nodes[2].json()) show_json(nodes[3].json()) -
结果:
{ "id_": "273d1a70-9de2-4083-b96f-f86e1a0aacfc", "embedding": null, "metadata": { "filename": "ChatALL.md", "extension": ".md", "header_path": "/" }, "excluded_embed_metadata_keys": [], "excluded_llm_metadata_keys": [], "relationships": { "1": { "node_id": "3790972b-d7be-4964-baaa-e619fe22ae72", "node_type": "4", "metadata": { "filename": "ChatALL.md", "extension": ".md" }, "hash": "2887c73e242e0a9093b111d28e45a5a2cf32728756c5d2a558ad2ec9a2e2433b", "class_name": "RelatedNodeInfo" }, "2": { "node_id": "bea9c12c-4376-4e85-8b1b-e46f4a1159c5", "node_type": "1", "metadata": { "filename": "ChatALL.md", "extension": ".md", "header_path": "/" }, "hash": "17a04477623bb7388889708bb15e562db0be59416a7e6350160912de08f47aeb", "class_name": "RelatedNodeInfo" }, "3": { "node_id": "6719ed41-6752-4b50-b3a4-bf085f02bae6", "node_type": "1", "metadata": { "header_path": "/功能/" }, "hash": "193cd3af1ed12c2d2b509eca4905a956857bb7336a1d5926b2049a51fbf605ec", "class_name": "RelatedNodeInfo" } }, "metadata_template": "{key}: {value}", "metadata_separator": "\n", "text": "## 功能\n\n基于大型语言模型(LLMs)的 AI 机器人非常神奇。然而,它们的行为可能是随机的,不同的机器人在不同的任务上表现也有差异。如果你想获得最佳体验,不要一个一个尝试。ChatALL(中文名:齐叨)可以把一条指令同时发给多个 AI,帮助您发现最好的回答。你需要做的只是[下载、安装](https://github.com/sunner/ChatALL/releases)和提问。", "mimetype": "text/plain", "start_char_idx": 456, "end_char_idx": 650, "metadata_seperator": "\n", "text_template": "{metadata_str}\n\n{content}", "class_name": "TextNode" } { "id_": "6719ed41-6752-4b50-b3a4-bf085f02bae6", "embedding": null, "metadata": { "filename": "ChatALL.md", "extension": ".md", "header_path": "/功能/" }, "excluded_embed_metadata_keys": [], "excluded_llm_metadata_keys": [], "relationships": { "1": { "node_id": "3790972b-d7be-4964-baaa-e619fe22ae72", "node_type": "4", "metadata": { "filename": "ChatALL.md", "extension": ".md" }, "hash": "2887c73e242e0a9093b111d28e45a5a2cf32728756c5d2a558ad2ec9a2e2433b", "class_name": "RelatedNodeInfo" }, "2": { "node_id": "273d1a70-9de2-4083-b96f-f86e1a0aacfc", "node_type": "1", "metadata": { "filename": "ChatALL.md", "extension": ".md", "header_path": "/" }, "hash": "b0fa83d695fb998bf234cde7461d03fa1ea0050dd0e6fcf793e6c5b0679cdc3b", "class_name": "RelatedNodeInfo" }, "3": { "node_id": "5196647c-a004-46b2-9418-7bc37824ac71", "node_type": "1", "metadata": { "header_path": "/功能/" }, "hash": "daf003d1977927bcd39ce78711b52c24c6e6baf9c39c79ec9ee60cf010fe083e", "class_name": "RelatedNodeInfo" } }, "metadata_template": "{key}: {value}", "metadata_separator": "\n", "text": "### 这是你吗?\n\nChatALL 的典型用户是:\n\n- 🤠**大模型重度玩家**,希望从大模型找到最好的答案,或者最好的创作\n- 🤓**大模型研究者**,直观比较各种大模型在不同领域的优劣\n- 😎**大模型应用开发者**,快速调试 prompt,寻找表现最佳的基础模型", "mimetype": "text/plain", "start_char_idx": 652, "end_char_idx": 788, "metadata_seperator": "\n", "text_template": "{metadata_str}\n\n{content}", "class_name": "TextNode" }
5 索引(Indexing)与检索(Retrieval)
5.1 索引介绍
-
索引的目的是将原始数据(如文档、网页、数据库记录)转化为可快速查询的结构化形式;
-
LlamaIndex 的索引过程分为以下步骤:
- 文档加载与切分:
- 输入:原始文档(PDF、HTML、数据库等);
- 处理:
- 使用
Document类加载文本; - 通过
Node将文档切分为语义块(如段落、章节);
- 使用
- 嵌入(Embedding)与向量化:
- 每个
Node的文本通过嵌入模型(如 OpenAI、BERT)转换为向量(Vector); - 向量捕获语义信息,用于后续相似性搜索;
- 关键点:
- 嵌入模型的选择直接影响检索质量;
- 可自定义本地模型(如
sentence-transformers);
- 每个
- 索引构建:
- 向量索引(Vector Index):
- 将 Node 向量存入向量数据库(如 FAISS、Pinecone);
- 支持近似最近邻搜索(ANN),加速查询;
- 结构化索引:
- 基于关键词的倒排索引(传统全文检索);
- 图索引(Graph Index):建立 Node 间的逻辑关系(如引用、层级);
- 向量索引(Vector Index):
- 元数据关联:为每个 Node 附加元数据(如来源、日期、作者),支持过滤检索。
- 文档加载与切分:
-
传统索引:搜索引擎索引 - 维基百科,自由的百科全书;
-
向量索引:Vector Indexing: A Roadmap for Vector Databases | by Neil Kanungo | KX Systems | Medium。
5.2 检索介绍
-
检索阶段根据用户查询(Query)从索引中提取最相关的信息;
-
LlamaIndex 提供多种检索策略:
-
语义检索(向量检索):
- 流程:
- 将用户查询文本嵌入为向量;
- 计算查询向量与所有 Node 向量的相似度(如余弦相似度);
- 返回 Top-K 最相似的 Node;
- 特点:
- 适合自然语言查询(如“总结量子力学的基础”);
- 依赖嵌入模型的质量;
- 流程:
-
关键词检索
-
使用传统倒排索引匹配关键词(如 BM25 算法);
-
适合精确术语查询(如“Python 的 GIL 是什么”);
-
-
混合检索(Hybrid Retrieval):结合语义检索和关键词检索,平衡召回率与精确度;
-
检索后处理(Reranking)
- 对初步检索结果重新排序:
- 使用交叉编码器(Cross-Encoder)计算查询与结果的精细相关性;
- 过滤低分结果或重复内容;
- 上下文增强:将检索到的 Node 组合为上下文,供大模型(如 GPT-4)生成答案;
-
-
核心优势:
- 灵活性:支持多种索引类型(向量、关键词、图结构),适配不同场景;
- 扩展性:可集成外部工具(如 Weaviate 向量库、Elasticsearch);
- 端到端流程:从原始数据到检索结果的全链路封装;
-
适用场景:
- RAG(检索增强生成):结合检索结果与大模型生成答案;
- 知识库问答:企业文档、技术手册的精准问答;
- 推荐系统:基于内容相似性的推荐。
5.3 向量检索
-
例:
SimpleVectorStore直接在内存中构建一个 Vector Store 并建索引;- 注意:LlamaIndex 默认的 Embedding 模型是
OpenAIEmbedding(model="text-embedding-ada-002"),要有 OpenAI 的api_key;
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader from llama_index.core.node_parser import TokenTextSplitter from llama_index.readers.file import PyMuPDFReader # 加载 pdf 文档 documents = SimpleDirectoryReader( "./data", required_exts=[".pdf"], file_extractor={".pdf": PyMuPDFReader()} ).load_data() # 定义 Node Parser node_parser = TokenTextSplitter(chunk_size=300, chunk_overlap=100) # 切分文档 nodes = node_parser.get_nodes_from_documents(documents) # 构建 index index = VectorStoreIndex(nodes) # 获取 retriever vector_retriever = index.as_retriever( similarity_top_k=2 # 返回2个结果 ) # 检索 results = vector_retriever.retrieve("Llama2有多少参数") print(results[0].text) print() print(results[1].text) - 注意:LlamaIndex 默认的 Embedding 模型是
5.4 Qdrant介绍
-
Qdrant 是一个开源的 向量数据库(Vector Database),专为高效存储和检索 向量嵌入(Embeddings) 而设计。它支持 近似最近邻搜索(ANN, Approximate Nearest Neighbor),适用于大模型(LLM)的语义搜索、推荐系统、图像检索等 AI 场景;
-
文档:Home - Qdrant;
-
核心特点:
特性 说明 高性能 使用 Rust 编写,优化了向量检索速度,支持 GPU 加速 可扩展 支持分布式部署,适合大规模数据 多种距离度量 支持余弦相似度(Cosine)、欧氏距离(Euclidean)、点积(Dot Product)等 过滤查询 支持结构化数据(如 metadata)过滤 + 向量检索结合 REST/gRPC API 提供 Python、Go、JavaScript 等 SDK 内存/持久化存储 支持 :memory:模式(仅内存)或持久化到磁盘 -
核心概念:
-
Collection(集合)
-
类似 SQL 的“表”,存储一组向量数据;
-
创建时需要指定 向量维度(size) 和 距离度量(Distance)(如
COSINE、EUCLIDEAN); -
示例:
client.create_collection( collection_name="demo", vectors_config=VectorParams(size=1024, distance=Distance.COSINE) )
-
-
Points(点)
-
每个点包含:
- ID(唯一标识)
- Vector(嵌入向量)
- Payload(可选元数据,如
{"text": "Llama2 有 70B 参数"})
-
示例:
{ "id": 1, "vector": [0.1, 0.2, ..., 0.9], "payload": {"text": "Llama2 有 70B 参数"} }
-
-
Search(检索)
-
输入一个查询向量,返回最相似的 Top-K 结果;
-
示例:
results = client.search( collection_name="demo", query_vector=[0.3, 0.1, ..., 0.5], limit=3 # 返回前 3 个最相似结果 )
-
-
-
在 LlamaIndex 中,Qdrant 作为 向量存储后端,用于:
- 存储文档的嵌入向量(如 OpenAI/BGE/Aliyun 生成的 Embeddings);
- 快速检索相似内容(如用户提问时,找到最相关的文本块);
- 支持混合检索(结合向量搜索 + 元数据过滤);
-
Qdrant 的部署方式:
方式 适用场景 示例 内存模式( :memory:)快速测试,数据不持久化 QdrantClient(":memory:")本地持久化 单机开发 QdrantClient(path="./qdrant_data")Docker 部署 生产环境 docker run -p 6333:6333 qdrant/qdrant云服务 Qdrant Cloud 免运维托管 QdrantClient(url="https://xxx.cloud", api_key="...") -
Qdrant VS 其它向量数据库:
数据库 语言 特点 适用场景 Qdrant Rust 高性能,支持过滤查询 推荐系统、语义搜索 Milvus Go 分布式架构,适合超大规模 企业级向量检索 Pinecone - 全托管,简单易用 快速上云的 AI 应用 Weaviate Go 支持图结构 + 向量搜索 复杂知识图谱 -
总结:
- Qdrant 是一个 专为 AI 设计的向量数据库,适合存储和检索 Embeddings;
- 在 LlamaIndex 中,它作为 向量存储引擎,加速语义搜索;
- 支持 内存模式(测试) 和 持久化部署(生产);
- 如果你的应用需要高效、可扩展的向量检索,Qdrant 是一个优秀的选择。
5.5 使用自定义向量数据库和向量模型实现向量检索
-
使用自定义的 Vector Store(以
Qdrant为例)和 阿里云的text-embedding-v3向量模型:-
注意:
- 根据阿里云百炼官方的向量模型调用方式,不能直接使用LlamaIndex的
OpenAIEmbedding类,需要创建了一个自定义的DashScopeEmbedding类,且继承自BaseEmbedding而不是OpenAIEmbedding,完全绕过了 OpenAI 的模型验证机制; - 确保 Qdrant 集合的向量维度设置为 1024,与阿里云百炼的嵌入维度匹配;
- 要实现
BaseEmbedding类中所有必需的同步和异步方法;
- 根据阿里云百炼官方的向量模型调用方式,不能直接使用LlamaIndex的
-
-
安装包:
