










工具使用基础
工具使用定义
工具使用对智能体而言至关重要,它不仅显著扩展了智能体的能力范围,使其能够高效执行如实时信息获取、复杂数据分析等高级任务,还提升了任务精度和用户体验的丰富性;此外,工具的集成增强了智能体的适应性和可扩展性,使其能够在不断变化的环境中保持灵活更新,从而更好地满足多样化的用户需求。
工具使用(也称函数调用)是指通过定义和调用外部工具或函数来扩展大模型的能力。我们可以让大模型访问一组预定义的工具,它可以在任何时候调用这些工具。工具允许我们编写代码,执行大模型无法完成的特定任务或计算。简而言之:使用工具是增强大模型功能的一种方式。
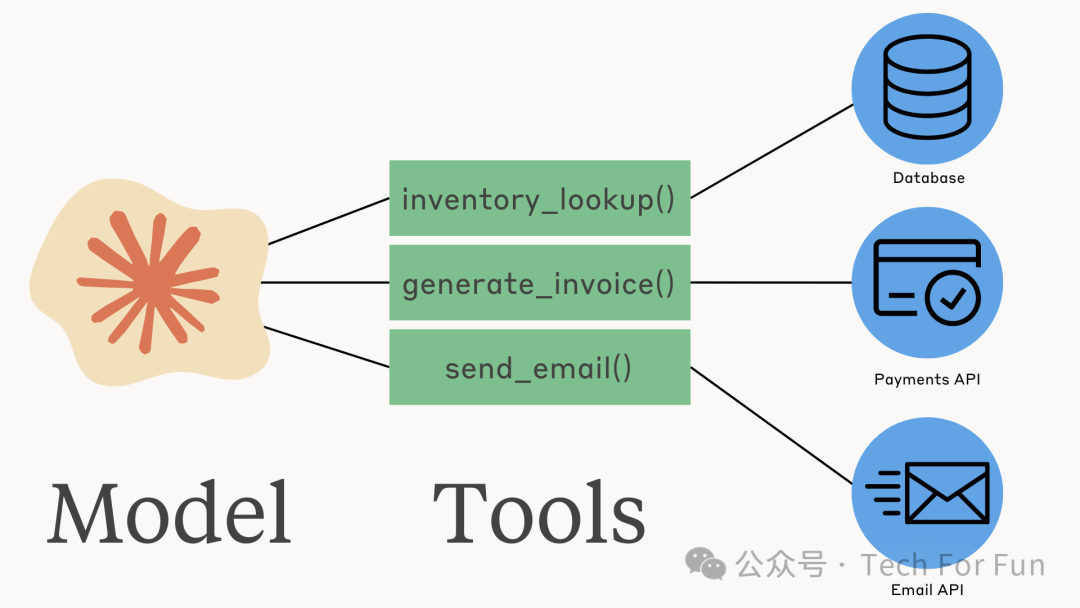
工具使用重要性
工具使用是一项能改变游戏规则的功能,它能释放大模型的真正潜能,开启一个充满可能性的世界。它是一个关键组件,可显著提升应用程序的价值和影响力。
-
扩展大模型的功能
-
通过工具使用,可以将大模型的功能扩展到其内置功能之外。通过定义和调用外部工具,可以让大模型执行它无法完成的任务。这意味着可以创建功能更强大、用途更广泛的应用程序,以满足更广泛的用户需求和要求。
-
与现有系统集成
-
工具使用可以实现大模型与现有系统、数据库或 API 的无缝集成。可以定义与后端服务交互、从数据库检索数据或在应用程序中触发操作的工具。通过这种集成,可以利用大模型的强大功能,同时使用现有的基础设施和数据。
-
自动执行复杂任务
-
通过工具使用,可以将涉及多个步骤或需要专门计算的复杂任务和工作流程自动化。通过定义封装这些任务的工具,可以简化流程、减少人工操作并提高效率。大模型可以根据用户输入或预定义条件,在正确的时间智能调用正确的工具。
-
增强用户体验
-
工具使用可以大大提升应用程序的用户体验。通过为大模型提供访问相关工具的权限,可以使其为用户查询提供更准确、更符合实际情况和更个性化的响应。用户可以使用自然语言与应用程序进行交互,而大模型则可以利用工具提供丰富的信息或代表用户执行所需的操作。
-
扩展和定制。
-
通过工具使用,可以扩展和定制应用程序,以满足用户不断变化的需求。随着用户群的扩大或需求的变化,可以轻松添加新工具或修改现有工具,以扩展大模型的功能。这种灵活性使应用程序能够快速适应和迭代,确保应用程序保持相关性和竞争力。
应用案例举例
在工具使用的客户中看到的一些通用主题包括:
-
检索信息
-
工具可用于从数据库、应用程序接口或网络服务等外部来源获取数据。例如,工具可以根据用户输入检索天气信息、股票价格或新闻文章。
-
执行计算
-
工具可以执行复杂的计算或数学运算,这可能超出了大模型的内置能力。这可能包括财务计算、科学计算或统计分析。
-
操作数据
-
工具可用于处理、转换或操作各种格式的数据。这包括数据格式化、数据提取或数据转换等任务。
-
与外部系统交互
-
工具可以促进与外部系统或服务的交互,例如发送电子邮件、触发通知或控制物联网设备。
-
生成内容
-
工具可根据用户输入或预定义模板协助生成特定类型的内容,如图像、图表或格式化文档。
更具体的可能用例包括:
-
企业数据集成:将大模型与CRM、ERP 和 ITSM 等企业系统集成,以检索客户数据、自动执行工作流程并提供个性化支持。
-
财务分析和报告:使用大模型和工具分析财务数据、生成投资报告、评估风险并确保合规性。
-
医疗诊断和治疗规划:将大模型与电子健康记录 (EHR) 和医学知识库整合,协助医疗保健专业人员做出明智的决策并制定个性化治疗计划。
-
教育辅导和内容创建:将大模型与教育资源和工具相结合,提供个性化辅导、生成学习材料并适应个人学习风格。
-
法律文件分析和审查:使用大模型和工具分析法律文件、提取关键信息、识别潜在问题并生成摘要,以简化法律流程。
-
客户支持自动化:将大模型与知识库和支持票单系统集成,以提供自动化客户支持、排除故障并缩短响应时间。
-
销售和营销自动化:将大模型与各种工具相结合,分析客户数据、生成个性化营销内容、筛选潜在客户并优化销售流程。
-
软件开发协助:将大模型与集成开发环境、版本控制系统和项目管理工具相结合,协助开发人员编写代码、识别错误并管理软件项目。
-
研究与创新:利用大模型和工具进行市场调研、分析专利数据、产生新想法并推动各行业的创新。
-
内容创建和优化:利用大模型和工具为各种平台(包括网站、社交媒体和营销活动)生成、优化和个性化内容。
接下来将以 Claude 中的工具使用为例,对工具使用的相关要点进行详细介绍。
如何使用工具
让我们来看看工具的实际使用方法。最重要的一点是,Claude 不会自己运行任何代码。我们告诉 Claude 一组它可以要求我们调用的工具,然后我们的工作就是实际运行底层工具代码,并将结果告诉Claude。
请注意,Claude 无法访问任何内置的服务器端工具。所有工具都必须由用户在每个 API 请求中明确提供。这意味着需要定义可用的工具,并提供清晰的描述和输入模式,以及实现和执行工具逻辑,例如根据 Claude 的请求运行特定函数或查询 API。这样就可以完全控制Claude可以使用的工具,并灵活地加以使用。
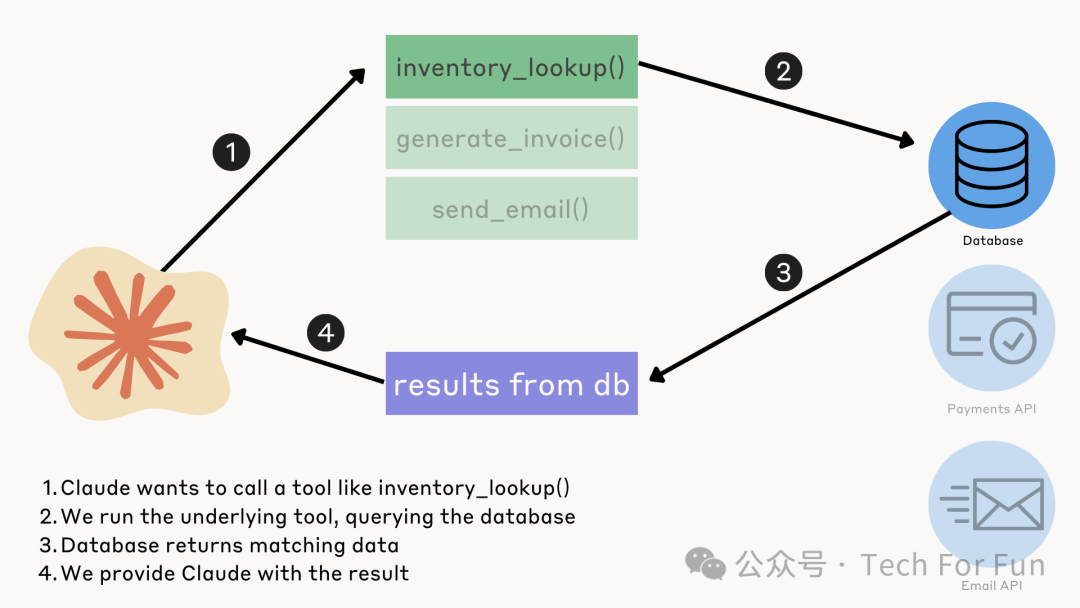
具体来说,Claude工具使用包括以下步骤:
1. 为 Claude 提供工具和用户提示词:(API 请求)
-
定义希望 Claude 访问的工具集,包括工具名称、描述和输入模式。
-
提供一个用户提示词,可能需要使用其中一个或多个工具来回答,例如 "我可以用 500 美元购买多少股通用汽车公司的股票?
2. Claude 工具使用:(API 响应)
-
Claude 会评估用户提示,并决定是否有任何可用工具可以帮助用户完成查询或任务。如果有,它还会决定使用哪种工具以及输入什么内容。
-
Claude 会输出格式正确的工具使用请求。
-
API 响应的
stop_reason将为tool_use,表明 Claude 希望使用外部工具。
3. 提取工具输入、运行代码并返回结果:(API 请求)
-
在客户端,应从 Claude 的工具使用请求中提取工具名称和输入。
-
在客户端运行实际的工具代码。
-
使用包含
tool_result内容块的新用户消息继续对话,将结果返回给 Claude。
4. Claude 将工具使用结果做出响应:(API 响应)
- 收到工具结果后,Claude 将使用该信息来制定对原始用户提示的最终响应。
步骤(3)和(4)是可选的–对于某些工作流,Claude 使用工具就能提供所需的全部信息,可能不需要将工具结果返回给 Claude。关于这一点,我们将在下一节详述。
假设工具使用场景
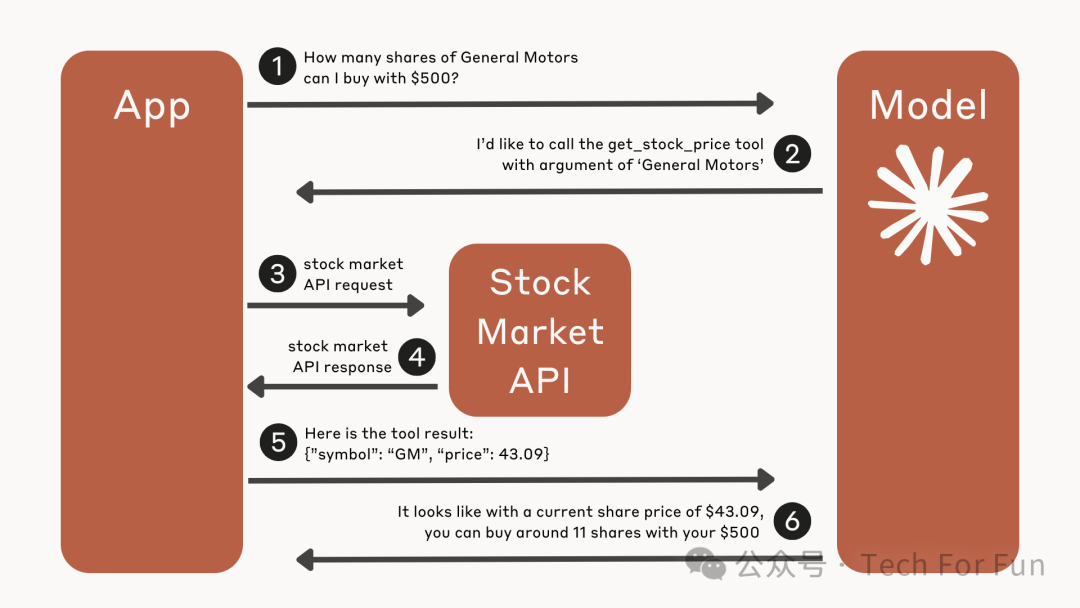
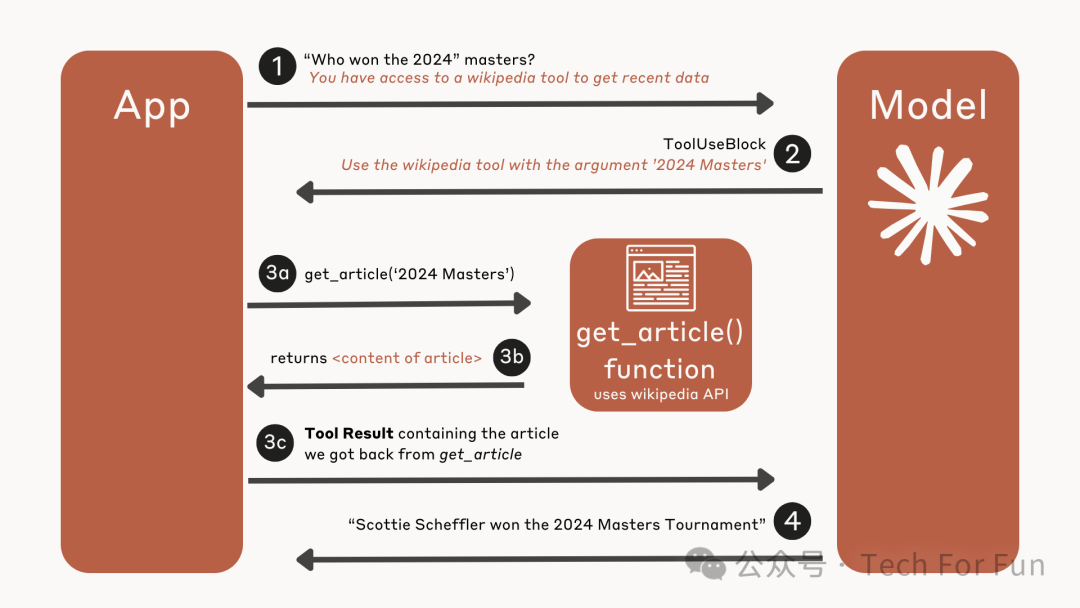
为了更好地理解工具的使用流程,设想一下,我们正在构建一个聊天应用程序,允许用户与 Claude 谈论股票市场并检索当前的股票价格。
当然,Claude 并不知道任何特定时间点的股市行情和价格,因此需要为 Claude 提供一个 get_stock_price 工具,用于检索某家公司当前的股票价格。
下面是一个简单的示意图,显示了我们的应用程序和 Claude 之间的信息流:
详细流程分解
以下是工具使用步骤的详细分解:
第 0 步:编写工具功能
在告诉 Claude 它可以访问的特定工具之前,我们首先需要编写该工具的功能。以 get_stock_price 工具为例,我们会编写一个函数,将公司名称或股票代码作为参数,然后向股票市场 API 发送请求,以获取实时股票数据。类似下面这样:
def get_stock_price(company):
#Send a request to a stock market API to lookup current stock price for a given company
#Returns a dictionary containing current stock price information for the specified company
如果完全实现了这个函数,并用 get_stock_price("General Motors") 来调用它,我们可能会得到类似下面这样的返回值:
{
"symbol”: “GM”,
"price”: 43.09
}
第 1 步:为Claude提供工具和用户提示(API 请求)
接下来,我们需要定义 get_stock_price 工具的名称、描述和输入模式。我们稍后会花更多时间来定义工具,下面是我们可以告诉Claude的一个假设的 get_stock_price 工具定义:
tool_definition = {
"name": "get_stock_price",
"description": "Retrieves the current stock price for a given company",
"input_schema": {
"type": "object",
"properties": {
"company": {
"type": "string",
"description": "The company name to fetch stock data for"
}
},
"required": ["company"]
}
}
接下来,我们会告诉 Claude 这个工具的存在,并通过提示提出可能需要这个工具的请求:
response = client.messages.create(
model="claude-3-opus-20240229",
messages=[{"role": "user", "content": "How many shares of General Motors can I buy with $500?"}],
max_tokens=500,
tools=[tool_definition]
)
步骤 2:Claude使用工具(API 响应)
Claude 收到 API 请求并评估用户提示。它认为get_stock_price 工具有助于回答有关购买通用汽车公司股票的问题。
Claude会响应格式正确的工具使用请求。我们稍后将对此进行深入探讨,下面是Claude表示 “希望” 使用我们的工具的响应示例:
{
“stop_reason”: “tool_use”,
“tool_use”: {
“name”: “get_stock_price”,
“input”: {
“company”: “General Motors”
}
}
}
第 3 步:提取工具输入、运行代码并返回结果(API 请求)
在客户端,我们从 Claude 的工具使用请求中提取工具名称(get_stock_price)和输入的公司名称(General Motors)。
我们执行实际的 get_stock_price 函数,该函数使用从 Claude 的工具请求中提取的输入,从 API 获取实时股票市场数据。函数返回的数据可能如下所示:
{
"symbol”: “GM”,
"price”: 43.09
}
然后,我们将工具的结果告诉 Claude。我们通过包含 tool_result 内容块的新用户消息继续对话,将股价工具的结果返回给Claude。
**第 4 步:Claude使用工具结果做出响应(API 响应)**Claude接收到股价工具的结果,并将实时股票市场信息纳入对原始用户提示的最终回复中,最后回复如下:
目前通用汽车股价为 43.09,你可以使用 500 美元购买大约 11 股通用汽车公司的股票。
第一个简单工具
在前面,我们介绍了工具使用 4 步工作流程。现在是时候实际操作一个简单的工具使用示例了。
我们将从一个简单的演示开始,只需要与 Claude “对话 ”一次(别担心,我们很快就会讲到更精彩的示例!)。这意味着我们先不考虑第 4 步。我们会要求 Claude 回答一个问题, Claude 会要求使用一个工具来回答这个问题,然后我们会提取工具的输入,运行代码,并返回结果值。
如今的大型语言模型在数学运算方面都很吃力,下面的代码就是明证。
我们要求 Claude “用 1984135 乘以 9343116”:
from anthropic import Anthropic
from dotenv import load_dotenv
load_dotenv()
client = Anthropic()
# A relatively simple math problem
response = client.messages.create(
model="claude-3-haiku-20240307",
messages=[{"role": "user", "content":"Multiply 1984135 by 9343116. Only respond with the result"}],
max_tokens=400
)
print(response.content[0].text)
18555375560
多次运行上述代码可能会得到不同的答案,但这是 Claude 给出的一个答案:
18593367726060
实际正确答案是 :18538003464660
Claude 偏差了 55364261400!
