









一,题目
Weakly Supervised Sequence Tagging from Noisy Rules
基于噪声规则的弱监督序列标注
Safranchik E , Luo S , Bach S . Weakly Supervised Sequence Tagging from Noisy Rules[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(4):5570-5578.
Department of Computer Science
Brown University Brown University
Brown University 布朗大学
Providence, RI, USA
二,摘要
提出两个内容:
1.提出了一个弱监督训练序列标注模型框架;提出了linking rules;
[linking rules的作用是,在token标注的内容的基础上,判断spans,即实体的跨度]
2.对于解决规则准确性与冲突,提出linked hidden Markov models (linked HMMs);
三,背景
希望用弱监督来解决NER问题;
引入规则来代替手工带来的问题:
- 规则具有未知的准确性,如何解决相互冲突的投票也不清楚。
- 解决冲突时应该考虑统计依赖关系;
- 独立启发式应注意相邻距离问题;
现在有的方法[3][4]:
把相关任务转化成分类任务。首先从序列中生成候选跨度,然后独立标记每个候选。
缺点:
第一,限制用户执行已存在有效候选生成器的任务; 第二,明显增加了所需的人力投入;
生成侯选法没有label启发好:
第一,生成需要假设有好的召回率;
第二,对于overlapping的情况,会进出不一致的输出;
论文贡献–提出一个新的框架的创新点:
- 提出linking rule这个新概念;
- 提出一个新的生成模型linked hidden Markov models (linked HMMs);
- 一种序列标注的噪声感知损失函数;
四,序列标注的规则 – Tagging Rules & Linking Rules
输入两个内容: 没有标注的数据,规则
输出:对应句子的标注序列;
规则分成两类:Tagging Rules & Linking Rules
Tagging Rules标注正确的序列元素;
Linking Rules相邻元素是否是相同标注。
IO标签方案:

Tagging Rules
思想与 Snorkel framework相类似。
经过函数之后:

‘SAME’ indicating that the corresponding pair of elements should have the same tags,
‘DIFF’ indicating they should be different,
‘ABS’ indicating that the rule abstains.
一些规则:

