






自动驾驶车道线检测具备重要的学术价值以及工程价值,由于在精度以及速度性能上还有很多改进空间,近年来成为学术好方向,如果你想在该方向发表文章或者实现落地,请看本文CLRNet的技术拆解,希望能给你带来帮助,欢迎探讨。

论文链接:
https://arxiv.org/pdf/2203.10350.pdf
代码链接:
https://github.com/Turoad/CLRNet
一、研究动机
车道线检测是一个需要具备高级语义、全局上下文以及局部特征的任务。这是因为车道线的形态又长又细,具有简单的局部模式,而现实场景中常常出现遮挡、光照、车道线磨损等挑战,使得检测出现困难。因此,高层特征(具备全局语义)和底层特征(具备细节信息,定位更准确)信息对于准确的车道检测是互补的。以前的工作要么对车道的局部几何结构进行建模并将其集成到全局结果中,要么构建一个具有全局特征的全连接层来预测车道线。这些检测器已经证明了局部或全局特征对于车道检测的重要性,但它们没有同时利用这两种特征,从而产生不准确的检测性能。CLRNet[1]从该角度出发,提出跨层优化的车道线检测方案。以下为车道线检测存在的问题分析

a)车道线本身存在奇异,导致训练回归的目标也存在不唯一性; b)车道线的偏移量回归不准确,导致在上采样的过程中存在偏移的问题;c, d)由于遮挡、光照条件、车道线磨损等情况导致车道较难检测;
二、创新点
1.针对高层特征与底层特征的利用,本文提出一种coarse-to-fine的机制,利用高层特征检出车道线,利用低层特征调节车道线位置,整体框架称为CLRNet。
2.针对无视觉线索问题(如图c,d),本文提出RoIGather模块获取全局语义信息。
3.提出Line IoU loss,把车道线作为一个整体来优化
三、技术拆解
1. 整体结构
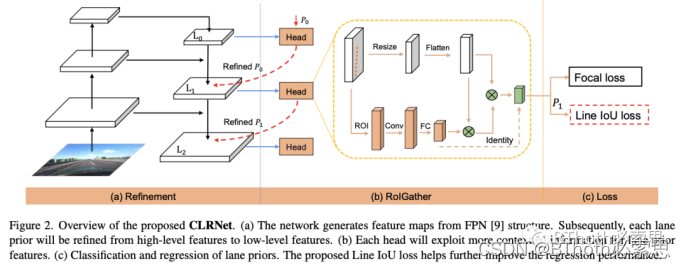
图1. CLRNet结构
CLRNet整体上分为三大部分,第一是Refinement,这块结构参考FPN(特征金字塔)[2]、Cascade RCNN[3],第二是RoIGather,第三是损失函数,包含Focal loss[4], Line IoU loss
2. The Lane Representation
理解该文章,首先得理解车道线是如何表征的。文章提出车道先验信息的概念Lane Prior,具体为沿着图像高度方向进行等间隔采样,如下图所示
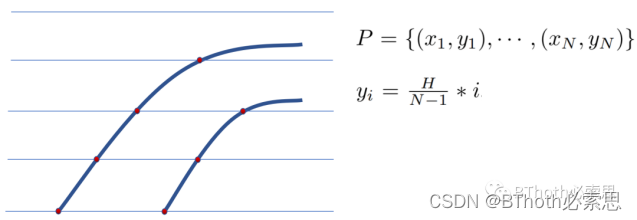
图2. 车道线表征
其中,H为图像高度,N为采样个数,设为72,这样就可以算出间隔,H/(N-1),然后实验时输入图像resize为高300,宽800,然后采样了36个点,不是全部点都采样。得到P的纵坐标集合y,而x的集合则是根据y与车道线的相交得到,如图红点所示。总之,Lane Prior的表征包含以下信息,可以用一个数组或者列表表达:
(1)第一维,前景和背景概率,用于判断是否车道线
(2)第二维,车道长度先验
