







咱先讲下梯度下降,然后对应caffe里的代码。
还是老样子,贴一个网址,人家讲softmax讲的挺好的。
http://www.bubuko.com/infodetail-601263.html
总的来说,梯度下降主要分为一下几部分:
1.先求假设函数;
2.再求代价函数,又叫损失函数;
3.对代价函数求导,最小化;
4.更新,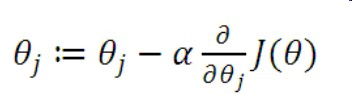
我经常会出现一种问题,就是算法看完了,没过多久就忘了,下次还得再看,对这个问题,我的方法就是看代码,把代码看熟悉了,也就记住了。
下面讲代码
**softmax_loss_layer.cpp**
主要看他的forward和backword
template <typename Dtype>
void SoftmaxWithLossLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
// The forward pass computes the softmax prob values.
//打印了此时的 层参数 见附1
softmax_layer_->Forward(softmax_bottom_vec_, softmax_top_vec_);
/* softmax_loss_layer.cpp里LayerSetUp() 函数对上边两个参数进行了定义
softmax_bottom_vec_.push_back(bottom[0]);
softmax_top_vec_.clear();
softmax_top_vec_.push_back(&prob_);
softmax_layer_->SetUp(softmax_bottom_vec_, softmax_top_vec_);*/
这里Forward调用了softmax_layer.cpp的Forward_cpu()函数,求出假设函数 h(x)见附2
/*
(gdb) p *top[0]
$11 = {data_ = {px = 0x7790a0, pn = {pi_ = 0x7790f0}}, diff_ = {px = 0x77b220,
pn = {pi_ = 0x7797b0}}, shape_data_ = {px = 0x778ad0, pn = {
pi_ = 0x779110}}, shape_ = std::vector of length 0, capacity 0,
count_ = 1, capacity_ = 1}
(gdb) p *bottom[0]
$12 = {data_ = {px = 0x777e30, pn = {pi_ = 0x772bb0}}, diff_ = {px = 0x7786c0,
pn = {pi_ = 0x7786f0}}, shape_data_ = {px = 0x778600, pn = {
pi_ = 0x778630}}, shape_ = std::vector of length 2, capacity 2 = {100,
10}, count_ = 1000, capacity_ = 1000}
(gdb) p *softmax_bottom_vec_[0]
$7 = {data_ = {px = 0x777e30, pn = {pi_ = 0x772bb0}}, diff_ = {px = 0x7786c0,
pn = {pi_ = 0x7786f0}}, shape_data_ = {px = 0x778600, pn = {
pi_ = 0x778630}}, shape_ = std::vector of length 2, capacity 2 = {100,
10}, count_ = 1000, capacity_ = 1000}
(gdb) p *softmax_top_vec_[0]
$8 = {data_ = {px = 0x779f00, pn = {pi_ = 0x779f30}}, diff_ = {px = 0x779f50,
pn = {pi_ = 0x779f80}}, shape_data_ = {px = 0x779e90, pn = {
pi_ = 0x779ec0}}, shape_ = std::vector of length 2, capacity 2 = {100,
10}, count_ = 1000, capacity_ = 1000}
你可以发现 bottom和softmax_bottom_vec_所指向的地址是相同的
*/
const Dtype* prob_data = prob_.cpu_data();
const Dtype* label = bottom[1]->cpu_data();
int dim = prob_.count() / outer_num_;
int count = 0;
Dtype loss = 0;
//针对每一张图像
for (int i = 0; i < outer_num_; ++i) {
for (int j = 0; j < inner_num_; j++) {
const int label_value = static_cast<int>(label[i * inner_num_ + j]);
if (has_ignore_label_ && label_value == ignore_label_) {
continue;
}
DCHECK_GE(label_value, 0);
DCHECK_LT(label_value, prob_.shape(softmax_axis_));
//prob_.shape(softmax_axis_)= 10
/// prob stores the output probability predictions from the SoftmaxLayer.
