






1.数据并行(DP)
将小批量分为n块,每个GPU拿到完整参数计算一块数据的梯度。(通常性能会更好)
假如一个批量有128个样本,然后有2个GPU,那么每个GPU可以拿到64个样本。(每个GPU计算完这部分样本的梯度后,会将所i有的梯度加起来,就会完成小批量的梯度的计算。)
所有梯度相加其实是完整的梯度,模型本质只有一份,进行模型更新,每个gpu模型保存一致。
数据并行又包含:DDP、FSDP等。
2.模型并行(MP)
将模型分成n块,每个GPU拿到一块模型计算他的前向和反向结果。
例如:有一个100层的Resnet,有两个GPU,那么一个gpu拿50层,另外一个gpu拿另外50层。第0号gpu计算完成后,把结果给gpu1,gpu1接着在往下计算。算梯度时倒过计算。gpu0计算式gpu1可能会空着,gpu1计算式gpu0可能会空着性能难以优化。一般是用于单个gpu无法加载模型的情况。
从单机多卡拓展到分布式训练:
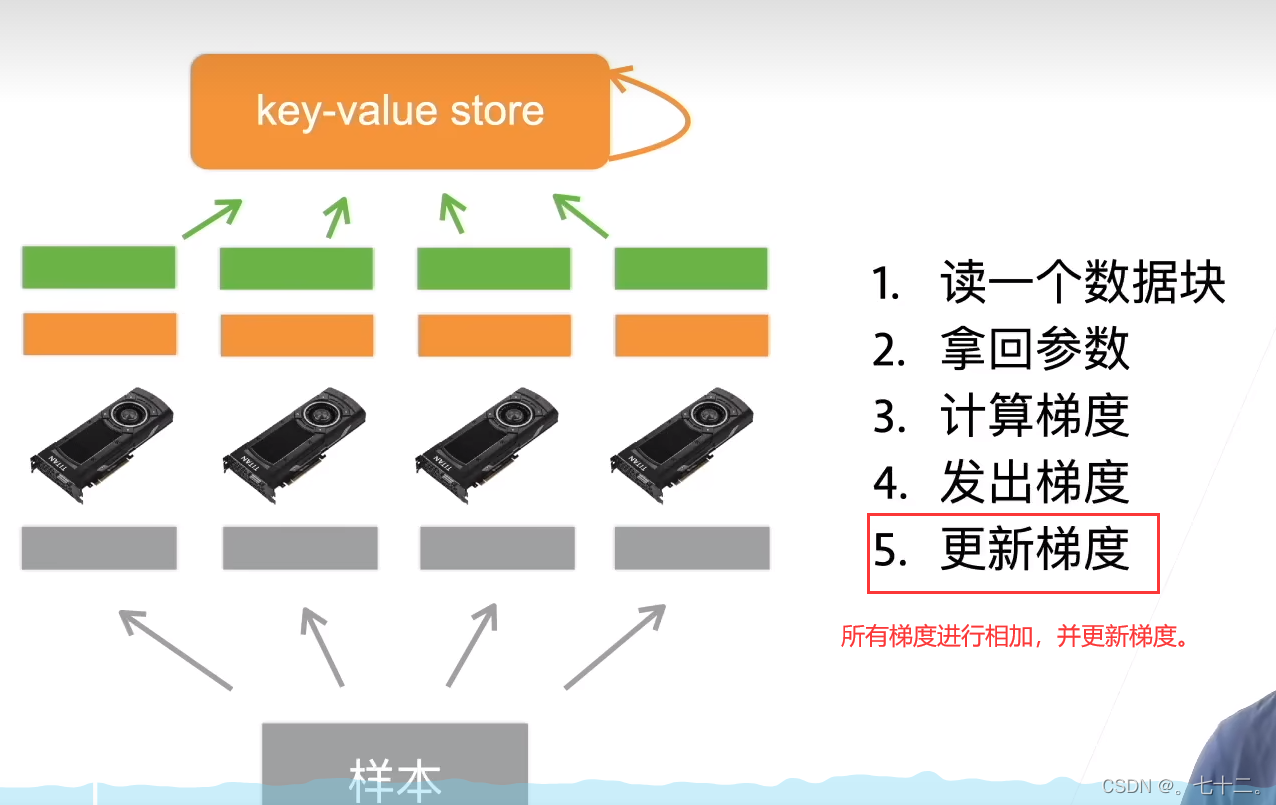
①数据存放的不同:数据可能放在一个分布式的文件系统上(而不是机器本地的硬盘上),所有的机器都可以去读取这个样本(分开存在不同的磁盘上)。收发参数,从一个网络跑到另一个网络。
②读取参数:通过网络读取。
③收发梯度:从一个gpu拷贝到另一个gpu。现在是通过网络从一台跑到另一台机器。
④性能方面的区别:
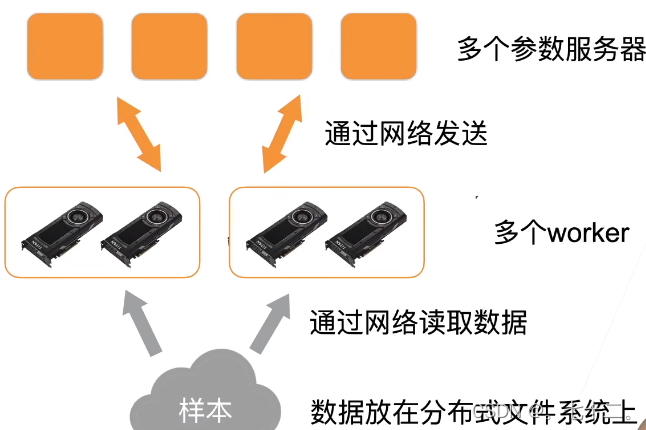
GPU机器架构:
(GPU与GPU之间通讯很快的,GPU到CPU之间通讯会降(5倍或10倍,通过PCIe通讯的),如果跨机器,通讯会降得更多。)尽量本地多通讯,实在不行可以取内存走一走,尽量避免多个机器通讯。