(3)第三维,车道线的起点与车道x轴之间的夹角(记为x、y、θ)
(4)第四维,N个偏移量,即预测值与GT真值之间的水平距离,根据起点以及偏移量,其他车道线的点就都可以计算得到。
以上的车道线表征方法大家有没有看出什么问题?这种方法对于直道是友好的,但是对于弯道,可能会出现弯道落在间隔中没有被采样到,连GT都没有包含弯道的信息,训练出的模型对弯道检测自然不能很好地处理到
3. Refinement
Refinement的方法采用的FPN(特征金字塔)[2],这样可以获取到多尺度的特征信息,FPN的输出特征为{L0,L1,L2},而Refined操作是怎么实现的呢。其实是参考了Cascade RCNN[3],大家看看Cascade RCNN的结构图3.
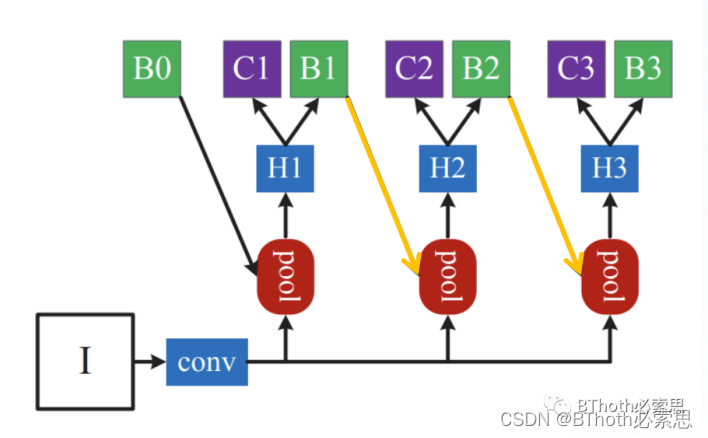
图3. Cascade RCNN结构
图3中检测头C1(分类)、B1(回归位置)学习到良好的物体类别以及位置信息,通过级连方式(黄色箭头)传递特征分布信息到其他检测头,这样便实现了Refined操作,实现更加精准的检测。而CLRNet的Refinement参考了这个思路,具体操作如公式所示,{R0,R1,R2}代表经过优化后的特征
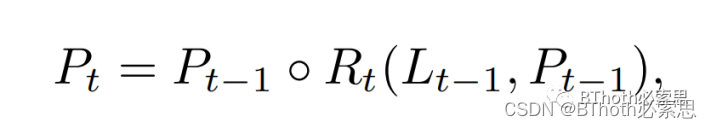
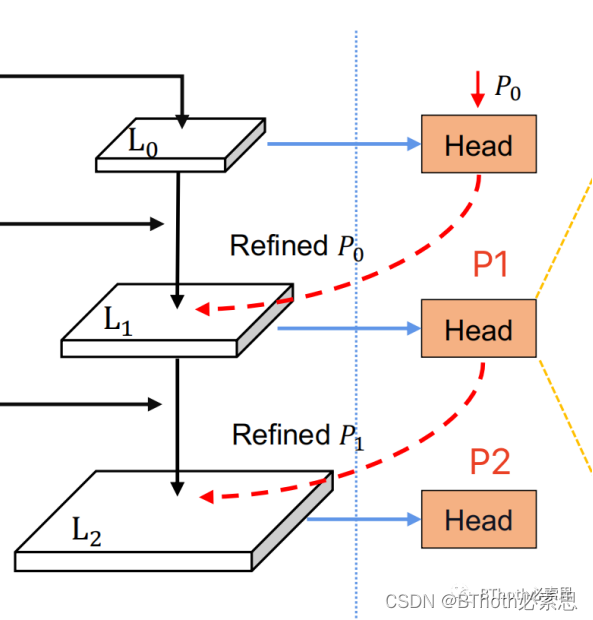
图4. Refinement结构
(1)CLRNet提出了一个从粗到细的refine结构,事实上refine的是anchor,也就起始点(x、y、θ)三个参数。P0从初始化的三参数开始,用梯度不断更新,因此称之为可学习anchor。每次迭代中,从P0开始,不断地refine anchor的三参数。P0 anchor+L0特征,首先将预测得到的, 重新根据直线方程计算72个点。新的72个点(注意,不是原来的)+预测的offset得到完整的72个点。获得192个78维的车道线预测,通过loss模块提供监督信号。
(1)上面的以及新的72个点组成新的anchor,称为图中的Refined P0,Refined P0 anchor+L1特征更新anchor参数,并获得车道线预测,通过loss模块提供监督信号。
(3)上面更新的anchor ,称为图中的Refined P1, Refined P1 anchor+L2特征 同样获得车道线预测,通过loss提供监督信号。推理时,这个结果就是最终的预测。
4. RoIGather
RoIGather为了节省运算量,对特征图谱进行resize到指定维度,整个过程的计算公式以及结构如下图,这里参考了transformer的self-attention[4]

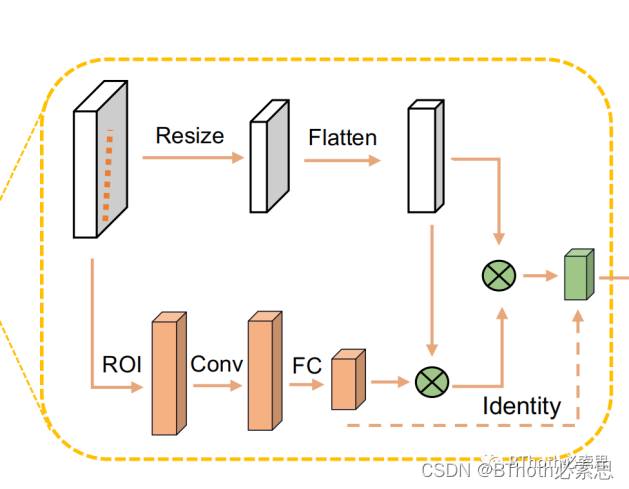
图5. RoIGather结构
5. Line Iou Loss
看到论文里Line Iou Loss的介绍,可能会觉得费解,其实这里的思想是借鉴了目标检测Iou的计算思路,请看图解6。

