




 本文探讨了深度学习模型Inception-V4及其与残差结构的结合,展示了在图像识别任务中如何通过优化网络结构提升训练效率与模型性能。实验表明,残差连接能显著加速Inception网络的训练,而合理增大网络宽度可进一步提高模型的表达能力。
本文探讨了深度学习模型Inception-V4及其与残差结构的结合,展示了在图像识别任务中如何通过优化网络结构提升训练效率与模型性能。实验表明,残差连接能显著加速Inception网络的训练,而合理增大网络宽度可进一步提高模型的表达能力。
本文翻译论文为深度学习经典模型之一:Inception-V4
论文链接:https://arxiv.org/pdf/1602.07261.pdf
摘要:近些年,超深度卷积网络成为图像识别领域的核心算法。其中,Inception结构在图像分类中表现优秀,并且计算代价很低。最近,残差与更加传统的结构相结合,在ILSVRC挑战中获得Start-of-art的结果(与Inception-v3)的分类精度差不多。那么,是不是结合残差连接与Inception结构能够产生更好的结果。因此,我们给出了充足的实验证据,残差连接使得Inception网络训练速度得到巨大的提升。论文给出了几种新的主流网络结构(residual and non-residual Inception networks)。我们进一步阐明,在保证宽Residual Inception网络的稳定性训练前提下,如何合理的增大每一层的激活值。三个Residual+1个Inception-v4获得3.05%的top-5误差。
1、Introduction
2012年ImageNet的冠军获得者-Krizhevsky,他们提出的网络 "AlexNet" 被成功的应用于各个视觉领域,比如目标检测,分割,人体姿态估计,视频分类,目标跟踪以及超分辨率。
本文中,我们研究如何结合最近的两种卷积网络思想:残差连接(residual connections)和Inception-v3。ResNet的作者认为残差连接是训练超深度卷积网络必不可少的条件。由于Inception网络非常深,很自然的,我们让Inception与residual结合。不仅能够获得residual思想的好处,也能保证Inception的计算效率。
除了直接将Residual融合,我们也研究:当Inception变得更深、更宽的情况下,是不是能够保证其效率。出于这个目的,我们设计新版本的结构-Inception-v4,它具有更加统一、简化的结构,以及更多的Inception模块(相比于Inception-v3)。Inception-v3继承了早期网络设计的诸多优点,主要的限制是如何进行分布式训练。但是,当TensorFlow出现后,那些不足不再存在。简化机构间(Section3)。