使用工具来解决!
Claude 并不擅长做复杂的数学运算,因此让我们通过提供计算器工具来增强 Claude 的能力。
下面是一个简单的示意图,解释了这一过程:

第一步是定义实际的计算器函数,并确保它能独立于 Claude 运行。我们将编写一个非常简单的函数,它需要三个参数:
-
一个操作,如 “加法 ”或 "乘法”
-
两个操作数
下面是一个基本实现:
def calculator(operation, operand1, operand2):
if operation == "add":
return operand1 + operand2
elif operation == "subtract":
return operand1 - operand2
elif operation == "multiply":
return operand1 * operand2
elif operation == "divide":
if operand2 == 0:
raise ValueError("Cannot divide by zero.")
return operand1 / operand2
else:
raise ValueError(f"Unsupported operation: {operation}")
请注意,这个简单函数的功能非常有限,因为它只能处理 234 + 213 或 3 * 9 这样的简单表达式。这里的重点是通过一个非常简单的教学示例来介绍使用工具的过程。
让我们测试一下我们的函数,确保它能正常工作。
calculator("add", 10, 3)
输出:
13
calculator("divide", 200, 25)
输出:
8.0
下一步是定义我们的工具,并向 Claude 介绍它。在定义工具时,我们遵循非常具体的格式。每个工具定义都包括
-
name:工具名称。必须匹配正则表达式 ^[a-zA-Z0-9_-]{1,64}$。 -
description:详细的明文描述,说明该工具的作用、使用时间和行为方式。 -
input_schema:输入模式:定义工具预期参数的 JSON 模式对象。
下面是一个假设工具的简单示例:
{
"name": "send_email",
"description": "Sends an email to the specified recipient with the given subject and body.",
"input_schema": {
"type": "object",
"properties": {
"to": {
"type": "string",
"description": "The email address of the recipient"
},
"subject": {
"type": "string",
"description": "The subject line of the email"
},
"body": {
"type": "string",
"description": "The content of the email message"
}
},
"required": ["to", "subject", "body"]
}
}
这个名为 send_email 的工具需要以下输入:
-
to:字符串,必填 -
subject:字符串,必填 -
body:字符串,必填
下面是另一个名为 search_product 的工具定义:
{
"name": "search_product",
"description": "Search for a product by name or keyword and return its current price and availability.",
"input_schema": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The product name or search keyword, e.g. 'iPhone 13 Pro' or 'wireless headphones'"
},
"category": {
"type": "string",
"enum": ["electronics", "clothing", "home", "toys", "sports"],
"description": "The product category to narrow down the search results"
},
"max_price": {
"type": "number",
"description": "The maximum price of the product, used to filter the search results"
}
},
"required": ["query"]
}
}
该工具有 3 项输入:
-
query:代表产品名称或搜索关键词的必填查询字符串。 -
category:一个可选的类别字符串,必须是预定义值之一,以缩小搜索范围。注意定义中的 “枚举”。 -
max_price:一个可选的数字,用于过滤低于某一价格点的结果。
计算器工具定义
让我们为之前编写的计算器函数定义相应的工具。我们知道,计算器函数需要 3 个参数:
-
operation- 只能是 “加”、“减”、“乘 ”或 "除” -
operand1- 应该是一个数字 -
operand2- 也应是一个数字
下面是工具定义:
calculator_tool = {
"name": "calculator",
"description": "A simple calculator that performs basic arithmetic operations.",
"input_schema": {
"type": "object",
"properties": {
"operation": {
"type": "string",
"enum": ["add", "subtract", "multiply", "divide"],
"description": "The arithmetic operation to perform."
},
"operand1": {
"type": "number",
"description": "The first operand."
},
"operand2": {
"type": "number",
"description": "The second operand."
}
},
"required": ["operation", "operand1", "operand2"]
}
}
练习
让我们以下面的函数为例,练习编写格式正确的工具定义:
def inventory_lookup(product_name, max_results):
return "this function doesn't do anything"
#You do not need to touch this or do anything with it!
这个假设的 inventory_lookup 函数应该这样调用:
inventory_lookup(“AA batteries”, 4)
inventory_lookup(“birthday candle”, 10)
你的任务是编写一个相应的、格式正确的工具定义。假设工具定义中需要两个参数。
为 Claude 提供工具
现在回到刚才的计算器函数。此时,Claude 对计算器工具一无所知!它只是一个小小的 Python 字典。在向 Claude 提出请求时,我们可以传递一个工具列表来 “告诉 ”Claude。我们现在就来试试:
response = client.messages.create(
model="claude-3-haiku-20240307",
messages=[{"role": "user", "content": "Multiply 1984135 by 9343116. Only respond with the result"}],
max_tokens=300,
# Tell Claude about our tool
tools=[calculator_tool]
)
接下来,让我们看看 Claude 给我们的回复:
response
ToolsBetaMessage(id=‘msg_01UfKwdmEsgTh99wfpgW4NJ7’, content=[ToolUseBlock(id=‘toolu_015wQ7Wipo589yT9B3YTwjF1’, input={‘operand1’: 1984135, ‘operand2’: 9343116, ‘operation’: ‘multiply’}, name=‘calculator’, type=‘tool_use’)], model=‘claude-3-haiku-20240307’, role=‘assistant’, stop_reason=‘tool_use’, stop_sequence=None, type=‘message’, usage=Usage(input_tokens=420, output_tokens=93))
你可能会注意到,我们的响应看起来与平时有些不同!具体来说,我们现在收到的不是普通的消息,而是 ToolsMessage。
此外,我们可以检查 response.stop_reason,发现 Claude 停止是因为它认为是时候使用工具了:
response.stop_reason
‘tool_use’
response.content 包含一个包含 ToolUseBlock 的列表,而 ToolUseBlock 本身则包含有关工具名称和输入的信息:
response.content
[ToolUseBlock(id=‘toolu_015wQ7Wipo589yT9B3YTwjF1’, input={‘operand1’: 1984135, ‘operand2’: 9343116, ‘operation’: ‘multiply’}, name=‘calculator’, type=‘tool_use’)]
tool_name = response.content[0].name
tool_inputs = response.content[0].input
print("The Tool Name Claude Wants To Call:", tool_name)
print("The Inputs Claude Wants To Call It With:", tool_inputs)
Claude 希望调用的工具名称:calculator Claude 希望调用它的输入:{‘operand1’: 1984135, ‘operand2’: 9343116, ‘operation’: ‘multiply’}。
下一步,我们只需使用 Claude 提供的工具名称和输入值,然后实际调用我们之前编写的计算器函数。这样我们就得到了最终答案!
operation = tool_inputs["operation"]
operand1 = tool_inputs["operand1"]
operand2 = tool_inputs["operand2"]
result = calculator(operation, operand1, operand2)
print("RESULT IS", result)
RESULT IS 18538003464660
我们得到的正确答案是 18538003464660!!!!!!我们只需向 Claude 提出一个问题,让它访问一个工具,必要时它就可以决定使用这个工具,而不是依赖 Claude 来正确计算。
重要提示
如果我们问 Claude 一些不需要使用工具的问题,在这种情况下,一些与数学或计算无关的问题,我们可能希望它能像平常一样回答。Claude 通常会这样做,但有时 Claude 也会非常渴望使用它的工具!
下面是一个例子, Claude 有时会尝试使用计算器,尽管使用它并没有什么意义。让我们看看当我们问 Claude “祖母绿是什么颜色的?”时会发生什么。
response = client.messages.create(
model="claude-3-haiku-20240307",
messages=[{"role": "user", "content":"What color are emeralds?"}],
max_tokens=400,
tools=[calculator_tool]
)
ToolsBetaMessage(id=‘msg_01Dj82HdyrxGJpi8XVtqEYvs’, content=[ToolUseBlock(id=‘toolu_01Xo7x3dV1FVoBSGntHNAX4Q’, input={‘operand1’: 0, ‘operand2’: 0, ‘operation’: ‘add’}, name=‘calculator’, type=‘tool_use’)], model=‘claude-3-haiku-20240307’, role=‘assistant’, stop_reason=‘tool_use’, stop_sequence=None, type=‘message’, usage=Usage(input_tokens=409, output_tokens=89))
Claude 希望我们调用计算器工具?一个非常简单的解决方法是调整我们的提示或添加一个系统提示,内容大致如下:You have access to tools, but only use them when necessary. If a tool is not required, respond as normal(您可以使用工具,但只能在必要时使用。如果不需要使用工具,请正常回复):
response = client.messages.create(
model="claude-3-haiku-20240307",
system="You have access to tools, but only use them when necessary. If a tool is not required, respond as normal",
messages=[{"role": "user", "content":"What color are emeralds?"}],
max_tokens=400,
tools=[calculator_tool]
)
ToolsBetaMessage(id=‘msg_01YRRfnUUhP1u5ojr9iWZGGu’, content=[TextBlock(text=‘Emeralds are green in color.’, type=‘text’)], model=‘claude-3-haiku-20240307’, role=‘assistant’, stop_reason=‘end_turn’, stop_sequence=None, type=‘message’, usage=Usage(input_tokens=434, output_tokens=12))
现在, Claude 会回复适当的内容,不会在不合理的情况下硬塞工具的使用。这就是我们得到的新回复:
‘Emeralds are green in color.’(绿宝石的颜色是绿色的。)
我们还可以看到,stop_reason 现在是 end_turn,而不是 tool_use。
response.stop_reason
‘end_turn’
将所有内容整合起来
def calculator(operation, operand1, operand2):
if operation == "add":
return operand1 + operand2
elif operation == "subtract":
return operand1 - operand2
elif operation == "multiply":
return operand1 * operand2
elif operation == "divide":
if operand2 == 0:
raise ValueError("Cannot divide by zero.")
return operand1 / operand2
else:
raise ValueError(f"Unsupported operation: {operation}")
calculator_tool = {
"name": "calculator",
"description": "A simple calculator that performs basic arithmetic operations.",
"input_schema": {
"type": "object",
"properties": {
"operation": {
"type": "string",
"enum": ["add", "subtract", "multiply", "divide"],
"description": "The arithmetic operation to perform.",
},
"operand1": {"type": "number", "description": "The first operand."},
"operand2": {"type": "number", "description": "The second operand."},
},
"required": ["operation", "operand1", "operand2"],
},
}
def prompt_claude(prompt):
messages = [{"role": "user", "content": prompt}]
response = client.messages.create(
model="claude-3-haiku-20240307",
system="You have access to tools, but only use them when necessary. If a tool is not required, respond as normal",
messages=messages,
max_tokens=500,
tools=[calculator_tool],
)
if response.stop_reason == "tool_use":
tool_use = response.content[-1]
tool_name = tool_use.name
tool_input = tool_use.input
if tool_name == "calculator":
print("Claude wants to use the calculator tool")
operation = tool_input["operation"]
operand1 = tool_input["operand1"]
operand2 = tool_input["operand2"]
try:
result = calculator(operation, operand1, operand2)
print("Calculation result is:", result)
except ValueError as e:
print(f"Error: {str(e)}")
elif response.stop_reason == "end_turn":
print("Claude didn't want to use a tool")
print("Claude responded with:")
print(response.content[0].text)
prompt_claude("I had 23 chickens but 2 flew away. How many are left?")
Claude want to use the calculator tool
Calculation result is: 21
prompt_claude("What is 201 times 2")
Claude want to use the calculator tool
Calculation result is: 402
prompt_claude("Write me a haiku about the ocean")
Claude didn’t want to use a tool
Claude responded with:
Here is a haiku about the ocean:\Vast blue expanse shines,
Waves crash upon sandy shores,
Ocean’s soothing song.
练习
你的任务是使用 Claude 帮助建立一个研究助手。用户可以输入一个想要研究的主题,并获得保存到标记文件中的维基百科文章链接列表,以便日后阅读。我们可以尝试让 Claude 直接生成文章 URL 列表,但 Claude 对 URL 的处理并不可靠,可能会出现文章 URL 的幻觉。此外,在 Claude 的培训截止日期之后,合法的文章可能已经转移到了新的 URL 上。相反,我们将使用一个连接到真正维基百科 API 的工具来实现这一功能!