pip install llama-index-vector-stores-qdrantimport os from typing import List # typing.List:类型注解,标注函数返回的列表类型 from llama_index.core import SimpleDirectoryReader, Settings from llama_index.core.node_parser import TokenTextSplitter from llama_index.readers.file import PyMuPDFReader from llama_index.core.indices.vector_store.base import VectorStoreIndex from llama_index.vector_stores.qdrant import QdrantVectorStore from llama_index.core import StorageContext from openai import OpenAI, AsyncOpenAI from llama_index.core.embeddings import BaseEmbedding from pydantic import Field # 用于定义数据模型的字段(Pydantic验证) # 继承 BaseEmbedding,定义一个兼容阿里云百炼的自定义嵌入模型类 class DashScopeEmbedding(BaseEmbedding): model: str = Field(default="text-embedding-v3", description="The model to use for embeddings") dimensions: int = Field(default=1024, description="The dimensions of the embedding vectors") # 初始化嵌入模型客户端 def __init__( self, model: str = "text-embedding-v3", # 模型名称 dimensions: int = 1024, # 指定嵌入向量的维度(1024) **kwargs ): super().__init__(**kwargs) self.model = model self.dimensions = dimensions # 创建同步 (OpenAI) 和异步 (AsyncOpenAI) 客户端 self._client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) self._async_client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) # 实现同步调用的嵌入生成方法 # 生成查询文本的嵌入向量 def _get_query_embedding(self, query: str) -> List[float]: return self._get_embeddings([query])[0] # 生成单个文本的嵌入向量 def _get_text_embedding(self, text: str) -> List[float]: return self._get_embeddings([text])[0] # 批量生成文本的嵌入向量 def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]: return self._get_embeddings(texts) # 实际调用阿里云API生成嵌入 def _get_embeddings(self, texts: List[str]) -> List[List[float]]: response = self._client.embeddings.create( model=self.model, input=texts, dimensions=self.dimensions, encoding_format="float" ) return [embedding.embedding for embedding in response.data] # 实现异步调用的嵌入生成方法(结构与同步方法类似,用于高性能场景) async def _aget_query_embedding(self, query: str) -> List[float]: return (await self._aget_embeddings([query]))[0] async def _aget_text_embedding(self, text: str) -> List[float]: return (await self._aget_embeddings([text]))[0] async def _aget_text_embeddings(self, texts: List[str]) -> List[List[float]]: return await self._aget_embeddings(texts) async def _aget_embeddings(self, texts: List[str]) -> List[List[float]]: response = await self._async_client.embeddings.create( model=self.model, input=texts, dimensions=self.dimensions, encoding_format="float" ) return [embedding.embedding for embedding in response.data] # 将自定义的 DashScopeEmbedding 设置为LlamaIndex的全局嵌入模型 Settings.embed_model = DashScopeEmbedding( model="text-embedding-v3", dimensions=1024 ) # 加载 pdf 文档 documents = SimpleDirectoryReader( "./data", required_exts=[".pdf"], file_extractor={".pdf": PyMuPDFReader()} ).load_data() # 使用 TokenTextSplitter 将文档分块(每块300词,重叠100词) node_parser = TokenTextSplitter(chunk_size=300, chunk_overlap=100) # 切分文档 nodes = node_parser.get_nodes_from_documents(documents) from qdrant_client import QdrantClient from qdrant_client.models import VectorParams, Distance # 在内存中创建Qdrant客户端 client = QdrantClient(location=":memory:") # 创建集合 demo,配置向量维度为1024,相似度度量方式为余弦距离 collection_name = "demo" collection = client.create_collection( collection_name=collection_name, vectors_config=VectorParams(size=1024, distance=Distance.COSINE) ) # 将分块后的文档节点 (nodes) 存入Qdrant,构建向量索引 vector_store = QdrantVectorStore(client=client, collection_name=collection_name) storage_context = StorageContext.from_defaults(vector_store=vector_store) index = VectorStoreIndex(nodes, storage_context=storage_context) # 创建检索器 (retriever),设置返回最相似的2个结果 vector_retriever = index.as_retriever(similarity_top_k=2) # 查询 "Llama2有多少参数",打印前2个匹配结果 results = vector_retriever.retrieve("Llama2有多少参数") print(results[0]) print(results[1]) -
结果:
Node ID: 861273e1-513d-4d00-bec0-5d91d5a3a253 Text: 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. We have also trained 34B varian... Score: 0.731 Node ID: 5e4ca0be-53c0-4fbb-9d54-9704e65d4bfd Text: Singh Koura Marie-Anne Lachaux Thibaut Lavril Jenya Lee Diana Liskovich Yinghai Lu Yuning Mao Xavier Martinet Todor Mihaylov Pushkar Mishra Igor Molybog Yixin Nie Andrew Poulton Jeremy Reizenstein Rashi Rungta Kalyan Saladi Alan Schelten Ruan Silva Eric Michael Smith Ranjan Subramanian Xiaoqing Ellen Tan Binh Tang Ross Taylor Adina Williams Jian... Score: 0.726- 第一个结果(Score: 0.731)确实包含Llama 2的参数信息(7B/13B/70B等),证明检索逻辑有效
- 两个结果的相似度分数合理(0.73 > 0.72),排序正确;
- 但第二个结果(Score: 0.726)是无效内容(人名列表),说明分块策略需要优化。
5.6 更多索引与检索方式
-
LlamaIndex 提供了多种检索机制,适用于不同的场景和需求;
-
关键字检索(Keyword-Based Retrieval):关键字检索是最基础的检索方式,通过提取查询或文档中的关键词进行匹配;
-
LlamaIndex 提供了多种关键字提取方法:
- 关键字检索(Keyword-Based Retrieval):关键字检索是最基础的检索方式,通过提取查询或文档中的关键词进行匹配。LlamaIndex 提供了多种关键字提取方法:
- BM25Retriever:
- 原理:基于经典的 BM25 算法(Best Matching 25),是一种基于概率的检索模型,改进自 TF-IDF;
- 考虑词频(TF)、逆文档频率(IDF)和文档长度归一化;
- 对短文本和长文本均有较好效果;
- 特点:
- 依赖分词器(tokenizer)处理文本;
- 适合通用场景,无需训练数据;
- 原理:基于经典的 BM25 算法(Best Matching 25),是一种基于概率的检索模型,改进自 TF-IDF;
- KeywordTableGPTRetriever:
- 原理:利用 GPT 模型(如 OpenAI 的 GPT-3.5/4)从查询或文档中提取关键词;
- 特点:
- 关键词提取更语义化,能理解上下文;
- 依赖大模型,可能成本较高;
- KeywordTableSimpleRetriever:
- 原理:基于正则表达式(Regex)提取关键词;
- 特点:
- 轻量级,规则简单;
- 灵活性较差,需手动设计规则;
- KeywordTableRAKERetriever:
- 原理:使用 RAKE(Rapid Automatic Keyword Extraction)算法提取关键词;
- RAKE 通过分析词频、共现和停用词过滤提取关键词;
- 特点:
- 对英文支持较好,其他语言需额外配置;
- 无需训练,适合无监督场景;
- 原理:使用 RAKE(Rapid Automatic Keyword Extraction)算法提取关键词;
- BM25Retriever:
- RAG-Fusion QueryFusionRetriever
- 背景:RAG(Retrieval-Augmented Generation)结合检索与生成,但单一查询可能不够精准;
- 原理:
- 查询扩展:通过生成多个相关查询(如改写、同义扩展)提升检索覆盖率;
- 结果融合:合并多个查询的检索结果,按相关性排序;
- 特点:
- 提高召回率,减少单一查询的偏差;
- 需调用生成模型,可能增加耗时;
- 知识图谱检索(KnowledgeGraph)
- 原理:基于结构化知识图谱(实体-关系-实体三元组)进行检索;
- 支持语义查询,如“爱因斯坦的母校是哪所?”;
- 特点:
- 适合复杂逻辑推理;
- 需预先构建知识图谱(可通过 LlamaIndex 或其他工具生成);
- 原理:基于结构化知识图谱(实体-关系-实体三元组)进行检索;
- SQL 检索
- 原理:将自然语言查询转换为 SQL 语句,从结构化数据库(如 MySQL、PostgreSQL)中检索;
- 例如:“2023年销售额最高的产品” →
SELECT product FROM sales ORDER BY revenue DESC LIMIT 1;
- 例如:“2023年销售额最高的产品” →
- 特点:
- 依赖 Text-to-SQL 模型(如 OpenAI 的
davinci); - 适合业务数据分析场景;
- 依赖 Text-to-SQL 模型(如 OpenAI 的
- 原理:将自然语言查询转换为 SQL 语句,从结构化数据库(如 MySQL、PostgreSQL)中检索;
- Text-to-SQL
- 原理:直接将自然语言转换为 SQL 查询;
- 与 SQL 检索的区别:Text-to-SQL 是技术实现手段,SQL 检索是应用场景;
- 工具:LlamaIndex 内置支持,也可结合 LangChain 的 SQLDatabaseChain;
- 特点:
- 需数据库 Schema 信息;
- 对复杂查询可能需人工校准;
- 原理:直接将自然语言转换为 SQL 查询;
- 关键字检索(Keyword-Based Retrieval):关键字检索是最基础的检索方式,通过提取查询或文档中的关键词进行匹配。LlamaIndex 提供了多种关键字提取方法:
-
对比与选型建议:
检索类型 适用场景 优点 缺点 BM25Retriever 通用文本检索 无需训练,高效 语义理解较弱 GPTRetriever 语义化关键词提取 上下文感知 成本高,延迟大 RAG-Fusion 复杂查询增强 高召回率 计算资源消耗大 KnowledgeGraph 关联数据推理 支持复杂逻辑 需构建知识图谱 Text-to-SQL 结构化数据查询 精准的数据库操作 依赖数据库 Schema
5.7 Ingestion Pipeline 自定义数据处理流程
-
LlamaIndex 通过
Transformations定义一个数据(Documents)的多步处理的流程(Pipeline)。 这个 Pipeline 的一个显著特点是,它的每个子步骤是可以缓存(cache)的,即如果该子步骤的输入与处理方法不变,重复调用时会直接从缓存中获取结果,而无需重新执行该子步骤,这样即节省时间也会节省 token (如果子步骤涉及大模型调用); -
定义一个测量代码块的执行时间的函数:
import time class Timer: def __enter__(self): self.start = time.time() return self def __exit__(self, exc_type, exc_val, exc_tb): self.end = time.time() self.interval = self.end - self.start print(f"耗时 {self.interval*1000} ms") -
例:
import time from llama_index.core.base.llms.types import LLMMetadata, CompletionResponseGen, ChatResponseGen, ChatResponseAsyncGen, \ CompletionResponseAsyncGen, CompletionResponse, ChatResponse from qdrant_client import QdrantClient from qdrant_client.models import VectorParams, Distance from llama_index.core.node_parser import SentenceSplitter from llama_index.core.extractors import TitleExtractor from llama_index.core.ingestion import IngestionPipeline from llama_index.core import SimpleDirectoryReader, Settings from llama_index.readers.file import PyMuPDFReader from llama_index.core.indices.vector_store.base import VectorStoreIndex from llama_index.vector_stores.qdrant import QdrantVectorStore from llama_index.core.embeddings import BaseEmbedding from pydantic import Field # 用于定义数据模型的字段(Pydantic验证) from llama_index.core.llms import LLM, CompletionResponse, ChatResponse, ChatMessage from typing import Dict, List, Iterator, AsyncIterator from openai import OpenAI, AsyncOpenAI import os from llama_index.core import Settings # 定义一个测量代码块的执行时间的函数 class Timer: def __enter__(self): self.start = time.time() return self def __exit__(self, exc_type, exc_val, exc_tb): self.end = time.time() self.interval = self.end - self.start print(f"耗时 {self.interval * 1000} ms") # 继承 BaseEmbedding,定义一个兼容阿里云百炼的自定义嵌入模型类 class DashScopeEmbedding(BaseEmbedding): model: str = Field(default="text-embedding-v3", description="The model to use for embeddings") dimensions: int = Field(default=1024, description="The dimensions of the embedding vectors") # 初始化嵌入模型客户端 def __init__( self, model: str = "text-embedding-v3", # 模型名称 dimensions: int = 1024, # 指定嵌入向量的维度(1024) **kwargs ): super().