







 本文介绍了一种名为NMRNN的深度学习模型,它在不依赖手工特征和预处理的情况下,通过端到端训练,有效地检测呼吸周期中的噪声并分类肺部声音。实验结果显示,NMRNN在肺部声音分析任务中表现出色,优于传统机器学习模型和同类深度学习方法。
本文介绍了一种名为NMRNN的深度学习模型,它在不依赖手工特征和预处理的情况下,通过端到端训练,有效地检测呼吸周期中的噪声并分类肺部声音。实验结果显示,NMRNN在肺部声音分析任务中表现出色,优于传统机器学习模型和同类深度学习方法。
具体的软硬件实现点击 MCU-AI技术网页_MCU-AI人工智能
简介
在过去的几十年里,许多机器学习(ML)方法被引入来分析呼吸周期的声音,包括爆裂声、咳嗽声和喘息声[1-6]。然而,几乎所有传统的ML模型都完全依赖于手工制作的功能。此外,需要高度复杂的预处理步骤来利用设计的特征[4-6]。因此,仅仅基于ML的模型可能对肺部声音中的外部/内部噪声不具有鲁棒性,并且可能无法在不同的软件和测量设备中推广其性能。然而,要在诊所中使用呼吸追踪系统,必须达到高分类精度。从这个角度来看,深度学习(DL)模型[7]在社区中获得了很多关注。基于DL的模型主要依赖于通过模型训练学习的数据的高度抽象表示。由于这一事实,DL模型在一系列任务上达到了最先进的性能,包括图像识别[8]、语音识别[9]、时间序列预测[10]。在这项工作中,我们提出了一种称为NMRNN的递归神经网络架构,该架构以端到端的方式进行训练,以同时检测呼吸周期中的噪声,并将肺部声音分为几个类别,如:正常、喘息、爆裂或喘息和爆裂。换句话说,我们的模型它本身决定了它应该使用什么信息以及从什么时间点进行呼吸声音的有效预测。该模型的关键特征是,它在不应用任何手部预处理阶段(如单个呼吸周期的切片)的情况下进行训练。通过广泛的测试,所提出的模型在最近发表的大型开放式肺部声音记录数据库上达到了最先进的性能[11]。
方法