我们将为 Claude 提供一个工具,它可以接受 Claude 生成但可能是幻觉的维基百科文章标题列表。我们可以使用该工具搜索维基百科,找到实际的维基百科文章标题和 URL,以确保最终列表中的文章都是真实存在的。然后,我们将把这些文章 URL 保存到一个标记符文件中,以便日后阅读。
我们为您提供了两个功能来帮助您:
import wikipedia
def generate_wikipedia_reading_list(research_topic, article_titles):
wikipedia_articles = []
for t in article_titles:
results = wikipedia.search(t)
try:
page = wikipedia.page(results[0])
title = page.title
url = page.url
wikipedia_articles.append({"title": title, "url": url})
except:
continue
add_to_research_reading_file(wikipedia_articles, research_topic)
def add_to_research_reading_file(articles, topic):
with open("output/research_reading.md", "a", encoding="utf-8") as file:
file.write(f"## {topic} \n")
for article in articles:
title = article["title"]
url = article["url"]
file.write(f"* [{title}]({url}) \n")
file.write(f"\n\n")
第一个函数是生成维基百科阅读列表(generate_wikipedia_reading_list),它需要传递一个研究课题,如 “夏威夷的历史 ”或 “世界各地的海盗”,以及我们将让 Claude 生成的潜在维基百科文章名称列表。该函数使用 wikipedia 软件包搜索相应的真实维基百科页面,并建立一个包含文章标题和 URL 的词典列表。
然后,它调用 add_to_research_reading_file,传入维基百科文章数据列表和整个研究课题。该函数只需将每篇维基百科文章的标记符链接添加到名为 output/research_reading.md 的文件中。文件名暂时为硬编码,函数假定它存在。该文件存在于本软件仓库中,但如果在其他地方工作,则需要自行创建。
我们的想法是,让 Claude “调用”generate_wikipedia_reading_list,并为其输入一个可能是也可能不是的潜在文章标题列表。Claude 可能会传递以下输入的文章标题列表,其中有些是真实的维基百科文章,有些则不是:
[“Piracy”, “Famous Pirate Ships”, “Golden Age Of Piracy”, “List of Pirates”, “Pirates and Parrots”, “Piracy in the 21st Century”]
generate_wikipedia_reading_list 函数会逐一查看这些文章标题,并为任何实际存在的维基百科文章收集真实的文章标题和相应的 URL。然后调用 add_to_research_reading_file,将这些内容写入一个 markdown 文件,以供日后参考。
最终的目标
您的任务是实现一个名为 get_research_help 的函数,该函数接受一个研究主题和所需的文章数量。该函数应使用 Claude 实际生成可能的维基百科文章列表,并调用上面的 generate_wikipedia_reading_list 函数。下面是几个函数调用示例:
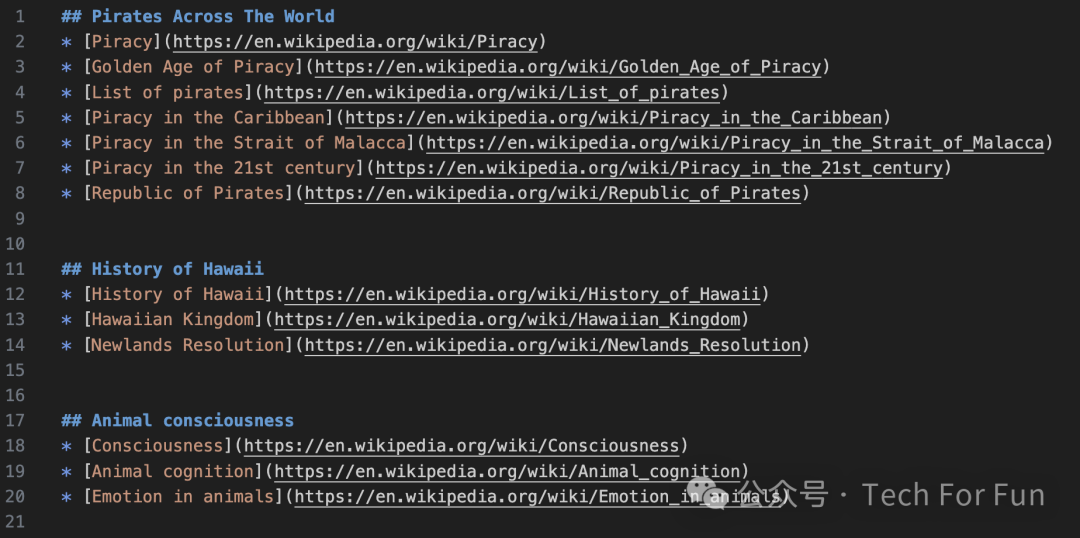
get_research_help(“Pirates Across The World”,7)
get_research_help(“History of Hawaii”,3)
get_research_help(“Are animals conscious?”, 3)
调用这 3 个函数后,我们输出的 research_reading.md 文件就是这个样子(请在 output/research_reading.md 中查看):
要实现这一点,需要做以下工作:
-
为
generate_wikipedia_reading_list函数编写工具定义 -
实现
get_research_help函数 -
给 Claude 写一个提示,告诉它您需要帮助收集关于特定主题的研究,以及您希望它生成多少文章标题
-
告诉 Claude 它可以使用的工具
-
向 Claude 发送请求
-
检查 Claude 是否调用了该工具。如果它调用了,需要将它生成的文章标题和主题传递给 generate_wikipedia_reading_list 函数。该函数将收集实际的维基百科文章链接,然后调用
add_to_research_reading_file将链接写入output/research_reading.md文件中 -
打开
output/research_reading.md,看看是否成功!
启动代码:
# Here's your starter code!
import wikipedia
def generate_wikipedia_reading_list(research_topic, article_titles):
wikipedia_articles = []
for t in article_titles:
results = wikipedia.search(t)
try:
page = wikipedia.page(results[0])
title = page.title
url = page.url
wikipedia_articles.append({"title": title, "url": url})
except:
continue
add_to_research_reading_file(wikipedia_articles, research_topic)
def add_to_research_reading_file(articles, topic):
with open("output/research_reading.md", "a", encoding="utf-8") as file:
file.write(f"## {topic} \n")
for article in articles:
title = article["title"]
url = article["url"]
file.write(f"* [{title}]({url}) \n")
file.write(f"\n\n")
def get_research_help(topic, num_articles=3):
#Implement this function!
pass
结构化输出
工具使用的一种更有趣的方式是强制 Claude 响应 JSON 等结构化内容。在许多情况下,我们可能希望从 Claude 获得标准化的 JSON 响应:提取实体、汇总数据、分析情感等。
其中一种方法是简单地要求 Claude 用 JSON 进行响应,但这可能需要额外的工作,以便从 Claude 返回的大字符串中实际提取 JSON,或确保 JSON 完全符合我们想要的格式。
好消息是,只要 Claude 想要使用某个工具,它就会使用我们在定义该工具时告诉它使用的结构完美的格式进行响应。
在上一节,我们给 Claude 提供了一个计算器工具。当 Claude 想要使用该工具时,它的响应内容是这样的
{
‘operand1’: 1984135,
‘operand2’: 9343116,
‘operation’: ‘multiply’
}
这看起来很像 JSON!
如果我们想让 Claude 生成结构化的 JSON,就可以利用这一点。我们所要做的就是定义一个描述特定 JSON 结构的工具,然后将其告诉 Claude 。就是这样。Claude 会做出响应,认为它在 “调用一个工具”,但实际上我们关心的只是它给出的结构化响应。
概念概览
这与我们在上一节中所做的有什么不同?下面是上一节的工作流程图:

在上一课中,我们让 Claude 访问一个工具,Claude 想要调用它,然后我们实际调用了底层工具函数。
在本课中,我们将 “欺骗 ” Claude ,告诉它一个特定的工具,但我们不需要实际调用底层工具函数。如图所示,我们将使用该工具来强制实现特定的响应结构:

情感分析
让我们从一个简单的例子开始。假设我们想让 Claude 分析某些文本中的情感,并用一个符合这种形状的 JSON 对象做出响应:
{
“negative_score”: 0.6,
“neutral_score”: 0.3,
“positive_score”: 0.1
}
我们要做的就是定义一个工具,使用 JSON 模式捕捉这种形状。下面是一个可能的实现方法:
tools = [
{
"name": "print_sentiment_scores",
"description": "Prints the sentiment scores of a given text.",
"input_schema": {
"type": "object",
"properties": {
"positive_score": {"type": "number", "description": "The positive sentiment score, ranging from 0.0 to 1.0."},
"negative_score": {"type": "number", "description": "The negative sentiment score, ranging from 0.0 to 1.0."},
"neutral_score": {"type": "number", "description": "The neutral sentiment score, ranging from 0.0 to 1.0."}
},
"required": ["positive_score", "negative_score", "neutral_score"]
}
}
]
现在,我们可以告诉 Claude 这个工具,并明确告诉 Claude 使用它,以确保它确实使用了这个工具。我们应该得到一个响应,告诉我们 Claude 想要使用一个工具。工具使用响应应该以我们想要的格式包含所有数据。
from anthropic import Anthropic
from dotenv import load_dotenv
import json
load_dotenv()
client = Anthropic()
tweet = "I'm a HUGE hater of pickles. I actually despise pickles. They are garbage."
query = f"""
<text>
{tweet}
</text>
Only use the print_sentiment_scores tool.
"""
response = client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=4096,
tools=tools,
messages=[{"role": "user", "content": query}]
)
让我们看看 Claude 给我们的回复。我们将重要部分用粗体标出:
ToolsBetaMessage(id=‘msg_01BhF4TkK8vDM6z5m4FNGRnB’, content=[TextBlock(text=‘Here is the sentiment analysis for the given text:’, type=‘text’), ToolUseBlock(id=‘toolu_01Mt1an3KHEz5RduZRUUuTWz’, input={‘positive_score’: 0.0, ‘negative_score’: 0.791, ‘neutral_score’: 0.209}, name=‘print_sentiment_scores’, type=‘tool_use’)], model=‘claude-3-sonnet-20240229’, role=‘assistant’, stop_reason=‘tool_use’, stop_sequence=None, type=‘message’, usage=Usage(input_tokens=374, output_tokens=112))
Claude “认为 ”这是在调用一个使用情感分析数据的工具,但实际上我们只是要提取数据并将其转化为 JSON 格式:
import json
json_sentiment = None
for content in response.content:
if content.type == "tool_use" and content.name == "print_sentiment_scores":
json_sentiment = content.input
break
if json_sentiment:
print("Sentiment Analysis (JSON):")
print(json.dumps(json_sentiment, indent=2))
else:
print("No sentiment analysis found in the response.")
Sentiment Analysis (JSON):
{
“positive_score”: 0.0,
“negative_score”: 0.791,
“neutral_score”: 0.209
}
成功了!现在,让我们将其转化为一个可重复使用的函数,接收一条推文或一篇文章,然后以 JSON 格式打印或返回情感分析结果。
def analyze_sentiment(content):
query = f"""
<text>
{content}
</text>
Only use the print_sentiment_scores tool.
"""
response = client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=4096,
tools=tools,
messages=[{"role": "user", "content": query}]
)
json_sentiment = None
for content in response.content:
if content.type == "tool_use" and content.name == "print_sentiment_scores":
json_sentiment = content.input
break
if json_sentiment:
print("Sentiment Analysis (JSON):")
print(json.dumps(json_sentiment, indent=2))
else:
print("No sentiment analysis found in the response.")
analyze_sentiment("OMG I absolutely love taking bubble baths soooo much!!!!")
Sentiment Analysis (JSON):
{
“positive_score”: 0.8,
“negative_score”: 0.0,
“neutral_score”: 0.2
}
输入:
analyze_sentiment(“Honestly I have no opinion on taking baths”)
响应:
Sentiment Analysis (JSON):
{
“positive_score”: 0.056,
“negative_score”: 0.065,
“neutral_score”: 0.879
}
强制tool_choice工具使用
目前,我们通过提示 “强制 ” Claude 使用 print_sentiment_scores 工具。我们在提示中写道:“Only use the print_sentiment_scores tool(请使用 print_sentiment_scores 工具)。”这通常有效,但还有更好的方法!实际上,我们可以使用 tool_choice 参数强制 Claude 使用特定的工具:
tool_choice={"type": "tool", "name": "print_sentiment_scores"}
上面的代码告诉 Claude,它必须通过调用 print_sentiment_scores 工具来做出响应。让我们更新函数来使用它:
def analyze_sentiment(content):
query = f"""
<text>
{content}
</text>
Only use the print_sentiment_scores tool.
"""
response = client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=4096,
tools=tools,
tool_choice={"type": "tool", "name": "print_sentiment_scores"},
messages=[{"role": "user", "content": query}]
)
json_sentiment = None
for content in response.content:
if content.type == "tool_use" and content.name == "print_sentiment_scores":
json_sentiment = content.input
break
if json_sentiment:
print("Sentiment Analysis (JSON):")
print(json.dumps(json_sentiment, indent=2))
else:
print("No sentiment analysis found in the response.")
我们将在后面章节详细介绍tool_choice。
实体提取示例
让我们用同样的方法让 Claude 生成格式化良好的 JSON,其中包含从文本样本中提取的人员、组织和地点等实体:
tools = [
{
"name": "print_entities",
"description": "Prints extract named entities.",
"input_schema": {
"type": "object",
"properties": {
"entities": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "The extracted entity name."},
"type": {"type": "string", "description": "The entity type (e.g., PERSON, ORGANIZATION, LOCATION)."},
"context": {"type": "string", "description": "The context in which the entity appears in the text."}
},
"required": ["name", "type", "context"]
}
}
},
"required": ["entities"]
}
}
]
text = "John works at Google in New York. He met with Sarah, the CEO of Acme Inc., last week in San Francisco."
query = f"""
<document>
{text}
</document>
Use the print_entities tool.
"""
response = client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=4096,
tools=tools,
messages=[{"role": "user", "content": query}]
)
json_entities = None
for content in response.content:
if content.type == "tool_use" and content.name == "print_entities":
json_entities = content.input
break
if json_entities:
print("Extracted Entities (JSON):")
print(json.dumps(json_entities, indent=2))
else:
print("No entities found in the response.")
Extracted Entities (JSON):
{
"entities": [
{
"name": "John",
"type": "PERSON",
"context": "John works at Google in New York."
},
{
"name": "Google",
"type": "ORGANIZATION",
"context": "John works at Google in New York."
},
{
"name": "New York",
"type": "LOCATION",
"context": "John works at Google in New York."
},
{
"name": "Sarah",
"type": "PERSON",
"context": "He met with Sarah, the CEO of Acme Inc., last week in San Francisco."
},
{
"name": "Acme Inc.",
"type": "ORGANIZATION",
"context": "He met with Sarah, the CEO of Acme Inc., last week in San Francisco."
},
{
"name": "San Francisco",
"type": "LOCATION",
"context": "He met with Sarah, the CEO of Acme Inc., last week in San Francisco."
}
]
}
我们使用的 “技巧” 和以前一样。我们告诉 Claude 它可以访问一个工具,以此让 Claude 用特定的数据格式做出回应。然后,我们提取 Claude 回应的格式化数据,这样就可以了。
请记住,在这个用例中,明确告诉 Claude 我们希望它使用某个工具是有帮助的。
Use the print_entities tool.
使用更复杂数据的维基百科摘要示例
让我们试试另一个更复杂的示例。我们将使用 Python wikipedia 软件包获取整个维基百科页面的文章,并将其传递给 Claude。我们将使用 Claude 生成一个响应,其中包括
-
文章主题
-
文章摘要
-
文章中提到的关键词和主题列表
-
文章的类别分类列表(娱乐、政治、商业等)以及分类得分(即该主题在该类别中的强弱程度)
如果我们通过 Claude 维基百科上关于沃尔特-迪斯尼的文章,我们可能会得到这样的结果:
{
"subject": "Walt Disney",
"summary": "Walter Elias Disney was an American animator, film producer, and entrepreneur. He was a pioneer of the American animation industry and introduced several developments in the production of cartoons. He held the record for most Academy Awards earned and nominations by an individual. He was also involved in the development of Disneyland and other theme parks, as well as television programs.",
"keywords": [
"Walt Disney",
"animation",
"film producer",
"entrepreneur",
"Disneyland",
"theme parks",
"television"
],
"categories": [
{
"name": "Entertainment",
"score": 0.9
},
{
"name": "Business",
"score": 0.7
},
{
"name": "Technology",
"score": 0.6
}
]
}
下面是一个函数的实现示例,该函数期望一个维基百科页面主题,找到文章,下载内容,将其传递给 Claude,然后打印出结果 JSON 数据。我们使用了相同的策略,即定义一个工具来 “指导 ” Claude 的响应格式。
注意:如果您的机器上没有 wikipedia,请务必使用 pip install wikipedia!
import wikipedia
#tool definition
tools = [
{
"name": "print_article_classification",
"description": "Prints the classification results.",
"input_schema": {
"type": "object",
"properties": {
"subject": {
"type": "string",
"description": "The overall subject of the article",
},
"summary": {
"type": "string",
"description": "A paragaph summary of the article"
},
"keywords": {
"type": "array",
"items": {
"type": "string",
"description": "List of keywords and topics in the article"
}
},
"categories": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "The category name."},
"score": {"type": "number", "description": "The classification score for the category, ranging from 0.0 to 1.0."}
},
"required": ["name", "score"]
}
}
},
"required": ["subject","summary", "keywords", "categories"]
}
}
]
#The function that generates the json for a given article subject
def generate_json_for_article(subject):
page = wikipedia.page(subject, auto_suggest=True)
query = f"""
<document>
{page.content}
</document>
Use the print_article_classification tool. Example categories are Politics, Sports, Technology, Entertainment, Business.
