







文章目录
从14年开始,细粒度分类任务步入深度学习阶段,也逐渐有了流派之分。
Part-Based R-CNNs for Fine-grained Category Detection(by localization- classification subnetwork)
Abstract
语义部件定位能够有助于细粒度分类。
姿态归一化表征的方法已经提出,但是由于目标检测的困难性,在测试阶段需要假定一些目标框。
本文通过利用自下而上的区域建议方法计算得到的深度卷积特征来克服这一限制(大概意思是解决对目标框的依赖)。
本文提出的方法学习了对整体和局部的检测器,加强了他们之间的几何约束,并且从一个姿态归一化的表征中预测细粒度类别。
找局部、修正局部、得到特征。
Introduction
定位对象中的各个部分很关键,可以建立实例之间的对应关系,同时能够一定程度上缓解姿态的变化和相机视角的不同。(只要局部找到了不管他在画面中呈现何种姿态,影响都不大)
许多姿态归一化表征的瓶颈本质上是能够准确的定位局部。Poselet、DPM(星型结构,根滤波器用于定位对象、可变形部件模块用于定位局部,这里应该强调的是可变形部件模块)这些方法已经能够被用于获得准确的局部定位。但是在测试时需要给出标注的边界框,这个定位才够准确。
本文则解决了模型对边界框的需求。
在过去的任务中,局部定位和局部描述是分开的,在此次工作中用相同的深度卷积进行了统一。
Part-Based R-CNNs
在RCNN的方法中,对于特定的对象类别,候选检测 x x x的CNN特征描述 ϕ ( x ) \phi(x) ϕ(x)被分配得到分数 w 0 T ϕ ( x ) w_0^T\phi(x) w0Tϕ(x)。其中 w 0 w_0 w0是对象类别的SVM权重的可学习向量。
在本文的方法中,我们进行了一个强监督的设置。在训练过程中,我么不仅对整个对象有bounding box,对语义局部 { p 1 , p 2 , . . . , p n } \{p_1,p_2,...,p_n\} {p1,p2,...,pn}也有。
给定这些局部注释,在训练过程中,对所有的对象和他们的每个部分最初被视为独立的对象类别:我们基于候选区域提取得到的特征训练一个一对多的线性SVM。
与GT重合率超过0.7的,标注为正例,重合率小于0.3的标注为反例。因此,对于单一的对象类别,我们学习了whole- object SVM weights w 0 w_0 w0以及part SVM weights { w 1 , w 2 , . . . , w n } \{w_1,w_2,...,w_n\} {w1,w2,...,wn}。
在测试的时候,对于每一个候选框,我们计算所有root和part SVMs的得分。
本文采用R-CNN对目标整体和局部都进行了检测训练。
Geometric Constrains
我们的目标是在测试图像中识别目标位置和部件位置。
选择令得分最大的框们。
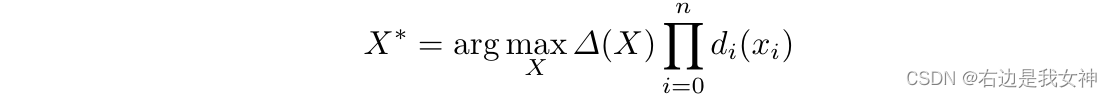
首先需要对框的选取进行限制。首先先选择可能的目标框和其中所有的部件框。之后定义评分函数:
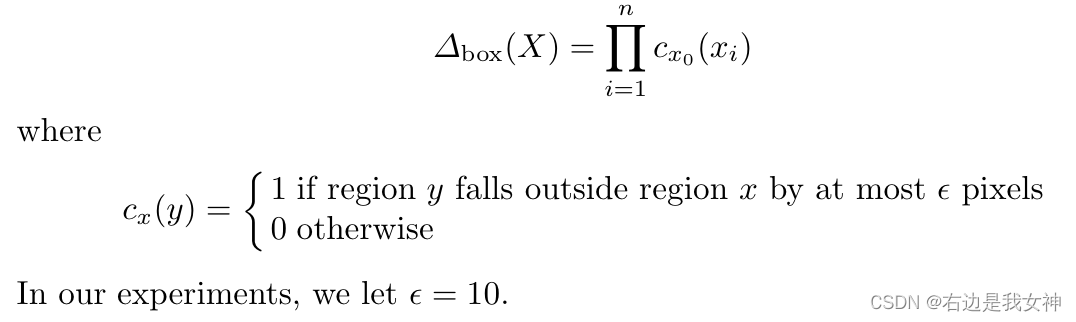
接着,我们要对几何进行约束。得分高的窗口不代表正确。特别是有遮挡时。因此,考虑使用一些评分函数来强制约束布局。

