






正文共2965个字,估计阅读时间10分钟。
本文主要介绍GoogLeNet续作二,inception v3。说实话,Szegedy这哥们真的很厉害,同一个网络他改一改就改出了4篇论文,这是其中第3篇,还有个inception v4。
[v3] Rethinking the Inception Architecture for Computer Vision,top5 error 3.5%
随着Szegedy研究GoogLeNet的深入,网络的复杂度也逐渐提高,到了inception v3,它的复杂度已经到了普通玩家望而却步的境界,内部结构实在是太乱了,不得不佩服作者。
论文做出的贡献主要有4个:
1、分解大filters,使其小型化、多层化,其中有个“非对称卷积”很新颖
2、优化inception v1的auxiliary classifiers
3、提出一种缩小特征图大小的方法,说白了就是一种新的、更复杂的pooling层
4、Label smooth,“标签平滑”,很难用中文说清楚的一种方法
Szegedy还把一段时间内的科研心得总结了一下,在论文里写了4项网络设计基本原则:
1、尽量避免representational bottlenecks,这种情况一般发生在pooling层,字面意思是,pooling后特征图变小了,但有用信息不能丢,不能因为网络的漏斗形结构而产生表达瓶颈,解决办法是上面提到的贡献3
2、采用更高维的表示方法能够更容易的处理网络的局部信息,我承认前面那句话是我硬翻译的,principle 2我确实不太明白
3、把大的filters拆成几个小filters叠加,不会降低网络的识别能力,对应上面的贡献1
4、把握好网络深度和宽度的平衡,这个原则说了等于没说
下面分析一下论文的4个贡献:
1、Filter分解
其实大filters拆解成若干小filters叠加的方法已经在VGG里提过了,inception v3更进了一步,提出了“非对称卷积”,我在非对称卷积—Asymmetric Convolutions一文中分析过一些,在这里就不展开介绍了,概念很简单,一看就懂那种类型。
2、优化auxiliary classifiers
GoogLeNet首次提出了auxiliary classifiers,效果还行,我之前在这里介绍过。Szegedy同志在过了一年多后,又看了看这个tech,他发现有点问题:auxiliary classifiers在训练初期的时候并不能加速收敛,只有当训练快结束的时候它才会略微提高网络精度。
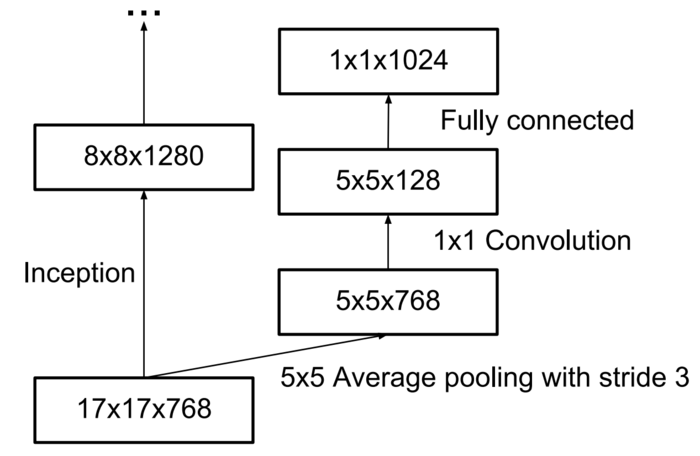
Auxiliary Classifiers
然后Szegedy就把第一个auxiliary classifiers去掉了!还说,auxiliary classifiers能够起到regularizer的作用,完全不知所云,以后有机会再看。原文如下:
Instead, we argue that the auxiliary classifiers act as regularizer. This is supported by the fact that the main classifier of the network performs better if the side branch is batch-normalized or has a dropout layer. This also gives a weak supporting evidence for the conjecture that batch normalization acts as a regularizer.
3、新的pooling层
按照传统的做法,在pooling之前,为了防止信息丢失,应当加入了expand层,如下图右半部分。
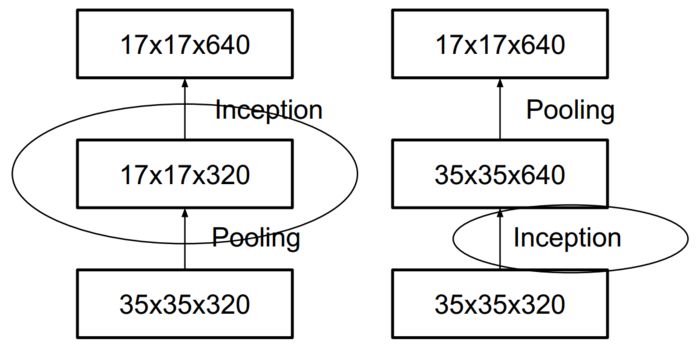
Unefficient grid size reduction
