







一、残差连接是什么?
残差连接(Residual Connection)是一种在深度学习领域,特别是在深度神经网络架构设计中的关键技术。它最初由何凯明等人在2015年的论文《Deep Residual Learning for Image Recognition》中提出,并应用于ResNet(Residual Network)中,极大地推动了深度神经网络的发展,尤其是在图像识别任务上的突破。
残差连接的核心思想是引入“捷径”或“跳过连接”,它允许输入信号可以直接传递到网络的较深层,而不仅仅依赖于逐层前向传播的计算结果。具体实现上,某个层的输入不仅经过一系列的非线性变换(如卷积、ReLU激活等),其原始输入还会绕过这一系列变换,然后与变换后的输出相加。数学上可以表示为 H(x) = F(x, W) + x,其中 x 是输入,F(x, W)是包含一组可学习参数W的一系列层的组合,H(x)是最终输出,即网络要学习的是残差映射而不是原始的全映射。
这种结构有助于解决随着网络加深带来的梯度消失问题。因为在反向传播过程中,梯度可以通过捷径直接回传到浅层,无需经过所有层级的非线性激活函数的连续链式法则,从而缓解梯度消失或梯度爆炸的风险,使得优化更加稳定,进而允许构建和训练出更深层次的神经网络。此外,残差连接还有助于特征重用,增强浅层特征在网络较深层级的重要性,从而提升模型的学习能力和泛化能力。
二、MLP是什么?
多层感知机(Multilayer Perceptron, MLP): 在机器学习和人工智能领域,MLP是指一种前馈型神经网络,它是人工神经网络(Artificial Neural Network, ANN)的一种常见形式。MLP至少包含一个隐藏层,除了输入层和输出层外,还可以有多层非线性处理单元,这些单元之间采用全连接的方式。通过反向传播算法进行训练,MLP能够用于分类和回归等多种预测任务,因其具有良好的非线性建模能力而在许多领域中广泛应用。
三、前馈型神经网络和循环神经网络
前馈型神经网络(Feedforward Neural Networks, FNNs)和循环神经网络(Recurrent Neural Networks, RNNs)是两种不同类型的神经网络结构,它们在设计、用途和处理数据的方式上有显著区别:
前馈神经网络(FFNNs)
-
结构:前馈神经网络具有严格的层次结构,信息从输入层开始,通过一系列隐藏层处理,并在输出层得出最终结果。每一层的神经元只与下一层神经元连接,不存在任何反馈回路或循环路径,故称为“前馈”。
-
数据处理:这类网络主要用于处理固定长度的输入,并一次性计算输出。它不保留历史信息,每个神经元的输出只取决于当前时刻的输入值。
-
应用:前馈神经网络常用于图像识别、语音识别、自然语言处理中的分类和回归任务等,尤其擅长处理空间或时间上不具顺序依赖性的数据。
循环神经网络(RNNs)
-
