







今天读的是2015年CVPR的一篇paper,关于图像分类的,做一些笔记,方便以后回忆。
**The Application of Two-level Attention Models in Deep Convolutional Neural
Network for Fine-grained Image Classification**
一看好亲切,中国人发表的,北大清华滴(不愧是中国第一第二的学府)
帅气的分割线。。。
————————————————————————————————————————
摘要
fine-grained分类问题很challenging。一般都是先找出forground(最显著位置?)的物体然后来提取可区分性的特征,即where and what。
本文利用了三种attention的机制:
a)bottom-up attention:粗略地提取候选的patches
b)object-level top-down attention:精细选择出和目标物体很相关的patches(Deep Learning)
c)part-level top-down attention:提取可区分性的特征
(这里插一句,关于bottom-up和top-down attention的机制在某篇论文里有下面一段介绍,有兴趣的可以看一下,不看也无所谓:Bottom-up mechanisms are thought to operate on raw sensory input, rapidly and involuntarily shifting attention to salient visual features of potential importance – the spot of red against a field of green that could be a piece of fruit, the sudden movement that could be a predator. Top-down mechanisms implement our longer-term cognitive strategies, biasing attention toward colored spots if we are hungry or toward sudden movements and quadrupedal shapes if we fear a predator.)
然后就是把上面的attention机制和深度学习结合起来,效果杠杠的。
还要强调一句,本文不使用expensive的标注,譬如bounding box或者part information from end-to-end,只用类别的label。
1 介绍
fine-grained分类问题就是在基础的(basic-level)种类中识别出从属的(subordinate-level)种类,譬如识别出狗狗中具体的品种,二哈呀,阿拉斯加呀,柯基呀。。。之所以说这种分类问题很难是因为有的区别很小,区分性的特征只存在于物体的部分,譬如狗狗的头,狗狗的尾巴。所以一般的流程就是先找到目标物体或者目标物体的部分然后在提取可区分性的特征。
所以需要上面提到的bottom-up步骤——利用selective search(一种非监督的方法)找出上千个很objectness的patches,但是这种方法高召回率低准确率,即找了很多noisy的patches,和目标物体几乎无关,大部分都是背景。所以需要接下来的步骤——top-down attention的模型来过滤到noisy的patches选出相关的patches,而这个attention的模型又分为两个过程,object-level和part-level(也就是标题所说的two-level models)

Methods
本文是基于一个很简单的直觉:
fine-grained分类问题分为两步:第一步就是找到目标物体,第二步就是找到最具区分性的部分。举个简单的例子,一张吉娃娃的图片,先要看见一只狗狗,然后再找到可以和别的种类的狗狗区分出来的特征。
因此,我们的分类器是基于patches来做的而不是原始图片。但是很detailed的label很昂贵,所以我们选择使用尽可能弱的label,即image-level的label。(弱监督?)
本文引出了一个方法:
a)bottom-up process
概念:从输入图片中提取出很有objectness的patches,按照下面两篇paper的方法:
N. Zhang, J. Donahue, R. Girshick, and T. Darrell.Part-based r-cnns for fine-grained category detection.In ECCV. 2014.
J. R. Uijlings, K. E. van de Sande, T. Gevers, and A. W. Smeulders. Selective search for object recognition. IJCV, 2013.
需要提供多尺度和多视角的原始图片
问题:高召回率低精确率
解决方案:top-down attention
b)top-down attention models
I)object-level attention model
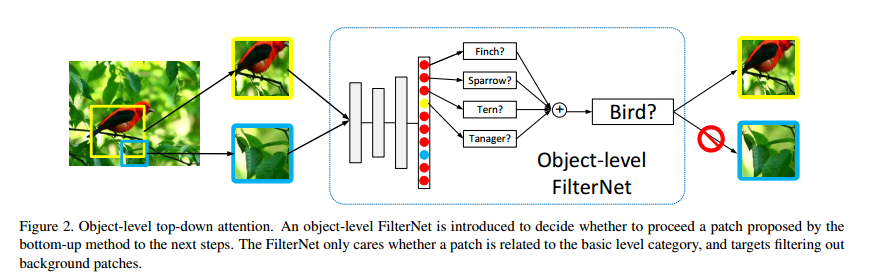
名称:FilterNet
用途:从bottom-up raw patches中来做patch selection,去除和目标物体不太相关的noisy patches
步骤:把一个在1000类ILSVR2012数据集上训练好的cnn转换成一个object-level FilterNet,softmax层中属于同一大类的神经元求和(譬如吉娃娃类,二哈类都属于狗大类,燕子,海鸥都属于鸟大类)作为selection confidence score,然后设定一个阈值,来决定这个patch是否该被选择,见下图
名称:DomainNet
用途:利用上面选出来的Patches(需要一些合适的变形)来从头训练一个新的CNN,称为DomainNet,之所以这么称是因为它可以提取一个大类中的具体各个物种的特征(譬如狗狗大类中吉娃娃、二哈、柯基的特征)。
原文:We call this second CNN the DomainNet because it extracts features relevant to the categories belonging to a specific domain (e.g., dog, cat, bird).
测试的时候:
对一幅图先用FilterNet筛选出patches,然后把这些patches输给DomainNet作前向传播,得到的结果average一下再做prediction就可以了。
实验部分:
1 数据集
ILSVRC2012中的两个子集:ILSVRC2012_Dog ILSVRC2012_bird,都是weakly annotated的,即只有类标签。
ILSVRC2012_Dog:153773 幅图,118种狗狗(好多狗狗呀);
ILSVRC2012_bird:79491幅图,59种鸟。
ps:训练/测试集按照标准的protocol分。
2 网络使用细节
AlexNet(换一下输出层)















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









