







 上文提到过策略梯度的模型优化过程,首先利用当前策略采样获得大量轨迹,然后根据轨迹计算梯度优化模型参数。因为每一轮策略模型更新后,采样获得的轨迹分布发生变化,所以上一轮采样的历史轨迹不能重用。在目标函数中增加了两种策略采样分布的距离(采集到的(s,a)对的距离),希望通过减小KL也就是分布差距实现在优化的同时两种分布不要差距过大。的差距不能太大,否则即使经过重要性采样转换后,所采集的数据的方差仍然具有较大差距。来改变采样数据的分布,这样我们就可以实现从其他策略采样获得的轨迹中学习了。
上文提到过策略梯度的模型优化过程,首先利用当前策略采样获得大量轨迹,然后根据轨迹计算梯度优化模型参数。因为每一轮策略模型更新后,采样获得的轨迹分布发生变化,所以上一轮采样的历史轨迹不能重用。在目标函数中增加了两种策略采样分布的距离(采集到的(s,a)对的距离),希望通过减小KL也就是分布差距实现在优化的同时两种分布不要差距过大。的差距不能太大,否则即使经过重要性采样转换后,所采集的数据的方差仍然具有较大差距。来改变采样数据的分布,这样我们就可以实现从其他策略采样获得的轨迹中学习了。
Reference
