






最近工作中接触了不少离线跑批系统,虽然它们业务不同,但设计思路却是相同的。
我梳理了设计思路并分享了一个简单案例,一起来看看吧。
01
背景
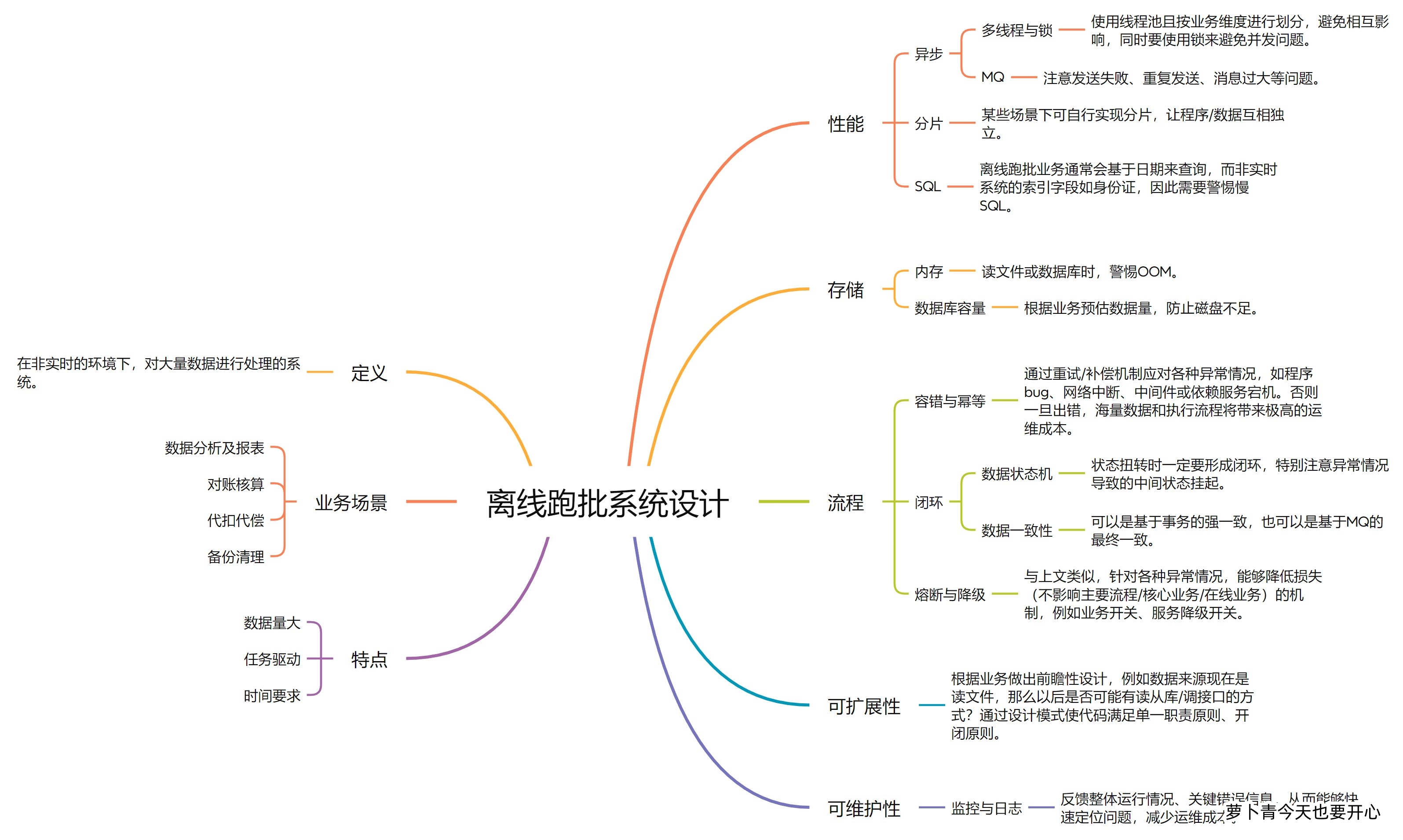
1.定义
在非实时的环境下,对大量数据进行处理的系统。
2.业务场景
-
数据分析及报表
-
对账核算
-
银行卡代扣
-
文件备份清理
-
……
3.特点
-
数据量大
-
任务驱动:由定时任务触发。
-
时间要求:通常需要在某个时间点前完成业务处理。
正是这些特点,对离线跑批系统的设计提出了独特的要求,例如数据量大,则要考虑存储问题;任务驱动,则要考虑流程设计的方方面面;数据量大+时间要求,则需要对性能进行考量。
02
设计要点
1.存储
-
内存
读取文件或数据库时,留意内存大小,警惕 OOM 。
-
数据库容量
根据业务情况预估数据量,该扩容就提前扩好容,防止磁盘空间不足。
2.性能
-
异步
- 多线程:使用线程池且按业务维度进行划分,避免相互影响,同时要使用锁来避免并发问题。
- MQ:注意发送失败、重复发送、消息过大等问题。
-
分片
某些场景下可自行实现分片,让程序或数据之间互相独立。
-
SQL
离线跑批业务通常会基于日期来查询,而非实时系统的索引字段如id、身份证,因此需要留意有无慢 SQL ,做好 SQL 优化。
3.流程
-
容错与幂等
通过重试/补偿机制应对各种异常情况,如程序 bug 、网络中断、中间件或依赖服务宕机。否则一旦出错,海量数据和执行流程将带来极高的运维成本。
-
闭环
- 数据状态机:状态扭转时一定要形成闭环,特别注意异常情况导致的中间状态挂起。
- 数据一致性:可以是基于事务的强一致,也可以是基于 MQ 的最终一致。
-
熔断与降级
与上面类似,针对各种异常情况,能够降低损失(不影响主要流程/核心业务/在线业务)的机制,例如业务开关、服务降级开关。
4.可扩展性
根据业务做出前瞻性设计,例如数据来源现在是读文件,那么以后是否可能有读从库/调接口的方式?
是否已满足单一职责原则、开闭原则?是否需要使用一些设计模式?
5.可维护性
做好日志打印与监控告警,要反馈整体运行情况、关键错误信息,从而能够快速定位问题,减少运维成本。
ok,现在我们已经熟悉离线跑批系统的设计要点了,来看个具体的案例吧。
03
案例
某天,业务提了这样一个需求:
“做一个系统,对某业务数据进行存储、计算及报表展示。某数据团队会通过文件提供基础数据,数据量大约三千万。”