"""
response = client.messages.create(
model="claude-3-haiku-20240307",
max_tokens=4096,
tools=tools,
messages=[{"role": "user", "content": query}]
)
json_classification = None
for content in response.content:
if content.type == "tool_use" and content.name == "print_article_classification":
json_classification = content.input
break
if json_classification:
print("Text Classification (JSON):")
print(json.dumps(json_classification, indent=2))
else:
print("No text classification found in the response.")
generate_json_for_article(“Jeff Goldblum”)
Text Classification (JSON):
{
"subject": "Jeff Goldblum",
"summary": "Jeffrey Lynn Goldblum is an American actor and musician who has starred in some of the highest-grossing films, such as Jurassic Park and Independence Day. He has had a long and successful career in both film and television, with roles in a wide range of movies and TV shows. Goldblum is also an accomplished jazz musician and has released several albums with his band, The Mildred Snitzer Orchestra.",
"keywords": [
"actor",
"musician",
"Jurassic Park",
"Independence Day",
"film",
"television",
"jazz"
],
"categories": [
{
"name": "Entertainment",
"score": 0.9
}
]
}
generate_json_for_article("Octopus")
Text Classification (JSON):
{
"subject": "Octopus",
"summary": "This article provides a comprehensive overview of octopuses, including their anatomy, physiology, behavior, ecology, and evolutionary history. It covers topics such as their complex nervous systems, camouflage and color-changing abilities, intelligence, and relationships with humans.",
"keywords": [
"octopus",
"cephalopod",
"mollusc",
"marine biology",
"animal behavior",
"evolution"
],
"categories": [
{
"name": "Science",
"score": 0.9
},
{
"name": "Nature",
"score": 0.8
}
]
}
generate_json_for_article("Herbert Hoover")
Text Classification (JSON):
{
"subject": "Herbert Hoover",
"summary": "The article provides a comprehensive biography of Herbert Hoover, the 31st President of the United States. It covers his early life, career as a mining engineer and humanitarian, his presidency during the Great Depression, and his post-presidency activities.",
"keywords": [
"Herbert Hoover",
"Great Depression",
"Republican Party",
"U.S. President",
"mining engineer",
"Commission for Relief in Belgium",
"U.S. Food Administration",
"Secretary of Commerce",
"Smoot\u2013Hawley Tariff Act",
"New Deal"
],
"categories": [
{
"name": "Politics",
"score": 0.9
},
{
"name": "Business",
"score": 0.7
},
{
"name": "History",
"score": 0.8
}
]
}
练习
使用上述策略编写一个名为 translate 的函数,该函数接收一个单词或短语,并生成一个结构化的 JSON 输出,其中包括英语的原始短语和西班牙语、法语、日语和阿拉伯语的翻译短语。
下面是一个示例,说明该函数应如何工作:
如果我们调用
translate("how much does this cost")
我们希望得到这样的输出结果:
{
"english": "how much does this cost",
"spanish": "¿cuánto cuesta esto?",
"french": "combien ça coûte?",
"japanese": "これはいくらですか",
"arabic": "كم تكلفة هذا؟"
}
注意:如果您想打印结果,这行代码将帮助您很好地打印出来:
print(json.dumps(translations_from_claude, ensure_ascii=False, indent=2))
完整的工具使用工作流
我们将介绍 “完整 ”的 4 步工具使用工作流程。到目前为止,我们已经看到 Claude 使用了工具,但我们还没有向 Claude 发送包含工具功能结果的后续请求。
以下是流程概览图:

这是解释我们的脚本如何工作的图表:
下面是一些真实的交流,说明了我们希望达到的最终结果:
User:As of 2024 who has more oscars, Christopher Nolan or Ben Stiller?(到 2024 年,克里斯托弗-诺兰和本-斯蒂勒谁获得的奥斯卡奖更多?)
Claude wants to get an article for Christopher Nolan (tool use)
Claude wants to get an article for Ben Stiller (tool use)
Claude :As of 2024, filmmaker Christopher Nolan has won 2 Academy Awards for Best Director and Best Picture for his 2023 film Oppenheimer. On the other hand, actor and comedian Ben Stiller has not won any Oscars in his career so far, although he has won other awards like Emmys and MTV Movie Awards. So to directly answer the question, as of 2024, Christopher Nolan has won more Oscars (2) than Ben Stiller, who has not won any.(截至 2024 年,电影制片人克里斯托弗-诺兰凭借 2023 年的电影《奥本海默》获得了奥斯卡最佳导演和最佳影片两项大奖。另一方面,演员兼喜剧演员本-斯蒂勒虽然获得过艾美奖和 MTV 电影奖等其他奖项,但迄今为止尚未获得过任何奥斯卡奖。因此,直接回答这个问题,截至 2024 年,克里斯托弗-诺兰获得的奥斯卡奖(2 项)要多于本-斯蒂勒,后者没有获得过任何奥斯卡奖。)
下面是另一个例子:
User:Who won the 2024 Masters Tournament?(谁赢得了 2024 年大师赛?)
Claude wants to get an article for 2024 Masters Tournament (tool use)
Claude :Scottie Scheffler won the 2024 Masters Tournament, his second Masters victory. He finished four strokes ahead of runner-up Ludvig Åberg, who was making his debut at the Masters.(斯科蒂-谢弗勒赢得了 2024 年名人赛,这是他第二次赢得名人赛。他领先亚军路德维格-奥贝里(Ludvig Åberg)四杆,后者是首次参加美国名人赛。)
如果我们问 Claude 一个问题,它不需要使用我们的工具就能回答,那么它就应该立即回答,而不需要使用我们的维基百科搜索工具:
User:Who won the 2021 Masters?(谁赢得了 2021 年美国名人赛?)
Claude :Hideki Matsuyama won the 2021 Masters Tournament, becoming the first Japanese man to win a major golf championship. He finished with a score of 278 (-10) to claim the green jacket at Augusta National Golf Club.(松山英树赢得了 2021 年美国名人赛,成为第一位赢得高尔夫大满贯赛的日本人。他以 278杆(-10)的成绩在奥古斯塔国家高尔夫俱乐部(Augusta National Golf Club)赢得绿夹克。)
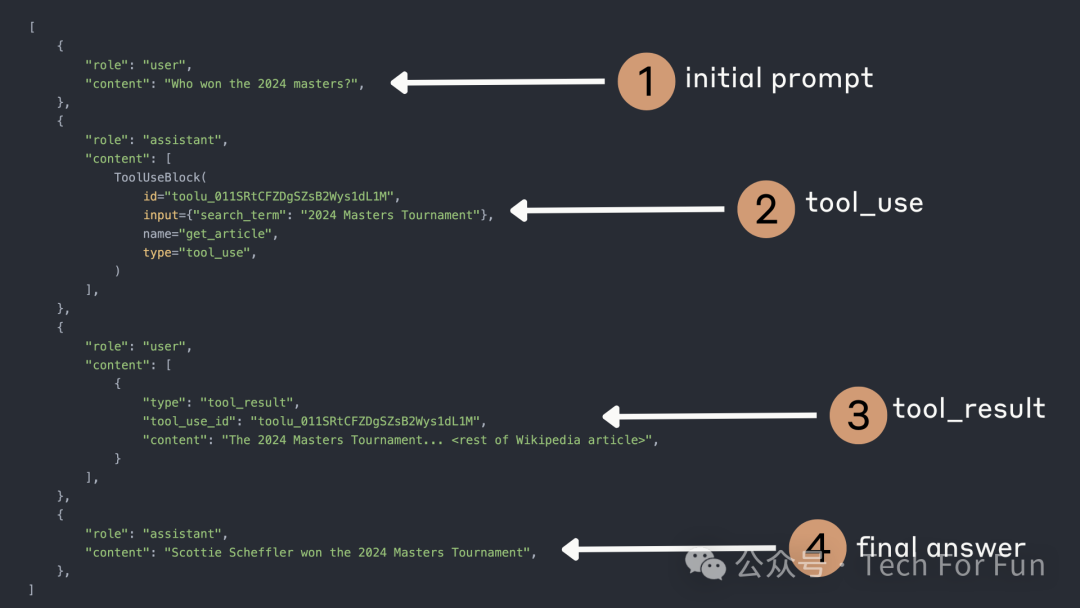
下面我们来看看这个过程结束时的messages列表:
建立完整的工作流程
1. 定义维基百科搜索函数
在使用 Claude 之前,我们先编写一个简单的维基百科搜索函数。下面的函数使用 wikipedia 软件包,根据搜索词搜索匹配的维基百科页面。为了简单起见,我们取第一个返回的页面标题,然后用它来访问相应的页面内容。
注意:这个简单的函数假设我们找到了一篇维基百科文章。为了简洁起见,该函数没有错误处理,这在现实世界中并不是一个好主意!
import wikipedia
def get_article(search_term):
results = wikipedia.search(search_term)
first_result = results[0]
page = wikipedia.page(first_result, auto_suggest=False)
return page.content
article = get_article("Superman")
print(article[:500]) # article is very long, so let's just print a preview
超人是美国 DC 漫画公司出版的漫画书中出现的超级英雄。该角色由作家杰里-西格尔和艺术家乔-舒斯特创作,首次登场于漫画书《行动漫画》第 1 期(封面日期为 1938 年 6 月,出版日期为 1938 年 4 月 18 日)。超人还被改编成许多其他媒体,包括广播连续剧、小说、电影、电视节目、戏剧和视频游戏。
超人出生在虚构的氪星,出生时的名字叫卡尔-埃尔(Kal-El)。小时候,他的名字是 Zendaya Maree Stoermer Coleman(zən-DAY-ə;1996 年 9 月 1 日出生),美国女演员、歌手。她获得过各种荣誉,包括两次艾美奖和一次金球奖。时代》杂志将她评为 2022 年全球最具影响力的 100 人之一。
赞达亚在加利福尼亚奥克兰出生长大,以童年模特和伴舞的身份开始了她的演艺生涯。她在迪斯尼频道情景喜剧《Shake It Up》(2010-2013 年)中饰演 Rocky Blue,首次登上电视荧屏。
article = get_article("Zendaya")
print(article[:500]) # article is very long, so let's just print a preview
2. 编写工具定义
接下来,我们需要使用正确的 JSON 模式格式来定义我们的工具。这是一个非常简单的工具定义,因为函数只需要一个参数:搜索词字符串。
article_search_tool = {
"name": "get_article",
"description": "A tool to retrieve an up to date Wikipedia article.",
"input_schema": {
"type": "object",
"properties": {
"search_term": {
"type": "string",
"description": "The search term to find a wikipedia article by title"
},
},
"required": ["search_term"]
}
}
3. 为 Claude 提供工具和用户提示
接下来,我们将告诉 Claude 它可以使用维基百科搜索工具,并要求它回答一个我们知道它在没有该工具的情况下无法回答的问题,比如 "谁赢得了 2024 年的大师赛?
from anthropic import Anthropic
from dotenv import load_dotenv
load_dotenv()
client = Anthropic()
messages = [{"role": "user", "content": "who won the 2024 Masters Tournament?"}]
response = client.messages.create(
model="claude-3-sonnet-20240229",
messages=messages,
max_tokens=1000,
tools=[article_search_tool]
)
4. Claude 使用工具(API 响应)
让我们来看看我们得到的响应。Claude 想要使用我们的工具!
response.content
[TextBlock(text=‘Okay, let me see if I can find information about the winner of the 2024 Masters Tournament on Wikipedia:’, type=‘text’),
ToolUseBlock(id=‘toolu_01CWuduGjgSRfsYJUNC2wxi7’, input={‘search_term’: ‘2024 Masters Tournament’}, name=‘get_article’, type=‘tool_use’)]
Claude 的回复包含 2 个块:
- 一个文本块,其文本为 “好的,让我使用可用工具尝试在维基百科上查找关于谁赢得了 2024 年大师赛的信息:”
TextBlock(text=‘Okay, let me use the available tool to try and find information on who won the 2024 Masters Tournament:’, type=‘text’)
ToolUseBlock调用我们的get_article工具,搜索关键词为 “2024 Masters Tournament(2024 年美国名人赛)”。
ToolUseBlock(id=‘toolu_01MbstBxD654o9hE2RGNdtSr’, input={‘search_term’: ‘2024 Masters Tournament’}, name=‘get_article’, type=‘tool_use’)]
5. 提取工具输入、运行代码并返回结果(API 请求)
既然 Claude 已经回复告诉我们它想使用某个工具,我们就该实际运行底层功能,并向 Claude 回复相应的维基百科页面内容了。
我们需要特别注意确保更新我们的 message 列表
首先,我们要更新message列表,将 Claude 的最新回复包含在内:
messages.append({"role": "assistant", "content": response.content})
messages
[{‘role’: ‘user’, ‘content’: ‘who won the 2024 Masters Tournament?’}, {‘role’: ‘assistant’,
‘content’: [TextBlock(text=‘Okay, let me see if I can find information about the winner of the 2024 Masters Tournament on Wikipedia:’, type=‘text’),
ToolUseBlock(id=‘toolu_01CWuduGjgSRfsYJUNC2wxi7’, input={‘search_term’: ‘2024 Masters Tournament’}, name=‘get_article’, type=‘tool_use’)]}]
接下来,我们将提取 Claude 想要使用的特定工具和参数:
# This is a simple, but brittle way of getting the tool use information
# We're simply taking the last block from Claude's response.
tool_use = response.content[-1]
tool_name = tool_use.name
tool_input = tool_use.input
print("Tool name: ", tool_name)
print("Tool input", tool_input)
Tool name: get_article
Tool input {‘search_term’: ‘2024 Masters Tournament’}
接下来,我们要确保 Claude 调用的是我们期待的 get_article 工具。我们将使用 Claude 提出的 search_term,并将其传递给我们之前编写的 get_article 函数。
if tool_name == "get_article":
search_term = tool_input["search_term"]
wiki_result = get_article(search_term)
print(f"Searching Wikipedia for {search_term}")
print("WIKIPEDIA PAGE CONTENT:")
print(wiki_result[:500]) #just printing a small bit of the article because it's so long
Searching Wikipedia for 2024 Masters Tournament
WIKIPEDIA PAGE CONTENT:
The 2024 Masters Tournament was the 88th edition of the Masters Tournament and the first of the men’s four major golf championships held in 2024. The tournament was played from April 11–14 at Augusta National Golf Club in Augusta, Georgia, United States. Scottie Scheffler won his second Masters and major, four strokes ahead of runner-up Ludvig Åberg, who was playing in his first major. Scheffler became the fourth-youngest two-time winner of the tournament and the second player, after Tiger Woods(2024 年名人赛是第 88 届名人赛,也是 2024 年举行的男子四大高尔夫锦标赛中的第一场。比赛于 4 月 11-14 日在美国佐治亚州奥古斯塔的奥古斯塔国家高尔夫俱乐部举行。斯科蒂-谢弗勒以领先亚军路德维格-奥贝里(Ludvig Åberg)四杆的优势赢得了他的第二个美国大师赛和大满贯赛冠军,后者是第一次参加大满贯赛。谢弗勒成为该赛事第四年轻的两届冠军得主,也是继泰格-伍兹(Tiger Woods)之后第二位获得该赛事冠军的选手。)
现在,我们已经执行了 Claude 希望我们调用的函数,是时候用维基百科页面数据回复 Claude 了。
我们知道,当 Claude 想要使用某个工具时,它会在 API 响应中以 tool_use 的 stop_reason 和一个或多个 tool_use 内容块响应我们,这些内容块包括
-
id:该特定工具使用块的唯一标识符。稍后将用于匹配工具结果。 -
name:正在使用的工具名称。 -
input:输入:包含传递给工具的输入的对象,符合工具的输入模式。
一旦我们执行了底层工具函数,我们还需要以特定格式向 Claude 作出回应。具体来说,为了继续对话,我们需要发送一条新消息,角色为用户,内容块包含 tool_result 类型以及以下信息:
-
tool_use_id:工具使用请求的 id。 -
content:工具结果,以字符串(如 “content”: “15度”)或嵌套内容块列表(如 “content”: [{“type”: “text”, “text”: “15度”}])的形式显示。 -
is_error(可选):如果工具执行时出错,则设为 true。
下面是一个格式正确的 tool_result 信息的示例:
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": "toolu_01A09q90qw90lq917835lq9",
"content": "The result of actually calling the tool goes here"
}
]
}
现在让我们以维基百科搜索为例进行说明。我们需要正确编写工具响应信息,将维基百科搜索结果发回给 Claude:
tool_response = {
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": tool_use.id,
"content": wiki_result
}
]
}
tool_response
{‘role’: ‘user’, ‘content’: [{‘type’: ‘tool_result’, ‘tool_use_id’: ‘toolu_01CWuduGjgSRfsYJUNC2wxi7’, ‘content’: “The 2024 Masters Tournament was the 88th edition of the Masters Tournament and the first of the men’s four major golf championships held in 2024. The tournament was played from April 11–14 at Augusta National Golf Club in Augusta, Georgia, United States. Scottie Scheffler won his second Masters and major, four strokes ahead of runner-up Ludvig Åberg, who was playing in his first major. Scheffler became the fourth-youngest two-time winner of the tournament and the second player, after Tiger Woods in 2001, to win both the Masters and The Players Championship in the same calendar year. \n\n\n== Course \n\nThe only change to the course for the 2024 tournament was the lengthening of the second hole by ten yards.\n\n\n Field \nParticipation in the Masters Tournament is by invitation only, and the tournament has the smallest field of the major championships. There are a number of criteria by which invitations are awarded, including all past winners, recent major champions, leading finishers in the previous year’s majors, leading players on the PGA Tour in the previous season, winners of full-point tournaments on the PGA Tour during the previous 12 months, leading players in the Official World Golf Ranking, and some leading amateurs.\n\n\n= Criteria =\nThere were three changes to invitee criteria between the 2023 and 2024 tournaments. The first was to add the current NCAA Division I Men’s Individual Champion a spot in the field, provided that he remains an amateur at the time of the tournament. In addition, Augusta National clarified that players who qualify for the Tour Championship must remain eligible to play in that event in order to qualify for the Masters. Also, with the PGA Tour returning to a calendar-year season schedule, Augusta National noted that winners of fall PGA Tour events would continue to qualify for the Masters.\nThe below list details the qualification criteria for the 2024 Masters Tournament and the players who have qualified under them; any additional criteria under which players qualified are indicated in parentheses.\n1. All past winners of the Masters Tournament\n\nPast winners who did not play: Tommy Aaron, Ángel Cabrera, Charles Coody, Ben Crenshaw, Nick Faldo, Raymond Floyd, Trevor Immelman, Bernhard Langer, Sandy Lyle, Larry Mize, Jack Nicklaus, Mark O’Meara, Gary Player, Craig Stadler, Tom Watson, Ian Woosnam, Fuzzy Zoeller\n2. Recent winners of the U.S. Open (2019–2023)\n\n3. Recent winners of The Open Championship (2019–2023)\n\n4. Recent winners of the PGA Championship (2019–2023)\n\n5. Recent winners of The Players Championship (2022–2024)\n6. The winner of the gold medal at the Olympic Games\n7. The winner and runner-up in the 2023 U.S. Amateur\n\nNeal Shipley (a)\n8. The winner of the 2023 Amateur Championship\n\nChristo Lamprecht (a)\n9. The winner of the 2023 Asia-Pacific Amateur Championship\n\nJasper Stubbs (a)\n10. The winner of the 2024 Latin America Amateur Championship\n\nSantiago de la Fuente (a)\n11. The winner of the 2023 U.S. Mid-Amateur Golf Championship\n\nStewart Hagestad (a)\n12. The winner of the 2023 NCAA Division I men’s golf individual championship\n\nFred Biondi forfeited his invitation by turning professional.\n13. The leading 12 players, and those tying for 12th place, from the 2023 Masters Tournament\n\n14. The leading four players, and those tying for fourth place, in the 2023 U.S. Open\n\nRory McIlroy (17,18,19,20)\n15. The leading four players, and those tying for fourth place, in the 2023 Open Championship\n\n16. The leading four players, and those tying for fourth place, in the 2023 PGA Championship\n\n17. Winners of tournaments on the PGA Tour between the 2023 Masters Tournament and the 2024 Masters Tournament\n\n18. All players who qualified for and are eligible for the 2023 Tour Championship\n\n19. The leading 50 players on the Official World Golf Ranking as of December 31, 2023\n\n20. The leading 50 players on the Official World Golf Ranking as of April 1, 2024\n\nAn Byeong-hun\n21. Special invitations\n\n\n Par-3 contest \nWednesday, April 10\nRickie Fowler won the par-3 contest with a score of 22 (−5). There were five holes-in-one recorded, by Sepp Straka, Luke List, Gary Woodland, Viktor Hovland, and Lucas Glover.\n\n\n Round summaries \n\n\n= First round =\nThursday, April 11, 2024Friday, April 12, 2024\nInclement weather delayed the start of the tournament until 10:30 am Eastern time. As a result, 27 players did not complete the first round on Thursday.\nThe 8th hole, a par 5, saw a record-breaking total of 53 par-breaking scores, including 50 birdies and 3 eagles, the highest ever recorded on this hole in Masters history. \n\n\n= Second round =\nFriday, April 12, 2024\nBy making the cut, Tiger Woods set the record for most consecutive cuts made at the Masters, at 24. Phil Mickelson made the cut for the 28th time, surpassing Raymond Floyd and Bernhard Langer to move into solo fourth place for most cuts made at the Masters, trailing only Jack Nicklaus (37), Fred Couples (31) and Gary Player (30).\nRookie Ludvig Åberg posted the lowest score of the round, a 69, and advanced to a solo 7th place.\nBryson DeChambeau, before making a birdie on the 13th hole, moved a large directional sign that was in his line of play.\nPatrick Cantlay achieved two eagles on par 4s, marking only the fourth instance in history that a player has recorded two par-4 eagles in a single Masters Tournament, the last being Brandt Jobe in 2006.\nThe cut came at 150 (+6), with 60 players advancing to the weekend. Notables to miss the cut included 2015 champion Jordan Spieth, 2020 champion Dustin Johnson, reigning U.S. Open champion Wyndham Clark, Open champion Brian Harman, and World No. 6 Viktor Hovland. Two-time major champion Justin Thomas played his last four holes in seven-over to miss the cut by one shot.\n\n\n= Third round =\nSaturday, April 13, 2024\nScottie Scheffler, beginning the round in a three-way tie for the lead, chipped in for birdie on the first hole. After a double bogey on the 10th, Scheffler holed a 31-foot eagle putt on the par-five 13th, the only eagle recorded on that hole during the round. He also birdied the 15th and 18th to finish at seven under following a 71 (−1) to take a one-shot lead into the final round.\nCollin Morikawa birdied his first three holes in a three-under round of 69 and finished at six under, one shot back of Scheffler. Max Homa, tied for the lead at the start of the round, didn’t make a birdie in a one-over 73 and fell two back at 5 under. Bryson DeChambeau was also atop the leaderboard to begin the round but hit his third shot in the water on the 15th and made double bogey. He holed out for birdie on the 18th to finish at three under and four shots back of Scheffler. Ludvig Åberg, making his Masters and major championship debut, was four under on his round until a bogey at the 14th. He then left his third shot on the 15th short and three-putted from just off the green for another bogey. He shot 70 (–2) and ended up at four under.\nNicolai Højgaard moved into sole possession of the lead following a run of three straight birdies from holes 8 to 10, but he then made five straight bogeys including hitting into the water on both the 13th and 15th and finished at two under.\nTiger Woods carded a 10-over-par 82 for the third round, his highest score ever in a major championship.\nNo eagles were recorded on the par-5 15th hole through the first three rounds, marking only the second time in the past 50 years that No. 15 has failed to produce an eagle by this point in the tournament. Shane Lowry scored an eagle on the par-4 14th hole, marking the first eagle on this hole since Martin Kaymer in 2016.\n\n\n= Final round =\nSunday, April 14, 2024\n\nWorld No. 1 Scottie Scheffler shot a four-under 68 to win his second Masters title in the last three years by four shots over runner-up Ludvig Åberg.\nScheffler began the round with a one-shot lead and birdied the third hole to go two shots ahead. He then bogeyed the fourth after hitting his tee shot over the green. Max Homa birdied the second, his first birdie in 34 holes, to get within one of the lead, while Åberg hit his approach on the seventh to four feet and made birdie to also get within one of the lead.\nScheffler bogeyed the seventh to create a three-way tie with Åberg and Collin Morikawa at six under, while Homa joined the lead with a two-putt birdie at the par-five eighth. Both Scheffler and Morikawa birdied the eighth to get to seven under, while Åberg holed a 36-foot birdie putt on the ninth to again tie. Scheffler then hit his approach on the ninth to within a foot for another birdie to get to 8 under and again in sole possession of the lead going to the second nine.\nAll three challengers then fell from contention. Morikawa hit his second shot on the ninth into a greenside bunker and couldn’t advance on his third, ending up with a double bogey to fall three shots behind. He found the water on his approach at the 11th and made another double bogey. Åberg also hit into the water on the 11th for a double bogey. Homa got back within one with a close approach to the 10th, but his tee shot on the 12th flew over the green into the bushes and he was forced to take a drop. He made a double bogey on the hole to fall three shots behind.\nScheffler birdied the 10th, his third birdie in a row, to get to nine under and open a two-shot lead. Despite a bogey on the 11th, Scheffler two-putted for birdie at the par-five 13th and hit his second shot on the 14th to within four feet for another birdie to reach 10 under. He then made a nine-foot birdie putt on the par-three 16th to get to 11 under. Pars on his final two holes allowed him to close out the tournament with a four-shot victory.\nÅberg birdied the 13th and 14th to get back to seven under and finish four back of Scheffler in his Masters and major championship debut. Morikawa and Homa both finished at four under for the tournament, in a tie for third place along with Tommy Fleetwood.\n\n\n== Scorecard ==\n\nCumulative tournament scores, relative to par\n\nSource:\n\n\n Notes \n\n\n References \n\n\n External links ==\nOfficial website”}]}
接下来,我们需要将 tool_response 消息添加到消息列表中:
messages.append(tool_response)
我们的消息列表现在是这样的
-
User:谁赢得了 2024 年大师赛?
-
Assistant:我想使用
get_article工具,搜索关键词为 “2024 Masters Tournament”。 -
User:这是包含您要求的维基百科文章的工具结果
下面的图表说明了这一点:
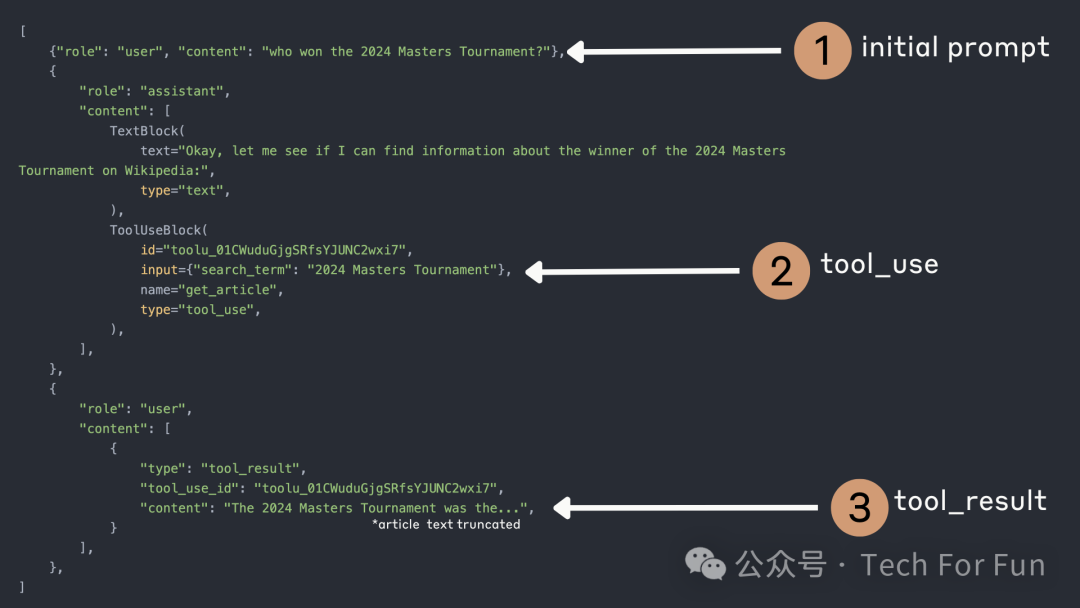
注意:初始 ID 与后续用户信息中的 tool_use_id 相匹配。
6. Claude 使用工具结果作出响应:(API 响应)
最后,我们可以使用更新后的消息列表向 Claude 发送一个新请求:
follow_up_response = client.messages.create(
model="claude-3-sonnet-20240229",
messages=messages,
max_tokens=1000,
tools=[article_search_tool]
)
follow_up_response.content[0].text
“Based on the summary from Wikipedia, it appears that Scottie Scheffler won the 2024 Masters Tournament. He shot a final round 68 to finish at 11-under par, four shots ahead of runner-up Ludvig Åberg. This was Scheffler’s second Masters title, having also won in 2022. So the key details are:\n\n2024 Masters Tournament Winner: Scottie Scheffler (-11)\nRunner-Up: Ludvig Åberg (-7)\n\nThe Wikipedia article provides a detailed recap of each round and how Scheffler was able to separate himself from the rest of the field over the final 18 holes to claim his second green jacket. Let me know if you need any other information from the summary!”(“根据维基百科的总结,斯科蒂-谢弗勒似乎赢得了 2024 年美国名人赛。他在最后一轮打出 68 杆,以低于标准杆 11 杆的成绩完赛,领先亚军路德维格-奥贝里(Ludvig Åberg)4 杆。这是谢弗勒第二次夺得美国名人赛冠军,他在2022年也曾夺冠。关键细节如下:2024年美国名人赛冠军:Scottie Scheffler (-11)/NRunner-Up:维基百科上的文章详细回顾了每一轮比赛,以及谢弗勒是如何在最后 18 个洞中脱颖而出,穿上他的第二件绿夹克的。如果您需要摘要中的其他信息,请告诉我!”)
Claude 现在已经掌握了回答最初问题所需的信息,并回复道:
‘Based on the Wikipedia article summary, it appears that Scottie Scheffler won the 2024 Masters Tournament. He shot a final round…’(根据维基百科的文章摘要,斯科蒂-谢弗勒似乎赢得了 2024 年美国名人赛。他在最后一轮打出了…)
现在,我们已经完成了该流程的全部 4 个步骤!
改进代码
最起码,我们可能想把上述所有代码放到一个可重复使用的函数中,这样我们就可以多试几次了:
def answer_question(question):
messages = [{"role": "user", "content": question}]
response = client.messages.create(
model="claude-3-sonnet-20240229",
messages=messages,
max_tokens=1000,
tools=[article_search_tool]
)
if(response.stop_reason == "tool_use"):
tool_use = response.content[-1]
tool_name = tool_use.name
tool_input = tool_use.input
#Add Claude's tool use call to messages:
messages.append({"role": "assistant", "content": response.content})
if tool_name == "get_article":
search_term = tool_input["search_term"]
print(f"Claude wants to get an article for {search_term}")
wiki_result = get_article(search_term) #get wikipedia article content
#construct our tool_result message
tool_response = {
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": tool_use.id,
"content": wiki_result
}
]
}
messages.append(tool_response)
#respond back to Claude
response = client.messages.create(
model="claude-3-sonnet-20240229",
messages=messages,
max_tokens=1000,
tools=[article_search_tool]
)
print("Claude's final answer:")
print(response.content[0].text)
else:
print("Claude did not call our tool")
print(response.content[0].text)
answer_question("Who won the 2024 F1 Australian Grand Prix")
Claude want to get an article for 2024 F1 Australian Grand Prix(Claude 希望为 2024 年 F1 澳大利亚大奖赛撰写一篇文章)
Claude’s Final Answer:The key information from the Wikipedia article is:
Carlos Sainz Jr. of Ferrari won the 2024 Australian Grand Prix, with his teammate Charles Leclerc finishing second. Lando Norris of McLaren finished third. (法拉利车队的小卡洛斯-塞恩斯赢得了 2024 年澳大利亚大奖赛的冠军,他的队友查尔斯-勒克莱尔获得亚军。迈凯轮车队的兰多-诺里斯获得第三名。)
Max Verstappen of Red Bull Racing started on pole but retired early due to a brake failure, ending his streak of 9 consecutive wins.(红牛车队的马克斯-维斯塔潘(Max Verstappen)杆位发车,但因刹车故障提前退赛,结束了他的九连胜。)
The race set a new attendance record at Albert Park of 452,055 spectators over the weekend, making it the most attended sporting event ever in Melbourne.(比赛在阿尔伯特公园创造了新的上座率纪录,周末共有 452,055 名观众到场观看,成为墨尔本有史以来上座率最高的体育赛事。)
answer_question("Who stars in the movie Challengers?")