五,Linked Hidden Markov Models
略
六,实验结果
实验1 - NER
数据集:
-
BC5CDR:
500 train, 500 development, and 500 test PubMed articles
15,953 chemical mentions and 13,318 disease mentions -
NCBI Disease:
包含PubMed摘要与6866种疾病mentions的文章,划分为592(train),100(dev),100(test); -
LaptopReview
3,845 sentences and 3,012 mentions
方法模型
AutoNER:使用特定领域词典学习命名实体标记,这个论文提出了两个神经网络模型来解决远程监督的noise问题;tie-or-break scheme,这个方案其实就是判断两个连接的tokens是否是连在一起的,还是分开的;
Snorkel:这个是一个一般WS模型,由斯坦福出来的,就是用户写很从LFs,它可以作评价,那些标签比较好;
Linked HMM:这个是这篇论文提出的。
Supervised Benchmark: 传统的监督学习任务;
SwellShark: 这是基本于Snorkel框架上在生物医学上NER的扩展,它要求要一个候选生成器。
结果
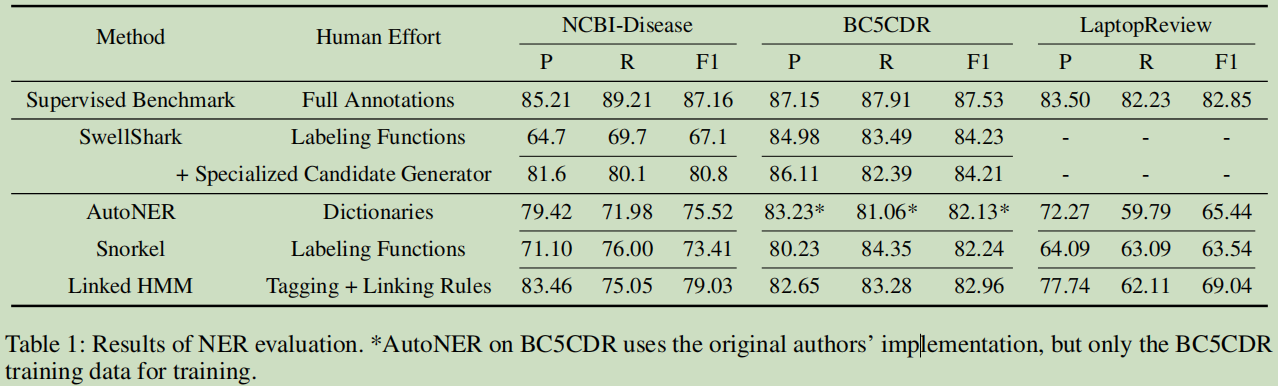
实验2-消融—提出的Linked HMM是否有提升
第一个是采用 a noise-aware bi-LSTM来训练的结果:
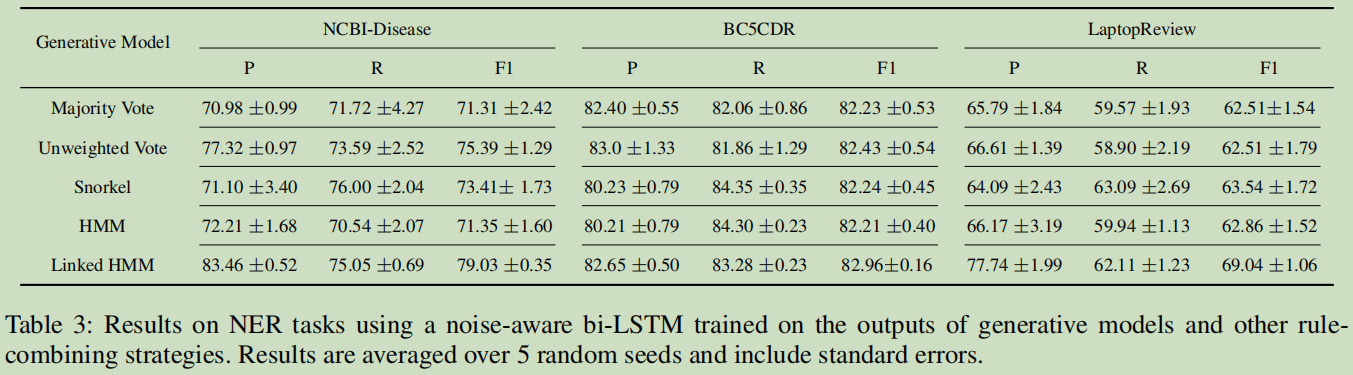
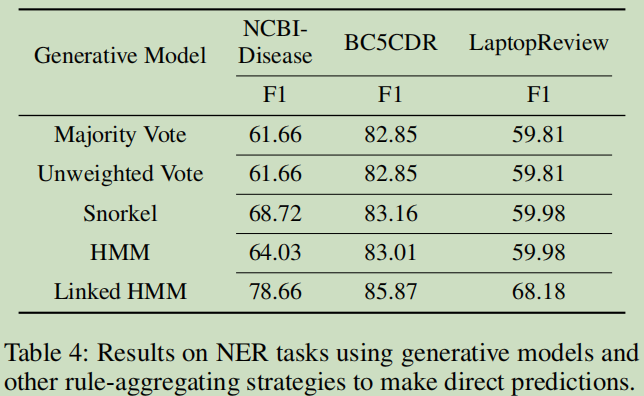
第二个只是对标注数据进行计算的结果,即是对标注进行处理,没有神经网络训练:
实验3-SRL(语义角色标签)
数据集
English Ontonotes v5.0
结果
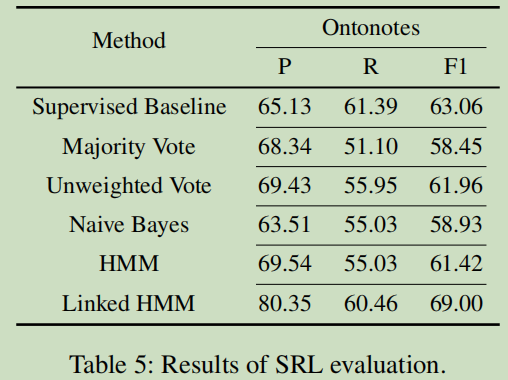
只是Linked HMM的性能超过监督基线的方法,F1提高了5.94个点。在这个实验中,Bayes是最差的一个模型了。
七,代码
7.1 labelmodels
生成模型包。
https://github.com/BatsResearch/labelmodels
Lightweight implementations of generative label models for weakly supervised machine learning
一个来自官网方的例子
# -*- coding: utf-8 -*-
# 假设投票是一个m x n矩阵,其中m是数据示例的数量,n是标签源的数量,每个元素都在集合{0,1,…, k},其中k是类的数量。
# 如果votes_{ij}为0,表示标签源j对样本i投票弃权;
# 举一个例子,对于二分类创建一个随机投票矩阵,例子中有1000个样本和5个标签源;
import numpy as np
votes = np.random.randint(0, 3, size=(1000, 5))
# 创建一个Naive Bayes生成模型去评估标签源的准确性
from labelmodels import NaiveBayes
# 初始化模型,指定2个类与5个标签源
model = NaiveBayes(num_classes=2, num_lfs=5)
# 然后,评估模型参数
model.estimate_label_model(votes)
print("标签源的精确率分布:\n", model.get_accuracies())
# 得到真实标签上的后验分布
labels = model.get_label_distribution(votes)
print("真实标签的后验分布:\n",labels)
运行结果:
标签源的精确率分布:
[[0.70593973 0.7510982 ]
[0.71339318 0.74762443]
[0.72823547 0.73560533]
[0.73060083 0.68081382]
[0.74447731 0.73926738]]
真实标签的后验分布:
[[0.29740885 0.70259112]
[0.75221914 0.24778081]
[0.22863835 0.77136165]
...
[0.94513512 0.05486495]
[0.99281138 0.00718864]
[0.45150739 0.54849255]]
7.2 wiser – Weak and Indirect Supervision for Entity Recognition
https://github.com/BatsResearch/wiser
说到底这个github是论文的弱监督系统的实现。
a system for training sequence tagging models, particularly neural networks for named entity recognition (NER) and related tasks. WISER uses weak supervision in the form of rules to train these models, as opposed to hand-labeled training data.