本文中,我们比较了两种Inception网络,Inception-v3和Inception-v4,它们的计算复杂度与Inception-ResNet类似。这些模型的设计的基本假设:相比于non-residual的模型,其参数和复杂度不能增加。事实上,我们测试过更大、更宽的Inception-ResNet变体,在ImageNet上的表现差不多。
本文集合了多个优秀模型,得到最优的结果。实验表明,Inception-v4和Inception-ResNet-v2表现差不多。我们着重研究:怎样结合二者的设计思想,进而得到更加优秀的模型。本文最后的部分,我们研究了一些分类失败,总结出模型的集合并没有处理好标注噪声,因此模型仍有提升的空间。
2、Related Work
自从AlexNet提出之后,卷积网络在图像识别领域越来越流行。之后一些重要的里程碑模型,比如VGG,Network-in-network,GoogLeNet。
He et al 提出了残差连接思想,并给出了强有力的理论依据以及实验(在图像识别,特别是目标检测,残差连接具有更强的信息融合能力)。作者认为,残差连接是训练超深神经网络的必要条件。但是,我们的研究并不是特别支持这个观点(至少在图像识别领域)。或许,我们需要更多的深度网络训练实验,才能更好地理解残差连接真正的优势。实验表明,没有残差连接的神经网络,训练并不是那么难。但是,残差连接可以很大程度上提升训练速度,这一点是毋庸置疑的。
3、Architectural Choices
3.1、Pure Inception blocks
出于模型占用内存的考虑,早期的Inception模型采用分段训练的模式。但是,Inception结构是可以微调的,意味着可以更改很多层的卷积核的个数,并且不会影响整体的性能。为了优化训练速度,以及平衡不同子网络之间的计算效率,我们很小心的微调层的大小。作为对比,当引入TensorFlow后,不需要分割模型进行训练。同时,也优化了内存的使用:比如,反向传播中,考虑到哪些需要计算,哪些不需要等等。
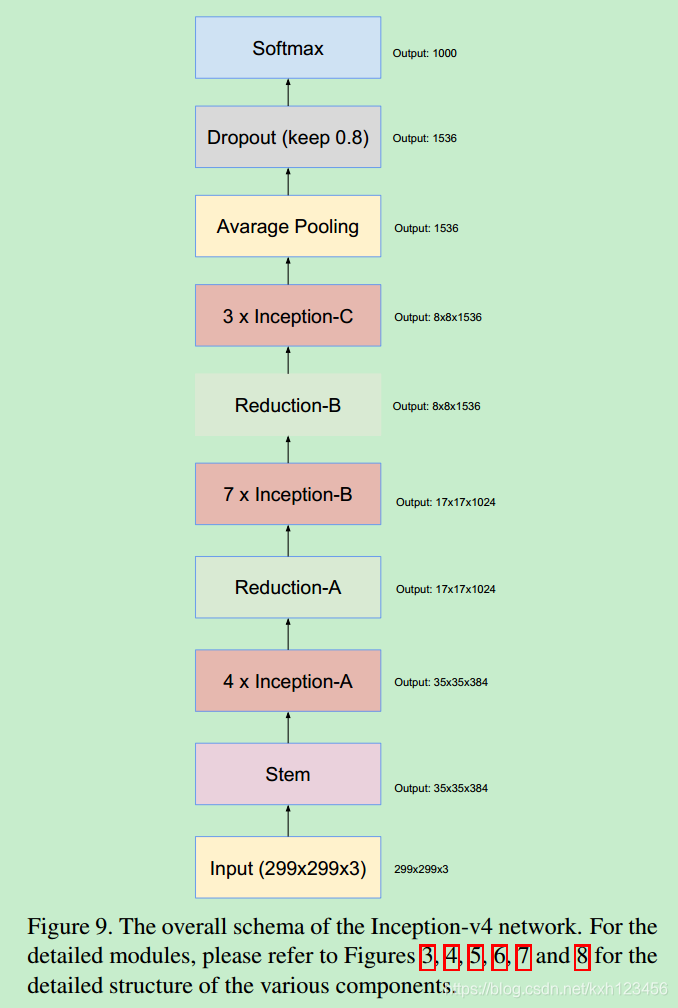
历史上讲,在更改网络结构上,我们相对的保守,并且,在实验中,我们独立的限制网络的模块(保证其它的网络部分稳定)。这也导致网络很复杂,难以修改。在我们最新的实验中(Inception-v4),我们简化了模块的设计,去除不必要的集成,对每一个Inception模块进行统一的设计。