







1.流水线前后处理与高性能采样
(1)使用流水线策略将 Tokenize(CPU),Computing(GPU), Detokenize(CPU)之间的延迟相互掩盖,这将提升系统5%~10%的QPS
模型推断过程无法并行,因为只有一个gpu,但是tokenize和Detokenize是cpu上发生的。
Detokenize发生的过程,实际上是等前一步的sample完成后,gpu结果完成后,在cpu上做Detokenize。实际上此时GPU就空闲了,即当上一次Sample完成后,可以直接进行下一次Computing的计算,可以不用等下一次Detokenize。这就是流水线优化。
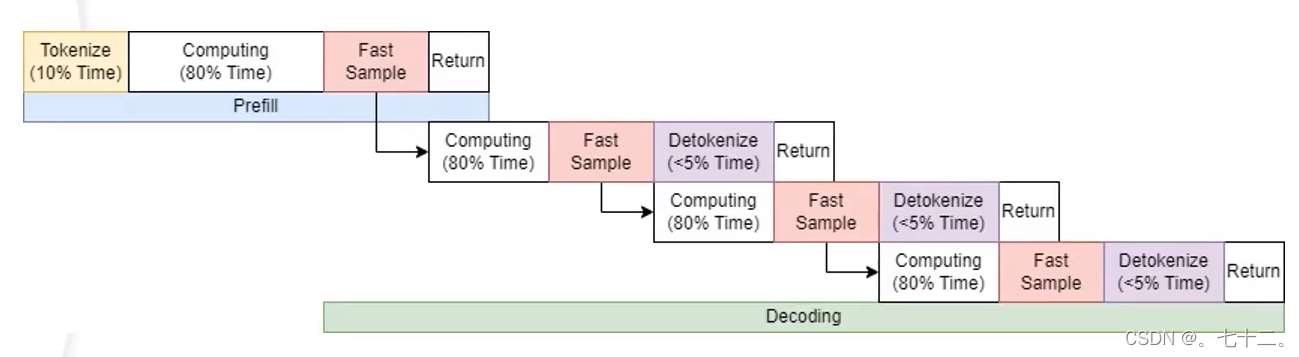
为了完成上述的优化,至少要开启三个线程或者线程池,一个线程池做tokenize,一个线程池做Detokenize,一个线程池做Computing(永远不可能并行的)。GPU过程会连续在一起,cpu会完全异步于GPU计算。
(2)使用更高性能的采样算子将提升系统10%~20%的QPS
FastSample进行采样。
2.动态批处理
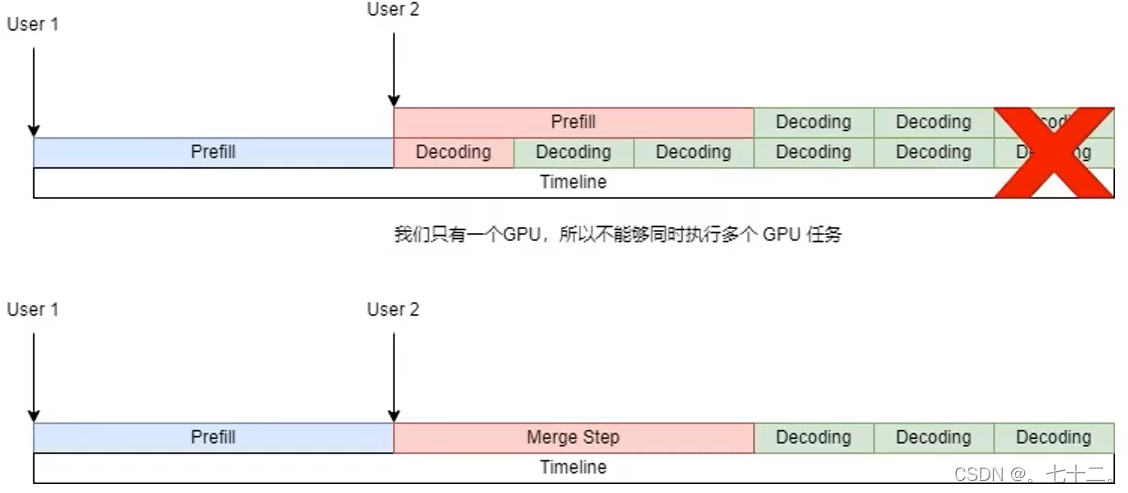
怎么协调多个用户在不同时间过来,怎么将该任务协调进去。第一个用户一开始达到系统,开始进行prefill,此时user2过来,执行他的prefill,他的prefill会和user1的decoding重叠在一起,但是重叠在一起是不能执行的,因为只有一个GPU,一时间内只能发一个任务上去。
(1)优化Deoding Attention:
当我接收到一个新输入时,会将接下来的一步变成merge step(将user1和user2的输入拼接在一起,同时进行操作,拼接好的输入一起做decoding)。
拼接具体过程:
user1进行decoding的过程,每次会输入一个token(维度:[1,4096]),user2需要做prefill会将所有内容进行输入(维度[48, 4096]),沿着第一个维度拼接在一起[49, 4096],然后标记第0个词是user1的,第1到48个词是user2的,然后正常执行模型推断
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 755
755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