__init__(**kwargs) self.model = model self.dimensions = dimensions # 创建同步 (OpenAI) 和异步 (AsyncOpenAI) 客户端 self._client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) self._async_client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) # 实现同步调用的嵌入生成方法 # 生成查询文本的嵌入向量 def _get_query_embedding(self, query: str) -> List[float]: return self._get_embeddings([query])[0] # 生成单个文本的嵌入向量 def _get_text_embedding(self, text: str) -> List[float]: return self._get_embeddings([text])[0] # 批量生成文本的嵌入向量 def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]: return self._get_embeddings(texts) # 实际调用阿里云API生成嵌入 def _get_embeddings(self, texts: List[str]) -> List[List[float]]: response = self._client.embeddings.create( model=self.model, input=texts, dimensions=self.dimensions, encoding_format="float" ) return [embedding.embedding for embedding in response.data] # 实现异步调用的嵌入生成方法(结构与同步方法类似,用于高性能场景) async def _aget_query_embedding(self, query: str) -> List[float]: return (await self._aget_embeddings([query]))[0] async def _aget_text_embedding(self, text: str) -> List[float]: return (await self._aget_embeddings([text]))[0] async def _aget_text_embeddings(self, texts: List[str]) -> List[List[float]]: return await self._aget_embeddings(texts) async def _aget_embeddings(self, texts: List[str]) -> List[List[float]]: response = await self._async_client.embeddings.create( model=self.model, input=texts, dimensions=self.dimensions, encoding_format="float" ) return [embedding.embedding for embedding in response.data] # 创建自定义LLM类,使用"qwen-max"模型 class DashScopeLLM(LLM): model_name: str = "qwen-max" @property def metadata(self) -> LLMMetadata: return LLMMetadata( context_window=8192, # 上下文窗口大小(token数) num_output=1024, # 最大输出token数 is_chat_model=True, # 是聊天模型 is_function_calling_model=False, # 不支持函数调用 model_name=self.model_name, # 模型名称 ) # 将 ChatMessage 对象列表转换为 API 需要的字典格式 def _format_messages(self, messages: List[ChatMessage]) -> List[Dict]: formatted_messages = [] for msg in messages: # 确保消息内容是字符串类型,避免类型错误 content = msg.content if isinstance(msg.content, str) else str(msg.content) formatted_messages.append({ "role": msg.role, # 角色(user/assistant/system) "content": content # 消息内容 }) return formatted_messages # 同步补全 def complete(self, prompt: str, **kwargs) -> CompletionResponse: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量获取API密钥 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 阿里云兼容端点 ) response = client.chat.completions.create( model=self.model_name, # 指定模型 messages=[{"role": "user", "content": prompt}], # 构造用户消息 **kwargs # 其他参数(如temperature等) ) return CompletionResponse(text=response.choices[0].message.content) # 返回响应 # 同步聊天。处理多轮对话场景,返回结构化的 ChatResponse 对象 def chat(self, messages: List[ChatMessage], **kwargs) -> ChatResponse: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) formatted_messages = self._format_messages(messages) # 格式化消息 response = client.chat.completions.create( model=self.model_name, messages=formatted_messages, # 使用格式化后的消息 **kwargs ) return ChatResponse( message=ChatMessage( role="assistant", # 设置角色为assistant content=response.choices[0].message.content # 获取响应内容 ) ) # 异步补全 async def acomplete(self, prompt: str, **kwargs) -> CompletionResponse: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( # 异步等待响应 model=self.model_name, messages=[{"role": "user", "content": prompt}], **kwargs ) return CompletionResponse(text=response.choices[0].message.content) # 异步聊天。异步版本的多轮对话处理,返回格式与同步版本一致 async def achat(self, messages: List[ChatMessage], **kwargs) -> ChatResponse: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) formatted_messages = self._format_messages(messages) response = await client.chat.completions.create( model=self.model_name, messages=formatted_messages, **kwargs ) return ChatResponse( message=ChatMessage( role="assistant", content=response.choices[0].message.content ) ) # 流式补全。实现流式文本生成,使用生成器逐步返回结果 def stream_complete(self, prompt: str, **kwargs) -> Iterator[CompletionResponse]: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = client.chat.completions.create( model=self.model_name, messages=[{"role": "user", "content": prompt}], stream=True, # 关键:启用流式响应 **kwargs ) def gen() -> Iterator[CompletionResponse]: for chunk in response: # 遍历流式响应的每个chunk yield CompletionResponse( text=chunk.choices[0].delta.content or "", # 获取增量内容 delta=chunk.choices[0].delta.content or "", # 同上 ) return gen() # 返回生成器 # 流式聊天。流式多轮对话,每次返回一个 ChatResponse 对象 def stream_chat(self, messages: List[ChatMessage], **kwargs) -> Iterator[ChatResponse]: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = client.chat.completions.create( model=self.model_name, messages=[m.dict() for m in messages], # 转换为字典 stream=True, **kwargs ) def gen() -> Iterator[ChatResponse]: for chunk in response: yield ChatResponse( message=ChatMessage( role="assistant", content=chunk.choices[0].delta.content or "" ) ) return gen() # 异步流式聊天 async def astream_chat(self, messages: List[ChatMessage], **kwargs) -> AsyncIterator[ChatResponse]: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( model=self.model_name, messages=[m.dict() for m in messages], stream=True, **kwargs ) # 异步遍历 async def gen() -> AsyncIterator[ChatResponse]: async for chunk in response: yield ChatResponse( message=ChatMessage( role="assistant", content=chunk.choices[0].delta.content or "" ) ) return gen() # 异步流式补全 async def astream_complete(self, prompt: str, **kwargs) -> AsyncIterator[CompletionResponse]: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( model=self.model_name, messages=[{"role": "user", "content": prompt}], stream=True, **kwargs ) async def gen() -> AsyncIterator[CompletionResponse]: async for chunk in response: yield CompletionResponse( text=chunk.choices[0].delta.content or "", delta=chunk.choices[0].delta.content or "", ) return gen() # 设置全局模型 Settings.embed_model = DashScopeEmbedding() Settings.llm = DashScopeLLM() # 在内存中创建Qdrant客户端 client = QdrantClient(location=":memory:") # 创建集合 ingestion_demo,配置向量维度为1024,相似度度量方式为余弦距离 collection_name = "ingestion_demo" collection = client.create_collection( collection_name=collection_name, vectors_config=VectorParams(size=1024, distance=Distance.COSINE) ) # 初始化一个 Qdrant 向量存储对象,用于后续存储文档向量 # client:之前创建的 Qdrant 客户端实例(内存或远程连接) # collection_name:指定要操作的集合名称(类似数据库表名) vector_store = QdrantVectorStore(client=client, collection_name=collection_name) # 定义一个文档处理流水线,按顺序执行:文本分块 → 2. 标题提取 → 3. 向量化 → 4. 存储到向量数据库 pipeline = IngestionPipeline( transformations=[ SentenceSplitter(chunk_size=300, chunk_overlap=100), # 将长文档分割成较小的文本块(chunks) TitleExtractor(llm=Settings.llm), # 为每个文本块生成一个简洁的标题(利用 LLM 理解内容) Settings.embed_model, # 调用嵌入模型(如 DashScopeEmbedding)将文本转换为向量 ], # 将生成的向量保存到之前初始化的 Qdrant 向量数据库中 vector_store=vector_store, ) # 加载 pdf 文档 documents = SimpleDirectoryReader( "./data", required_exts=[".pdf"], file_extractor={".pdf": PyMuPDFReader()} ).load_data() # 计时 with Timer(): pipeline.run(documents=documents) # 创建索引 index = VectorStoreIndex.from_vector_store(vector_store) # 创建检索器 (retriever),设置返回最相似的1个结果 vector_retriever = index.as_retriever(similarity_top_k=1) # 查询 "Llama2有多少参数" results = vector_retriever.retrieve("Llama2有多少参数") print(results[0])- 以下是上面代码的主要功能和执行流程:
- 自定义模型定义:
DashScopeEmbedding:封装阿里云的文本嵌入服务(text-embedding-v3),用于将文本转换为1024维向量;DashScopeLLM:封装阿里云的Qwen-max大模型(兼容OpenAI API格式),用于文本生成和问答;
- 系统初始化:
- 设置全局的嵌入模型和LLM模型;
- 在内存中创建Qdrant向量数据库(也可替换为远程服务器);
- 创建名为"ingestion_demo"的集合,配置为1024维向量,使用余弦相似度;
- 文档处理流水线:
IngestionPipeline定义了文档处理流程:- 使用
SentenceSplitter将文档分块(每块300词,重叠100词); - 用
TitleExtractor为每块生成标题; - 用
DashScopeEmbedding将文本转为向量; - 存储到Qdrant数据库;
- 使用
- 数据加载与处理:
- 从
./data目录读取PDF文件(使用PyMuPDF解析器); - 通过流水线处理这些文档;
- 从
- 查询系统:
- 创建基于向量存储的索引
- 构建查询引擎
- 示例查询:“Llama2 有多少参数?”