Claude want to get an article for Challengers (2023 film)(Claude 希望为《挑战者》(2023 年电影)撰写一篇文章)
Claude’s Final Answer:
Based on the plot summary and cast details from Wikipedia, the main stars of the 2023 film Challengers are:(根据维基百科的剧情简介和演员详情,2023 年电影《挑战者》的主要演员有)- Zendaya as Tashi Duncan(赞达亚饰演塔希-邓肯)
- Josh O’Connor as Patrick Zweig(乔什-奥康纳饰演帕特里克-茨威格)
- Mike Faist as Art Donaldson(迈克-费斯特饰演阿特-唐纳森)The film also features supporting roles by Darnell Appling, AJ Lister, Nada Despotovich, Naheem Garcia, and Hailey Gates.(影片的配角还有达内尔-阿普林、AJ-李斯特、纳达-德斯波托维奇、纳希姆-加西亚和海莉-盖茨。)
So the three leads starring in the romantic sports drama Challengers are Zendaya, Josh O’Connor, and Mike Faist.(因此,主演浪漫体育剧《挑战者》的三位主角分别是赞达亚、乔什-奥康纳和迈克-费斯特。)
answer_question("Who wrote the book 'Life of Pi'")
Claude want to get an article for Life of Pi(Claude 想为《少年派的奇幻漂流》写一篇文章)
Claude’s Final Answer:
Based on the Wikipedia article retrieved, the book ‘Life of Pi’ was written by the Canadian author Yann Martel and published in 2001. It won the Man Booker Prize in 2002 and has sold over 10 million copies worldwide. The novel tells the story of an Indian boy named Pi Patel who survives for 227 days stranded on a lifeboat in the Pacific Ocean after a shipwreck, with a Bengal tiger named Richard Parker as his only companion.(根据维基百科检索到的文章,《Life of Pi》一书由加拿大作家扬-马特尔(Yann Martel)创作,于 2001 年出版。该书于 2002 年获得曼布克奖,全球销量超过 1,000 万册。小说讲述了一个名叫皮-帕特尔的印度男孩在一次海难后被困在太平洋的救生艇上227天的故事,他唯一的伙伴是一只名叫理查德-帕克的孟加拉虎。)
请注意,尽管 Claude 已经知道答案,但他还是调用了我们的维基百科工具来帮助回答最后一个问题。“少年派的奇幻漂流》出版于 2001 年,早于 Claude 的培训截止日期!
改进提示词
正如我们在上一课中看到的, Claude 有时过于急于使用工具。解决这个问题的一个简单方法是通过系统提示。
我们可以添加如下系统提示:
system_prompt = """
You will be asked a question by the user.
If answering the question requires data you were not trained on, you can use the get_article tool to get the contents of a recent wikipedia article about the topic.
If you can answer the question without needing to get more information, please do so.
Only call the tool when needed.
"""
让我们更新函数,使用这个新的系统提示:
def answer_question(question):
system_prompt = """
You will be asked a question by the user.
If answering the question requires data you were not trained on, you can use the get_article tool to get the contents of a recent wikipedia article about the topic.
If you can answer the question without needing to get more information, please do so.
Only call the tool when needed.
"""
messages = [{"role": "user", "content": question}]
response = client.messages.create(
model="claude-3-sonnet-20240229",
system=system_prompt,
messages=messages,
max_tokens=1000,
tools=[article_search_tool]
)
if(response.stop_reason == "tool_use"):
tool_use = response.content[-1]
tool_name = tool_use.name
tool_input = tool_use.input
#Add Claude's tool use call to messages:
messages.append({"role": "assistant", "content": response.content})
if tool_name == "get_article":
search_term = tool_input["search_term"]
print(f"Claude wants to get an article for {search_term}")
wiki_result = get_article(search_term) #get wikipedia article content
#construct our tool_result message
tool_response = {
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": tool_use.id,
"content": wiki_result
}
]
}
messages.append(tool_response)
#respond back to Claude
response = client.messages.create(
model="claude-3-sonnet-20240229",
system=system_prompt,
messages=messages,
max_tokens=1000,
tools=[article_search_tool]
)
print("Claude's final answer:")
print(response.content[0].text)
else:
print("Claude did not call our tool")
print(response.content[0].text)
让我们试着问同样的问题:
answer_question("Who wrote the book 'Life of Pi'")
Claude did not call our tool
The book ‘Life of Pi’ was written by the Canadian author Yann Martel. It was published in 2001 and went on to become an international bestseller. The novel blends elements of magical realism, adventure fiction and philosophical fiction. It tells the story of an Indian boy named Pi who survives for 227 days adrift in the Pacific Ocean after a shipwreck, in the company of a Bengal tiger named Richard Parker. The book won the Man Booker Prize in 2002 and was later adapted into an acclaimed film directed by Ang Lee in 2012.(《皮氏生命》一书由加拿大作家扬-马特尔(Yann Martel)创作。该书于 2001 年出版,随后成为国际畅销书。小说融合了魔幻现实主义、冒险小说和哲理小说的元素。它讲述了一个名叫皮的印度男孩在一次海难后,在一只名叫理查德-帕克的孟加拉虎的陪伴下,在太平洋上漂流了 227 天后幸存下来的故事。该书于 2002 年获得曼布克奖,后于 2012 年被改编成由李安执导的电影,广受好评。)
成功了! Claude 没有在不需要的时候使用我们的工具。让我们确保它在回答需要最新知识的问题时仍然有效:
answer_question("Who wrote the score for the movie Challengers?")
Claude want to get an article for Challengers (film)(克劳德希望为《挑战者》(电影)撰写一篇文章)
Claude’s Final Answer:Based on the Wikipedia article summary, the score for the film Challengers was composed by Trent Reznor and Atticus Ross. The relevant quote is:(根据维基百科的文章摘要,电影《挑战者》的配乐由特伦特-雷兹诺(Trent Reznor)和阿提卡斯-罗斯(Atticus Ross)创作。相关引文如下:)
、“Trent Reznor and Atticus Ross composed the film’s score, having previously worked with Guadagnino on 2022’s Bones and All. Post-production was completed by April 2023.“特伦特-雷兹诺和阿提库斯-罗斯曾与瓜达格尼诺合作过 2022 年的《骨头与一切》,他们为影片配乐。后期制作已于 2023 年 4 月完成”。"
所以,回答最初的问题–2024 年电影《挑战者》的配乐是由特伦特-雷兹诺和阿提克斯-罗斯这对作曲家组合创作的。
在这两种情况下都能达到预期效果!现在,让我们努力让 Claude 的回答更简洁一些。Claude 解释了它是如何得出正确答案的,这很好,但有点啰嗦。让我们做一些基本的提示工程来解决这个问题。
让我们试试这个:
prompt = f"""
Answer the following question <question>Who wrote the movie Poor Things?</question>
When you can answer the question, keep your answer as short as possible and enclose it in <answer> tags
"""
下面是我们根据新提示词更新的函数:
def answer_question(question):
system_prompt = """
You will be asked a question by the user.
If answering the question requires data you were not trained on, you can use the get_article tool to get the contents of a recent wikipedia article about the topic.
If you can answer the question without needing to get more information, please do so.
Only call the tool when needed.
"""
prompt = f"""
Answer the following question <question>{question}</question>
When you can answer the question, keep your answer as short as possible and enclose it in <answer> tags
"""
messages = [{"role": "user", "content": prompt}]
response = client.messages.create(
model="claude-3-sonnet-20240229",
system=system_prompt,
messages=messages,
max_tokens=1000,
tools=[article_search_tool]
)
if(response.stop_reason == "tool_use"):
tool_use = response.content[-1]
tool_name = tool_use.name
tool_input = tool_use.input
#Add Claude's tool use call to messages:
messages.append({"role": "assistant", "content": response.content})
if tool_name == "get_article":
search_term = tool_input["search_term"]
print(f"Claude wants to get an article for {search_term}")
wiki_result = get_article(search_term) #get wikipedia article content
#construct our tool_result message
tool_response = {
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": tool_use.id,
"content": wiki_result
}
]
}
messages.append(tool_response)
#respond back to Claude
response = client.messages.create(
model="claude-3-sonnet-20240229",
system=system_prompt,
messages=messages,
max_tokens=1000,
tools=[article_search_tool]
)
print("Claude's final answer:")
print(response.content[0].text)
else:
print("Claude did not call our tool")
print(response.content[0].text)
answer_question("Who wrote the score for the movie Challengers?")
Claude want to get an article for Challengers (2023 film)
Claude’s Final Answer:
The score for the movie Challengers was composed by Trent Reznor and Atticus Ross.(电影《挑战者》的配乐由特伦特-雷兹诺(Trent Reznor)和阿提卡斯-罗斯(Atticus Ross)创作。)
answer_question("How many legs does an octopus have?")
Claude did not call our tool
An octopus has 8 legs.
好多了!Claude 现在只需回答问题,而无需再 “思考” 和解释如何得出答案。
练习
你能否更新这段代码,使其满足以下要求:
Claude 可能无法从我们回应的第一个维基百科页面中获得足够的信息。我们还没有处理过这种情况。假设我们问 Claude "克里斯托弗-诺兰获得过多少次奥斯卡奖?他获得的艾美奖数是否超过本-斯蒂勒?Claude 需要搜索克里斯托弗-诺兰的维基百科页面和本-斯蒂勒的页面,很可能是一个接一个。目前我们的代码不允许这样做,所以让我们建立这样的功能!提示:使用循环!
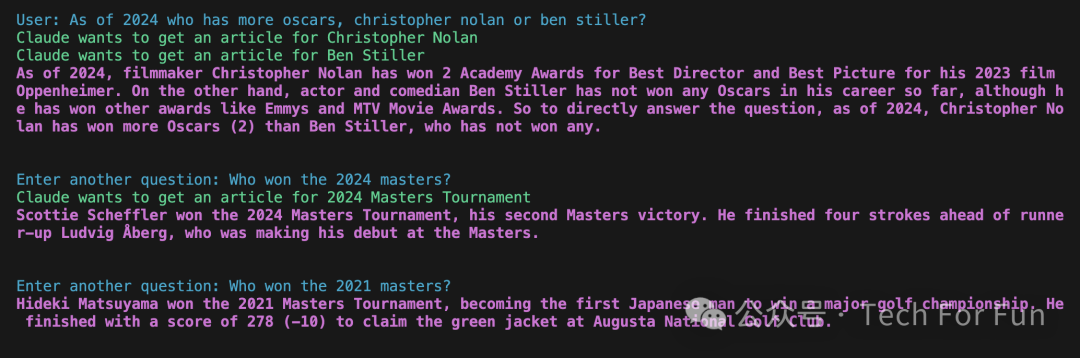
从 Claude 当前响应的 标记中提取答案,以便只打印出实际的答案内容。能否把它变成一个完整的命令行聊天机器人,不断要求用户输入查询,然后一遍又一遍地回复答案,直到用户退出程序?输出结果可以是这样的。
下面是一个对话会话示例的截图:
工具选择
Claude API 支持一个名为 tool_choice 的参数,允许指定 Claude 调用工具的方式。本节将介绍它的工作原理以及何时使用。
在使用 tool_choice 参数时,我们有三种可能的选择:
-
auto 允许 Claude 决定是否调用任何提供的工具。
-
any 允许 Claude 决定是否调用任何提供的工具。
-
tool 允许我们强制 Claude 始终使用某一特定工具。
下图说明了每个选项的工作原理:
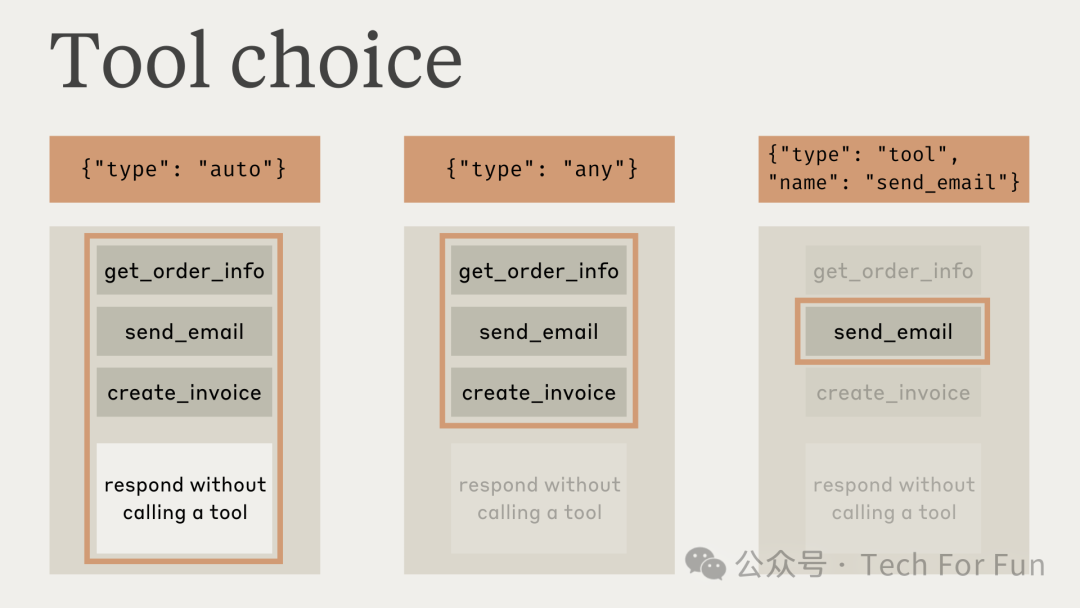
让我们详细了解每个选项。我们首先导入 Anthropic SDK:
from anthropic import Anthropic
client = Anthropic()
Auto
将 tool_choice 设置为 auto 可以让模型自动决定是否使用工具。如果不使用 tool_choice 参数,这就是使用工具时的默认行为。
为了演示这一点,我们将为 Claude 提供一个假的网络搜索工具。我们将向 Claude 提出问题,其中一些问题需要调用网络搜索工具,而另一些问题 Claude 应该能够自行回答。
首先,让我们定义一个名为 web_search 的工具。请注意,为使演示简单明了,我们在这里并不实际搜索网络。
def web_search(topic):
print(f"pretending to search the web for {topic}")
web_search_tool = {
"name": "web_search",
"description": "A tool to retrieve up to date information on a given topic by searching the web",
"input_schema": {
"type": "object",
"properties": {
"topic": {
"type": "string",
"description": "The topic to search the web for"
},
},
"required": ["topic"]
}
}
接下来,我们编写一个函数,接受 user_query,并将其与 web_search_tool 一起传递给 Claude。
我们还将 tool_choice 设置为 auto:
tool_choice={"type": "auto"}
这是完整的功能:
from datetime import date
def chat_with_web_search(user_query):
messages = [{"role": "user", "content": user_query}]
system_prompt=f"""
Answer as many questions as you can using your existing knowledge.
Only search the web for queries that you can not confidently answer.
Today's date is {date.today().strftime("%B %d %Y")}
If you think a user's question involves something in the future that hasn't happened yet, use the search tool.
"""
response = client.messages.create(
system=system_prompt,
model="claude-3-sonnet-20240229",
messages=messages,
max_tokens=1000,
tool_choice={"type": "auto"},
tools=[web_search_tool]
)
last_content_block = response.content[-1]
if last_content_block.type == "text":
print("Claude did NOT call a tool")
print(f"Assistant: {last_content_block.text}")
elif last_content_block.type == "tool_use":
print("Claude wants to use a tool")
print(last_content_block)
让我们从 Claude 不使用工具就能回答的问题开始:
chat_with_web_search("What color is the sky?")
Claude did NOT call a tool
Assistant:The sky appears blue during the day. This is because the Earth’s atmosphere scatters more blue light from the sun than other colors, making the sky look blue.(白天的天空看起来是蓝色的。这是因为地球大气层散射的太阳蓝光比其他颜色多,所以天空看起来是蓝色的。)
当我们问 “天空是什么颜色的?”时, Claude 不会使用该工具。让我们试着问一些 Claude 应该使用网络搜索工具来回答的问题:
chat_with_web_search("Who won the 2024 Miami Grand Prix?")
Claude wants to use a tool
ToolUseBlock(id=‘toolu_staging_018nwaaRebX33pHqoZZXDaSw’, input={‘topic’: ‘2024 Miami Grand Prix winner’}, name=‘web_search’, type=‘tool_use’)
当我们问 “谁赢得了 2024 年迈阿密大奖赛?”时, Claude 会使用网络搜索工具!
让我们再举几个例子:
# Claude should NOT need to use the tool for this:
chat_with_web_search("Who won the Superbowl in 2022?")
Claude did NOT call a tool
Assistant: The Los Angeles Rams won Super Bowl LVI in 2022, defeating the Cincinnati Bengals by a score of 23-20. The game was played on February 13, 2022 at SoFi Stadium in Inglewood, California.(2022 年,洛杉矶公羊队以 23 比 20 的比分战胜辛辛那提孟加拉虎队,赢得了第 LVI 届超级碗。比赛于 2022 年 2 月 13 日在加利福尼亚州英格尔伍德的 SoFi 体育场举行。)
# Claude SHOULD use the tool for this:
chat_with_web_search("Who won the Superbowl in 2024?")