Fine-Grained Categorization
这里提的特征和预测位置的时候用的是一个。这一段重点说了这个CNN模型是预训练过的,完事儿还微调了一下。
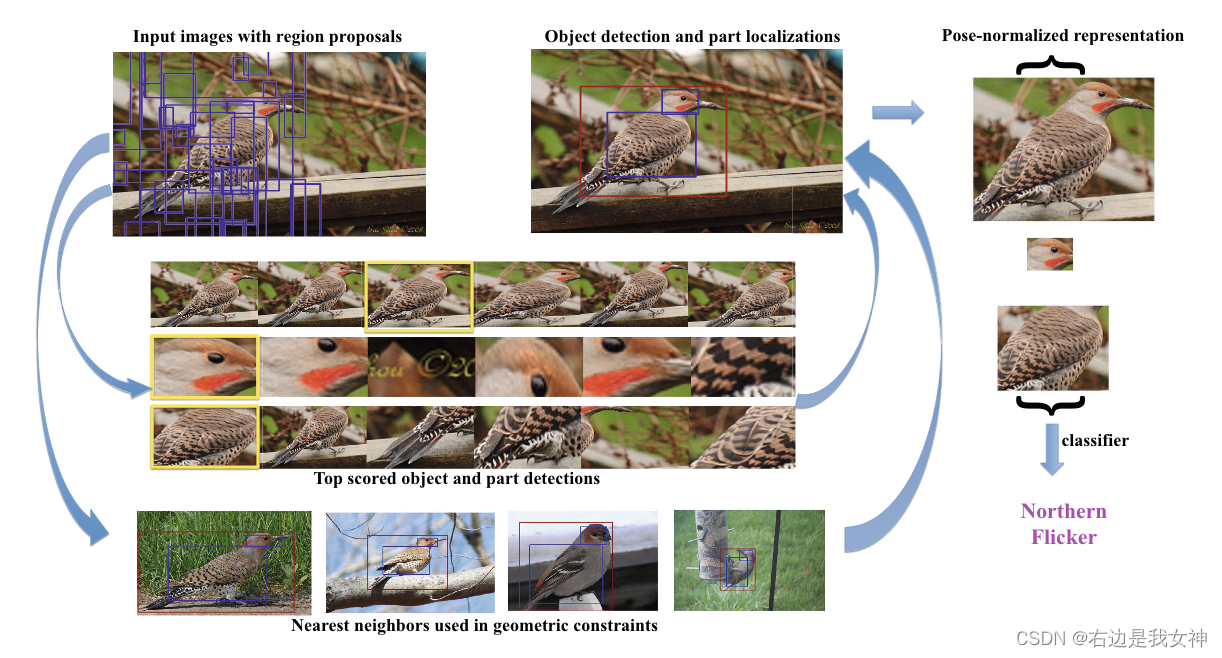
- 给出候选框;
- 所有窗口进行特征提取与评分;
- 依据约束进行窗口筛选;
- 根据最终的窗口的特征进行分类(此时的特征应该是姿态归一化的)。
相比于单纯的RCNN,增加了对部件的检测与配套的约束。
第二部分评分过程的训练依赖于局部的注释。
















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