此时,我们脑海中应该会浮现出以下问题:
-
业务想要这个报表的原因是什么,或者说这个数据有什么价值?
-
此需求自身承接是否合理?还是应该让数据团队承接?
-
是否只能通过文件交互?是否可根据某种规则拆分文件?
-
推送的数据是增量还是全量?预估推送完成时间是多久?预估下数据量的增长趋势是怎么样的?
-
确认文件传输完成标识,文件地址、路径、格式,数据格式、分隔符?
-
具体数据计算逻辑?
-
……
假设以上问题都已得到答案,我们稍加思考,至少可以得到以下方案:
| 方案 | 优缺点 |
| A:单机读文件,单机批量数据入库。 | 系统复杂度低; 耗时长。 |
| B:单机读文件,发送 MQ ,多机消费入库。 | 系统复杂度中; 耗时中。 |
| C:单机多线程读文件,发送 MQ ,多机消费入库。 | 系统复杂度高; 耗时短。 |
| D:拆分文件,多机读多文件,发送 MQ ,多机消费入库。 | 系统复杂度中; 需要外部配合; 耗时短。 |
可以看到,不同的方案通常是在性能和系统复杂度上做取舍。想要极致的性能,那么系统复杂度一定高,对开发的要求也更高,系统出问题的概率也会变大。
我的建议是选择满足性能要求的,复杂度最低的方案。
(是否满足性能要求,要根据性能测试结果、对方提供文件时间点、业务方期望完成时间等综合判断)
接下来我们以方案B为例,简单展开一下。

前面性能、存储都已讨论过了,通过每次仅处理少量文件行数来防止 OOM ,以及因为单线程读文件,也不涉及多线程和锁的问题,所以重点看看流程。
这里注意文件解析任务、统计数量任务都要能支持重跑(手动传参执行),同时还有一个 MQ 发送失败的补偿任务,这样在各种异常情况下,程序都能够处理,另外,通过数据库唯一索引来保证幂等。
当然,别忘了最后一块拼图——日志打印与监控告警,我们需要根据实际业务情况,配置好定时任务执行时间,以及理论上应该执行完成的时间,针对“数据团队是否推送文件”、“应用是否读完文件”、“应用是否消费完 MQ ”、“当日跑批整体情况”进行监控告警,以便第一时间发现问题。


原文链接:如何设计离线跑批系统
原创不易,点个关注不迷路哟,谢谢!
文章推荐:















 1476
1476











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