[1] Hung-yi Lee: https://youtu.be/OAKAZhFmYoI
1. Policy Gradient
一种policy-based方法,由策略网络直接输出动作。
1.1 Actor, Enviroment, Reward
(1)Actor
Actor指策略网络 π θ \pi_\theta πθ,输入状态s输出动作。
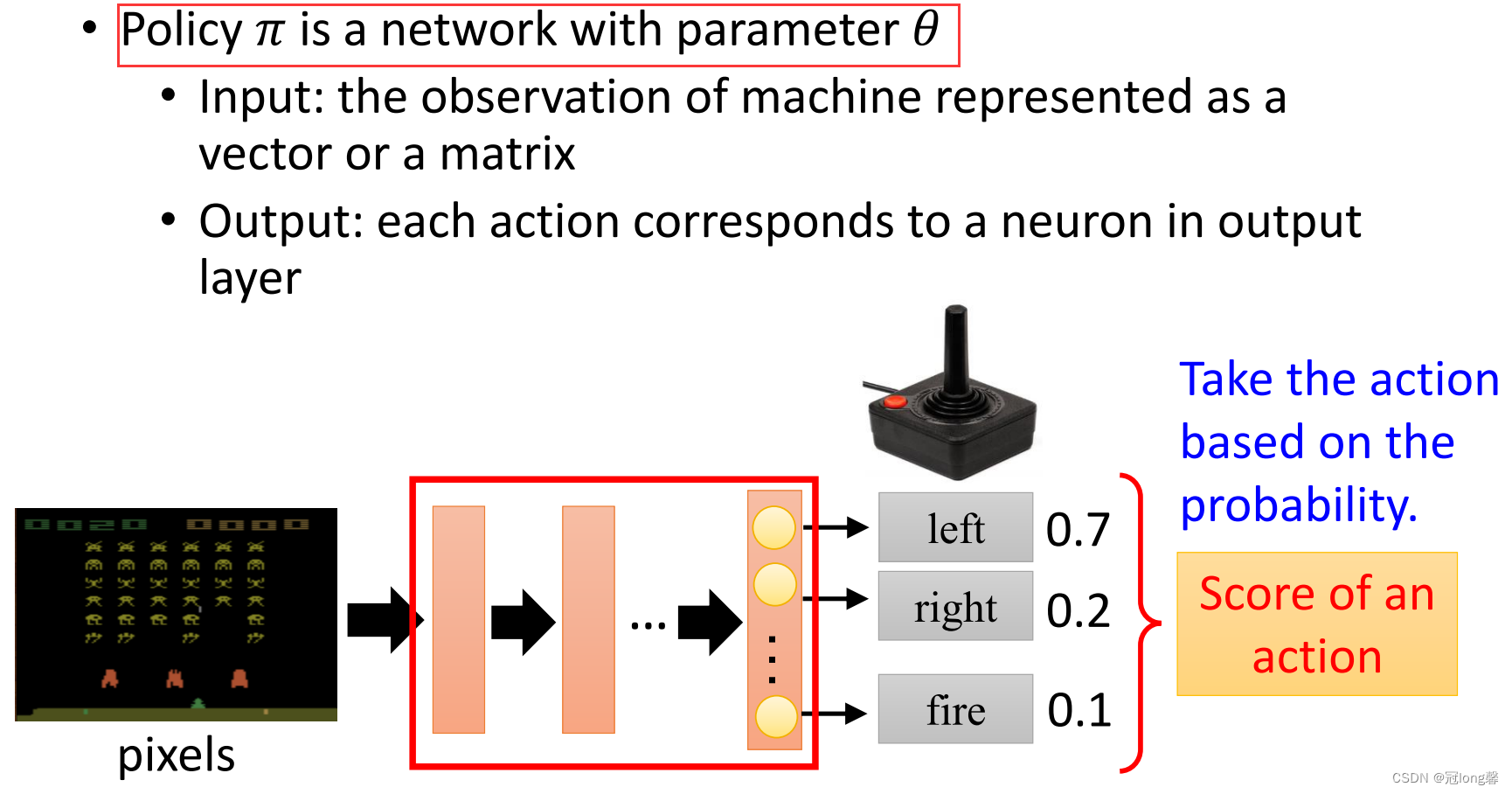
(2)Interaction Process
演员与环境的交互过程:将环境状态 s i s_i si输入到actor,策略网络输出动作 a i a_i ai。将动作 a i a_i ai输入到环境中可以获得奖励和下一状态 R i + 1 , s i + 1 R_{i+1},s_{i+1} Ri+1,si+1。一条完整的轨迹 τ \tau τ由有限个状态动作对组成。
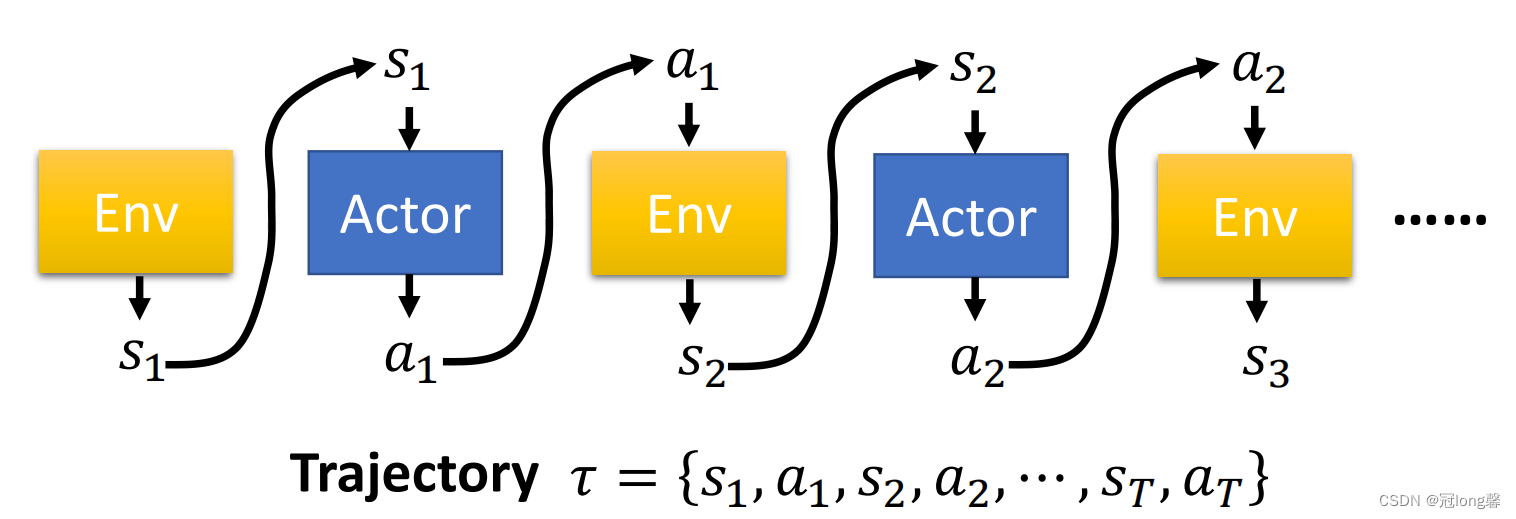
-
轨迹概率 p θ ( τ ) p_\theta(\tau) pθ(τ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











