






开发文档 - 基于多维度机器学习算法的共享单车需求预测与可视化
1. 项目概述
项目名称:基于多维度机器学习算法的共享单车需求预测与可视化
项目背景:
共享单车作为一种便捷的城市出行方式,在全球范围内得到了广泛应用。为了提高共享单车的运维效率,精确预测需求变化成为管理和调度的关键。本项目基于多维度机器学习算法,结合历史数据,通过机器学习模型对未来的共享单车需求进行预测,为相关决策提供数据支持。
主要目标:
- 收集和整理共享单车的历史数据。
- 采用多种机器学习算法(线性回归、随机森林、支持向量机)进行需求预测。
- 使用 Flask 提供 Web 服务,展示预测结果并进行数据可视化。
2. 技术架构
2.1 后端技术栈
- 语言:Python 3.x
- Web 框架:Flask
- 数据库:SQLite(用于存储共享单车数据)
- 机器学习库:
scikit-learn:实现随机森林、支持向量机、线性回归等机器学习算法。pandas:用于数据处理和操作。numpy:用于数值计算。matplotlib:用于数据可视化。- 前端技术:
HTML5,CSS3,JavaScript- 数据可视化:
Chart.js,D3.js(用于展示预测结果)
2.2 前端技术栈
- 前端框架:Bootstrap 4(用于实现响应式界面)
- 图表库:
Chart.js和D3.js,用于绘制预测数据、需求量等可视化图表。
3. 数据库设计
项目使用 SQLite 数据库存储共享单车的历史数据和用户信息。以下是数据库的主要表结构设计:
3.1 数据库表:DanChe(共享单车数据表)
该表存储共享单车的历史行程数据,用于机器学习模型的训练和预测。
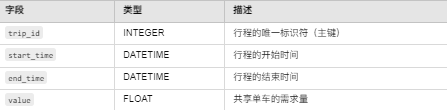
说明:
trip_id:每次行程的唯一标识符,作为主键。start_time和end_time:记录行程的时间信息,用于特征工程和时间序列分析。value:预测目标——共享单车的需求量,作为目标变量用于模型训练。
3.2 数据库表:User(用户表)
该表存储平台用户的信息,用于用户注册和登录。
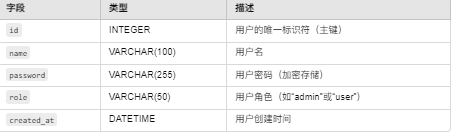
4. 机器学习算法
4.1 线性回归(Linear Regression)
线性回归模型假设输入特征和目标变量之间存在线性关系。其目标是通过训练找到最佳拟合线,使得预测值与真实值之间的误差最小。
核心代码:
def linear_regression_predict():
# 获取数据
dates = DanChe.query.all()
data = pd.DataFrame([(date.trip_id, date.date, date.value) for date in dates], columns=['trip_id', 'date', 'value'])
# 数据准备
X = data[['trip_id', 'date']] # 特征:trip_id和日期
y = data['value'] # 目标:预测的共享单车需求量(value)
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型训练
model = LinearRegression()
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'MSE: {mse}, R²: {r2}')
return model
功能:
- 将
trip_id和date作为特征,value作为目标变量。 - 使用
train_test_split将数据集划分为训练集和测试集,训练并评估线性回归模型。
优点:
- 简单直观,适用于线性关系的预测任务。
缺点:
- 假设特征和目标之间存在线性关系,无法很好地处理非线性问题。
4.2 随机森林(Random Forest)
随机森林是一种集成学习方法,通过训练多个决策树并对其预测结果进行投票或平均来做出最终预测。该方法能够捕捉特征之间的非线性关系。
核心代码:
def random_forest_predict():
# 获取数据
dates = DanChe.query.all()
data = pd.DataFrame([(date.trip_id, date.date, date.value) for date in dates], columns=['trip_id', 'date', 'value'])