在做分布式时,尽量减少跨机器通讯。
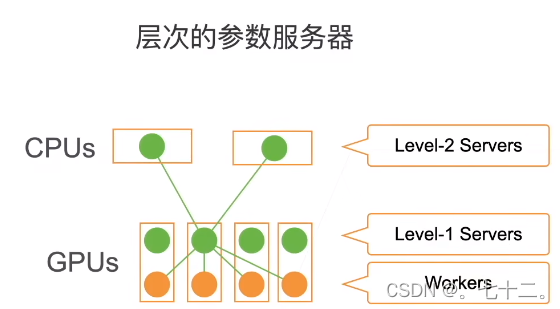
⑤在做分布式训练时,怎么减少跨机器的通讯:
读入样本,假设有两台机器,每个机器有一张卡,一共有100个样本,则每台机器拿到50,每个卡拿到25(先复制到每个机器的内存,再复制到每个gpu的内存)。每个机器从参数服务器上拿到模型,模型是被复制到每个gpu上(每次从(假设有个server)server上拿到一个模型到主内存,之后在复制到gpu上),开始每个gpu计算自己的梯度,现在本地做all reduce(把每个gpu的梯度累加到主内存上),加完之后再把梯度发出去(梯度传回服务器)。
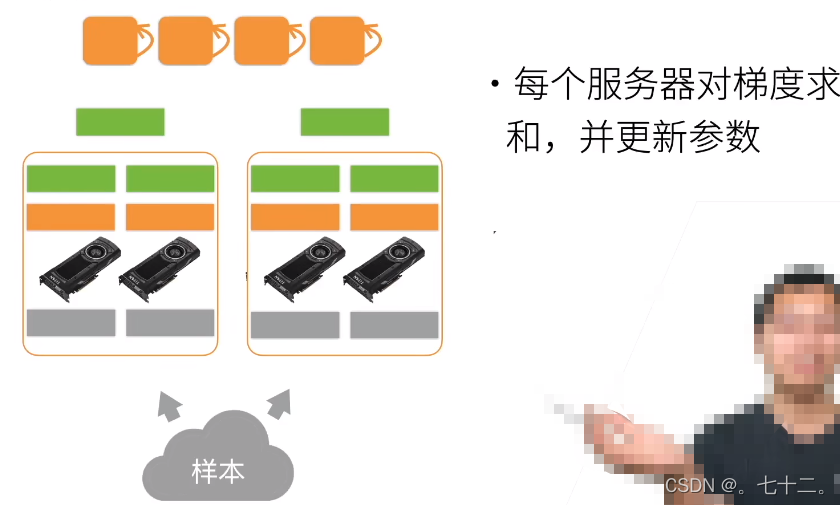
同步SGD:

所以就有当你的bs固定,lr固定,增加gpu的数量,是不会影响模型收敛的。
性能:

如果计算时间>>通讯时间 那么主要就是计算时间,反之会导致gpu等待。增加样本数不会影响通讯时间,因为通讯时参数是批量发出去(增大b,t1会增大,t2不会)。一般t1比t2大20-30%左右。(但是增大b,训练有效性会降低,会导致收敛变慢,需要更多epoch达到需要精度;如果一个批量中有很多相似的冗余照片,每个样本计算出来的梯度都是相同的,对梯度贡献相同,所以最好小批量中数据多样性较大,bs大小取决于数据集的多样性和优化算法,一般不要超过10*类别数)。
性能的权衡:
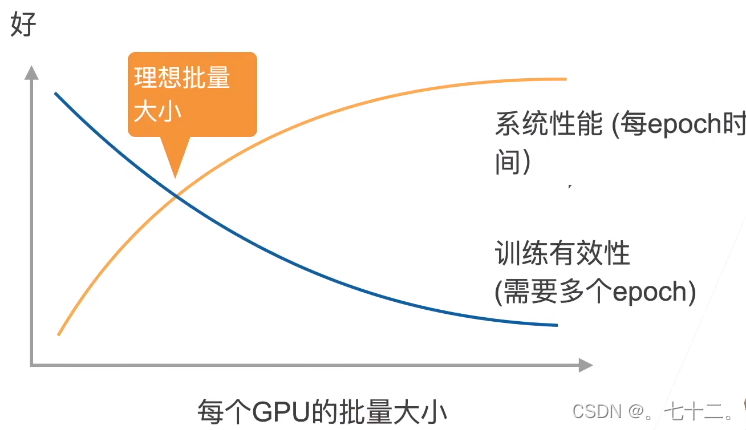
做并行的建议:
- 使用一个大的数据集;
- 好的GPU-GPU和机器-机器带宽。好的主板,gpu和gpu之间的带宽、gpu和cpu之间的带宽很高;
- 高效的数据读取和预处理;
- 模型有较好的计算(FLOP)通讯(model size)比;
- Inception>resnet>alexnet
- 使用足够大的批量大小获得好的系统性能;
- 使用高效的优化算法对应大批量大小。
模型并行又包含:张量并行(TP)和流水线并行(PP)。
3.通道并行(数据+模型并行)
当一个模型能够用单卡计算,通常使用数据并行拓展到多张卡。
模型并行则用于单张卡无法加载模型的情况。
分布式训练效果,时间并没有缩短有很多原因,有可能是data读起来比较慢、gpu增加但是batchsize没有增加(例如gpu从1变为2,但是batchsize仍然是256,原来一个gpu可以处理256个样本,现在换成2个GPU,每个只能处理128个样本,本来lr已经足够小,batchsize变小,计算性能会变低。)所以增加gpu,最好每个gpu仍然能拿到同样的batchsize,但是收敛可能会变慢,可以适当增加lr。

(损失函数抖动大的情况下,可以适当调小学习率,数据集多样性不够大的时候,batchsize不能设置的太大,同一批数据中样本重复或相似,计算梯度是浪费。)
batchsize越大,理论上数据稳定性会越好。(batchsize小的时候,lr不能太大)
















 529
529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











