







NIPS 2016:吴恩达表示,“在继深度学习之后,迁移学习将引领下一波机器学习技术。

大牛吴恩达曾经说过:做 AI 研究就像造宇宙飞船,除了充足的燃料之外,强劲的引擎也是必不可少的。假如燃料不足,则飞船就无法进入预定轨道。而引擎不够强劲,飞船甚至不能升空。类比于 AI,深度学习模型就好像引擎,海量的训练数据就好像燃料,这两者对于 AI 而言同样缺一不可。在训练深度神经网络、学习输入到输出的精准映射上,近年来大家做得越来越好。不管是针对图像、语句,还是标签预测,有了大量做过标记的样例,都已不再是难题。
但是!今天的深度学习算法仍然欠缺的,是在新情况(不同于训练集的情况)上的泛化能力和训练模型所必须的海量数据难以获取。
一、深度学习的局限性
在深度学习热火朝天,全民深度的时候说深度学习的坏话,而且对于那些没有看完本文的标题党,会不会打我。但是我还是要鼓足勇气说一下深度学习目前面临的困难:
-
表达能力的限制。因为一个模型毕竟是一种现实的反映,等于是现实的镜像,它能够描述现实的能力越强就越准确,而机器学习都是用变量来描述世界的,它的变量数是有限的,深度学习的深度也是有限的。另外它对数据的需求量随着模型的增大而增大,但现实中有那么多高质量数据的情况还不多。所以一方面是数据量,一方面是数据里面的变量、数据的复杂度,深度学习来描述数据的复杂度还不够复杂。
-
缺乏反馈机制。目前深度学习对图像识别、语音识别等问题来说是最好的,但是对其他的问题并不是最好的,特别是有延迟反馈的问题,例如机器人的行动,AlphaGo 下围棋也不是深度学习包打所有的,它还有强化学习的一部分,反馈是直到最后那一步才知道你的输赢。还有很多其他的学习任务都不一定是深度学习才能来完成的。
-
模型复杂度高。以下是一些当前比较流行的机器学习模型和其所需的数据量,可以看到随着模型复杂度的提高,其参数个数和所需的数据量也是惊人的。