# 数据准备
X = data[['trip_id', 'date']]
y = data['value']
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型训练
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'MSE: {mse}, R²: {r2}')
return model
功能:
- 使用多个决策树进行训练,能够处理复杂的非线性关系。
- 通过训练多个树,减少过拟合的风险。
优点:
- 适合高维数据,能够自动处理特征之间的交互作用。
- 对缺失值和异常值较为鲁棒。
缺点:
- 计算复杂度较高,特别是在树的数量较多时,训练和预测可能较为耗时。
4.3 支持向量机(SVM)
支持向量机(SVM)通过最大化间隔来进行分类和回归,能够处理复杂的非线性问题。在回归任务中,使用支持向量回归(SVR)。
核心代码:
def svm_predict():
# 获取数据
dates = DanChe.query.all()
data = pd.DataFrame([(date.trip_id, date.date, date.value) for date in dates], columns=['trip_id', 'date', 'value'])
# 数据准备
X = data[['trip_id', 'date']]
y = data['value']
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 模型训练
model = SVR(kernel='rbf')
model.fit(X_train, y_train)
# 预测与评估
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'MSE: {mse}, R²: {r2}')
return model
功能:
- 使用径向基函数(RBF)核进行回归预测。
- 在支持向量机回归(SVR)中,寻找最优超平面来进行数据预测。
优点:
- 对非线性问题特别有效,能够捕捉复杂的模式。
- 对小数据集有良好的泛化能力。
缺点:
- 对于大规模数据集,训练时间较长。
- 参数调优较为复杂,需要选择合适的核函数。
5. 项目结构
project/ │ ├── daoru.py # 数据导入与清洗 ├── main.py # Flask 应用入口,路由处理 ├── models.py # 数据库模型定义 ├── RandomForest.py # 随机森林算法实现 ├── SVM.py # SVM 算法实现 ├── yuce.py # 线性回归算法实现 ├── templates/ # HTML 模板 │ ├── index.html # 首页,展示预测结果 │ └── login.html # 登录页面 ├── static/ # 静态文件(CSS、JavaScript) └── dangche.db # SQLite 数据库文件
6. 部署与使用
6.1 环境配置
确保安装以下依赖:
pip install -r requirements.txt
6.2 启动 Flask 应用
python main.py
应用会在 http://127.0.0.1:5000/ 启动,用户可以通过浏览器访问。
6.3 数据库初始化
运行一次数据导入脚本 daoru.py,将共享单车数据导入 dangche.db 数据库。
7. 总结
本项目通过使用三种常见的机器学习算法(线性回归、随机森林和支持向量机)来预测共享单车的需求。通过 Flask 提供 Web 服务,展示预测结果并进行数据可视化。该系统可以帮助商家进行更精确的需求预测,优化单车调度和运营管理。
具体功能演示效果:
【基于多维度机器学习算法的共享单车流量预测与可视化分析(随即森林+svm+线性回归模型)S2025022】 基于多维度机器学习算法的共享单车流量预测与可视化分析(随即森林+svm+线性回归模型)S2025022_哔哩哔哩_bilibili
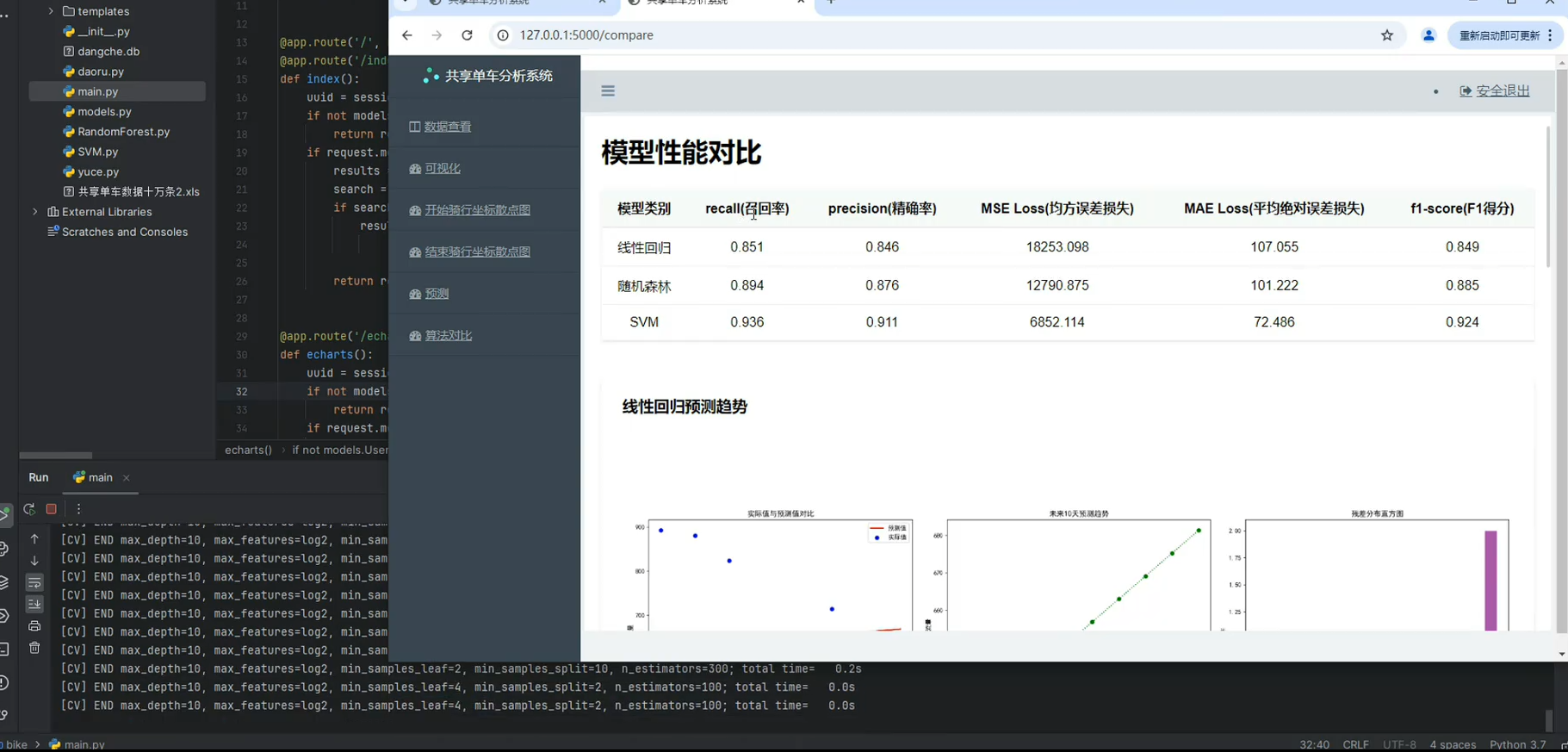
项目支持横向开发,只要是预测类的项目都能进行多算法模型对比二次开发(如空气质量预测、农产品价格预测)


















 2967
2967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