RNN是一类人工神经网络,能够处理声音和文本等时间数据。RNN可以使用其内部状态(内存)和反馈来处理输入序列。LSTM(长短期记忆)和GRU(门控递归单元)网络[15,16]是RNN的流行变体。它们在序列相关任务上表现出前所未有的性能,如NLP(自然语言处理)[17]和语音识别[18]。我们在实验中同时使用LSTM和GRU单元。NMRNN基于三个主要思想:
1.自适应RNN,它是为时间尺度数据设计的,可以考虑来自输入信号的顺序帧的所有信息。
2. 在训练过程中自动区分噪音和内容。
3. 只使用呼吸(没有噪音)进行预测,因为噪音可能包括类似喘息或爆裂声的有偏差的异常。
MNRNN模型由三个部分组成:噪声分类器、呼吸(或异常)分类器和某种称为MASK的注意力。该模型的示意图如图1所示。
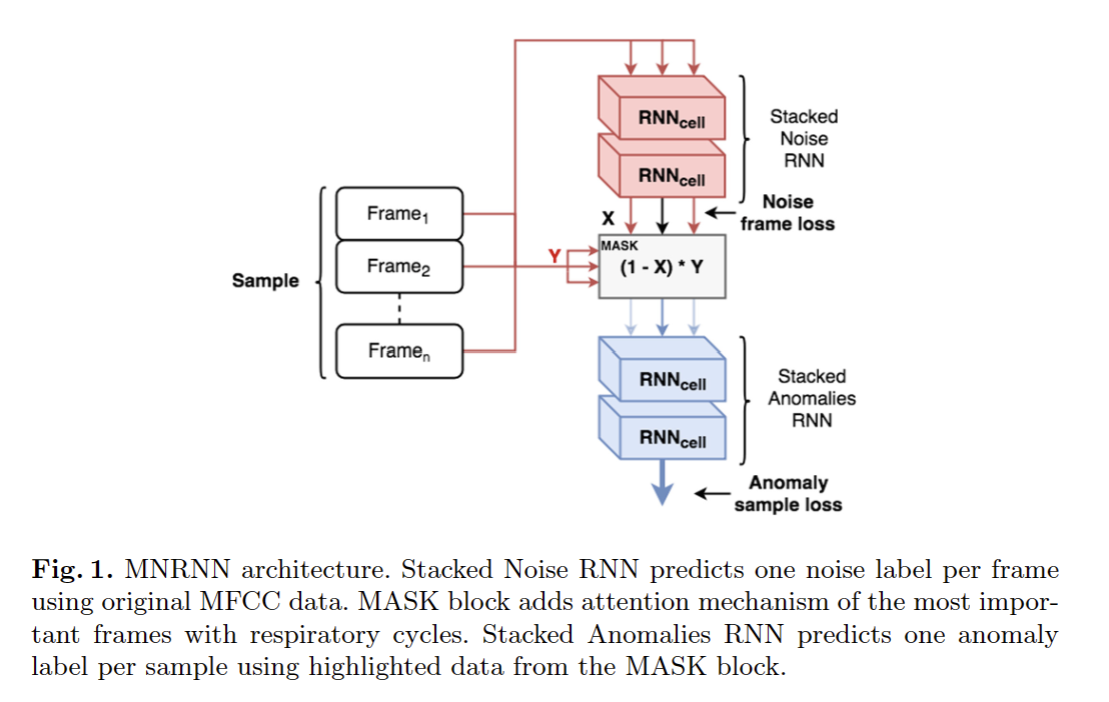
首先,在模型训练之前,将每个声音样本分割在长度相等的帧上。对于声音样本只有一个异常标签,对于每个帧只有一个噪声标签。噪声分类器是一种称为NRNN的堆叠RNN,它预测样本中每一帧的噪声标签。NRNN优化训练期间为每个输出计算的交叉熵损失
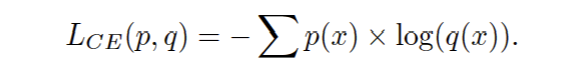
然后,预测噪声标签通过称为MASK的掩蔽层传播,其中原始帧与掩蔽系数(1−X)×Y相乘,其中Xi是预测噪声标签(对于噪声帧,X=1),Y是帧。异常分类器是一个称为ARNN的堆叠RNN,它为一个样本(所有帧)预测一个异常标签。ARNN将MASK块中高亮显示的帧作为输入数据,并优化每个样本一个标签的交叉熵损失。拟议架构的最终损失如下:
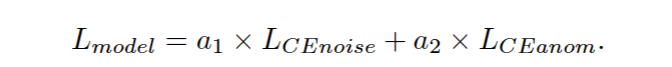
系数a1和a2的值基于这样的思想,即模型的主要目标是异常分类,而不是噪声分类。所提出的MASK机制简单高效,其灵感来自GRU单元中使用的门控技术,其中需要在每个时间步长仅使用来自输入的重要信息来重写存储器。使用NRNN和ARNN损失对NRNN参数进行了优化,因此NRNN和MASK机制一起不仅可以掩盖噪声帧,还可以突出显示具有类似呼吸内容的有用子样本。当前模型中使用的注意力机制与通常用于seq2seq模型的机制不同[19]。