图9给出了Inception-v4的结构,图3,4,5,6,7,8是每个模块的详细结构。所有卷积中(没有标记为V)意味着填充方式为"SAME Padding",输入和输出维度一致。标记为V的卷积中,使用"VALID Padding",输出维度视具体情况而定。
3.2、Residual Inception Blocks
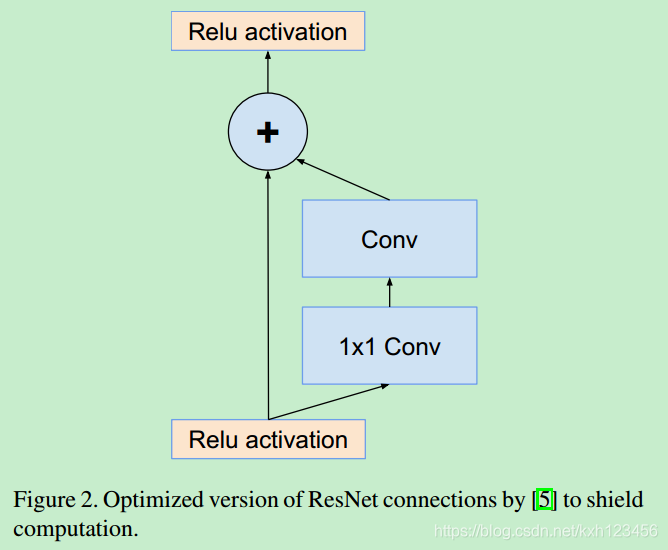
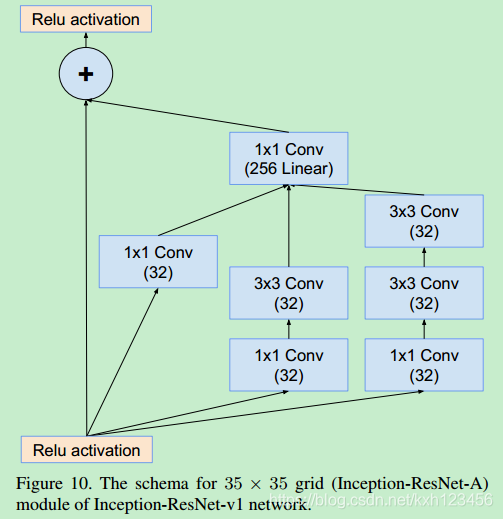
对于残差版本的Inception网络,我们使用更加低廉的Inception blocks。每一个Inception block都会添加卷积核扩展层(1x1卷积,没有激活层),在与输入执行相加之前,增大卷积核个数(宽度)。相当于是对Inception block降低维度的弥补。
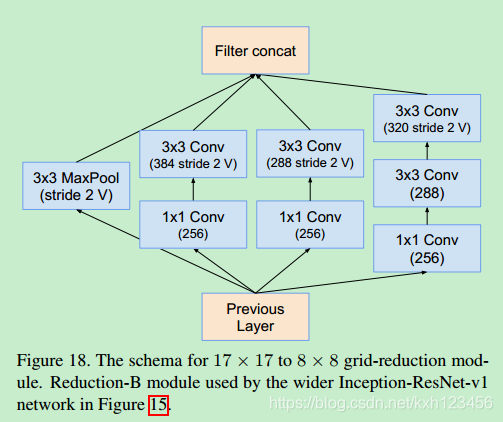
我们尝试过不同版本的ResNet-Inception,只详细介绍其中的两种。第一种:"Inception-ResNet-V1",计算效率与Inception-v3类似;第二种:"Inception-ResNet-V2",计算效率与Inception-v4类似。图15给出了上述网络的大致结构。