- 打印回答
- 自定义模型定义:
- 以下是上面代码的主要功能和执行流程:
-
结果:
100%|██████████| 3/3 [00:06<00:00, 2.04s/it] 100%|██████████| 5/5 [00:11<00:00, 2.29s/it] 100%|██████████| 5/5 [00:04<00:00, 1.07it/s] 100%|██████████| 4/4 [00:04<00:00, 1.09s/it] 耗时 44927.462577819824 ms Node ID: a49c296a-1738-4319-b6b5-c016a8a34914 Text: Figure 3: Safety human evaluation results for Llama 2-Chat compared to other open-source and closed- source models. Human raters judged model generations for safety violations across ~2,000 adversarial prompts consisting of both single and multi-turn prompts. More details can be found in Section 4.4. It is important to caveat these safety result... Score: 0.686-
耗时分析:
- 总耗时约45秒(44927ms),处理文档量不大时表现尚可;
- 各阶段速度:
- 分块:2.04s/任务;
- 标题提取:2.29s/任务(LLM调用瓶颈);
- 向量化:1.07任务/s(约0.93s/任务);
- 存储:1.09s/任务;
-
主要瓶颈:
TitleExtractor(llm=Settings.llm) # 同步LLM调用导致延迟
-
-
改进:在上面代码的末尾加上
# 本地保存 IngestionPipeline 的缓存 pipeline.persist("./pipeline_storage") new_pipeline = IngestionPipeline( transformations=[ SentenceSplitter(chunk_size=300, chunk_overlap=100), TitleExtractor(llm=Settings.llm), # 删去了调用嵌入模型(如 DashScopeEmbedding)将文本转换为向量的步骤 ], ) # 加载缓存 new_pipeline.load("./pipeline_storage") with Timer(): nodes = new_pipeline.run(documents=documents) -
结果:
100%|██████████| 3/3 [00:05<00:00, 1.98s/it] 100%|██████████| 5/5 [00:04<00:00, 1.08it/s] 100%|██████████| 5/5 [00:04<00:00, 1.07it/s] 100%|██████████| 4/4 [00:03<00:00, 1.29it/s] 耗时 39616.902112960815 ms Node ID: 4f6c78fa-c44f-46d5-8a31-7e6e3f9dcaef Text: Figure 3: Safety human evaluation results for Llama 2-Chat compared to other open-source and closed- source models. Human raters judged model generations for safety violations across ~2,000 adversarial prompts consisting of both single and multi-turn prompts. More details can be found in Section 4.4. It is important to caveat these safety result... Score: 0.688 耗时 0.9901523590087891 ms- 可以发现执行时间从
39616.902112960815 ms减少到了0.9901523590087891 ms;
- 可以发现执行时间从
-
此外:
- 也可以用远程的 Redis 或 MongoDB 等存储
IngestionPipeline的缓存,具体参考官方文档:Remote Cache Management; IngestionPipeline也支持异步和并发调用,请参考官方文档:Async Support、Parallel Processing。
- 也可以用远程的 Redis 或 MongoDB 等存储
5.8 检索后处理
-
LlamaIndex 的
Node Postprocessors提供了一系列检索后处理模块; -
例:可以用不同模型对检索后的
Nodes做重排序from llama_index.core.base.llms.types import LLMMetadata from qdrant_client import QdrantClient from qdrant_client.models import VectorParams, Distance from llama_index.core.node_parser import SentenceSplitter from llama_index.core.extractors import TitleExtractor from llama_index.core.ingestion import IngestionPipeline from llama_index.core import SimpleDirectoryReader, Settings from llama_index.readers.file import PyMuPDFReader from llama_index.core.indices.vector_store.base import VectorStoreIndex from llama_index.vector_stores.qdrant import QdrantVectorStore from llama_index.core.embeddings import BaseEmbedding from pydantic import Field # 用于定义数据模型的字段(Pydantic验证) from llama_index.core.llms import LLM, CompletionResponse, ChatResponse, ChatMessage from typing import Dict, List, Iterator, AsyncIterator from openai import OpenAI, AsyncOpenAI import os from llama_index.core import Settings # 继承 BaseEmbedding,定义一个兼容阿里云百炼的自定义嵌入模型类 class DashScopeEmbedding(BaseEmbedding): model: str = Field(default="text-embedding-v3", description="The model to use for embeddings") dimensions: int = Field(default=1024, description="The dimensions of the embedding vectors") # 初始化嵌入模型客户端 def __init__( self, model: str = "text-embedding-v3", # 模型名称 dimensions: int = 1024, # 指定嵌入向量的维度(1024) **kwargs ): super().__init__(**kwargs) self.model = model self.dimensions = dimensions # 创建同步 (OpenAI) 和异步 (AsyncOpenAI) 客户端 self._client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) self._async_client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) # 实现同步调用的嵌入生成方法 # 生成查询文本的嵌入向量 def _get_query_embedding(self, query: str) -> List[float]: return self._get_embeddings([query])[0] # 生成单个文本的嵌入向量 def _get_text_embedding(self, text: str) -> List[float]: return self._get_embeddings([text])[0] # 批量生成文本的嵌入向量 def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]: return self._get_embeddings(texts) # 实际调用阿里云API生成嵌入 def _get_embeddings(self, texts: List[str]) -> List[List[float]]: response = self._client.embeddings.create( model=self.model, input=texts, dimensions=self.dimensions, encoding_format="float" ) return [embedding.embedding for embedding in response.data] # 实现异步调用的嵌入生成方法(结构与同步方法类似,用于高性能场景) async def _aget_query_embedding(self, query: str) -> List[float]: return (await self._aget_embeddings([query]))[0] async def _aget_text_embedding(self, text: str) -> List[float]: return (await self._aget_embeddings([text]))[0] async def _aget_text_embeddings(self, texts: List[str]) -> List[List[float]]: return await self._aget_embeddings(texts) async def _aget_embeddings(self, texts: List[str]) -> List[List[float]]: response = await self._async_client.embeddings.create( model=self.model, input=texts, dimensions=self.dimensions, encoding_format="float" ) return [embedding.embedding for embedding in response.data] # 创建自定义LLM类,使用"qwen-max"模型 class DashScopeLLM(LLM): model_name: str = "qwen-max" @property def metadata(self) -> LLMMetadata: return LLMMetadata( context_window=8192, # 上下文窗口大小(token数) num_output=1024, # 最大输出token数 is_chat_model=True, # 是聊天模型 is_function_calling_model=False, # 不支持函数调用 model_name=self.model_name, # 模型名称 ) # 将 ChatMessage 对象列表转换为 API 需要的字典格式 def _format_messages(self, messages: List[ChatMessage]) -> List[Dict]: formatted_messages = [] for msg in messages: # 确保消息内容是字符串类型,避免类型错误 content = msg.content if isinstance(msg.content, str) else str(msg.content) formatted_messages.append({ "role": msg.role, # 角色(user/assistant/system) "content": content # 消息内容 }) return formatted_messages # 同步补全 def complete(self, prompt: str, **kwargs) -> CompletionResponse: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量获取API密钥 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 阿里云兼容端点 ) response = client.chat.completions.create( model=self.model_name, # 指定模型 messages=[{"role": "user", "content": prompt}], # 构造用户消息 **kwargs # 其他参数(如temperature等) ) return CompletionResponse(text=response.choices[0].message.content) # 返回响应 # 同步聊天。处理多轮对话场景,返回结构化的 ChatResponse 对象 def chat(self, messages: List[ChatMessage], **kwargs) -> ChatResponse: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) formatted_messages = self._format_messages(messages) # 格式化消息 response = client.chat.completions.create( model=self.model_name, messages=formatted_messages, # 使用格式化后的消息 **kwargs ) return ChatResponse( message=ChatMessage( role="assistant", # 设置角色为assistant content=response.choices[0].message.content # 获取响应内容 ) ) # 异步补全 async def acomplete(self, prompt: str, **kwargs) -> CompletionResponse: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( # 异步等待响应 model=self.model_name, messages=[{"role": "user", "content": prompt}], **kwargs ) return CompletionResponse(text=response.choices[0].message.content) # 异步聊天。异步版本的多轮对话处理,返回格式与同步版本一致 async def achat(self, messages: List[ChatMessage], **kwargs) -> ChatResponse: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) formatted_messages = self._format_messages(messages) response = await client.chat.completions.create( model=self.model_name, messages=formatted_messages, **kwargs ) return ChatResponse( message=ChatMessage( role="assistant", content=response.choices[0].message.content ) ) # 流式补全。实现流式文本生成,使用生成器逐步返回结果 def stream_complete(self, prompt: str, **kwargs) -> Iterator[CompletionResponse]: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = client.chat.completions.create( model=self.model_name, messages=[{"role": "user", "content": prompt}], stream=True, # 关键:启用流式响应 **kwargs ) def gen() -> Iterator[CompletionResponse]: for chunk in response: # 遍历流式响应的每个chunk yield CompletionResponse( text=chunk.choices[0].delta.content or "", # 获取增量内容 delta=chunk.choices[0].delta.content or "", # 同上 ) return gen() # 返回生成器 # 流式聊天。流式多轮对话,每次返回一个 ChatResponse 对象 def stream_chat(self, messages: List[ChatMessage], **kwargs) -> Iterator[ChatResponse]: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = client.chat.completions.create( model=self.model_name, messages=[m.dict() for m in messages], # 转换为字典 stream=True, **kwargs ) def gen() -> Iterator[ChatResponse]: for chunk in response: yield ChatResponse( message=ChatMessage( role="assistant", content=chunk.choices[0].delta.content or "" ) ) return gen() # 异步流式聊天 async def astream_chat(self, messages: List[ChatMessage], **kwargs) -> AsyncIterator[ChatResponse]: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( model=self.model_name, messages=[m.dict() for m in messages], stream=True, **kwargs ) # 异步遍历 async def gen() -> AsyncIterator[ChatResponse]: async for chunk in response: yield ChatResponse( message=ChatMessage( role="assistant", content=chunk.choices[0].delta.content or "" ) ) return gen() # 异步流式补全 async def astream_complete(self, prompt: str, **kwargs) -> AsyncIterator[CompletionResponse]: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( model=self.model_name, messages=[{"role": "user", "content": prompt}], stream=True, **kwargs ) async def gen() -> AsyncIterator[CompletionResponse]: async for chunk in response: yield CompletionResponse( text=chunk.choices[0].delta.content or "", delta=chunk.choices[0].delta.content or "", ) return gen() # 设置全局模型 Settings.embed_model = DashScopeEmbedding() Settings.llm = DashScopeLLM() # 在内存中创建Qdrant客户端 client = QdrantClient(location=":memory:") # 创建集合 ingestion_demo,配置向量维度为1024,相似度度量方式为余弦距离 collection_name = "ingestion_demo" collection = client.create_collection( collection_name=collection_name, vectors_config=VectorParams(size=1024, distance=Distance.COSINE) ) # 初始化一个 Qdrant 向量存储对象,用于后续存储文档向量 # client:之前创建的 Qdrant 客户端实例(内存或远程连接) # collection_name:指定要操作的集合名称(类似数据库表名) vector_store = QdrantVectorStore(client=client, collection_name=collection_name) # 定义一个文档处理流水线,按顺序执行:文本分块 → 2. 