结构:循环神经网络的独特之处在于它们具有时间维度上的循环连接,允许信息在网络中循环流动,让神经元不仅可以接受当前时刻的输入,还能考虑之前时刻的信息。换句话说,每个神经元的输出不仅取决于当前时刻的输入,还取决于其在前一时刻的隐藏状态。
-
数据处理:RNN非常适合处理序列数据,如文本、音频或视频序列,因为它们有能力捕获时间序列中的长期依赖关系。每一个时间步长的输出都会作为下一个时间步长的输入的一部分。
-
应用:循环神经网络广泛应用于自然语言处理(如文本生成、翻译、情感分析)、语音识别、机器翻译、音乐生成等领域,以及其他任何需要考虑时间序列上下文的任务。
总结起来,前馈神经网络是一种无记忆的、单向传播信息的网络结构,而循环神经网络则具有内在的记忆机制,能够处理和学习序列数据中的动态变化和模式。
四、RNN的早期结构和encoder-decoder架构
在深度学习时代早期,人们使用RNN(循环神经网络)来处理机器翻译任务。一段输入先是会被预处理成一个token序列。RNN会对每个token逐个做计算,并维护一个表示整段文字整体信息的状态。根据当前时刻的状态,RNN可以输出当前时刻的一个token。
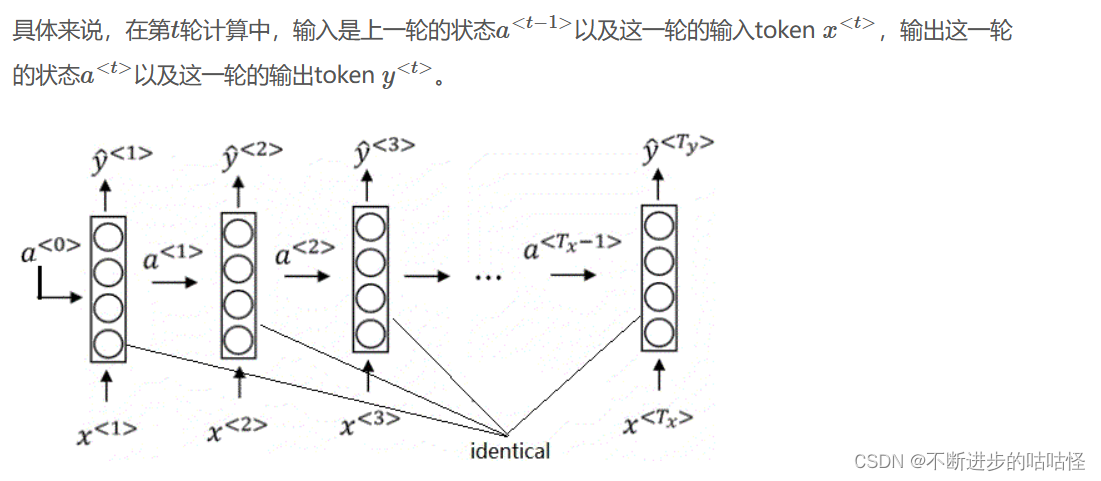
这种简单的RNN架构仅适用于输入和输出等长的任务。然而,大多数情况下,机器翻译的输出和输入都不是等长的。因此,人们使用了一种新的架构。前半部分的RNN只有输入,后半部分的RNN只有输出(上一轮的输出会当作下一轮的输入以补充信息)。两个部分通过一个状态
来传递信息。把该状态看成输入信息的一种编码的话,前半部分可以叫做“编码器”,后半部分可以叫做“解码器”。这种架构因而被称为“编码器-解码器”架构。
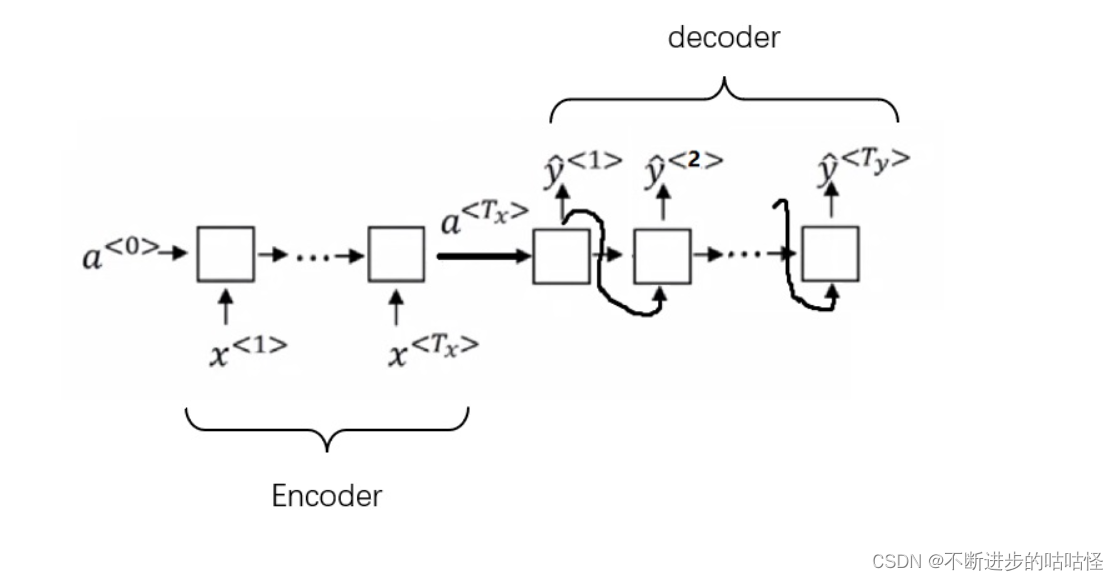
五、注意力机制
1、自注意力机制(Self-Attention Mechanism)
一种在自然语言处理中常用的技术,主要用于捕捉输入序列内部元素之间的关系。与传统的注意力机制不同,自注意力机制不需要依赖外部目标(Target),而是在输入序列内部进行计算。
在传统的循环神经网络(RNN)或长短期记忆网络(LSTM)中,隐藏状态只能依赖于前一时刻的状态和当前时刻的输入,而自注意力机制克服了这种局限性,它让序列中的每个元素都有机会直接参考序列内的所有其他元素。
自注意力机制的核心思想是计算输入序列中每个元素与其他元素之间的关联程度,进而对输入序列进行加权表示。这种机制可以帮助模型捕捉到长距离依赖关系,从而更好地理解输入序列的结构和语义信息。
自注意力的基本工作原理包括以下几个步骤:
- 将输入序列通过不同的线性变换分别映射成三个向量:查询(Query)、键(Key)和值(Value)。
- 计算Query与Key的点积或相关度得分,经过softmax函数归一化后得到每个位置对其他所有位置的注意力权重。
