






参考文档:(tiny) YOLOv4 详细训练指南(附下载链接)_yolov4_tiny 预训练模型下载-CSDN博客
由于需要在gazebo上识别仿真平台提供的iris四旋翼无人机,需要对其建立数据集并训练自己的.weights文件
开始标注
打开labelme,选择Opendir为~/darknet/train_data/VOCdevkit/VOC2007/JPEGImages
在上方菜单选择File/Change Output Dir为~/darknet/train_data/VOCdevkit/VOC2007/Json,
开启Save Automatically
选择Edit/Create Rectangle标注框为矩形
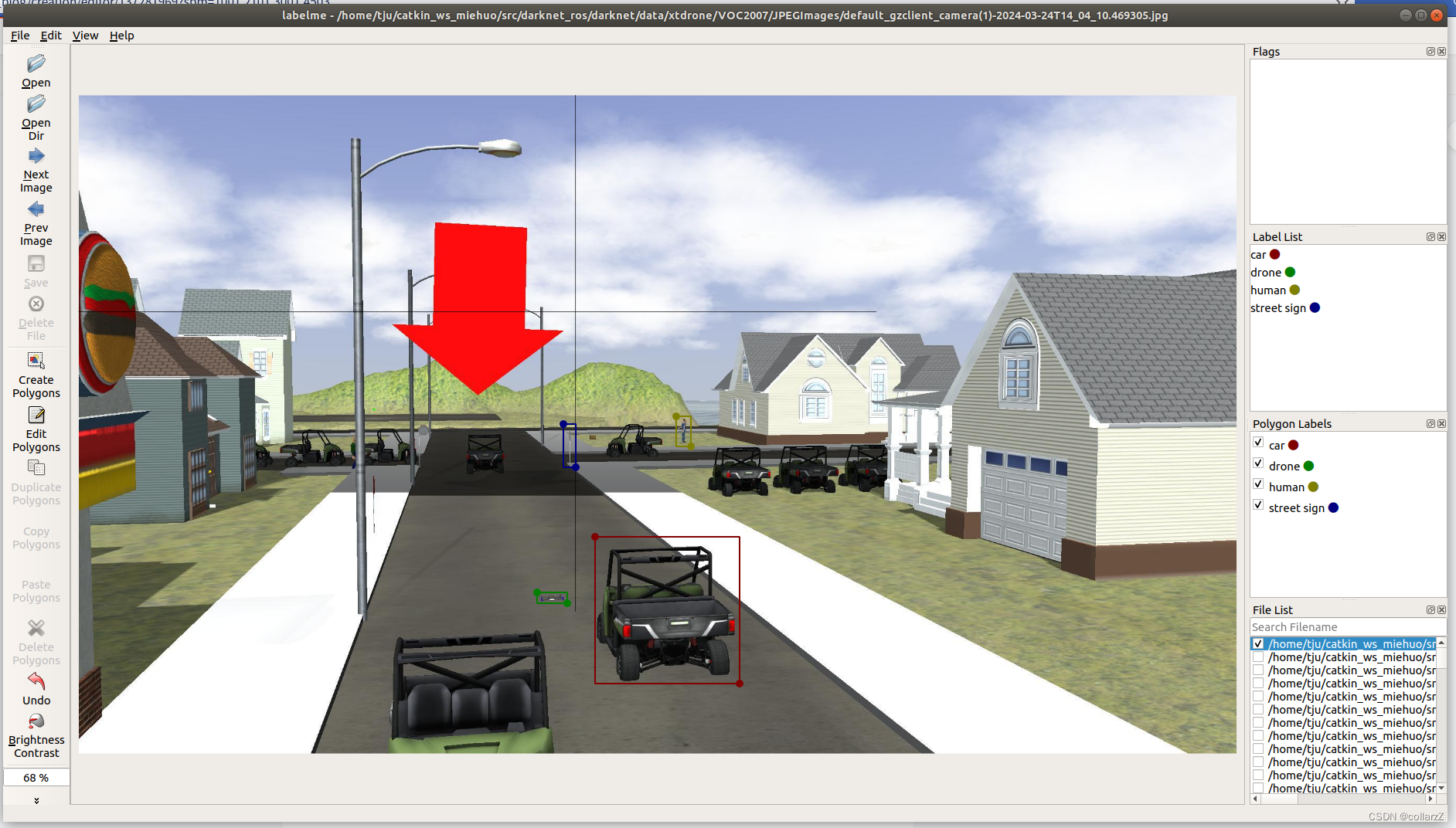
这里我标了四种类型,包括drone、car、human、street sign,依次将所有图片完成标注
使用下方.py脚本进行转换
from __future__ import print_function
import argparse
import glob
import os
import os.path as osp
import sys
import imgviz
import labelme
try:
import lxml.builder
import lxml.etree
except ImportError:
print("Please install lxml:\n\n pip install lxml\n")
sys.exit(1)
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument("input_dir", help="input annotated directory")
parser.add_argument("output_dir", help="output dataset directory")
parser.add_argument("--labels", help="labels file", required=True)
parser.add_argument(
"--noviz", help="no visualization", action="store_true"
)
args = parser.parse_args()
if osp.exists(args.output_dir):
print("Output directory already exists:", args.output_dir)
sys.exit(1)
os.makedirs(args.output_dir)
os.makedirs(osp.join(args.output_dir, "JPEGImages"))
os.makedirs(osp.join(args.output_dir, "Annotations"))
if not args.noviz:
os.makedirs(osp.join(args.output_dir, "AnnotationsVisualization"))
print("Creating dataset:", args.output_dir)
class_names = []
class_name_to_id = {}
for i, line in enumerate(open(args.labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
class_name_to_id[class_name] = class_id
if class_id == -1:
assert class_name == "__ignore__"
continue
elif class_id == 0:
assert class_name == "_background_"
class_names.append(class_name)
class_names = tuple(class_names)
print("class_names:", class_names)
out_class_names_file = osp.join(args.output_dir, "class_names.txt")
with open(out_class_names_file, "w") as f:
f.writelines("\n".join(class_names))
print("Saved class_names:", out_class_names_file)
for filename in glob.glob(osp.join(args.input_dir, "*.json")):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(args.output_dir, "JPEGImages", base + ".jpg")
out_xml_file = osp.join(args.output_dir, "Annotations", base + ".xml")
if not args.noviz:
out_viz_file = osp.join(
args.output_dir, "AnnotationsVisualization", base + ".jpg"
)
img = labelme.utils.img_data_to_arr(label_file.imageData)
imgviz.io.imsave(out_img_file, img)
maker = lxml.builder.ElementMaker()
xml = maker.annotation(
maker.folder(),
maker.filename(base + ".jpg"),
maker.database(), # e.g., The VOC2007 Database
maker.annotation(), # e.g., Pascal VOC2007
maker.image(), # e.g., flickr
maker.size(
maker.height(str(img.shape[0])),
maker.width(str(img.shape[1])),
maker.depth(str(img.shape[2])),
),
maker.segmented(),
)
bboxes = []
labels = []
for shape in label_file.shapes:
if shape["shape_type"] != "rectangle":
print(
"Skipping shape: label={label}, "