标题提取 → 3. 向量化 → 4. 存储到向量数据库 pipeline = IngestionPipeline( transformations=[ SentenceSplitter(chunk_size=300, chunk_overlap=100), # 将长文档分割成较小的文本块(chunks) TitleExtractor(llm=Settings.llm), # 为每个文本块生成一个简洁的标题(利用 LLM 理解内容) Settings.embed_model, # 调用嵌入模型(如 DashScopeEmbedding)将文本转换为向量 ], # 将生成的向量保存到之前初始化的 Qdrant 向量数据库中 vector_store=vector_store, ) # 加载 pdf 文档 documents = SimpleDirectoryReader( "./data", required_exts=[".pdf"], file_extractor={".pdf": PyMuPDFReader()} ).load_data() pipeline.run(documents=documents) # 创建索引 index = VectorStoreIndex.from_vector_store(vector_store) # 创建检索器 (retriever),设置返回最相似的5个结果 vector_retriever = index.as_retriever(similarity_top_k=5) # 查询 "Llama2 有商用许可吗?" nodes = vector_retriever.retrieve("Llama2 有商用许可吗?") for i, node in enumerate(nodes): print(f"[{i}] {node.text}\n") -
结果:
100%|██████████| 3/3 [00:05<00:00, 1.86s/it] 100%|██████████| 5/5 [00:07<00:00, 1.52s/it] 100%|██████████| 5/5 [00:09<00:00, 1.84s/it] 100%|██████████| 4/4 [00:03<00:00, 1.27it/s] [0] The capabilities of LLMs are remarkable considering the seemingly straightforward nature of the training methodology. Auto-regressive transformers are pretrained on an extensive corpus of self-supervised data, followed by alignment with human preferences via techniques such as Reinforcement Learning with Human Feedback (RLHF). Although the training methodology is simple, high computational requirements have limited the development of LLMs to a few players. There have been public releases of pretrained LLMs (such as BLOOM (Scao et al., 2022), LLaMa-1 (Touvron et al., 2023), and Falcon (Penedo et al., 2023)) that match the performance of closed pretrained competitors like GPT-3 (Brown et al., 2020) and Chinchilla (Hoffmann et al., 2022), but none of these models are suitable substitutes for closed “product” LLMs, such as ChatGPT, BARD, and Claude. These closed product LLMs are heavily fine-tuned to align with human preferences, which greatly enhances their usability and safety. [1] We release variants of this model with 7B, 13B, and 70B parameters as well. We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs, Llama 2 is a new technology that carries potential risks with use (Bender et al., 2021b; Weidinger et al., 2021; Solaiman et al., 2023). Testing conducted to date has been in English and has not — and could not — cover all scenarios. Therefore, before deploying any applications of Llama 2-Chat, developers should perform safety testing and tuning tailored to their specific applications of the model. We provide a responsible use guide¶ and code examples‖ to facilitate the safe deployment of Llama 2 and Llama 2-Chat. More details of our responsible release strategy can be found in Section 5.3. [2] Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper but are not releasing.§ 2. Llama 2-Chat, a fine-tuned version of Llama 2 that is optimized for dialogue use cases. We release variants of this model with 7B, 13B, and 70B parameters as well. We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs, Llama 2 is a new technology that carries potential risks with use (Bender et al., 2021b; Weidinger et al., 2021; Solaiman et al., 2023). [3] Figure 3: Safety human evaluation results for Llama 2-Chat compared to other open-source and closed- source models. Human raters judged model generations for safety violations across ~2,000 adversarial prompts consisting of both single and multi-turn prompts. More details can be found in Section 4.4. It is important to caveat these safety results with the inherent bias of LLM evaluations due to limitations of the prompt set, subjectivity of the review guidelines, and subjectivity of individual raters. Additionally, these safety evaluations are performed using content standards that are likely to be biased towards the Llama 2-Chat models. We are releasing the following models to the general public for research and commercial use‡: 1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. [4] These closed product LLMs are heavily fine-tuned to align with human preferences, which greatly enhances their usability and safety. This step can require significant costs in compute and human annotation, and is often not transparent or easily reproducible, limiting progress within the community to advance AI alignment research. In this work, we develop and release Llama 2, a family of pretrained and fine-tuned LLMs, Llama 2 and Llama 2-Chat, at scales up to 70B parameters. On the series of helpfulness and safety benchmarks we tested, Llama 2-Chat models generally perform better than existing open-source models. They also appear to be on par with some of the closed-source models, at least on the human evaluations we performed (see Figures 1 and 3). We have taken measures to increase the safety of these models, using safety-specific data annotation and tuning, as well as conducting red-teaming and employing iterative evaluations. Additionally, this paper contributes a thorough description of our fine-tuning methodology and approach to improving LLM safety.- 从输出看,检索系统成功返回了与查询“Llama2 有商用许可吗?”相关的文档片段:
- 结果
[0]和[4]提到Llama 2的开源性质及商用许可(“release to the general public for research and commercial use”); - 其他结果补充了Llama 2的技术细节(如参数规模、安全评估等);
- 结果
- 从输出看,检索系统成功返回了与查询“Llama2 有商用许可吗?”相关的文档片段:
-
接下来使用 Hugging Face 的
SentenceTransformerRerank模型,用于对检索结果进行重新排序(Re-Rank),该模型的核心作用是提升检索系统的精度;# 剩余代码同上,只做下面的修改 # 查询 "Llama2 有商用许可吗?" nodes = vector_retriever.retrieve("Llama2 有商用许可吗?") # for i, node in enumerate(nodes): # print(f"[{i}] {node.text}\n") os.environ["HF_ENDPOINT"] = "https://hf-mirror.com" # 使用HF镜像站 from llama_index.core.postprocessor import SentenceTransformerRerank # 检索后排序模型 postprocessor = SentenceTransformerRerank( model="BAAI/bge-reranker-large", top_n=2 ) nodes = postprocessor.postprocess_nodes(nodes, query_str="Llama2 有商用许可吗?") for i, node in enumerate(nodes): print(f"[{i}] {node.text}") -
结果:
100%|██████████| 3/3 [00:05<00:00, 1.78s/it] 100%|██████████| 5/5 [00:05<00:00, 1.18s/it] 100%|██████████| 5/5 [00:05<00:00, 1.13s/it] 100%|██████████| 4/4 [00:05<00:00, 1.29s/it] [0] Figure 3: Safety human evaluation results for Llama 2-Chat compared to other open-source and closed- source models. Human raters judged model generations for safety violations across ~2,000 adversarial prompts consisting of both single and multi-turn prompts. More details can be found in Section 4.4. It is important to caveat these safety results with the inherent bias of LLM evaluations due to limitations of the prompt set, subjectivity of the review guidelines, and subjectivity of individual raters. Additionally, these safety evaluations are performed using content standards that are likely to be biased towards the Llama 2-Chat models. We are releasing the following models to the general public for research and commercial use‡: 1. Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. [1] Llama 2, an updated version of Llama 1, trained on a new mix of publicly available data. We also increased the size of the pretraining corpus by 40%, doubled the context length of the model, and adopted grouped-query attention (Ainslie et al., 2023). We are releasing variants of Llama 2 with 7B, 13B, and 70B parameters. We have also trained 34B variants, which we report on in this paper but are not releasing.§ 2. Llama 2-Chat, a fine-tuned version of Llama 2 that is optimized for dialogue use cases. We release variants of this model with 7B, 13B, and 70B parameters as well. We believe that the open release of LLMs, when done safely, will be a net benefit to society. Like all LLMs, Llama 2 is a new technology that carries potential risks with use (Bender et al., 2021b; Weidinger et al., 2021; Solaiman et al., 2023).- 结果 [0]:
- 内容重点:
- 提到了 Llama 2-Chat 的安全评估结果(与开源/闭源模型的对比);
- 明确说明 Llama 2 系列模型(包括 7B、13B、70B 参数版本)已公开发布,可用于研究和商业用途(
research and commercial use); - 提示了模型评估可能存在偏差(如评测标准的主观性);
- **为什么被排到第一?**Re-Rank 模型识别到以下关键信息:
- “research and commercial use” 直接回应了“商用许可”的查询意图;
- 虽然开头提到安全评估,但后续的“商用许可”描述更贴合问题;
- 结果 [1]:
- 内容重点:
- 重复强调了 Llama 2 的版本更新和参数规模(7B/13B/70B);
- 补充说明了 Llama 2-Chat 是对话优化的版本,同样开放商用;
- 提到技术风险(所有LLM共有问题,非Llama 2特有);
- 为什么被排到第二?