OK,从上面的阐述,我们可以得出目前传统的机器学习方法(包括深度学习)三个待解决的关键问题:
-
随着模型复杂度的提高,参数个数惊人。
-
在新情况下模型泛化能力有待提高。
-
训练模型的海量的标记费时且昂贵。
-
表达能力有限且缺乏反馈机制。
迁移学习帮你搞定一切,让你的模型小而轻,还能举一反三!
二、到底什么是迁移学习?
"你永远不能理解一种语言——除非你至少理解两种语言"。
任何一个学过第二语言的人,对英国作家杰弗里·威廉斯的这句话应该都会"感同身受"。但为什么这样说呢?其原因在于学习使用外语的过程会不可避免地加深一个人对其母语的理解。事实上,歌德也发现这一理念的强大威力,以至于他不由自主地做出了一个与之类似但更为极端的断言:
"一个不会外语的人对其母语也一无所知"。
这种说法极为有趣,但令人惊讶的是恐怕更在于其实质——对某一项技能或心理机能的学习和精进能够对其他技能或心理机能产生积极影响——这种效应即为迁移学习。它不仅存在于人类智能,对机器智能同样如此。如今,迁移学习已成为机器学习的基础研究领域之一,且具有广泛的实际应用潜力。
一些人也许会很惊讶,计算机化的学习系统怎样能展现出迁移学习的能力。Google 通过一项涉及两套机器学习系统的实验来思考了这个问题,为了简单起见,我们将它们称为机器 A 和机器 B。机器 A 使用全新的 DNN,机器 B 则使用已经接受训练并能理解英语的 DNN。现在,假设我们用一组完全相同的普通话录音及对应文本来对机器 A 和 B 进行训练,大家觉得结果会怎样?令人称奇的是,机器 B(曾接受英语训练的机器)展现出比机器 A 更好的普通话技能,因为它之前接受的英语训练将相关能力迁移到了普通话理解任务中。
不仅如此,这项实验还有另一个令人更为惊叹的结果:机器 B 不仅普通话能力更高,它的英语理解能力也会提高!看来威廉斯和歌德确实说对了一点——学习第二语言确实能够加深对两种语言的理解,即使机器也不例外。
其实这就是计算机化的迁移学习。然而在我们身边,迁移学习的例子太多太多,一个精通吉他的人会比那些没有音乐基础的人能更快地学习钢琴;一个会打乒乓球的人比没有经验的人更容易接受网球;会骑自行车的人能更快学习骑电动车,等等,迁移学习就在你身边。
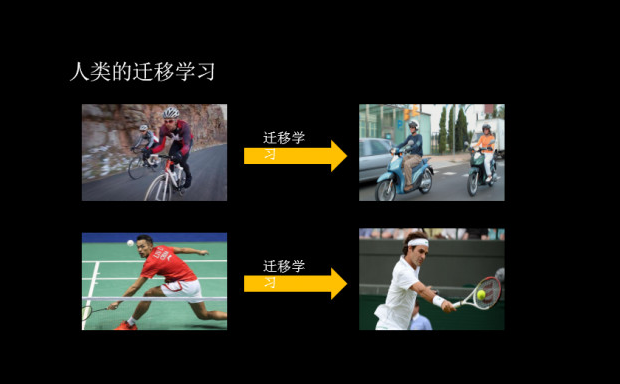
三、迁移学习和传统机器学习的差别
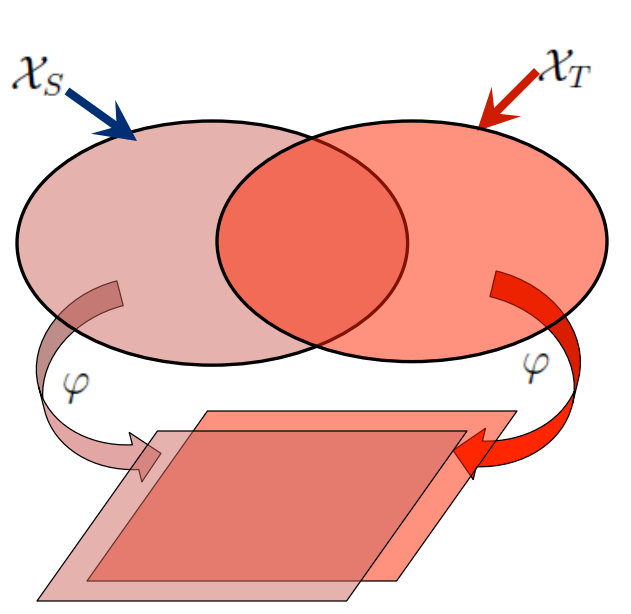
在机器学习的经典监督学习场景中,如果我们要针对一些任务和域 A 训练一个模型,我们会假设被提供了针对同一个域和任务的标签数据(也就是说训练集和测试集的数据必须是iid的,即独立同分布)。我们可以在下图中清楚地看到这一点,其中我们的模型 A 在训练数据和测试数据中的域和任务都是一样的(后面我会详细地定义什么是任务(task),以及什么是域(domain))。

现在我们可以在这个数据集上训练一个模型 A,并期望它在同一个任务和域中的未知数据上表现良好。在另一种情况下,当给定一些任务或域 B 的数据时,我们还需要可以用来训练模型 B 的有标签数据,这些数据要属于同一个任务和域,这样我们才能预期能在这个数据集上表现良好。
但是,现实往往很残酷,当我们没有足够的来自于我们关心的任务或域的标签数据来训练可靠的模型时(新的标签数据很难获取,或者很费时),传统的监督学习范式就支持不了了。
但传统的监督学习方法也会失灵——在缺乏某任务/领域标记数据的情况下,它往往无法得出一个可靠的模型。举个例子,如果我们想要训练出一个模型,对夜间的行人图像进行监测,我们可以应用一个相近领域的训练模型——白天的行人监测。理论上这是可行的。但实际上,模型的表现效果经常会大幅恶化,甚至崩溃。这很容易理解,模型从白天训练数据获取了一些偏差,不知道怎么泛化到新场景。
如果我们想要执行全新的任务,比如监测自行车骑手,重复使用原先的模型是行不通的。这里有一个很关键的原因:不同任务的数据标签不同。但是迁移学习就允许我们通过借用已经存在的一些相关的任务或域的标签数据来处理这些场景,充分利用相近任务/领域的现有数据我们尝试着把在源域中解决源任务时获得的知识存储下来,并将其应用在我们感兴趣的目标域中的目标任务上去,如下图所示。