- 使用得到的注意力权重对Value向量进行加权求和,生成每个位置的新向量,即自注意力上下文向量。
通过这种方式,Transformer可以自动地学习到输入序列之间的依赖关系,并且不需要像RNN那样递归地更新状态。此外,Transformer还引入了多头注意力机制,即将输入序列分为多个子序列,分别计算注意力权重,并将结果合并起来,进一步提高了模型的表达能力。
2、多头注意力机制(Multi-Head Attention Mechanism)
多头注意力机制(Multi-Head Attention)是一种在Transformer架构中被提出的创新设计,它极大地提升了处理序列数据(如自然语言)时的模型性能和效率。下面是对多头注意力机制的详细解释:
多头注意力是对自注意力机制的一个扩展和改进,它不是只执行一次注意力运算,而是并行地执行多次独立的注意力运算,每一个被称为一个“头”(head)。每个头都具有自己的Query、Key和Value投影矩阵,因此它们可以从不同的子空间角度关注输入序列的不同方面。
这种方法在Transformer架构中被广泛采用,并在多项自然语言处理任务如机器翻译、文本分类、问答系统等方面取得了显著成果。
步骤:
- 投影映射:原始的Query、Key和Value首先通过不同的线性变换矩阵,生成多个子空间的版本,比如如果设置有ℎh个头,那么对于每个输入位置都会得到ℎh组Q、K、V向量。
- 并行计算:在每个注意力头上独立地执行自注意力计算。每个头都会基于各自的Query和Key计算注意力得分,然后使用softmax函数得到归一化的注意力权重,接着用这些权重去加权对应的Value向量。
- 汇总输出:各个头计算出的注意力输出(加权后的Value向量)会被拼接在一起,然后再次通过一个线性层(也称为合并层或输出层)来整合这些信息,生成最终的注意力输出向量。
优势:
- 多样性和丰富性:多头注意力允许模型从不同的角度和特征子集上审视输入序列,因此能够捕捉到更为复杂和多元的依赖关系。
- 并行计算:由于每个头的注意力计算相互独立,可以有效地利用现代计算设备的并行计算能力,提升计算效率。
- 更好的表征学习:通过结合不同头部学到的信息,模型能构建更为全面且具有层次感的上下文表征。
六、激活函数
激活函数作用和重要性
激活函数是神经元内部的一个非线性运算单元,负责将神经元接收的加权输入信号转化为输出信号。在单个神经元层面上,激活函数的作用在于对输入信号进行非线性变换,从而使得整个网络具备更强大的表达能力和学习非线性关系的能力。
没有激活函数的多层神经网络本质上仅仅是线性模型的堆叠,无法捕捉复杂的模式。激活函数引入了非线性,使得即使在网络的深层结构中,组合的多层神经元也可以实现复杂的决策边界和抽象特征的学习。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