- 包含“商用”相关信息,但未像 [0] 那样直接明确提到许可条款;
- Re-Rank 模型可能认为其相关性略低于 [0];
- Re-Rank 的作用体现:
- 去重:原始检索结果可能包含重复内容(如参数规格描述),Re-Rank 过滤了冗余信息;
- 精准聚焦:将最直接回答“商用许可”的段落([0] 中的
research and commercial use)排到顶部,而非仅匹配“Llama 2”关键词的泛泛描述; - 长文本优化:即使段落较长(如 [0] 包含安全评估和许可信息),模型也能识别出核心句子的相关性;
-
更多的 Rerank 及其它后处理方法,参考官方文档:Node Postprocessor Modules。
6 生成回复(QA & Chat)
6.1 单轮回答(Query Engine)
-
例:
from llama_index.core.base.llms.types import LLMMetadata from qdrant_client import QdrantClient from qdrant_client.models import VectorParams, Distance from llama_index.core.node_parser import SentenceSplitter from llama_index.core.extractors import TitleExtractor from llama_index.core.ingestion import IngestionPipeline from llama_index.core import SimpleDirectoryReader, Settings from llama_index.readers.file import PyMuPDFReader from llama_index.core.indices.vector_store.base import VectorStoreIndex from llama_index.vector_stores.qdrant import QdrantVectorStore from llama_index.core.embeddings import BaseEmbedding from pydantic import Field # 用于定义数据模型的字段(Pydantic验证) from llama_index.core.llms import LLM, CompletionResponse, ChatResponse, ChatMessage from typing import Dict, List, Iterator, AsyncIterator from openai import OpenAI, AsyncOpenAI import os from llama_index.core import Settings # 继承 BaseEmbedding,定义一个兼容阿里云百炼的自定义嵌入模型类 class DashScopeEmbedding(BaseEmbedding): model: str = Field(default="text-embedding-v3", description="The model to use for embeddings") dimensions: int = Field(default=1024, description="The dimensions of the embedding vectors") # 初始化嵌入模型客户端 def __init__( self, model: str = "text-embedding-v3", # 模型名称 dimensions: int = 1024, # 指定嵌入向量的维度(1024) **kwargs ): super().__init__(**kwargs) self.model = model self.dimensions = dimensions # 创建同步 (OpenAI) 和异步 (AsyncOpenAI) 客户端 self._client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) self._async_client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) # 实现同步调用的嵌入生成方法 # 生成查询文本的嵌入向量 def _get_query_embedding(self, query: str) -> List[float]: return self._get_embeddings([query])[0] # 生成单个文本的嵌入向量 def _get_text_embedding(self, text: str) -> List[float]: return self._get_embeddings([text])[0] # 批量生成文本的嵌入向量 def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]: return self._get_embeddings(texts) # 实际调用阿里云API生成嵌入 def _get_embeddings(self, texts: List[str]) -> List[List[float]]: response = self._client.embeddings.create( model=self.model, input=texts, dimensions=self.dimensions, encoding_format="float" ) return [embedding.embedding for embedding in response.data] # 实现异步调用的嵌入生成方法(结构与同步方法类似,用于高性能场景) async def _aget_query_embedding(self, query: str) -> List[float]: return (await self._aget_embeddings([query]))[0] async def _aget_text_embedding(self, text: str) -> List[float]: return (await self._aget_embeddings([text]))[0] async def _aget_text_embeddings(self, texts: List[str]) -> List[List[float]]: return await self._aget_embeddings(texts) async def _aget_embeddings(self, texts: List[str]) -> List[List[float]]: response = await self._async_client.embeddings.create( model=self.model, input=texts, dimensions=self.dimensions, encoding_format="float" ) return [embedding.embedding for embedding in response.data] # 创建自定义LLM类,使用"qwen-max"模型 class DashScopeLLM(LLM): model_name: str = "qwen-max" @property def metadata(self) -> LLMMetadata: return LLMMetadata( context_window=8192, # 上下文窗口大小(token数) num_output=1024, # 最大输出token数 is_chat_model=True, # 是聊天模型 is_function_calling_model=False, # 不支持函数调用 model_name=self.model_name, # 模型名称 ) # 将 ChatMessage 对象列表转换为 API 需要的字典格式 def _format_messages(self, messages: List[ChatMessage]) -> List[Dict]: formatted_messages = [] for msg in messages: # 确保消息内容是字符串类型,避免类型错误 content = msg.content if isinstance(msg.content, str) else str(msg.content) formatted_messages.append({ "role": msg.role, # 角色(user/assistant/system) "content": content # 消息内容 }) return formatted_messages # 同步补全 def complete(self, prompt: str, **kwargs) -> CompletionResponse: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量获取API密钥 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 阿里云兼容端点 ) response = client.chat.completions.create( model=self.model_name, # 指定模型 messages=[{"role": "user", "content": prompt}], # 构造用户消息 **kwargs # 其他参数(如temperature等) ) return CompletionResponse(text=response.choices[0].message.content) # 返回响应 # 同步聊天。处理多轮对话场景,返回结构化的 ChatResponse 对象 def chat(self, messages: List[ChatMessage], **kwargs) -> ChatResponse: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) formatted_messages = self._format_messages(messages) # 格式化消息 response = client.chat.completions.create( model=self.model_name, messages=formatted_messages, # 使用格式化后的消息 **kwargs ) return ChatResponse( message=ChatMessage( role="assistant", # 设置角色为assistant content=response.choices[0].message.content # 获取响应内容 ) ) # 异步补全 async def acomplete(self, prompt: str, **kwargs) -> CompletionResponse: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( # 异步等待响应 model=self.model_name, messages=[{"role": "user", "content": prompt}], **kwargs ) return CompletionResponse(text=response.choices[0].message.content) # 异步聊天。异步版本的多轮对话处理,返回格式与同步版本一致 async def achat(self, messages: List[ChatMessage], **kwargs) -> ChatResponse: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) formatted_messages = self._format_messages(messages) response = await client.chat.completions.create( model=self.model_name, messages=formatted_messages, **kwargs ) return ChatResponse( message=ChatMessage( role="assistant", content=response.choices[0].message.content ) ) # 流式补全。实现流式文本生成,使用生成器逐步返回结果 def stream_complete(self, prompt: str, **kwargs) -> Iterator[CompletionResponse]: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = client.chat.completions.create( model=self.model_name, messages=[{"role": "user", "content": prompt}], stream=True, # 关键:启用流式响应 **kwargs ) def gen() -> Iterator[CompletionResponse]: for chunk in response: # 遍历流式响应的每个chunk yield CompletionResponse( text=chunk.choices[0].delta.content or "", # 获取增量内容 delta=chunk.choices[0].delta.content or "", # 同上 ) return gen() # 返回生成器 # 流式聊天。流式多轮对话,每次返回一个 ChatResponse 对象 def stream_chat(self, messages: List[ChatMessage], **kwargs) -> Iterator[ChatResponse]: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = client.chat.completions.create( model=self.model_name, messages=[m.dict() for m in messages], # 转换为字典 stream=True, **kwargs ) def gen() -> Iterator[ChatResponse]: for chunk in response: yield ChatResponse( message=ChatMessage( role="assistant", content=chunk.choices[0].delta.content or "" ) ) return gen() # 异步流式聊天 async def astream_chat(self, messages: List[ChatMessage], **kwargs) -> AsyncIterator[ChatResponse]: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( model=self.model_name, messages=[m.dict() for m in messages], stream=True, **kwargs ) # 异步遍历 async def gen() -> AsyncIterator[ChatResponse]: async for chunk in response: yield ChatResponse( message=ChatMessage( role="assistant", content=chunk.choices[0].delta.content or "" ) ) return gen() # 异步流式补全 async def astream_complete(self, prompt: str, **kwargs) -> AsyncIterator[CompletionResponse]: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( model=self.model_name, messages=[{"role": "user", "content": prompt}], stream=True, **kwargs ) async def gen() -> AsyncIterator[CompletionResponse]: async for chunk in response: yield CompletionResponse( text=chunk.choices[0].delta.content or "", delta=chunk.choices[0].delta.content or "", ) return gen() # 设置全局模型 Settings.embed_model = DashScopeEmbedding() Settings.llm = DashScopeLLM() # 在内存中创建Qdrant客户端 client = QdrantClient(location=":memory:") # 创建集合 ingestion_demo,配置向量维度为1024,相似度度量方式为余弦距离 collection_name = "ingestion_demo" collection = client.create_collection( collection_name=collection_name, vectors_config=VectorParams(size=1024, distance=Distance.COSINE) ) # 初始化一个 Qdrant 向量存储对象,用于后续存储文档向量 # client:之前创建的 Qdrant 客户端实例(内存或远程连接) # collection_name:指定要操作的集合名称(类似数据库表名) vector_store = QdrantVectorStore(client=client, collection_name=collection_name) # 定义一个文档处理流水线,按顺序执行:文本分块 → 2. 标题提取 → 3. 向量化 → 4. 存储到向量数据库 pipeline = IngestionPipeline( transformations=[ SentenceSplitter(chunk_size=300, chunk_overlap=100), # 将长文档分割成较小的文本块(chunks) TitleExtractor(llm=Settings.llm), # 为每个文本块生成一个简洁的标题(利用 LLM 理解内容) Settings.embed_model, # 调用嵌入模型(如 DashScopeEmbedding)将文本转换为向量 ], # 将生成的向量保存到之前初始化的 Qdrant 向量数据库中 vector_store=vector_store, ) # 加载 pdf 文档 documents = SimpleDirectoryReader( "./data", required_exts=[".pdf"], file_extractor={".pdf": PyMuPDFReader()} ).load_data() pipeline.run(documents=documents) # 创建索引 index = VectorStoreIndex.from_vector_store(vector_store) # 单轮回答(Query Engine) qa_engine = index.as_query_engine() response = qa_engine.query("Llama2 有多少参数?") print(response) -