四、迁移学习的概念、定义及分类
1.迁移学习的基本概念:域和任务,源和目标
一个域 D 由一个特征空间 X 和特征空间上的边际概率分布 P(X) 组成,其中 X=x1,…, xn∈X。对于有很多词袋表征(bag-of-words representation)的文档分类,X 是所有文档表征的空间,xi 是第 i 个单词的二进制特征,X 是一个特定的文档。对我来说,通俗的理解就是域 D 就是特征的空间及分布。
给定一个域 D=,一个任务 T 由一个标签空间 y 以及一个条件概率分布 P(Y|X)构成,这个条件概率分布通常是从由特征——标签对 xi∈X,yi∈Y 组成的训练数据中学习得到。在我们的文档分类的例子中,Y 是所有标签的集合(即真(True)或假(False)),yi 要么为真,要么为假。
源域 Ds,一个对应的源任务 Ts,还有目标域 Dt,以及目标任务 Tt,这个就很好理解了,源就是对应的我们的训练集,目标就是对应我们的测试集。
2.迁移学习的定义:
在 Ds≠Dt 和/或 Ts≠Tt 的情况下,让我们在具备来源于 Ds 和 Ts 的信息时,学习得到目标域 Dt 中的条件概率分布 P(Yt|Xt)。绝大多数情况下,假设可以获得的有标签的目标样本是有限的,有标签的目标样本远少于源样本。
3.迁移学习的分类:
-
XS≠XT,即源域和目标域的特征空间不同,举个例子,文档是用两种不同的语言写的。在自然语言处理的背景下,这通常被称为跨语言适应(cross-lingual adaptation),我们将这种情况称为异构迁移学习(Heterogeneous TL)。
-
XS=XT,即源域和目标域的特征空间相同,称为同构迁移学习(Homogenrous TL)
-
P(Xs)≠P(Xt),源域和目标域的边际概率分布不同,例如,两个文档有着不同的主题。这种情况通常被称为域适应(domain adaptation)。
-
P(Ys|Xs)≠P(Yt|Xt),源任务和目标任务的条件概率分布不同,例如,两个不同数据集的标签规则是不一样的。
-
YS≠YT,两个任务的标签空间不同,例如源域是二分类问题,目标域是 4 分类问题,因为不同的任务拥有不同的标签空间,但是拥有相同的条件概率分布,这是极其罕见的。
借用一张之前自己做的幻灯片:

4.迁移学习的四种常见解决方法:

四种方法分别为:基于样本的迁移学习、基于特征的迁移学习、基于参数/特征的迁移学习和基于关系的迁移学习。
(1) 基于样本的迁移学习

第一种为样本迁移,就是在数据集(源领域)中找到与目标领域相似的数据,把这个数据的权值进行调整,使得新的数据与目标领域的数据进行匹配(将分布变成相同)。样本迁移的特点是:1)需要对不同例子加权;2)需要用数据进行训练,上图的例子就是找到源领域的例子 3,然后加重该样本的权值,使得在预测目标领域时的比重加大。
(2) 基于特征的迁移学习

第二种为特征迁移,就是通过观察源领域图像与目标域图像之间的共同特征,然后利用观察所得的共同特征在不同层级的特征间进行自动迁移,上图左侧的例子就是找当两种狗在不同层级上的共同特征,然后进行预测。
(3) 基于参数/模型的迁移学习