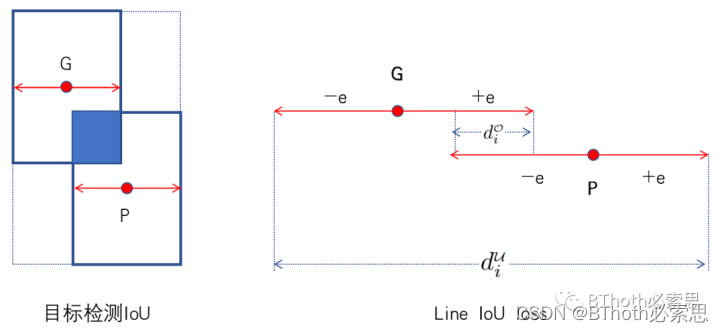
图6. Line IoU loss
如图6,上面是Line IoU的解释,定义了车道线的真值点G以及预测点P,然后用-e, +e对横坐标x进行左右偏移,形成一条线段,e设为15。整个Line Iou Loss的计算公式如上所示,其实如下面图Line IoU loss表达的,是两条线段的交集除以并集。我们回想下目标检测Iou是怎么计算的,两个框的交集除以两个框形成的最小闭包面积,如图目标检测IoU展示。如果我们记真值框的中心点为G,预测框的中心点为P,当两个框的高变为1,那这两个框就变成一条线段,框的中心点到左右两边的距离是一样的,就与Line IoU 的-e,+e是一样的。因此Line IoU loss其实是从目标检测的IoU计算思路演变过来的,这样是不是很好理解了。
三. 实验结果
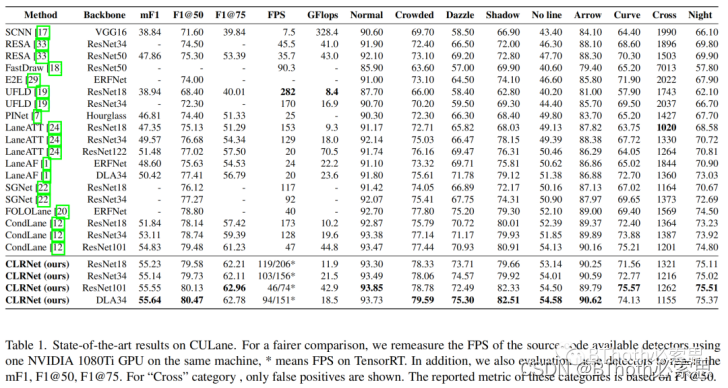
CLRNet在tusimple、culane、llamas三个数据集取得sota效果,如下表为culane结果,速度性能采用TensorRT测试,不是在pytorch里测试的,这个会快很多。而且TensorRT里实现grid-sample这个算子不容易做,缺乏TensorRT经验的同学了解就好
四. 总结
CLRNet结合high-level跟low-level特征,提出Refinement的操作进行优化,然后RoIGather获取全局语义信息,设计Line Iou loss,在车道线检测取得sota,文章亮点挺多,但仔细琢磨,也存在一些改进的地方。想要发文章的同学可以从这些点入手,或者联系BThoth获取更多想法:
(1)等间隔采样策略对弯道不友好,设计更加全面的车道线表征尤其重要
(2)backbone思想可以借鉴yolo策略,做到更快更好
(3)损失函数改进
BThoth介绍
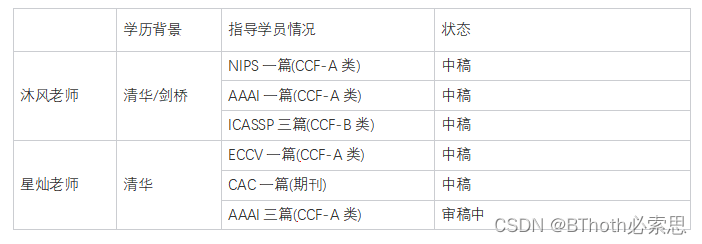
BThoth必索思,我们团队是来自清华剑桥的优秀硕博、博士后,具备丰富的学术工程经验,如果你想提升自己的ai学术工程能力,那就关注我们吧。报名成功后可以发起老师meeting,验证学历背景、论文成果等,专业、真实、值得信赖。截至10月上榜老师战绩情况如下:
联系方式:
微信号:BThoth 微信公众号: BThoth必索思
参考文献
[1]Zheng, T., Huang, Y., Liu, Y., Tang, W., Yang, Z., Cai, D., & He, X. (2022). Clrnet: Cross layer refinement network for lane detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 898-907).
[2]Lin, T. Y., Dollár, P., Girshick, R., He, K., Hariharan, B., & Belongie, S. (2017). Feature pyramid networks for object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2117-2125).
[3]Cai, Z., & Vasconcelos, N. (2019). Cascade R-CNN: High quality object detection and instance segmentation. IEEE transactions on pattern analysis and machine intelligence, 43(5), 1483-1498.















 349
349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