结果:
100%|██████████| 3/3 [00:04<00:00, 1.48s/it] 100%|██████████| 5/5 [00:04<00:00, 1.07it/s] 100%|██████████| 5/5 [00:07<00:00, 1.41s/it] 100%|██████████| 4/4 [00:04<00:00, 1.02s/it] Llama 2 有几种不同参数规模的变体,分别是70亿、130亿和700亿参数。此外,还提到了一个340亿参数的版本,但这个版本没有对外发布。 -
流式输出:添加
streaming=True参数# 流式输出(失败,可能是与阿里云百炼 API 不兼容) # qa_engine = index.as_query_engine(streaming=True) # response = qa_engine.query("Llama2 有多少参数?") # response.print_response_stream()
6.2 多轮对话(Chat Engine)
-
例:
# 剩余代码同 6.1 单轮回答(Query Engine),只做下面的修改 # 多轮对话(Chat Engine) chat_engine = index.as_chat_engine() response = chat_engine.chat("Llama2 有多少参数?") print(response) -
结果:
100%|██████████| 3/3 [00:04<00:00, 1.40s/it] 100%|██████████| 5/5 [00:06<00:00, 1.23s/it] 100%|██████████| 5/5 [00:05<00:00, 1.02s/it] 100%|██████████| 4/4 [00:04<00:00, 1.03s/it] Llama 2 有多种参数规模的版本,分别为70亿、130亿和700亿参数。此外,还提到了一个340亿参数的版本,但这个版本并未对外发布。 -
流式输出:
# 流式输出(失败) # chat_engine = index.as_chat_engine() # streaming_response = chat_engine.stream_chat("Llama 2有多少参数?") # # streaming_response.print_response_stream() # for token in streaming_response.response_gen: # print(token, end="", flush=True)
7 底层接口:Prompt、LLM 与 Embedding
7.1 Prompt 模板
-
PromptTemplate定义提示词模板:from llama_index.core import PromptTemplate prompt = PromptTemplate("写一个关于{topic}的笑话") print(prompt.format(topic="小明")) -
结果:
写一个关于小明的笑话 -
ChatPromptTemplate定义多轮消息模板:from llama_index.core.llms import ChatMessage, MessageRole from llama_index.core import ChatPromptTemplate chat_text_qa_msgs = [ ChatMessage( role=MessageRole.SYSTEM, content="你叫{name},你必须根据用户提供的上下文回答问题。", ), ChatMessage( role=MessageRole.USER, content=( "已知上下文:\n" \ "{context}\n\n" \ "问题:{question}" ) ), ] text_qa_template = ChatPromptTemplate(chat_text_qa_msgs) print( text_qa_template.format( name="瓜瓜", context="这是一个测试", question="这是什么" ) ) -
结果:
system: 你叫瓜瓜,你必须根据用户提供的上下文回答问题。 user: 已知上下文: 这是一个测试 问题:这是什么 assistant:
7.2 语言模型
-
若使用 OpenAI 的大模型,参考代码如下:
from llama_index.llms.openai import OpenAI llm = OpenAI(temperature=0, model="gpt-4o") response = llm.complete(prompt.format(topic="小明")) print(response.text) -
使用
qwen-plus模型:import os from llama_index.core import PromptTemplate from llama_index.core.llms import ChatMessage, MessageRole from llama_index.core import ChatPromptTemplate from openai import OpenAI class QwenLLM: def __init__(self, temperature=0, model="qwen-plus"): self.client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", ) self.temperature = temperature self.model = model def complete(self, prompt): completion = self.client.chat.completions.create( model=self.model, messages=[ {'role': 'system', 'content': 'You are a helpful assistant.'}, {'role': 'user', 'content': prompt} ], temperature=self.temperature ) return completion.choices[0].message.content prompt = PromptTemplate("写一个关于{topic}的笑话") # 使用示例 llm = QwenLLM(temperature=0, model="qwen-plus") response = llm.complete(prompt.format(topic="小明")) print(response) chat_text_qa_msgs = [ ChatMessage( role=MessageRole.SYSTEM, content="你叫{name},你必须根据用户提供的上下文回答问题。", ), ChatMessage( role=MessageRole.USER, content=( "已知上下文:\n" "{context}\n\n" "问题:{question}" ) ), ] text_qa_template = ChatPromptTemplate(chat_text_qa_msgs) response = llm.complete( text_qa_template.format( name="瓜瓜", context="这是一个测试", question="你是谁,我们在干嘛" ) ) print(response) -
结果:
小明有一天跟爸爸说:“爸爸,我想要一台新电脑。” 爸爸问:“为什么呀?你的电脑不是还能用吗?” 小明一本正经地回答:“因为昨天我用它查‘大象有多重’,结果把电脑给压崩溃了!” 我是瓜瓜,根据上下文“这是一个测试”,我们正在做一个测试。 -
设置全局使用的语言模型(OpenAI 的大模型),参考代码如下:
from llama_index.core import Settings Settings.llm = OpenAI(temperature=0, model="gpt-4o") -
设置全局使用的语言模型(OpenAI 的大模型):
from llama_index.core import Settings from llama_index.llms.dashscope import DashScope # 设置 DashScope(通义千问)作为 LLM Settings.llm = DashScope( model="qwen-plus", # 可选:qwen-turbo, qwen-plus, qwen-max api_key=os.getenv("DASHSCOPE_API_KEY") ) -
除 OpenAI 外,LlamaIndex 已集成多个大语言模型,包括云服务 API 和本地部署 API,详见官方文档:Available LLM integrations。
7.3 Embedding 模型
-
若使用 OpenAI 的大模型,参考代码如下:
from llama_index.embeddings.openai import OpenAIEmbedding from llama_index.core import Settings # 全局设定 Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=512) -
若使用阿里云的向量模型
text-embedding-v3import os from llama_index.embeddings.dashscope import DashScopeEmbedding from llama_index.core import Settings # 全局设定 Settings.embed_model = DashScopeEmbedding( model="text-embedding-v3", # 使用DashScope的文本嵌入模型 dimensions=512, # 设置维度为512 api_key=os.getenv("DASHSCOPE_API_KEY") # 从环境变量获取API Key ) -
LlamaIndex 同样集成了多种 Embedding 模型,包括云服务 API 和开源模型(HuggingFace)等,详见官方文档。
8 基于 LlamaIndex 实现一个功能较完整的 RAG 系统
-
功能要求:
- 加载指定目录的文件;
- 支持 RAG-Fusion;
- 使用 Qdrant 向量数据库,并持久化到本地;
- 支持检索后排序;
- 支持多轮对话;
from llama_index.core.base.llms.types import LLMMetadata from llama_index.core.chat_engine import CondenseQuestionChatEngine from llama_index.core.postprocessor import SentenceTransformerRerank from llama_index.core.query_engine import RetrieverQueryEngine from llama_index.core.retrievers import QueryFusionRetriever from qdrant_client import QdrantClient from llama_index.core.node_parser import SentenceSplitter from llama_index.core.extractors import TitleExtractor from llama_index.core import SimpleDirectoryReader, Settings, StorageContext from llama_index.readers.file import PyMuPDFReader from llama_index.core.indices.vector_store.base import VectorStoreIndex from llama_index.vector_stores.qdrant import QdrantVectorStore from llama_index.core.embeddings import BaseEmbedding from pydantic import Field # 用于定义数据模型的字段(Pydantic验证) from llama_index.core.llms import LLM, CompletionResponse, ChatResponse, ChatMessage from typing import Dict, List, Iterator, AsyncIterator from openai import OpenAI, AsyncOpenAI import os EMBEDDING_DIM = 512 # 指定向量的维度为512 COLLECTION_NAME = "full_demo" # 定义集合(collection)的名称为"full_demo" PATH = "./qdrant_db" # 指定数据库存储的本地路径 client = QdrantClient(path=PATH) # 创建一个连接到本地Qdrant数据库的客户端实例,数据库文件将存储在"./qdrant_db"路径下 # 继承 BaseEmbedding,定义一个兼容阿里云百炼的自定义嵌入模型类 class DashScopeEmbedding(BaseEmbedding): model: str = Field(default="text-embedding-v3", description="The model to use for embeddings") dimensions: int = Field(default=1024, description="The dimensions of the embedding vectors") # 初始化嵌入模型客户端 def __init__( self, model: str = "text-embedding-v3", # 模型名称 dimensions: int = 1024, # 指定嵌入向量的维度(1024) **kwargs ): super().