//Blob<Dtype> prob_;
loss -= log(std::max(prob_data[i * dim + label_value * inner_num_ + j],
Dtype(FLT_MIN)));
++count;
}
}
top[0]->mutable_cpu_data()[0] = loss / get_normalizer(normalization_, count);
//求代价函数也就是这个公式
if (top.size() == 2) {
top[1]->ShareData(prob_);
}
}
附1
p *this
$2 = {<caffe::LossLayer<float>> = {<caffe::Layer<float>> = {
_vptr.Layer = 0x7ffff7dbf130 <vtable for caffe::SoftmaxWithLossLayer<float>+16>, layer_param_ = {<google::protobuf::Message> = {<No data fields>},
static kNameFieldNumber = 1, static kTypeFieldNumber = 2,
static kBottomFieldNumber = 3, static kTopFieldNumber = 4,
static kPhaseFieldNumber = 10, static kLossWeightFieldNumber = 5,
static kParamFieldNumber = 6, static kBlobsFieldNumber = 7,
static kPropagateDownFieldNumber = 11, static kIncludeFieldNumber = 8,
static kExcludeFieldNumber = 9,
static kTransformParamFieldNumber = 100,
static kLossParamFieldNumber = 101,
static kAccuracyParamFieldNumber = 102,
static kArgmaxParamFieldNumber = 103,
static kBatchNormParamFieldNumber = 139,
static kBiasParamFieldNumber = 141,
static kConcatParamFieldNumber = 104,
static kContrastiveLossParamFieldNumber = 105,
static kConvolutionParamFieldNumber = 106,
static kCropParamFieldNumber = 144,
static kDataParamFieldNumber = 107,
static kDropoutParamFieldNumber = 108,
static kDummyDataParamFieldNumber = 109,
static kEltwiseParamFieldNumber = 110,
---Type <return> to continue, or q <return> to quit---
static kEluParamFieldNumber = 140,
static kEmbedParamFieldNumber = 137,
static kExpParamFieldNumber = 111,
static kFlattenParamFieldNumber = 135,
static kHdf5DataParamFieldNumber = 112,
static kHdf5OutputParamFieldNumber = 113,
static kHingeLossParamFieldNumber = 114,
static kImageDataParamFieldNumber = 115,
static kInfogainLossParamFieldNumber = 116,
static kInnerProductParamFieldNumber = 117,
static kInputParamFieldNumber = 143,
static kLogParamFieldNumber = 134, static kLrnParamFieldNumber = 118,
static kMemoryDataParamFieldNumber = 119,
static kMvnParamFieldNumber = 120,
static kPoolingParamFieldNumber = 121,
static kPowerParamFieldNumber = 122,
static kPreluParamFieldNumber = 131,
static kPythonParamFieldNumber = 130,
static kReductionParamFieldNumber = 136,
static kReluParamFieldNumber = 123,
static kReshapeParamFieldNumber = 133,
static kScaleParamFieldNumber = 142,
static kSigmoidParamFieldNumber = 124,
---Type <return> to continue, or q <return> to quit---
static kSoftmaxParamFieldNumber = 125,
static kSppParamFieldNumber = 132,
static kSliceParamFieldNumber = 126,
static kTanhParamFieldNumber = 127,
static kThresholdParamFieldNumber = 128,
static kTileParamFieldNumber = 138,
static kWindowDataParamFieldNumber = 129, _unknown_fields_ = {
fields_ = 0x0}, name_ = 0x778fe0, type_ = 0x779000,
bottom_ = {<google::protobuf::internal::RepeatedPtrFieldBase> = {
static kInitialSize = 0, elements_ = 0x779240, current_size_ = 2,
allocated_size_ = 2, total_size_ = 4}, <No data fields>},
top_ = {<google::protobuf::internal::RepeatedPtrFieldBase> = {
static kInitialSize = 0, elements_ = 0x778f90, current_size_ = 1,
allocated_size_ = 1, total_size_ = 4}, <No data fields>},
loss_weight_ = {static kInitialSize = <optimized out>,
elements_ = 0x779060, current_size_ = 1, total_size_ = 4},
param_ = {<google::protobuf::internal::RepeatedPtrFieldBase> = {
static kInitialSize = 0, elements_ = 0x0, current_size_ = 0,
allocated_size_ = 0, total_size_ = 0}, <No data fields>},
blobs_ = {<google::protobuf::internal::RepeatedPtrFieldBase> = {
static kInitialSize = 0, elements_ = 0x0, current_size_ = 0,
allocated_size_ = 0, total_size_ = 0}, <No data fields>},
propagate_down_ = {static kInitialSize = <optimized out>,
---Type <return> to continue, or q <return> to quit---
elements_ = 0x0, current_size_ = 0, total_size_ = 0},
include_ = {<google::protobuf::internal::RepeatedPtrFieldBase> = {
static kInitialSize = 0, elements_ = 0x0, current_size_ = 0,
allocated_size_ = 0, total_size_ = 0}, <No data fields>},
exclude_ = {<google::protobuf::internal::RepeatedPtrFieldBase> = {