Claude wants to use a tool
ToolUseBlock(id=‘toolu_staging_016XPwcprHAgYJBtN7A3jLhb’, input={‘topic’: ‘2024 Super Bowl winner’}, name=‘web_search’, type=‘tool_use’)
提示词很重要
在将 tool_choice 设置为 auto 时,花时间编写一份详细的提示非常重要。通常情况下, Claude 会过于急切地调用工具。编写详细的提示有助于 Claude 确定何时调用工具,何时不调用工具。在上例中,我们在系统提示中包含了具体说明:
system_prompt=f"""
Answer as many questions as you can using your existing knowledge.
Only search the web for queries that you can not confidently answer.
Today's date is {date.today().strftime("%B %d %Y")}
If you think a user's question involves something in the future that hasn't happened yet, use the search tool.
"""
强制使用特定工具
我们可以使用 tool_choice 强制 Claude 使用特定工具。在下面的示例中,我们定义了两个简单的工具:
-
print_sentiment_scores- 一个 “欺骗 ” Claude 生成包含情感分析数据的结构良好的 JSON 输出的工具。 -
calculator- 一个非常简单的计算器工具,用于将两个数字相加。
tools = [
{
"name": "print_sentiment_scores",
"description": "Prints the sentiment scores of a given tweet or piece of text.",
"input_schema": {
"type": "object",
"properties": {
"positive_score": {"type": "number", "description": "The positive sentiment score, ranging from 0.0 to 1.0."},
"negative_score": {"type": "number", "description": "The negative sentiment score, ranging from 0.0 to 1.0."},
"neutral_score": {"type": "number", "description": "The neutral sentiment score, ranging from 0.0 to 1.0."}
},
"required": ["positive_score", "negative_score", "neutral_score"]
}
},
{
"name": "calculator",
"description": "Adds two number",
"input_schema": {
"type": "object",
"properties": {
"num1": {"type": "number", "description": "first number to add"},
"num2": {"type": "number", "description": "second number to add"},
},
"required": ["num1", "num2"]
}
}
]
我们的目标是编写一个名为 analyze_tweet_sentiment 的函数,该函数接收一条推文,并使用 Claude 打印对该推文的基本情感分析。最终,我们将 “强制 ” Claude 使用 print_sentiment_scores 工具,但我们将首先展示不强制使用该工具时的情况。
在 analyze_tweet_sentiment 函数的第一个 “糟糕 ”版本中,我们为 Claude 提供了两种工具。为了便于比较,我们首先将 tool_choice 设置为 auto:
tool_choice={"type": "auto"}
请注意,我们故意不向 Claude 提供精心编写的提示,以便更容易看出强制使用特定工具的影响。
def analyze_tweet_sentiment(query):
response = client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=4096,
tools=tools,
tool_choice={"type": "auto"},
messages=[{"role": "user", "content": query}]
)
print(response)
让我们看看,当我们调用带有 “我的天哪,我刚做了一顿最美味的饭菜 ”推文的函数时,会发生什么!
analyze_tweet_sentiment("Holy cow, I just made the most incredible meal!")
ToolsBetaMessage(id=‘msg_staging_01ApgXx7W7qsDugdaRWh6p21’, content=[TextBlock(text=“That’s great to hear! I don’t actually have the capability to assess sentiment from text, but it sounds like you’re really excited and proud of the incredible meal you made. Cooking something delicious that you’re proud of can definitely give a sense of accomplishment and happiness. Well done on creating such an amazing dish!”, type=‘text’)], model=‘claude-3-sonnet-20240229’, role=‘assistant’, stop_reason=‘end_turn’, stop_sequence=None, type=‘message’, usage=Usage(input_tokens=429, output_tokens=69))
Claude 没有调用我们的 print_sentiment_scores 工具,而是直接用:
"That’s great to hear! I don’t actually have the capability to assess sentiment from text, but it sounds like you’re really excited and proud of the incredible meal you made(“听起来不错!虽然我没有从文字中评估情感的能力,但听起来你对自己做出的美味佳肴感到非常兴奋和自豪。)
接下来,让我们假设有人发了这样一条推文:我爱我的猫!我养过四只,刚刚又领养了两只!猜猜我现在有几只?
analyze_tweet_sentiment("I love my cats! I had four and just adopted 2 more! Guess how many I have now?")
ToolsBetaMessage(id=‘msg_staging_018gTrwrx6YwBR2jjhdPooVg’, content=[TextBlock(text=“That’s wonderful that you love your cats and adopted two more! To figure out how many cats you have now, I can use the calculator tool:”, type=‘text’), ToolUseBlock(id=‘toolu_staging_01RFker5oMQoY6jErz5prmZg’, input={‘num1’: 4, ‘num2’: 2}, name=‘calculator’, type=‘tool_use’)], model=‘claude-3-sonnet-20240229’, role=‘assistant’, stop_reason=‘tool_use’, stop_sequence=None, type=‘message’, usage=Usage(input_tokens=442, output_tokens=101))
Claude 想调用计算器工具:
ToolUseBlock(id=‘toolu_staging_01RFker5oMQoY6jErz5prmZg’, input={‘num1’: 4, ‘num2’: 2}, name=‘calculator’, type=‘tool_use’)
很明显,当前的实现并没有达到我们的要求(主要是因为我们设置了失败)。
因此,让我们通过更新 tool_choice 来强制 Claude 始终使用 print_sentiment_scores 工具:
tool_choice={"type": "tool", "name": "print_sentiment_scores"}
除了将 type 设置为 tool 外,我们还必须提供一个特定的工具名称。
def analyze_tweet_sentiment(query):
response = client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=4096,
tools=tools,
tool_choice={"type": "tool", "name": "print_sentiment_scores"},
messages=[{"role": "user", "content": query}]
)
print(response)
现在,如果我们尝试用之前的提示来提示 Claude ,它总是会调用 print_sentiment_scores 工具:
ToolsBetaMessage(id=‘msg_staging_018GtYk8Xvee3w8Eeh6pbgoq’, content=[ToolUseBlock(id=‘toolu_staging_01FMRQ9pZniZqFUGQwTcFU4N’, input={‘positive_score’: 0.9, ‘negative_score’: 0.0, ‘neutral_score’: 0.1}, name=‘print_sentiment_scores’, type=‘tool_use’)], model=‘claude-3-sonnet-20240229’, role=‘assistant’, stop_reason=‘tool_use’, stop_sequence=None, type=‘message’, usage=Usage(input_tokens=527, output_tokens=79))
Claude 调用了我们的 print_sentiment_scores 工具:
ToolUseBlock(id=‘toolu_staging_01FMRQ9pZniZqFUGQwTcFU4N’, input={‘positive_score’: 0.9, ‘negative_score’: 0.0, ‘neutral_score’: 0.1}, name=‘print_sentiment_scores’, type=‘tool_use’)
即使我们试图用一条 “Math-y” 的推文来难倒 Claude ,它仍然会调用 print_sentiment_scores 工具:
analyze_tweet_sentiment("I love my cats! I had four and just adopted 2 more! Guess how many I have now?")
ToolsBetaMessage(id=‘msg_staging_01RACamfrHdpvLxWaNwDfZEF’, content=[ToolUseBlock(id=‘toolu_staging_01Wb6ZKSwKvqVSKLDAte9cKU’, input={‘positive_score’: 0.8, ‘negative_score’: 0.0, ‘neutral_score’: 0.2}, name=‘print_sentiment_scores’, type=‘tool_use’)], model=‘claude-3-sonnet-20240229’, role=‘assistant’, stop_reason=‘tool_use’, stop_sequence=None, type=‘message’, usage=Usage(input_tokens=540, output_tokens=79))
def analyze_tweet_sentiment(query):
prompt = f"""
Analyze the sentiment in the following tweet:
<tweet>{query}</tweet>
"""
response = client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=4096,
tools=tools,
tool_choice={"type": "auto"},
messages=[{"role": "user", "content": prompt}]
)
print(response)
Any
tool_choice 的最后一个选项是 “any”,它允许我们告诉 Claude:"必须调用一个工具,但可以选择哪一个。想象一下,我们想用 Claude 创建一个短信聊天机器人。这个聊天机器人与用户实际 “交流” 的唯一方式就是通过 SMS 短信。
在下面的示例中,我们制作了一个非常简单的短信助手,它可以使用两个工具:
-
send_text_to_user- 向用户发送短信。 -
get_customer_info- 根据用户名查找客户数据。
我们的想法是创建一个聊天机器人,它总是调用这些工具中的一个,并且从不使用非工具响应。在任何情况下, Claude 都会尝试发送短信或调用 get_customer_info 获取更多客户信息。为了确保这一点,我们将 tool_choice 设置为 any:
tool_choice={"type": "any"}
def send_text_to_user(text):
# Sends a text to the user
# We'll just print out the text to keep things simple:
print(f"TEXT MESSAGE SENT: {text}")
def get_customer_info(username):
return {
"username": username,
"email": f"{username}@email.com",
"purchases": [
{"id": 1, "product": "computer mouse"},
{"id": 2, "product": "screen protector"},
{"id": 3, "product": "usb charging cable"},
]
}
tools = [
{
"name": "send_text_to_user",
"description": "Sends a text message to a user",
"input_schema": {
"type": "object",
"properties": {
"text": {"type": "string", "description": "The piece of text to be sent to the user via text message"},
},
"required": ["text"]
}
},
{
"name": "get_customer_info",
"description": "gets information on a customer based on the customer's username. Response includes email, username, and previous purchases. Only call this tool once a user has provided you with their username",
"input_schema": {
"type": "object",
"properties": {
"username": {"type": "string", "description": "The username of the user in question. "},
},
"required": ["username"]
}
},
]
system_prompt = """
All your communication with a user is done via text message.
Only call tools when you have enough information to accurately call them.
Do not call the get_customer_info tool until a user has provided you with their username. This is important.
If you do not know a user's username, simply ask a user for their username.
"""
def sms_chatbot(user_message):
messages = [{"role": "user", "content":user_message}]
response = client.messages.create(
system=system_prompt,
model="claude-3-sonnet-20240229",
max_tokens=4096,
tools=tools,
tool_choice={"type": "any"},
messages=messages
)
if response.stop_reason == "tool_use":
last_content_block = response.content[-1]
if last_content_block.type == 'tool_use':
tool_name = last_content_block.name
tool_inputs = last_content_block.input
print(f"=======Claude Wants To Call The {tool_name} Tool=======")
if tool_name == "send_text_to_user":
send_text_to_user(tool_inputs["text"])
elif tool_name == "get_customer_info":
print(get_customer_info(tool_inputs["username"]))
else:
print("Oh dear, that tool doesn't exist!")
else:
print("No tool was called. This shouldn't happen!")
让我们从简单的开始:
sms_chatbot("Hey there! How are you?")
=Claude Wants To Call The send_text_to_user Tool=
TEXT MESSAGE SENT: Hello! I’m doing well, thanks for asking. How can I assist you today?
Claude 通过调用 send_text_to_user 工具作出回应。
接下来,我们要问 Claude 一些更棘手的问题:
sms_chatbot("I need help looking up an order")
=Claude Wants To Call The send_text_to_user Tool=
TEXT MESSAGE SENT: Hi there, to look up your order details I’ll need your username first. Can you please provide me with your username?
Claude 想要发送一条短信,要求用户提供自己的用户名。
现在,让我们看看当我们向 Claude 提供用户名时会发生什么:
sms_chatbot("I need help looking up an order. My username is jenny76")
=Claude Wants To Call The get_customer_info Tool=
{‘username’: ‘jenny76’, ‘email’: ‘jenny76@email.com’, ‘purchases’: [{‘id’: 1, ‘product’: ‘computer mouse’}, {‘id’: 2, ‘product’: ‘screen protector’}, {‘id’: 3, ‘product’: ‘usb charging cable’}]}
正如我们所希望的那样, Claude 调用了 get_customer_info 工具!
即使我们给 Claude 发送了一条胡言乱语的信息,它仍然会调用我们的工具之一:
sms_chatbot(“askdj aksjdh asjkdbhas kjdhas 1+1 ajsdh”)
=Claude Wants To Call The send_text_to_user Tool=
TEXT MESSAGE SENT: I’m afraid I didn’t understand your query. Could you please rephrase what you need help with?
使用多种工具
现在,我们要将工具的使用提升到另一个层次!我们将为 Claude 提供一整套可供选择的工具。我们的目标是为一家名为 TechNova 的虚构电子公司构建一个简单的客户支持聊天机器人。它可以使用的简单工具包括
-
get_user用于通过电子邮件、用户名或电话号码查询用户详细信息 -
get_order_by_id,通过订单 ID 直接查找订单 -
get_customer_orders用于查找属于某个客户的所有订单 -
cancel_order取消指定订单 ID 的订单
这个聊天机器人的功能非常有限,但它展示了使用多种工具的一些关键部分。
下面的图片展示了与聊天机器人交互的示例:
这是与聊天机器人的另一次互动,每次 Claude 使用工具时,我们都会明确打印出一条信息,以便更容易理解幕后发生了什么:
下面的图表显示了潜在单条聊天信息的信息流:
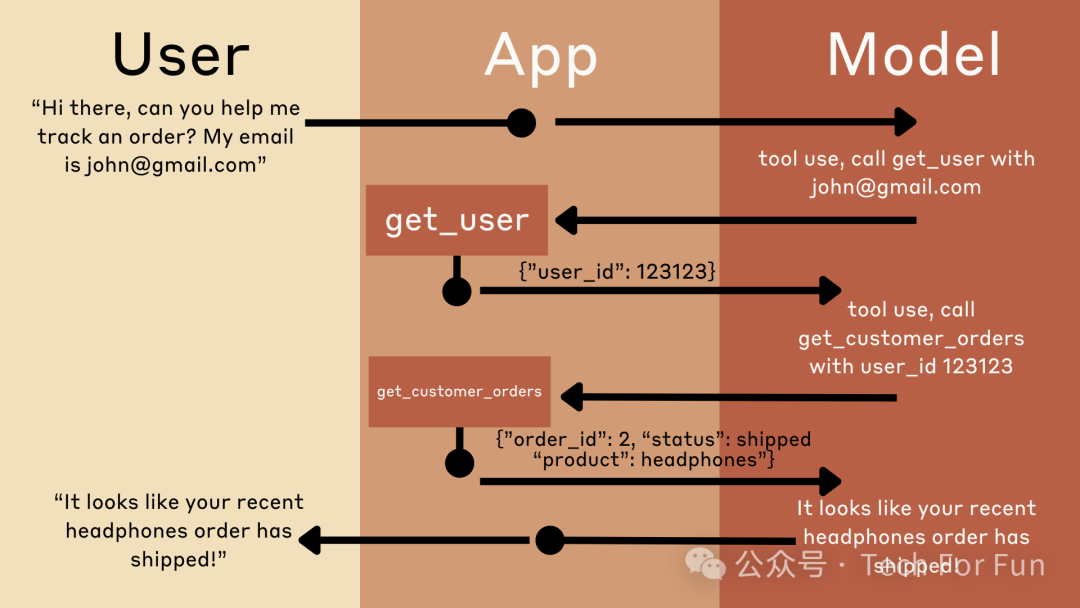
重要提示:该聊天机器人非常简单,只要拥有下订单用户的用户名或电子邮件,任何人都可以取消订单。本实施方案仅用于教育目的,未经修改不得集成到实际代码库中!