__init__(**kwargs) self.model = model self.dimensions = dimensions # 创建同步 (OpenAI) 和异步 (AsyncOpenAI) 客户端 self._client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) self._async_client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) # 实现同步调用的嵌入生成方法 # 生成查询文本的嵌入向量 def _get_query_embedding(self, query: str) -> List[float]: return self._get_embeddings([query])[0] # 生成单个文本的嵌入向量 def _get_text_embedding(self, text: str) -> List[float]: return self._get_embeddings([text])[0] # 批量生成文本的嵌入向量 def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]: return self._get_embeddings(texts) # 实际调用阿里云API生成嵌入 def _get_embeddings(self, texts: List[str]) -> List[List[float]]: response = self._client.embeddings.create( model=self.model, input=texts, dimensions=self.dimensions, encoding_format="float" ) return [embedding.embedding for embedding in response.data] # 实现异步调用的嵌入生成方法(结构与同步方法类似,用于高性能场景) async def _aget_query_embedding(self, query: str) -> List[float]: return (await self._aget_embeddings([query]))[0] async def _aget_text_embedding(self, text: str) -> List[float]: return (await self._aget_embeddings([text]))[0] async def _aget_text_embeddings(self, texts: List[str]) -> List[List[float]]: return await self._aget_embeddings(texts) async def _aget_embeddings(self, texts: List[str]) -> List[List[float]]: response = await self._async_client.embeddings.create( model=self.model, input=texts, dimensions=self.dimensions, encoding_format="float" ) return [embedding.embedding for embedding in response.data] # 创建自定义LLM类,使用"qwen-max"模型 class DashScopeLLM(LLM): model_name: str = "qwen-max" @property def metadata(self) -> LLMMetadata: return LLMMetadata( context_window=8192, # 上下文窗口大小(token数) num_output=1024, # 最大输出token数 is_chat_model=True, # 是聊天模型 is_function_calling_model=False, # 不支持函数调用 model_name=self.model_name, # 模型名称 ) # 将 ChatMessage 对象列表转换为 API 需要的字典格式 def _format_messages(self, messages: List[ChatMessage]) -> List[Dict]: formatted_messages = [] for msg in messages: # 确保消息内容是字符串类型,避免类型错误 content = msg.content if isinstance(msg.content, str) else str(msg.content) formatted_messages.append({ "role": msg.role, # 角色(user/assistant/system) "content": content # 消息内容 }) return formatted_messages # 同步补全 def complete(self, prompt: str, **kwargs) -> CompletionResponse: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # 从环境变量获取API密钥 base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 阿里云兼容端点 ) response = client.chat.completions.create( model=self.model_name, # 指定模型 messages=[{"role": "user", "content": prompt}], # 构造用户消息 **kwargs # 其他参数(如temperature等) ) return CompletionResponse(text=response.choices[0].message.content) # 返回响应 # 同步聊天。处理多轮对话场景,返回结构化的 ChatResponse 对象 def chat(self, messages: List[ChatMessage], **kwargs) -> ChatResponse: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) formatted_messages = self._format_messages(messages) # 格式化消息 response = client.chat.completions.create( model=self.model_name, messages=formatted_messages, # 使用格式化后的消息 **kwargs ) return ChatResponse( message=ChatMessage( role="assistant", # 设置角色为assistant content=response.choices[0].message.content # 获取响应内容 ) ) # 异步补全 async def acomplete(self, prompt: str, **kwargs) -> CompletionResponse: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( # 异步等待响应 model=self.model_name, messages=[{"role": "user", "content": prompt}], **kwargs ) return CompletionResponse(text=response.choices[0].message.content) # 异步聊天。异步版本的多轮对话处理,返回格式与同步版本一致 async def achat(self, messages: List[ChatMessage], **kwargs) -> ChatResponse: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) formatted_messages = self._format_messages(messages) response = await client.chat.completions.create( model=self.model_name, messages=formatted_messages, **kwargs ) return ChatResponse( message=ChatMessage( role="assistant", content=response.choices[0].message.content ) ) # 流式补全。实现流式文本生成,使用生成器逐步返回结果 def stream_complete(self, prompt: str, **kwargs) -> Iterator[CompletionResponse]: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = client.chat.completions.create( model=self.model_name, messages=[{"role": "user", "content": prompt}], stream=True, # 关键:启用流式响应 **kwargs ) def gen() -> Iterator[CompletionResponse]: for chunk in response: # 遍历流式响应的每个chunk yield CompletionResponse( text=chunk.choices[0].delta.content or "", # 获取增量内容 delta=chunk.choices[0].delta.content or "", # 同上 ) return gen() # 返回生成器 # 流式聊天。流式多轮对话,每次返回一个 ChatResponse 对象 def stream_chat(self, messages: List[ChatMessage], **kwargs) -> Iterator[ChatResponse]: client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = client.chat.completions.create( model=self.model_name, messages=[m.dict() for m in messages], # 转换为字典 stream=True, **kwargs ) def gen() -> Iterator[ChatResponse]: for chunk in response: yield ChatResponse( message=ChatMessage( role="assistant", content=chunk.choices[0].delta.content or "" ) ) return gen() # 异步流式聊天 async def astream_chat(self, messages: List[ChatMessage], **kwargs) -> AsyncIterator[ChatResponse]: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( model=self.model_name, messages=[m.dict() for m in messages], stream=True, **kwargs ) # 异步遍历 async def gen() -> AsyncIterator[ChatResponse]: async for chunk in response: yield ChatResponse( message=ChatMessage( role="assistant", content=chunk.choices[0].delta.content or "" ) ) return gen() # 异步流式补全 async def astream_complete(self, prompt: str, **kwargs) -> AsyncIterator[CompletionResponse]: client = AsyncOpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" ) response = await client.chat.completions.create( model=self.model_name, messages=[{"role": "user", "content": prompt}], stream=True, **kwargs ) async def gen() -> AsyncIterator[CompletionResponse]: async for chunk in response: yield CompletionResponse( text=chunk.choices[0].delta.content or "", delta=chunk.choices[0].delta.content or "", ) return gen() # 1、设置全局LLM和Embedding模型 Settings.embed_model = DashScopeEmbedding() Settings.llm = DashScopeLLM() # 2、指定全局文档处理的 Ingestion Pipeline Settings.transformations = [ SentenceSplitter(chunk_size=300, chunk_overlap=100), # 将长文档分割成较小的文本块(chunks) TitleExtractor(llm=Settings.llm), # 为每个文本块生成一个简洁的标题(利用 LLM 理解内容) ] # 3、加载 pdf 文档 documents = SimpleDirectoryReader( "./data", file_extractor={".pdf": PyMuPDFReader()} ).load_data() # 4、创建 collection if client.collection_exists(collection_name=COLLECTION_NAME): client.delete_collection(collection_name=COLLECTION_NAME) # 5、创建 Vector Store vector_store = QdrantVectorStore(client=client, collection_name=COLLECTION_NAME) # 6、指定 Vector Store 的 Storage 用于 index storage_context = StorageContext.from_defaults(vector_store=vector_store) index = VectorStoreIndex.from_documents( documents, storage_context=storage_context ) # 7、定义检索后排序模型 reranker = SentenceTransformerRerank( model="BAAI/bge-reranker-large", # model="BAAI/bge-reranker-v2-m3", # 可以使用更强的模型,但是要加上os.environ["HF_ENDPOINT"] = "https://hf-mirror.com",使用HF镜像站 top_n=5 ) # 8、定义 RAG Fusion 检索器 fusion_retriever = QueryFusionRetriever( [index.as_retriever()], similarity_top_k=10, # 增加检索数量 num_queries=5, # 增加查询变体数量 use_async=False, # 禁用异步可能提升性能 query_gen_prompt=( "你是一个专业的AI助手。请为以下用户问题生成3-5个不同角度的搜索查询," "确保包含技术细节的变体。用户问题:{query}" ) ) # 9. 构建单轮 query engine query_engine = RetrieverQueryEngine.from_args( fusion_retriever, node_postprocessors=[reranker] ) # 10. 对话引擎 chat_engine = CondenseQuestionChatEngine.from_defaults( query_engine=query_engine, # condense_question_prompt=... # 可以自定义 chat message prompt 模板 ) while True: question = input("User: ").strip() # 如果用户输入以下内容,就退出 if question.lower() in ("exit", "quit", ""): print("对话结束") break response = chat_engine.chat(question) print(f"AI: {response}") -
结果:
100%|██████████| 5/5 [00:04<00:00, 1.23it/s] 100%|██████████| 3/3 [00:03<00:00, 1.33s/it] 100%|██████████| 5/5 [00:05<00:00, 1.02s/it] 100%|██████████| 5/5 [00:06<00:00, 1.33s/it] 100%|██████████| 4/4 [00:04<00:00, 1.14s/it] C:\python3.12.7\Lib\site-packages\llama_index\vector_stores\qdrant\base.py:703: UserWarning: Payload indexes have no effect in the local Qdrant. Please use server Qdrant if you need payload indexes. self._client.create_payload_index( User: llama2有多少参数 AI: Llama 2有多个参数规模的版本,包括70亿、130亿和700亿参数的版本。此外,还提到了一个340亿参数的版本,但这个版本没有对外发布。 User: 最多多少 AI: Llama 2的最大参数规模是70B。 User: 对话结束-
出现的警告如下,这是无害的,只是说明使用的是本地Qdrant而非服务器版本;
UserWarning: Payload indexes have no effect in the local Qdrant. -
虽然基本功能已经实现,但是参数回答不准确:AI回答"Llama 2模型的最大参数量是70亿"明显是错误的(实际最大应该是700亿)。这可能由以下原因导致:
- PDF文档数据可能不完整或过时;
- 检索-排序环节可能没有正确返回最相关的信息;
- RAG Fusion生成的查询可能不够准确;
-
解决:
-
尝试调整检索参数提高准确性 & 调整reranker保留更多结果
# 尝试调整检索参数提高准确性 fusion_retriever = QueryFusionRetriever( [index.as_retriever()], similarity_top_k=10, # 增加检索数量 num_queries=5, # 增加查询变体数量 use_async=True, # 启用异步可能提升性能(慎用,LlamaIndex与国产大模型的兼容存在一定问题) ) # 调整reranker保留更多结果 reranker = SentenceTransformerRerank( model="BAAI/bge-reranker-large", top_n=5 # 增加保留的排序结果数 ) -
使用更强的reranker模型;
- 要加上
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com",使用HF镜像站
# 使用更强的reranker模型 reranker = SentenceTransformerRerank( model="BAAI/bge-reranker-v2-m3", # 使用更强的模型 top_n=5 ) - 要加上
-
-


















 499
499

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