主要区别在于,seq2seq注意力机制通常使用编码器隐藏状态的加权和来创建上下文向量,并将其映射到当前解码器隐藏状态。因此,seq2seq中的注意力扩展了解码器在序列预测过程中的视野。我们的MASK层依赖于预测的噪声和异常标签,因为它接收来自两个RNN块的梯度。我们进行了额外的实验,以表明具有MASK机制的模型在分类指标方面优于没有MASK机制。MNRNN方法的主要特点是能够执行端到端分类,而无需使用任何手动预处理步骤,如在单独的循环上切片呼吸。我们所做的唯一常用的预处理步骤是将数据分割成相等的帧。帧的数量也不会影响模型的训练和测试。
实验
在这项研究中,逻辑回归(LR)、随机森林(RF)、梯度提升机(GBM)、基于SVM的分类器[20]和标准RNN被用作用于与NMRNN模型进行比较的基线。对于基线实验,我们使用了与[4]中提供的相同的预处理。
数据
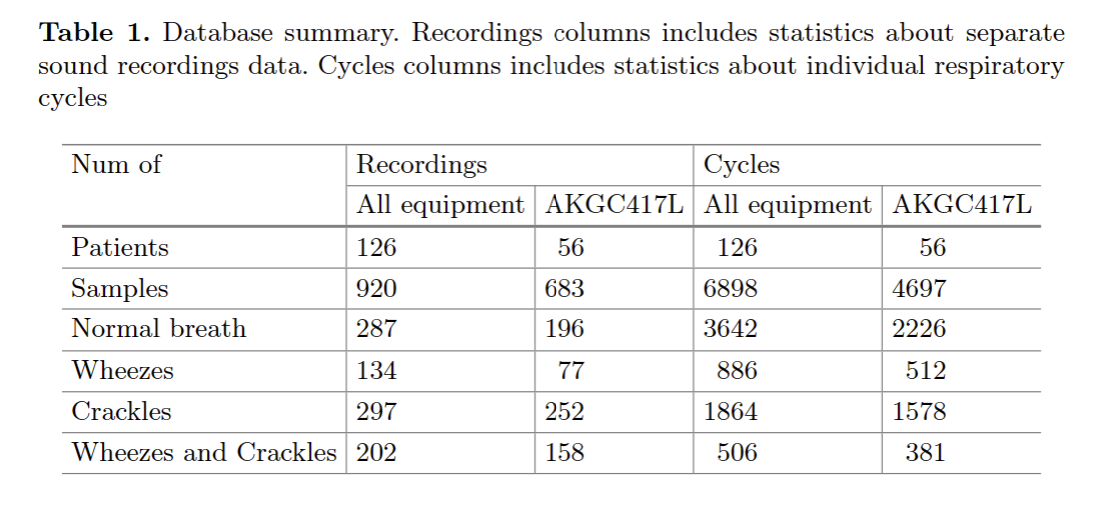
为了进行训练和评估,使用了ICBHI科学挑战数据库[11]。该数据库包含音频样本,由两个不同国家的两个研究团队在几年内独立收集。该数据库由来自126名患者的920个注释音频样本组成。它包括6898个不同的呼吸周期,1864次爆裂,886次喘息,506次爆裂和喘息。数据库摘要如表1所示。声音中有很多噪声:所有数据中有1840个噪声周期,AKGC417L数据中有1366个噪声周期。它模拟了真实生活条件,使分类算法对噪声攻击更加鲁棒和稳定。
实验步骤
在这项工作中,我们进行了几个实验。对它们使用了不同的数据和预处理步骤。所有实验的关键思想是将所提出的方法与其他机器学习模型在不同情况下的性能和鲁棒性进行比较。1.用于初始模型检查的简单噪声二值分类实验。2.使用个体呼吸周期作为输入的4类异常分类。3.使用每个声音样本中有几个呼吸周期的声音样本进行4类异常分类(端到端分类)。第一个实验的目的是检查RNN和NMRNN学习呼吸和噪声周期间隔长度和频率的能力。第二个实验应该将我们的基线模型与最近提出的方法进行比较[12]。