wiser中自带的例子就比较好.
分了三个文件:
文件1:Tagging and Linking Rules; 根据规则函数来标注数据;
文件2:Generative Models; 生成模型来处理上面标注的数据;
文件3: Neural Networks ; 训练最后的模型-- 用allennlp来计算;
7.3 论文相关代码
https://github.com/BatsResearch/safranchik-aaai20-code
这个代码是论文提到实验,它依赖上面那两个核心包,这数据及资源还是比较重要的。
例如BC5CDR,可以看到有26个Tagging Rules,4个Linking Rules;
对于后面训练模型,会把每一步都记录下来:
例如是这样的输出:
{
"best_epoch": 27,
"peak_cpu_memory_MB": 7972.112,
"peak_gpu_0_memory_MB": 3,
"peak_gpu_1_memory_MB": 3,
"training_duration": "0:05:49.548476",
"training_start_epoch": 0,
"training_epochs": 51,
"epoch": 51,
"training_accuracy": 0.9599292869770183,
"training_accuracy3": 1.0,
"training_precision-overall": 0.7553956834532368,
"training_recall-overall": 0.7394366197183093,
"training_f1-measure-overall": 0.7473309608540419,
"training_loss": 478.4224166870117,
"training_cpu_memory_MB": 7972.112,
"training_gpu_0_memory_MB": 3,
"training_gpu_1_memory_MB": 3,
"validation_accuracy": 0.9461325966850829,
"validation_accuracy3": 1.0,
"validation_precision-overall": 0.6493506493506485,
"validation_recall-overall": 0.8064516129032245,
"validation_f1-measure-overall": 0.7194244604316041,
"validation_loss": 269.5497741699219,
"best_validation_accuracy": 0.9571823204419889,
"best_validation_accuracy3": 1.0,
"best_validation_precision-overall": 0.7058823529411754,
"best_validation_recall-overall": 0.7741935483870955,
"best_validation_f1-measure-overall": 0.7384615384614875,
"best_validation_loss": 237.91796875
}
八,总结
这个是继学习snorkel以后的又一个比较好的框架了,之前在使用snorkel时,就是不知道NER的数据应该怎么标注,这一篇给出来指导。项目中考虑使用一下这个结构预测的框架代码。
九,参考:
[1] 代码,https://github.com/BatsResearch/safranchik-aaai20-code
[2] 论文,http://cs.brown.edu/people/sbach/files/safranchik-aaai20.pdf
[3] Ratner, A. J.; Hancock, B.; Dunnmon, J.; Sala, F.; Pandey, S.; and R´e, C. 2019. Training complex models with multi-task weak supervision. In AAAI.
[4] Fries, J.; Wu, S.; Ratner, A.; and R´e, C. 2017. SwellShark: A generative model for biomedical named entity recognition without labeled data. arXiv preprint arXiv:1704.06360.
https://blog.csdn.net/ld326/article/details/117261273















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