第三种为模型迁移,其原理时利用上千万的狗狗图象训练一个识别系统,当我们遇到一个新的狗狗图象领域,就不用再去找几千万个图象来训练了,可以原来的图像识别系统迁移到新的领域,所以在新的领域只用几万张图片同样能够获取相同的效果。模型迁移的一个好处是我们可以区分,就是可以和深度学习结合起来,我们可以区分不同层次可迁移的度,相似度比较高的那些层次他们被迁移的可能性就大一些。
(4) 基于关系的迁移学习

这种关系的迁移,我研究的较少,定义说明是可以将两个相关域之间的相关性知识建立一个映射,例如源域有皇帝、皇后,那么就可以对目标域的男和女之间建立这种关系,一般用在社会网络,社交网络之间的迁移上比较多。
五、迁移学习到底可以解决哪些问题
迁移学习主要可以解决两大类问题:小数据问题和个性化问题。
小数据问题:比方说我们新开一个网店,卖一种新的糕点,我们没有任何的数据,就无法建立模型对用户进行推荐。但用户买一个东西会反应到用户可能还会买另外一个东西,所以如果知道用户在另外一个领域,比方说卖饮料,已经有了很多很多的数据,利用这些数据建一个模型,结合用户买饮料的习惯和买糕点的习惯的关联,我们就可以把饮料的推荐模型给成功地迁移到糕点的领域,这样,在数据不多的情况下可以成功推荐一些用户可能喜欢的糕点。这个例子就说明,我们有两个领域,一个领域已经有很多的数据,能成功地建一个模型,有一个领域数据不多,但是和前面那个领域是关联的,就可以把那个模型给迁移过来。
个性化问题:比如我们每个人都希望自己的手机能够记住一些习惯,这样不用每次都去设定它,我们怎么才能让手机记住这一点呢?其实可以通过迁移学习把一个通用的用户使用手机的模型迁移到个性化的数据上面。我想这种情况以后会越来越多。
六、迁移学习的应用
1. 我到底是什么颜色?

大家一看这幅图就知道,这里以此前网上流行的一个连衣裙图片为例。如图所示,如果你想通过深度学习判断这条裙子到底是蓝黑条纹还是白金条纹,那就必须收集大量的包含蓝黑条纹或者白金条纹的裙子的图像数据。参考上文提到的问题规模和参数规模之间的对应关系,建立这样一个精准的图像识别模型至少需要 140M 个参数,1.2M 张相关的图像训练数据,这几乎是一个不可能完成的任务。
现在引入迁移学习,用如下公式可以得到在迁移学习中这个模型所需的参数个数:
No. of parameters = [Size(inputs) 1] [Size(outputs) 1] = [2048 1][1 1]~ 4098parameters
可以看到,通过迁移学习的引入,针对同一个问题的参数个数从**140M 减少到了 4098**,减少了 10 的 5 次方个数量级!这样的对参数和训练数据的消减程度是惊人的。
这里给大家介绍一个迁移学习的工具 NanoNets,它是一个简单方便的基于云端实现的迁移学习工具,其内部包含了一组已经实现好的预训练模型,每个模型有数百万个训练好的参数。用户可以自己上传或通过网络搜索得到数据,NanoNets 将自动根据待解问题选择最佳的预训练模型,并根据该模型建立一个 NanoNets(纳米网络),并将之适配到用户的数据。以上文提到的蓝黑条纹还是白金条纹的连衣裙为例,用户只需要选择待分类的名称,然后自己上传或者网络搜索训练数据,之后 NanoNets 就会自动适配预训练模型,并生成用于测试的 web 页面和用于进一步开发的 API 接口。如下所示,图中为系统根据一张连衣裙图片给出的分析结果。具体使用方法详见 NanoNets 官网:http://nanonets.ai/ 。

2. Deepmind 的作品 progressive neural network(机器人)
Google 的 Deepmind 向来是大家关注的热点,就在去年,其将三个小游戏 Pong, Labyrinth, Atari 通过将已学其一的游戏的 parameter 通过一个 lateral connection feed 到一个新游戏。外墙的可以看 youtub 的视频:https://www.youtube.com/watch?v=aWAP_CWEtSI,与此同时,DeepMind 最新的成果 Progressive Neural Networks终于伸向真正的机器人了!