Residual and non-residual Inception的另一个微小的差别是:在Inception-ResNet网络中,我们只在传统层(traditional layers)使用BN,不在求和层(summations layers)使用BN。通常认为,所有层使用BN是有必要的,但是我们希望模型能够在单个GPU上训练。实验证明,增大层的宽度对于GPU内存的消耗是不成比例的。通过在网络顶层去掉BN层,我们大幅度提高Inception模块的数量。
3.3、Scaling of the Residuals
我们发现,如果卷积核数量突破1000,残差的各种变体开始变得不稳定,网络在更早的死亡,意味着,在训练几万步之后,平均池化前面的几层网络出现零值。即使使用低的学习率或者BN,也无法避免这种情况的出现。
我们发现,在与前一层激活层求和时,缩小残差有助于稳定训练过程。一般我们会选择固定的缩放因子,见图20:
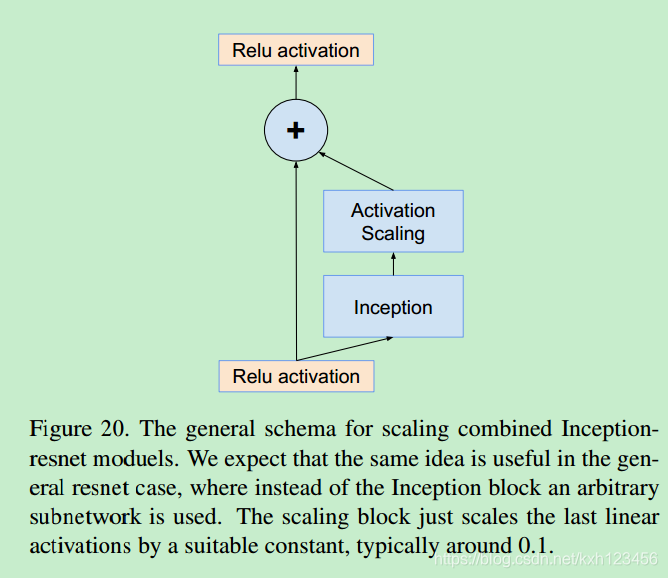
He 同样发现了超深度网络训练训练不稳定性,为此他们使用了两阶段训练方式:使用小的学习率,进行预热训练(warm-up),当误差降低到一定程度后,增大学习率。但是,我们发现如果卷积核个数太多,那么即使很小的学习率(比如0.00001)也无法解决。最好的方式是缩小残差。尽管缩放并不是严格的必要,但是没有损害最终的精度,并且稳定了训练过程。