static kInitialSize = 0, elements_ = 0x0, current_size_ = 0,
allocated_size_ = 0, total_size_ = 0}, <No data fields>},
transform_param_ = 0x0, loss_param_ = 0x0, accuracy_param_ = 0x0,
argmax_param_ = 0x0, batch_norm_param_ = 0x0, bias_param_ = 0x0,
concat_param_ = 0x0, contrastive_loss_param_ = 0x0,
convolution_param_ = 0x0, crop_param_ = 0x0, data_param_ = 0x0,
dropout_param_ = 0x0, dummy_data_param_ = 0x0, eltwise_param_ = 0x0,
elu_param_ = 0x0, embed_param_ = 0x0, exp_param_ = 0x0,
flatten_param_ = 0x0, hdf5_data_param_ = 0x0,
hdf5_output_param_ = 0x0, hinge_loss_param_ = 0x0,
image_data_param_ = 0x0, infogain_loss_param_ = 0x0,
inner_product_param_ = 0x0, input_param_ = 0x0, log_param_ = 0x0,
lrn_param_ = 0x0, memory_data_param_ = 0x0, mvn_param_ = 0x0,
pooling_param_ = 0x0, power_param_ = 0x0, prelu_param_ = 0x0,
python_param_ = 0x0, reduction_param_ = 0x0, relu_param_ = 0x0,
reshape_param_ = 0x0, scale_param_ = 0x0, sigmoid_param_ = 0x0,
softmax_param_ = 0x0, spp_param_ = 0x0, slice_param_ = 0x0,
tanh_param_ = 0x0, threshold_param_ = 0x0, tile_param_ = 0x0,
---Type <return> to continue, or q <return> to quit---
window_data_param_ = 0x0, phase_ = 1, _cached_size_ = 0, _has_bits_ = {
19, 0}, static default_instance_ = 0x6c3230}, phase_ = caffe::TEST,
blobs_ = std::vector of length 0, capacity 0,
param_propagate_down_ = std::vector<bool> of length 0, capacity 0,
loss_ = std::vector of length 1, capacity 1 = {1}, is_shared_ = false,
forward_mutex_ = {px = 0x74d670, pn = {
pi_ = 0x779130}}}, <No data fields>}, softmax_layer_ = {
px = 0x779ad0, pn = {pi_ = 0x779960}}, prob_ = {data_ = {px = 0x779f00,
pn = {pi_ = 0x779f30}}, diff_ = {px = 0x779f50, pn = {pi_ = 0x779f80}},
shape_data_ = {px = 0x779e90, pn = {pi_ = 0x779ec0}},
shape_ = std::vector of length 2, capacity 2 = {100, 10}, count_ = 1000,
capacity_ = 1000},
softmax_bottom_vec_ = std::vector of length 1, capacity 1 = {0x7789f0},
softmax_top_vec_ = std::vector of length 1, capacity 1 = {0x779708},
has_ignore_label_ = false, ignore_label_ = 0,
normalization_ = caffe::LossParameter_NormalizationMode_VALID,
softmax_axis_ = 1, outer_num_ = 100, inner_num_ = 1}
附2
template <typename Dtype>
void SoftmaxLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
/// scale is an intermediate Blob to hold temporary results.
Dtype* scale_data = scale_.mutable_cpu_data();
// (gdb) p *bottom_data = 0.0491851866(进行归一化后的像素值,还原的话要除以scale: 0.00390625)
//(gdb) p *top_data = 0
//(gdb) p *scale_data = 0
int channels = bottom[0]->shape(softmax_axis_);
// p channels = 10
int dim = bottom[0]->count() / outer_num_;
// p dim = 10(10个类)
caffe_copy(bottom[0]->count(), bottom_data, top_data);
//将bottom的数据复制给top,bottom[0]->count()=1000 为复制的个数
// We need to subtract the max to avoid numerical issues, compute the exp,
// and then normalize.
//对每一张图片进行数据的处理
for (int i = 0; i < outer_num_; ++i) {
//outer_num_输入图像的个数=batch_size
// initialize scale_data to the first plane
caffe_copy(inner_num_, bottom_data + i * dim, scale_data);
for (int j = 0; j < channels; j++) {
for (int k = 0; k < inner_num_; k++) {
scale_data[k] = std::max(scale_data[k],
bottom_data[i * dim + j * inner_num_ + k]);
}
}
//先求取max然后所有值先减去了这个max,目的作者也给了注释是数值问题,毕竟之后是要接上e为底的指数运算的,所以值不可以太大,这个操作相当合理
// subtraction caffe各公式计算http://blog.csdn.net/seven_first/article/details/47378697
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, inner_num_,
1, -1., sum_multiplier_.cpu_data(), scale_data, 1., top_data);
//top_data(10*1)=-1*sum_multiplier_.cpu_data()(10*1)* scale_data(1*1)+1*top_data(10*1)
// exponentiation
caffe_exp<Dtype>(dim, top_data, top_data);
// sum after exp
hege_cpu_gemv<Dtype>(CblasTrans, channels, inner_num_, 1.,
top_data, sum_multiplier_.cpu_data(), 0., scale_data);
// division
for (int j = 0; j < channels; j++) {
caffe_div(inner_num_, top_data, scale_data, top_data);
top_data += inner_num_;
}
}
这个大的for循环主要是实现这个公式(假设函数)!
}















 503
503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