它做了什么事情呢?就是在仿真环境中训练一个机械臂移动,然后训练好之后,可以把知识迁移到真实的机械臂上,真实的机械臂稍加训练也可以做到和仿真一样的效果!视频在这:https://www.youtube.com/watch?v=YZz5Io_ipi8
3. 舆情分析

迁移学习也可应用在舆情分析中,如用户评价方面。以电子产品和视频游戏留言为例,上图中绿色为好评标签,而红色为差评标签。我们可以从上图左侧的电子产品评价中找到特征,促使它在这个领域(电子产品评价)建立模型,然后利用模型把其迁移到视频游戏中。这里可以看到,舆情也可以进行大规模的迁移,而且在新的领域不需要标签。
4. 个性化对话

训练一个通用型的对话系统,该系统可能是闲聊型,也可能是一个任务型的。但是,我们可以根据在特定领域的小数据修正它,使得这个对话系统适应不同任务。比如,一个用户想买咖啡,他并不想回答所有繁琐的问题,例如是要大杯小杯,热的冷的?
5. 基于迁移学习的推荐系统

在线推荐系统中利用迁移学习,可以在某个领域做好一个推荐系统,然后应用在稀疏的、新的垂直领域。(影像资料——>书籍资料)
6. 迁移学习在股票中的预测
香港科技大学杨强教授的学生就把迁移学习应用到大家公认的很难的领域中——预测股市走势。下图所示为 A 股里面的某个股票,用过去十年的数据训练该模型。首先,运用数据之间的连接,产生不同的状态,让各个状态之间能够互相迁移。其次,不同状态之间将发生变化,他们用了一个强化学习器模拟这种变化。最后,他们发现深度学习的隐含层里面会自动产生几百个状态,基本就能够对这十年来的经济状况做出一个很完善的总结。
杨强教授也表示,这个例子只是在金融领域的一个小小的试验。不过,一旦我们对一个领域有了透彻的了解,并掌握更多的高质量数据,就可以将人工智能技术迁移到这个领域来,在应用过程中对所遇到的问题作清晰的定义,最终能够实现通用型人工智能的目的。

迁移学习的应用越来越广泛,这里仅仅介绍了冰山一角,例如生物基因检测、异常检测、疾病预测、图像识别等等。
七、风头正劲的迁移学习

当今全世界都在推动迁移学习,当今 AAAI 中大概有 20 多篇迁移学习相关文章,而往年只有五六篇。与此同时,如吴恩达等深度学习代表人物也开始做迁移学习。正如吴恩达在 NIPS 2016 讲座上画了一副草图,大致的意思如下图所示:

有一点是毋庸置疑的:迄今为止,机器学习在业界的应用和成功,主要由监督学习推动。而这又是建立在深度学习的进步、更强大的计算设施、做了标记的大型数据集的基础上。近年来,这一波公众对 人工智能技术的关注、投资收购浪潮、机器学习在日常生活中的商业应用,主要是由监督学习来引领。但是,该图在吴恩达眼中是推动机器学习取得商业化成绩的主要驱动技术,而且从中可以看出,吴恩达认为下一步将是迁移学习的商业应用大爆发。
最后,借鉴香港科技大学计算机与工程系主任,全球第一位华人 AAAI Fellow 杨强教授在 2016 年底腾讯暨 KDD China 大数据峰会上的一页胶片来作为结束。

昨天我们在深度学习上有着很高成就。但我们发现深度学习在有即时反馈的领域和应用方向有着一定的优势,但在其他领域则不行。打个比方:就像我在今天讲个笑话,你第二天才能笑得出来,在今天要解决这种反馈的时延问题需要强化学习来做。而在明天,则有更多的地方需要迁移学习:它会让机器学习在这些非常珍贵的大数据和小数据上的能力全部释放出来。做到举一反三,融会贯通。
打个小广告,由于自己本人希望在迁移学习方向上长期研究和学习,因此申请了一个"迁移学习"的公众号,每周会推送迁移学习的技术和学术干货,同时对自己也是一种监督,也希望在学习和分享的过程中遇到同路人,共同交流和进步,请大家多多支持。















 4147
4147

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









