







文章目录
前言
想要了解一些好的audio to landmark的方法, 还记得有一篇one-shot的方法, 一会去看看。
正文
这篇论文是输入identity image 和audio signal, 输出会说话的人脸, 它会先切割把人脸框出来,然后做视频生成。
方法-aduio to landmarks
下图是它前半部分框架的方法:

下面是我从github作者提供的ppt看到的

- 注: latex正上箭头是这样
$\hat{}$, 输入\text=可以减小等号长度,\varphi是 φ \varphi φ
整体的公式如下:
p
^
1
:
T
=
Ψ
(
a
1
:
T
,
p
p
)
\hat{p}_{1:T}\text=\Psi(a_{1:T}, p_p)
p^1:T=Ψ(a1:T,pp)
其中
p
^
1
:
T
\hat{p}_{1:T}
p^1:T 是生成的 landmarks,
a
1
:
T
a_{1:T}
a1:T 是音频序列,
p
p
p_p
pp 是example frame的landmarks, 就是你输入的那张照片的landmarks.
作者把
Ψ
\Psi
Ψ 这部分叫做
A
T
-
n
e
t
AT\text-net
AT-net, 具体公式如下:
[
h
t
,
c
t
]
=
φ
l
m
a
r
k
(
L
S
T
M
(
f
a
u
d
i
o
(
a
t
)
,
f
l
m
a
r
k
(
h
p
)
,
c
t
−
1
)
)
[h_t, c_t]\text=\varphi_{lmark}(LSTM(f_{audio}(a_t), f_{lmark}(h_p), c_{t-1}))
[ht,ct]=φlmark(LSTM(faudio(at),flmark(hp),ct−1))
p ^ t = P C A R ( h t ) = h t ⊙ w ∗ U T + M \hat{p}_t\text=PCA_R(h_t)\text=h_t\odot w*U^T\text+M p^t=PCAR(ht)=ht⊙w∗UT+M
a t a_t at 是MFCC, h p h_p hp 是图片的PCA降维后的landmarks, h t h_t ht 就是和输入MFCC配对的PCA components. f a u d i o f_{audio} faudio, f l m a r k f_{lmark} flmark 是audio encoder 和 landmarks encoder , φ l m a r k \varphi_{lmark} φlmark 是landmarks decoder
P C A R PCA_R PCAR 是 PCA 重构矩阵, w w w 是 增强PCA feature 的 boost 矩阵. U 对应于最大特征值, M是训练集中 landmarks 的 mean shape
方法-visual generation
总体公式如下:
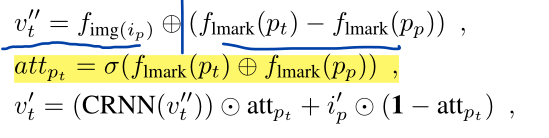
假设特征空间中当前图片和示例图片的距离可以用landmarks之间的距离表示
p
t
p_t
pt 是current landmark,
v
t
′
′
v_t^{''}
vt′′ 是当前帧的特征, 是模板图片的特征级联上当前帧landmark与模板图片landmark的差
然后根据difference计算注意力map
预测帧是通过注意力, 当前帧特征以及模板图片的特征
i
p
′
i_p^{'}
ip′ (128*32*32)输入到MMCRNN得到.
CRNN部分是由卷积层, 残差块,和反卷积层构成
+是通道级联, . 是element-wise 乘法
方法-attention-based dynamic pixel-wise loss
Gan 损失或者L1, L2损失很难生成时序中持续变化的完美帧, 尤其是对于视听非相关的区域, 比如背景和头部运动
思想很简单, 就是和视听相关区域的像素取原图片的, 嘴唇部分用生成的像素
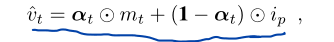
像素损失:
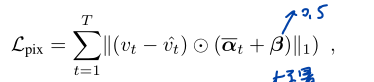
移除了αt的梯度,以防止平凡解(较低的损失但没有辨别能力)。还为所有像素赋予基本权重β,以确保所有像素都得到优化。手动调整超参数β,并在所有实验中设置β=0.5。

基于回归的鉴别器
这个部分利用了回归损失, 关键思想是,感知网络部分的权重是固定的,而损失只会对生成器/解码器部分产生影响。
鉴别器的输入是示例的landmark p p p_p pp, 和真值视频帧 v 1 : T v_{1:T} v1:T或合成的视频帧 v 1 : T ′ v_{1:T}^{'} v1:T′, 然后回归和输入帧配对的landmarks p 1 : T ′ p_{1:T}^{'} p1:T′,同时给出一个score s(对整个序列而言)

⊕ 意味着连接。+表示元素相加。蓝色箭头和红色箭头分别代表Dp和Ds
将鉴别器分为帧级部分Dp(图中的蓝色箭头)和序列级部分Ds(图中的红色箭头)
Dp观察模板landmarks和视频帧,然后回归出landmarks序列
图上的 pt^ 计算如下
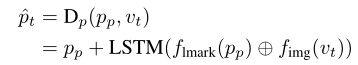
在鉴别器训练阶段观察ground truth图像,在生成器训练阶段观察合成图像
⊕ 意味着连接。+表示元素相加。
除了Dp, LSTM单元还产生另一个分支Ds,它从每个LSTM得到cell unit, 然后通过average pooling聚合它们. sigmoid判断序列得分
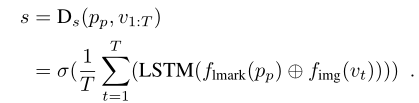
Dp部分经过优化,以最小化预测地标和地面真实地标之间的L2损失。
其实这个Dp和Ds也就是单帧和序列的区别,感觉区别也不是很大
最后是总的Gan Loss:
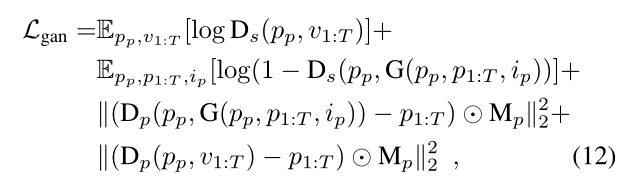 Mp是一个预定义的权重mask超参数,可以对嘴唇区域进行更多惩罚
Mp是一个预定义的权重mask超参数,可以对嘴唇区域进行更多惩罚
当我们训练生成器时,我们将固定鉴别器的重量,包括Ds和Dp,这样Dp就不会对生成器造成损害。从Dp传播的loss将强制生成器生成准确的面部形状(例如脸颊形状、嘴唇形状等),从Ds传播的loss将强制网络生成高质量的图像。
目标函数
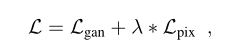
参数为10.0
实验
在 LRW 数据集和 GRID 数据集上定量和定性地评估 ATVGnet
LRW数据集由500个不同的单词组成,数百个不同的说话者的视频。遵循与论文(Lip reading in the wild. 2016)中相同的 train-test split。In GRID dataset, there are 1000 short videos, each spoken by 33 different speakers in the experimental condition.
对于图像流,使用 dlib 以25FPS的采样率基于提取的地标的关键点(眼睛和鼻子)对齐视频中的所有会说话的脸,然后将其调整为128*128。对于音频数据,每个音频段对应于 280ms 音频。以 10ms 的窗口大小提取MFCC,并使用中心图像帧作为配对的图像数据。
作者从原始MFCC向量中删除了第一个系数,并最终为每个音频块产生了
28
,
12
28, 12
28,12 的 MFCC 特征
评价指标
- PSNR
- SSIM
- landmark distance(LMD)
















 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