4、Training Methodology
优化器:RMSProp,decay为0.9;
学习率:0.045,每两轮指数衰减(0.94);
5、Experiments Results
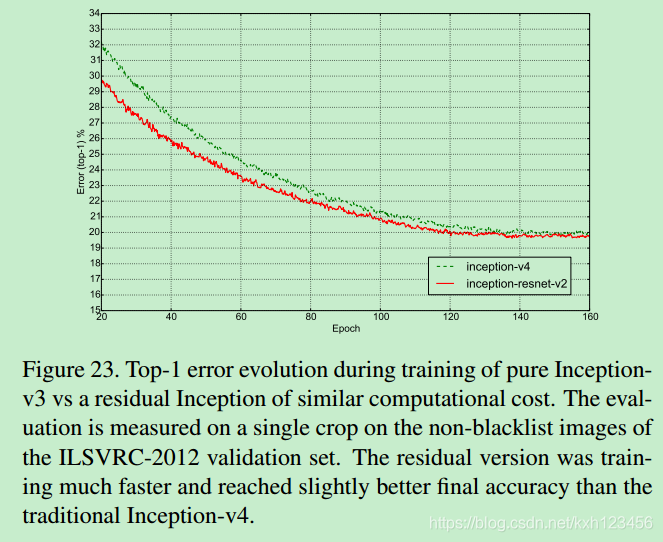
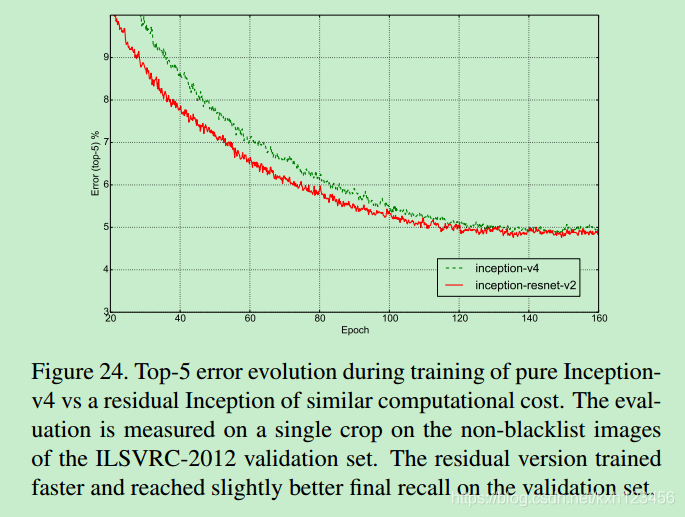
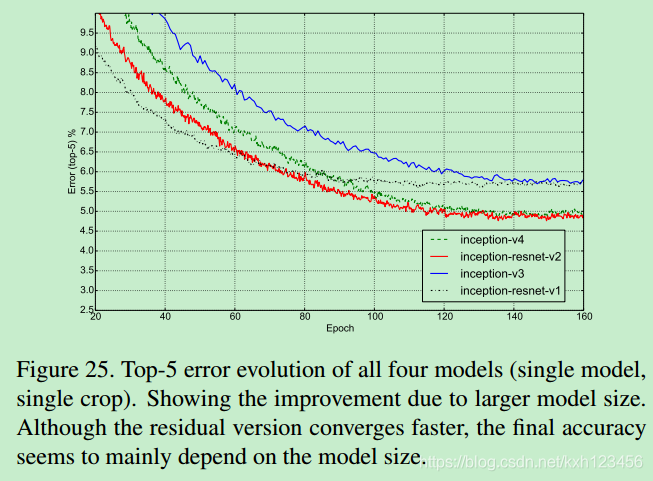
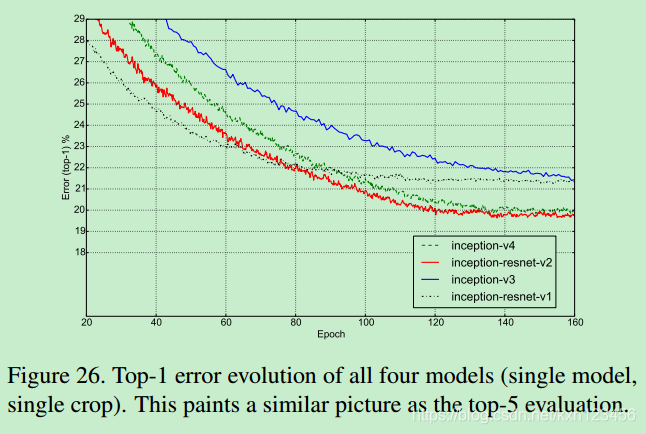
6、网络结构
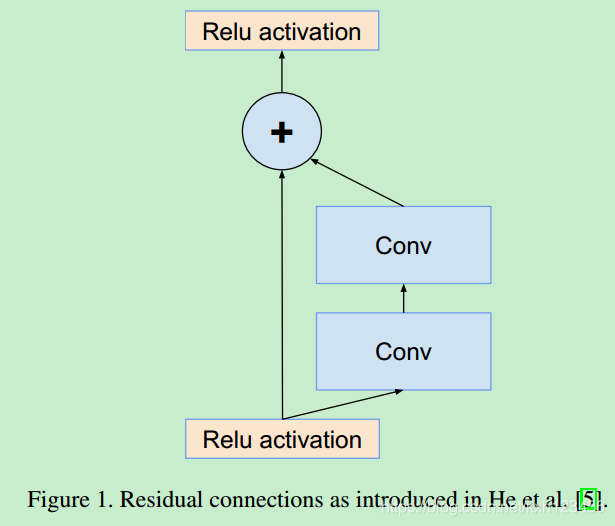
残差模块:图1和图2
Inception-v4:各个模型的详细结构,图3,4,5,6,7,8
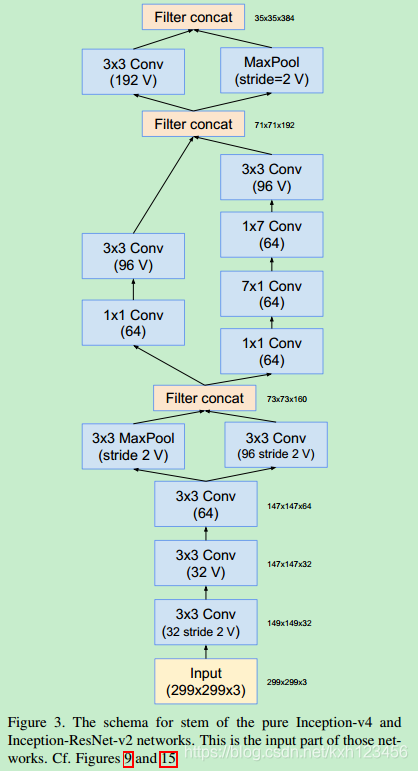
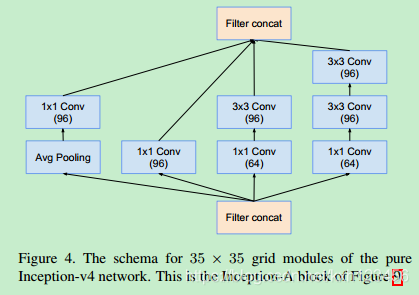
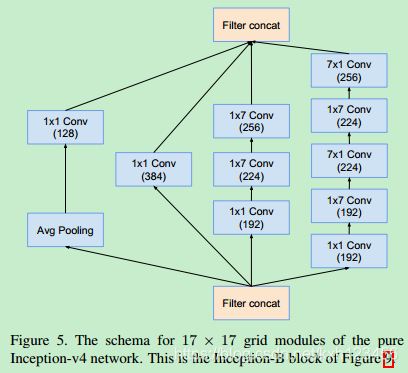
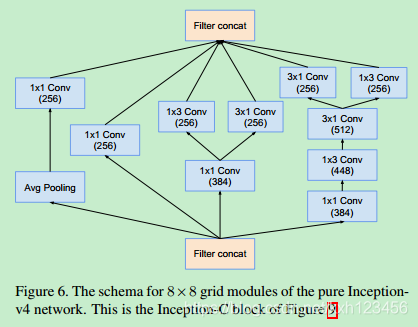