第二个实验是示范性的,但它有一个关键的局限性:它不是端到端的实验,因为首先我们需要在呼吸周期上分割肺部声音,但这项任务还没有自动的通用解决方案。因此,对于每个新的肺部声音记录,我们需要手动将其划分为呼吸周期。出于这个原因,进行了第三个实验。本实验的目的是检查模型发现哪些输入信息是重要的以及它在多维特征空间中的位置的能力。作为端到端分类器的模型需要自己在数据中找到与呼吸相关的特征。此外,每个实验都有两种不同的数据。我们使用所有可用的数据和仅记录在AKGC417L麦克风上的数据。使用第二种数据类型的主要思想是表明仅使用一个无偏数据源,模型就可以获得更好的性能。所有实验都是在具有128GB RAM和NVIDIA GTX 1080Ti GPU的英特尔酷睿i7-6900 CPU的计算机上进行的。
结果
对于噪声二元分类任务,NMRNN获得了0.89的评估分数,而最佳基线模型GBM仅获得0.53的分数。这可以通过RNN学习周期和噪声间隔长度和频率并在预测期间使用该附加信息的能力来解释。
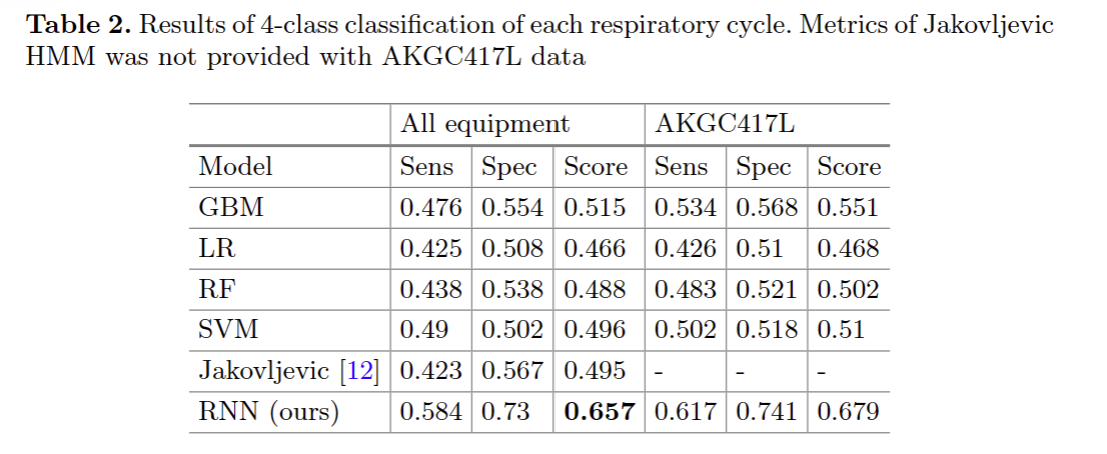
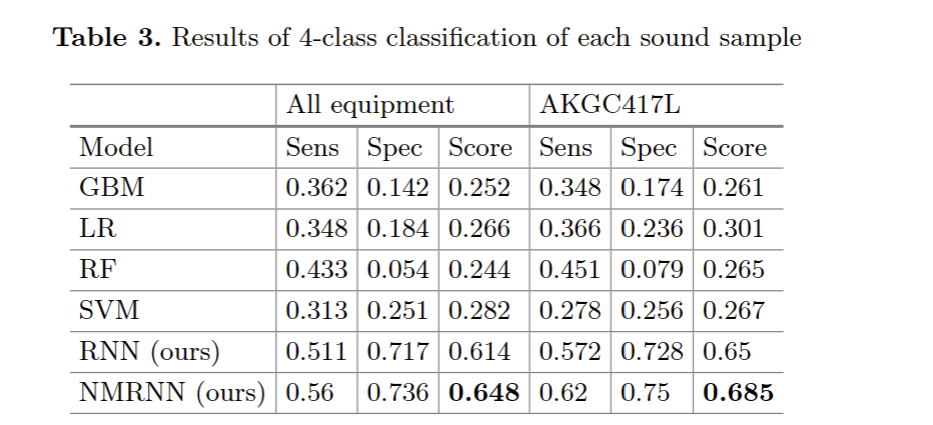
每个呼吸周期的4类分类结果如表2所示。我们的基线和NMRNN模型与Jakovljevic提出的基于HMM的方法进行了比较。所有模型都接受了MFCC功能训练。除了NMRNN优于竞争对手外,我们的模型的性能与Jakovljevic HMM[12]的性能相似。因此,在下一个实验中将所提出的基线模型与所提出的基于RNN的方法进行比较是正确的。此外,仅根据AKGC417L数据训练的模型由于数据分布的偏差减少而显示出预期的更好的分数。第二个实验没有第三个实验复杂,因为训练前人工切割了呼吸周期的数据。端到端分类的结果如表3所示。NMRNN在所选标准方面肯定优于其他方法。主要原因是RNN被设计用于处理具有时间依赖性的此类数据。

















 639
639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