这么做有个问题,会增加运算量,于是Szegedy就想出了下面这种pooling层。
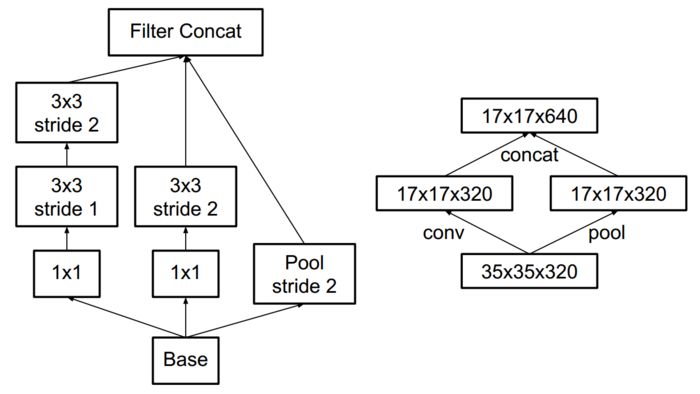
Efficient grid size reduction
是不是很复杂?想不到pooling也能玩儿出这么多花样。
上图可以这么理解,Szegedy利用了两个并行的结构完成grid size reduction,分别是conv和pool,就是上图的右半部分。左半部分是右半部分的内部结构。
为什么这么做?我是说这种结构是怎么设计出来的?Szegedy只字不提,或许这就是深度学习的魅力所在吧。
4、Lable smooth
Szegedy用了将近一页的篇幅叙述label smooth,可见这个方法有多么难理解。
深度学习用的labels一般都是one hot向量,用来指示classifier的唯一结果,这样的labels有点类似信号与系统里的脉冲函数,或者叫“Dirac delta”,即只在某一位置取1,其它位置都是0。
Labels的脉冲性质会引发两个不良后果:一是over-fitting,另外一个是降低了网络的适应性。这段话我实在没看懂,附上原文:
First, it may result in over-fitting: if the model learns to assign full probability to the groundtruth label for each training example, it is not guaranteed to generalize. Second, it encourages the differences between the largest logit and all others to become large, and this, combined with the bounded gradient, reduces the ability of the model to adapt.
Szegedy在阐述完上面两个缺点后,补充了一句话,说不良后果的产生就是因为网络对它预测的东西太自信了。完全没搞懂。
Intuitively, this happens because the model becomes too confident about its predictions.
我想起来一个美国签证官曾经跟我说过的话:“他看学术论文的时候,每个单词都认识,但所有单词拼到一起的时候,就蒙圈了。”
好了,先不管这么多,这个label smooth具体是怎么实现的?就是下式:
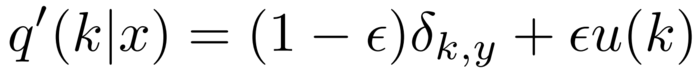
label smooth
为了方便理解,转换成python代码,就是这样的:
new_labels = (1.0 - label_smoothing) * one_hot_labels + label_smoothing / num_classes
Szegedy在网络实现的时候,令 label_smoothing = 0.1,num_classes = 1000。Label smooth提高了网络精度0.2%。
我对Label smooth理解是这样的,它把原来很突兀的one_hot_labels稍微的平滑了一点,枪打了出头鸟,削了立于鸡群那只鹤的脑袋,分了点身高给鸡们,避免了网络过度学习labels而产生的弊端。
原文链接:https://www.jianshu.com/p/0cc42b8e6d25
查阅更为简洁方便的分类文章以及最新的课程、产品信息,请移步至全新呈现的“LeadAI学院官网”:
www.leadai.org
请关注人工智能LeadAI公众号,查看更多专业文章

大家都在看
















 1674
1674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