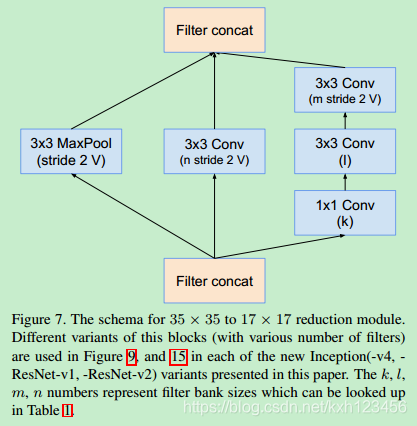
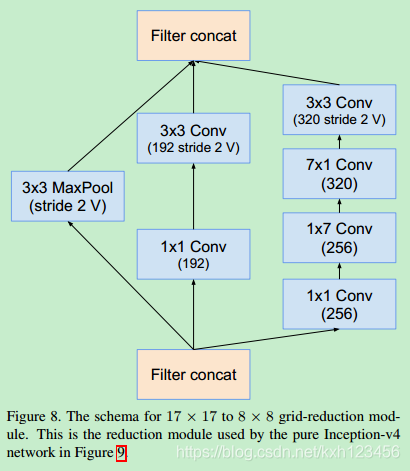
Inception-ResNet-V1:各个模块的详细结构,图14,10,7,11,12,13
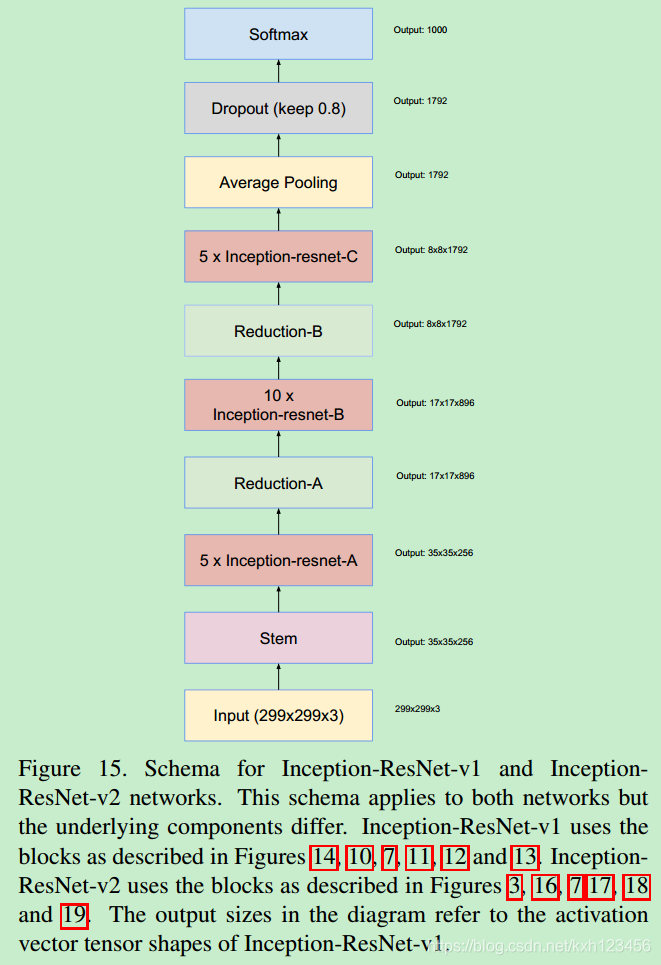

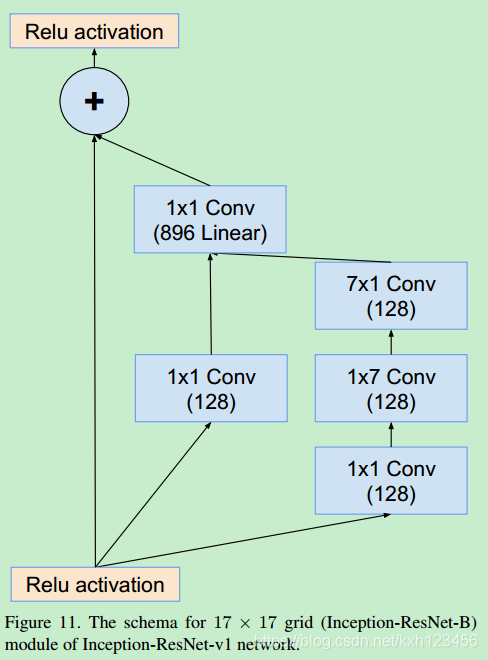
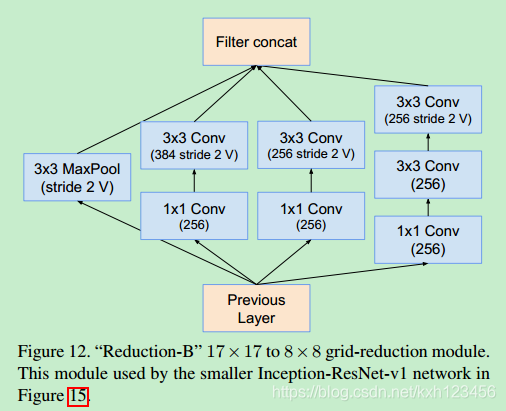
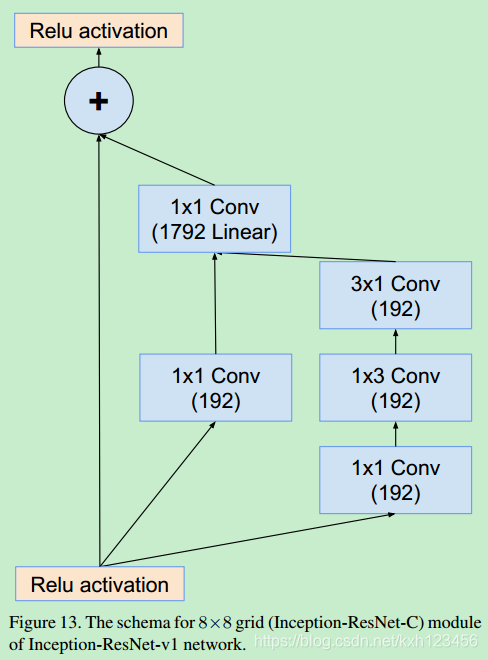
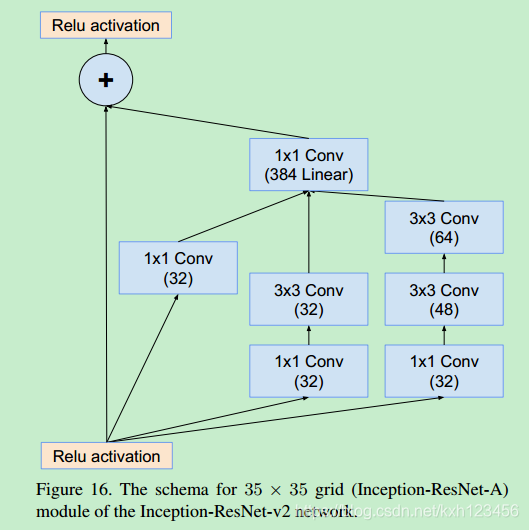
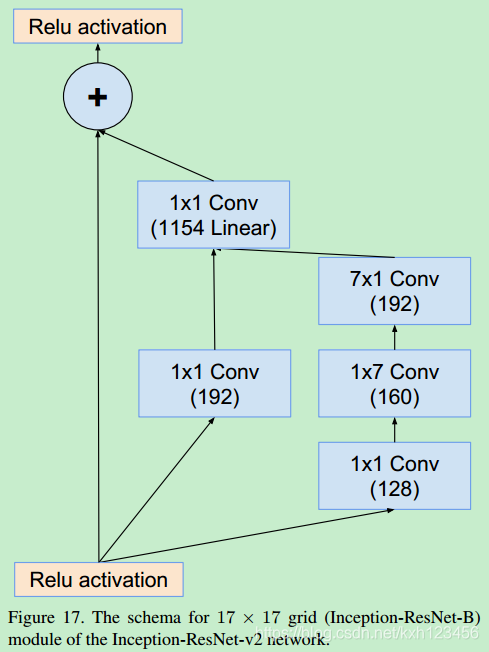
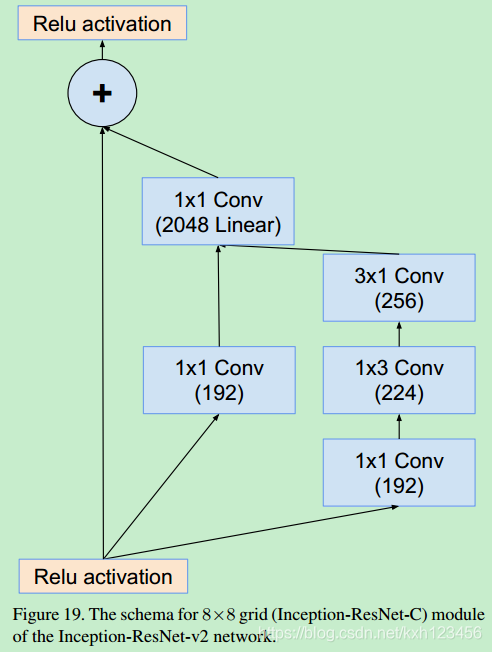
Inception-ResNet-V2: 各个模块的详细结构,图3,16,7,17,18,19


















 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