"shape_type={shape_type}".format(**shape)
)
continue
class_name = shape["label"]
class_id = class_names.index(class_name)
(xmin, ymin), (xmax, ymax) = shape["points"]
# swap if min is larger than max.
xmin, xmax = sorted([xmin, xmax])
ymin, ymax = sorted([ymin, ymax])
bboxes.append([ymin, xmin, ymax, xmax])
labels.append(class_id)
xml.append(
maker.object(
maker.name(shape["label"]),
maker.pose(),
maker.truncated(),
maker.difficult(),
maker.bndbox(
maker.xmin(str(xmin)),
maker.ymin(str(ymin)),
maker.xmax(str(xmax)),
maker.ymax(str(ymax)),
),
)
)
if not args.noviz:
captions = [class_names[label] for label in labels]
viz = imgviz.instances2rgb(
image=img,
labels=labels,
bboxes=bboxes,
captions=captions,
font_size=15,
)
imgviz.io.imsave(out_viz_file, viz)
with open(out_xml_file, "wb") as f:
f.write(lxml.etree.tostring(xml, pretty_print=True))
if __name__ == "__main__":
main()
运行脚本
#在jsontoxml.py同级文件夹下新建labels.txt文件
#内容为
__ignore__
_background_
drone
car
human
street sign
#根据实际标注数据类型调整
python3 jsontoxml.py --labels=labels.txt ~/darknet/train_data/VOCdevkit/VOC2007/Json ~/xmloutput
#~/darknet/train_data/VOCdevkit/VOC2007/Json 为输入文件夹 ~/xmloutput为输出文件夹
mv ~/xmloutput/Annotations/* ~/darknet/train_data/VOCdevkit/VOC2007/Annotations/
rm -r ~/xmloutput修改~/darknet/scripts/xml2voc.py
import os
import random
trainval_percent = 1 # trainval数据集占所有数据的比例
train_percent = 0.7 # train数据集占trainval数据的比例
xmlfilepath = '../train_data/VOCdevkit/VOC2007/Annotations/'
txtsavepath = '../train_data/VOCdevkit/VOC2007/ImageSets/Main/'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num*trainval_percent)
tr = int(tv*train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open(txtsavepath + 'trainval.txt', 'w')
ftest = open(txtsavepath + 'test.txt', 'w')
ftrain = open(txtsavepath + 'train.txt', 'w')
fval = open(txtsavepath + 'val.txt', 'w')
for i in list:
name = total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()python3 ~/darknet/scripts/xml2voc.py#运行生成test.txt train.txt val.txt生成voc的label文件
将~/darknet/scripts/voc_label.py修改为以下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
classes = ["drone", "car", "human", "street sign"]
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or (difficult is not None and int(difficult)==1):
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt > train.txt")
并将其复制到train_data目录下,并运行
cp ~/darknet/scripts/voc_label.py ~/darknet/train_data/
python3 ~/darknet/train_data/voc_label.py最后格式如下
----train_data\
|----2007_test.txt
|----2007_train.txt
|----2007_val.txt
|----train.txt
|----VOCdevkit\
| |----VOC2007\
| | |----Annotations\
| | | |----00000001.xml
| | |----ImageSets\
| | | |----Main\
| | | | |----test.txt
| | | | |----train.txt
| | | | |----val.txt
| | |----JPEGImages\
| | | |----00000001.jpg
| | |----labels\
| | | |----00000001.txt
|----voc_label.py













 221
221











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









