







近期碰到一个需求,需要对数据分组然后 分组后的数据还要进行处理
首先创建一个简单的dataframe
df=pd.DataFrame({'a':[1,3,3,3,4],'b':[1,3,3,3,40]})
print(df)
然后我们进行分组完整代码如下:
df=pd.DataFrame({'a':[1,3,3,3,4],'b':[1,3,3,3,40]})
print(df)
df2=df.groupby(by=[df['a'],df['b']]).count()
print(df2)
result:

居然是一个空列表,这样只有索引了,别的数据没有,所以这种方式行不通
对代码进行更新下:
df=pd.DataFrame({'a':[1,3,3,3,4],'b':[1,3,3,3,40],'c':[2,5,2,4,100],'d':[2,5,2,4,100]})
df2=df['c'].groupby(by=[df['a'],df['b']]).count().apply(lambda x:x+1)
df2=df2.reset_index()
print(df2)
执行结果:

注意这个里面是针对的C列数据进行了全部行处理,如果写多列那么多列都这样处理,groupby之后的count() 得到的结果是<class ‘pandas.core.frame.DataFrame’>类型
修改下代码在验证我们上面的结论
df=pd.DataFrame({'a':[1,3,3,3,4],'b':[1,3,3,3,40],'c':[2,5,2,4,100],'d':[2,5,41,3,100]})
df2=df[['c','d']].groupby(by=[df['a'],df['b']]).count().apply(lambda x:x+1001)
df2=df2.reset_index()
print(df2)
result:

c列和D列不一样,但是count数据都是针对非空数据,如果是np.NAN的话,会算作0,这一点和我们Oracle数据库得出的结果一致,非空列不统计在内
验证方式也很简单粗暴
df=pd.DataFrame({'a':[1,3,3,3,4],'b':[1,3,3,3,40],'c':[2,5,2,4,100],'d':[np.NAN,np.NAN,np.NAN,3,100]})
df2=df[['c','d']].groupby(by=[df['a'],df['b']]).count().apply(lambda x:x+1001)
df2=df2.reset_index()
print(df2)
result:

apply可以对整个dataframe进行处理,每一行每一列都这么干,但是前提要确保类型一致才行,apply和applymap这样效果均可以产生
对于分组之后的数据,没有进行count或者sum或者mean之类聚合操作的,我们可以使用apply来实现这些功能
完整代码如下:
import pandas as pd
import numpy as np
def get_price(df):
result=df[pd.notna(df['d'])].shape[0]
allcnt = df[['d']].shape[0]
return result/allcnt
df=pd.DataFrame({'a':[1,1,3,3,4],'b':[1,3,3,3,40],'c':[2,5,2,4,100],'d':[np.NAN,np.NAN,np.NAN,3,100]})
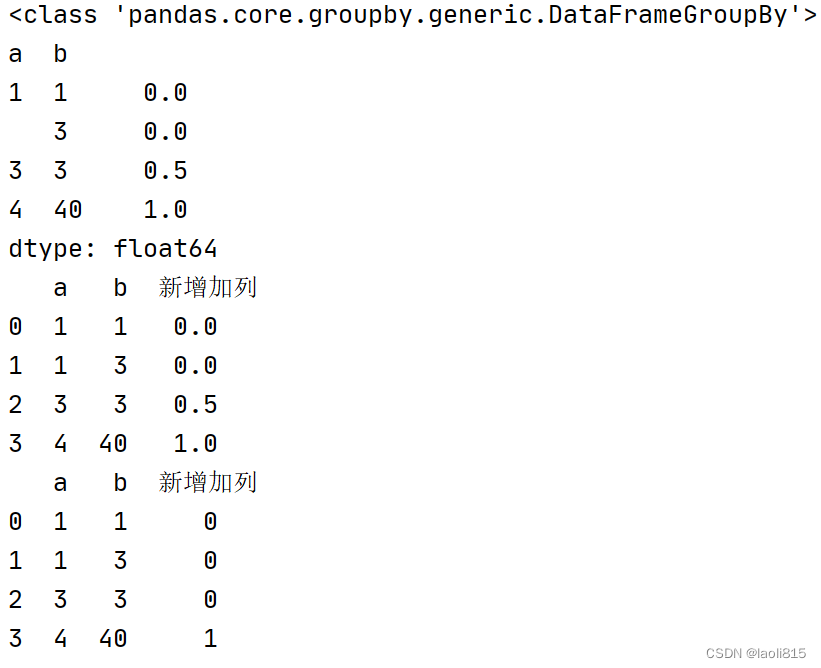
print(type(df.groupby(by=[df['a'],df['b']])))
df2=df.groupby(by=[df['a'],df['b']]).apply(get_price)
print(df2)
df2=df2.reset_index(name='新增加列')
print(df2)
df2=df2.applymap(lambda x:int(x))
print(df2)
result:
注意到上面groupby之后其实没有列名的,我们这是使用了reset_index(name=?)重新赋值
在上一个更完整的
import pandas as pd
import numpy as np
def get_price(df):
result=df[pd.notna(df['d'])].shape[0]
allcnt = df[['d']].shape[0]
return result,allcnt,result/allcnt
df=pd.DataFrame({'a':[1,1,3,3,4],'b':[1,3,3,3,40],'c':[2,5,2,4,100],'d':[np.NAN,np.NAN,np.NAN,3,100]})
print(type(df.groupby(by=[df['a'],df['b']])))
df2=df.groupby(by=[df['a'],df['b']]).apply(get_price)
print(df2)
df2=df2.reset_index(name='新增加列')
print(df2)
df2['分组d列不为空数据行数']=df2['新增加列'].apply(lambda x:x[0])
df2['分组d列总数据行数']=df2['新增加列'].apply(lambda x:x[1])
df2['百分数']=df2['新增加列'].apply(lambda x:x[2])
df2.drop(columns=['新增加列'],inplace=True)
print(df2)
result:
<class 'pandas.core.groupby.generic.DataFrameGroupBy'>
a b
1 1 (0, 1, 0.0)
3 (0, 1, 0.0)
3 3 (1, 2, 0.5)
4 40 (1, 1, 1.0)
dtype: object
a b 新增加列
0 1 1 (0, 1, 0.0)
1 1 3 (0, 1, 0.0)
2 3 3 (1, 2, 0.5)
3 4 40 (1, 1, 1.0)
a b 分组d列不为空数据行数 分组d列总数据行数 百分数
0 1 1 0 1 0.0
1 1 3 0 1 0.0
2 3 3 1 2 0.5
3 4 40 1 1 1.0
Process finished with exit code 0
可以看到函数
def get_price(df):
result=df[pd.notna(df['d'])].shape[0]
allcnt = df[['d']].shape[0]
return result,allcnt,result/allcnt
这个里面的df针对的分组之后每一组,apply应用的也是针对这个组的数据,本例获取的是空值和不为空的值
如果不能使用sum ,mean,max,min,count这类的聚合函数,我们可以使用这种
当然这里我们也可以对每一组分组之后的数据进行排序
伪代码如下
def sort(x):
return x.sort_values('columnname',ascending=False)
df.groupby(by=[coluns1,columns..]).apply(sort)
这样就可以对每组数据进行分组
关于pandas 聚合函数几种使用方式
```python
import pandas as pd
import numpy as np
def get_price(df):
result=df[pd.notna(df['d'])].shape[0]
allcnt = df[['d']].shape[0]
return result,allcnt,result/allcnt
df=pd.DataFrame({'a':[1,1,3,3,4],'b':[1,3,3,3,40],'c':[2,5,2,4,100],'d':[np.NAN,np.NAN,np.NAN,3,100]})
df2=df.groupby(by=[df['a'],df['b']]).count()
print(df2)
df2=df.groupby(by=[df['a'],df['b']]).agg({'c':'count','d':'count'})
df2=df2.reset_index()
print(df2)
df2=df.groupby(by=[df['a'],df['b']]).agg(ccount2=('c','count'),dcount2=('d','count'))
print(df2)
result:
c d
a b
1 1 1 0
3 1 0
3 3 2 1
4 40 1 1
a b c d
0 1 1 1 0
1 1 3 1 0
2 3 3 2 1
3 4 40 1 1
ccount2 dcount2
a b
1 1 1 0
3 1 0
3 3 2 1
4 40 1 1















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