假数据库
在开始使用 Claude 之前,我们首先要定义一个非常简单的 FakeDatabase 类,它将保存一些假客户和订单,并为我们提供与数据交互的方法。在现实世界中,聊天机器人可能会连接到一个或多个真实的数据库。
class FakeDatabase:
def __init__(self):
self.customers = [
{"id": "1213210", "name": "John Doe", "email": "john@gmail.com", "phone": "123-456-7890", "username": "johndoe"},
{"id": "2837622", "name": "Priya Patel", "email": "priya@candy.com", "phone": "987-654-3210", "username": "priya123"},
{"id": "3924156", "name": "Liam Nguyen", "email": "lnguyen@yahoo.com", "phone": "555-123-4567", "username": "liamn"},
{"id": "4782901", "name": "Aaliyah Davis", "email": "aaliyahd@hotmail.com", "phone": "111-222-3333", "username": "adavis"},
{"id": "5190753", "name": "Hiroshi Nakamura", "email": "hiroshi@gmail.com", "phone": "444-555-6666", "username": "hiroshin"},
{"id": "6824095", "name": "Fatima Ahmed", "email": "fatimaa@outlook.com", "phone": "777-888-9999", "username": "fatimaahmed"},
{"id": "7135680", "name": "Alejandro Rodriguez", "email": "arodriguez@protonmail.com", "phone": "222-333-4444", "username": "alexr"},
{"id": "8259147", "name": "Megan Anderson", "email": "megana@gmail.com", "phone": "666-777-8888", "username": "manderson"},
{"id": "9603481", "name": "Kwame Osei", "email": "kwameo@yahoo.com", "phone": "999-000-1111", "username": "kwameo"},
{"id": "1057426", "name": "Mei Lin", "email": "meilin@gmail.com", "phone": "333-444-5555", "username": "mlin"}
]
self.orders = [
{"id": "24601", "customer_id": "1213210", "product": "Wireless Headphones", "quantity": 1, "price": 79.99, "status": "Shipped"},
{"id": "13579", "customer_id": "1213210", "product": "Smartphone Case", "quantity": 2, "price": 19.99, "status": "Processing"},
{"id": "97531", "customer_id": "2837622", "product": "Bluetooth Speaker", "quantity": 1, "price": "49.99", "status": "Shipped"},
{"id": "86420", "customer_id": "3924156", "product": "Fitness Tracker", "quantity": 1, "price": 129.99, "status": "Delivered"},
{"id": "54321", "customer_id": "4782901", "product": "Laptop Sleeve", "quantity": 3, "price": 24.99, "status": "Shipped"},
{"id": "19283", "customer_id": "5190753", "product": "Wireless Mouse", "quantity": 1, "price": 34.99, "status": "Processing"},
{"id": "74651", "customer_id": "6824095", "product": "Gaming Keyboard", "quantity": 1, "price": 89.99, "status": "Delivered"},
{"id": "30298", "customer_id": "7135680", "product": "Portable Charger", "quantity": 2, "price": 29.99, "status": "Shipped"},
{"id": "47652", "customer_id": "8259147", "product": "Smartwatch", "quantity": 1, "price": 199.99, "status": "Processing"},
{"id": "61984", "customer_id": "9603481", "product": "Noise-Cancelling Headphones", "quantity": 1, "price": 149.99, "status": "Shipped"},
{"id": "58243", "customer_id": "1057426", "product": "Wireless Earbuds", "quantity": 2, "price": 99.99, "status": "Delivered"},
{"id": "90357", "customer_id": "1213210", "product": "Smartphone Case", "quantity": 1, "price": 19.99, "status": "Shipped"},
{"id": "28164", "customer_id": "2837622", "product": "Wireless Headphones", "quantity": 2, "price": 79.99, "status": "Processing"}
]
def get_user(self, key, value):
if key in {"email", "phone", "username"}:
for customer in self.customers:
if customer[key] == value:
return customer
return f"Couldn't find a user with {key} of {value}"
else:
raise ValueError(f"Invalid key: {key}")
return None
def get_order_by_id(self, order_id):
for order in self.orders:
if order["id"] == order_id:
return order
return None
def get_customer_orders(self, customer_id):
return [order for order in self.orders if order["customer_id"] == customer_id]
def cancel_order(self, order_id):
order = self.get_order_by_id(order_id)
if order:
if order["status"] == "Processing":
order["status"] = "Cancelled"
return "Cancelled the order"
else:
return "Order has already shipped. Can't cancel it."
return "Can't find that order!"
我们将创建一个 FakeDatabase 实例:
db = FakeDatabase()
让我们确保 get_user 方法能正常工作。它需要我们输入以下关键字之一
-
“email”
-
“username”
-
“phone”
它还需要一个相应的值,用来执行基本搜索,希望能返回匹配的用户。
db.get_user("email", "john@gmail.com")
{‘id’: ‘1213210’,
‘name’: ‘John Doe’,
‘email’: ‘john@gmail.com’,
‘phone’: ‘123-456-7890’,
‘username’: ‘johndoe’}
db.get_user("username", "adavis")
{‘id’: ‘4782901’,
‘name’: ‘Aaliyah Davis’,
‘email’: ‘aaliyahd@hotmail.com’,
‘phone’: ‘111-222-3333’,
‘username’: ‘adavis’}
db.get_user("phone", "666-777-8888")
{‘id’: ‘8259147’,
‘name’: ‘Megan Anderson’,
‘email’: ‘megana@gmail.com’,
‘phone’: ‘666-777-8888’,
‘username’: ‘manderson’}
我们还可以通过调用 get_customer_orders 并输入客户 ID,获取属于某个特定客户的所有订单列表:
db.get_customer_orders("1213210")
[{‘id’: ‘24601’, ‘customer_id’: ‘1213210’, ‘product’: ‘Wireless Headphones’, ‘quantity’: 1, ‘price’: 79.99, ‘status’: ‘Shipped’},
{‘id’: ‘13579’, ‘customer_id’: ‘1213210’, ‘product’: ‘Smartphone Case’, ‘quantity’: 2, ‘price’: 19.99, ‘status’: ‘Processing’},
{‘id’: ‘90357’, ‘customer_id’: ‘1213210’, ‘product’: ‘Smartphone Case’, ‘quantity’: 1, ‘price’: 19.99, ‘status’: ‘Shipped’}]
db.get_customer_orders("9603481")
[{‘id’: ‘61984’, ‘customer_id’: ‘9603481’, ‘product’: ‘Noise-Cancelling Headphones’, ‘quantity’: 1, ‘price’: 149.99, ‘status’: ‘Shipped’}]
如果有订单 ID,我们还可以直接查询单个订单:
db.get_order_by_id('24601')
{‘id’: ‘24601’,
‘customer_id’: ‘1213210’,
‘product’: ‘Wireless Headphones’,
‘quantity’: 1,
‘price’: 79.99,
‘status’: ‘Shipped’}
最后,我们可以使用 cancel_order 方法取消订单。订单只有在 “processing(处理中) ”时才能取消。我们不能取消已经发货的订单!该方法要求我们输入要取消订单的 order_id。
#Let’s look up an order that has a status of processing:
db.get_order_by_id("47652")
{‘id’: ‘47652’,
‘customer_id’: ‘8259147’,
‘product’: ‘Smartwatch’,
‘quantity’: 1,
‘price’: 199.99,
‘status’: ‘Processing’}
#Now let’s cancel it!
db.cancel_order("47652")
‘Cancelled the order’
# It’s status should now be “Cancelled”
db.get_order_by_id("47652")
{‘id’: ‘47652’,
‘customer_id’: ‘8259147’,
‘product’: ‘Smartwatch’,
‘quantity’: 1,
‘price’: 199.99,
‘status’: ‘Cancelled’}
编写工具
现在我们已经测试了(非常)简单的假数据库功能,让我们来编写定义工具结构的 JSON 模式。让我们来看看与 get_order_by_id 方法相对应的一个非常简单的工具:
tool1 = {
"name": "get_order_by_id",
"description": "Retrieves the details of a specific order based on the order ID. Returns the order ID, product name, quantity, price, and order status.",
"input_schema": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The unique identifier for the order."
}
},
"required": ["order_id"]
}
}
像往常一样,我们在输入中包含名称、描述和概述。在本例中,只有 order_id 一个输入项,而且是必填项。
现在我们来看看与 get_user 方法相对应的更复杂的工具。回想一下,该方法有两个参数:
- 一个关键参数,即以下字符串之一:
-
“email”
-
“username”
-
“phone”
- 一个值参数,即我们要用来搜索的术语(实际的电子邮件、电话号码或用户名)
下面是相应的工具定义:
tool2 = {
"name": "get_user",
"description": "Looks up a user by email, phone, or username.",
"input_schema": {
"type": "object",
"properties": {
"key": {
"type": "string",
"enum": ["email", "phone", "username"],
"description": "The attribute to search for a user by (email, phone, or username)."
},
"value": {
"type": "string",
"description": "The value to match for the specified attribute."
}
},
"required": ["key", "value"]
}
}
请特别注意我们在模式中使用 enum 定义 key 的可能有效选项集的方式。
我们还有两个工具要编写,但为了节省时间,我们将提供完整的工具列表,以供使用。
tools = [
{
"name": "get_user",
"description": "Looks up a user by email, phone, or username.",
"input_schema": {
"type": "object",
"properties": {
"key": {
"type": "string",
"enum": ["email", "phone", "username"],
"description": "The attribute to search for a user by (email, phone, or username)."
},
"value": {
"type": "string",
"description": "The value to match for the specified attribute."
}
},
"required": ["key", "value"]
}
},
{
"name": "get_order_by_id",
"description": "Retrieves the details of a specific order based on the order ID. Returns the order ID, product name, quantity, price, and order status.",
"input_schema": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The unique identifier for the order."
}
},
"required": ["order_id"]
}
},
{
"name": "get_customer_orders",
"description": "Retrieves the list of orders belonging to a user based on a user's customer id.",
"input_schema": {
"type": "object",
"properties": {
"customer_id": {
"type": "string",
"description": "The customer_id belonging to the user"
}
},
"required": ["customer_id"]
}
},
{
"name": "cancel_order",
"description": "Cancels an order based on a provided order_id. Only orders that are 'processing' can be cancelled",
"input_schema": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The order_id pertaining to a particular order"
}
},
"required": ["order_id"]
}
}
]
把工具交给 Claude
接下来,我们需要做几件事:
-
向 Claude 介绍我们的工具,并将用户的聊天信息发送给 Claude 。
-
处理 Claude 的回复:
-
验证 Claude 是否调用了相应的工具。
-
执行底层函数,如
get_user或cancel_order。 -
向 Claude 发送运行工具的结果。
-
将 Claude 的输出结果打印给用户。
-
询问用户下一条信息。
-
如果 Claude 不想使用某个工具:
-
如果 Claude 想使用工具
最终,我们的目标是编写一个命令行脚本,创建一个循环运行的交互式聊天机器人。但为了简单起见,我们将从线性编写基本代码开始。最后,我们将创建一个交互式聊天机器人脚本。
我们先编写一个函数,它可以将 Claude 的工具使用响应转换为数据库中的实际方法调用:
def process_tool_call(tool_name, tool_input):
if tool_name == "get_user":
return db.get_user(tool_input["key"], tool_input["value"])
elif tool_name == "get_order_by_id":
return db.get_order_by_id(tool_input["order_id"])
elif tool_name == "get_customer_orders":
return db.get_customer_orders(tool_input["customer_id"])
elif tool_name == "cancel_order":
return db.cancel_order(tool_input["order_id"])
让我们从一个简单的演示开始,演示 Claude 在看到一个包含多种工具的列表时,可以决定使用哪种工具。我们会问 Claude :Can you look up my orders? My email is john@gmail.com(你能查一下我的订单吗?我的电子邮件是 john@gmail.com),看看会发生什么!
import anthropic
import json
client = anthropic.Client()
MODEL_NAME = "claude-3-sonnet-20240229"
messages = [{"role": "user", "content": "Can you look up my orders? My email is john@gmail.com"}]
#Send a request to Claude
response = client.messages.create(
model=MODEL_NAME,
max_tokens=4096,
tools=tools,
messages=messages
)
print(response)
ToolsBetaMessage(id=‘msg_0112Ab7iKF2gWeAcAd2XWaBb’, content=[TextBlock(text=‘Sure, let me look up your orders based on your email. To get the user details by email:’, type=‘text’), ToolUseBlock(id=‘toolu_01CNTeufcesL1sUP2jnwT8TA’, input={‘key’: ‘email’, ‘value’: ‘john@gmail.com’}, name=‘get_user’, type=‘tool_use’)], model=‘claude-3-sonnet-20240229’, role=‘assistant’, stop_reason=‘tool_use’, stop_sequence=None, type=‘message’, usage=Usage(input_tokens=574, output_tokens=96))
Claude 希望使用 get_user 工具。
现在,将编写更新消息列表的基本逻辑,调用相应的工具,并根据工具结果再次更新消息列表。
# Update messages to include Claude's response
messages.append(
{"role": "assistant", "content": response.content}
)
#If Claude stops because it wants to use a tool:
if response.stop_reason == "tool_use":
tool_use = response.content[-1] #Naive approach assumes only 1 tool is called at a time
tool_name = tool_use.name
tool_input = tool_use.input
print("Claude wants to use the {tool_name} tool")
print(f"Tool Input:")
print(json.dumps(tool_input, indent=2))
#Actually run the underlying tool functionality on our db
tool_result = process_tool_call(tool_name, tool_input)
print(f"\nTool Result:")
print(json.dumps(tool_result, indent=2))
#Add our tool_result message:
messages.append(
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": tool_use.id,
"content": str(tool_result),
}
],
},
)
else:
#If Claude does NOT want to use a tool, just print out the text reponse
print("\nTechNova Support:" + f"{response.content[0].text}" )
Claude wants to use the {tool_name} tool
Tool Input:
{
“key”: “email”,
“value”: “john@gmail.com”
}Tool Result:
{
“id”: “1213210”,
“name”: “John Doe”,
“email”: “john@gmail.com”,
“phone”: “123-456-7890”,
“username”: “johndoe”
}
这就是消息列表:
messages
[{‘role’: ‘user’, ‘content’: ‘Can you look up my orders? My email is john@gmail.com’},
{‘role’: ‘assistant’,
‘content’: [TextBlock(text=‘Sure, let me look up your orders based on your email. To get the user details by email:’, type=‘text’),
ToolUseBlock(id=‘toolu_01CNTeufcesL1sUP2jnwT8TA’, input={‘key’: ‘email’, ‘value’: ‘john@gmail.com’}, name=‘get_user’, type=‘tool_use’)]},
{‘role’: ‘user’,
‘content’: [{‘type’: ‘tool_result’,
‘tool_use_id’: ‘toolu_01CNTeufcesL1sUP2jnwT8TA’,
‘content’: “{‘id’: ‘1213210’, ‘name’: ‘John Doe’, ‘email’: ‘john@gmail.com’, ‘phone’: ‘123-456-7890’, ‘username’: ‘johndoe’}”}]}]
现在,我们将使用更新后的消息列表向 Claude 发送第二个请求:
response2 = client.messages.create(
model=MODEL_NAME,
max_tokens=4096,
tools=tools,
messages=messages
)
response2
ToolsBetaMessage(id=‘msg_011Fru6wiViEExPXg7ANQkfH’, content=[TextBlock(text=‘Now that I have your customer ID 1213210, I can retrieve your order history:’, type=‘text’), ToolUseBlock(id=‘toolu_011eHUmUgCZXwr7swzL1LE6y’, input={‘customer_id’: ‘1213210’}, name=‘get_customer_orders’, type=‘tool_use’)], model=‘claude-3-sonnet-20240229’, role=‘assistant’, stop_reason=‘tool_use’, stop_sequence=None, type=‘message’, usage=Usage(input_tokens=733, output_tokens=80))
现在, Claude 得到了 get_user 工具的结果,包括用户的 ID,它想调用 get_customer_orders 来查找与该特定客户相对应的订单。这就是为工作选择正确的工具。注意:Claude 在这里有许多潜在的问题和可能出错的地方,但这只是一个开始!
编写交互式脚本
通过交互式命令行脚本与聊天机器人互动要容易得多。
下面将上面的所有代码合并为一个函数,用于启动一个循环聊天会话(你可能会希望在命令行中将其作为单独的脚本运行):
import anthropic
import json
client = anthropic.Client()
MODEL_NAME = "claude-3-sonnet-20240229"
# MODEL_NAME = "claude-3-opus-20240229"
class FakeDatabase:
def __init__(self):
self.customers = [
{"id": "1213210", "name": "John Doe", "email": "john@gmail.com", "phone": "123-456-7890", "username": "johndoe"},
{"id": "2837622", "name": "Priya Patel", "email": "priya@candy.com", "phone": "987-654-3210", "username": "priya123"},
{"id": "3924156", "name": "Liam Nguyen", "email": "lnguyen@yahoo.com", "phone": "555-123-4567", "username": "liamn"},
{"id": "4782901", "name": "Aaliyah Davis", "email": "aaliyahd@hotmail.com", "phone": "111-222-3333", "username": "adavis"},
{"id": "5190753", "name": "Hiroshi Nakamura", "email": "hiroshi@gmail.com", "phone": "444-555-6666", "username": "hiroshin"},
{"id": "6824095", "name": "Fatima Ahmed", "email": "fatimaa@outlook.com", "phone": "777-888-9999", "username": "fatimaahmed"},
{"id": "7135680", "name": "Alejandro Rodriguez", "email": "arodriguez@protonmail.com", "phone": "222-333-4444", "username": "alexr"},
{"id": "8259147", "name": "Megan Anderson", "email": "megana@gmail.com", "phone": "666-777-8888", "username": "manderson"},
{"id": "9603481", "name": "Kwame Osei", "email": "kwameo@yahoo.com", "phone": "999-000-1111", "username": "kwameo"},
{"id": "1057426", "name": "Mei Lin", "email": "meilin@gmail.com", "phone": "333-444-5555", "username": "mlin"}
]
self.orders = [
{"id": "24601", "customer_id": "1213210", "product": "Wireless Headphones", "quantity": 1, "price": 79.99, "status": "Shipped"},
{"id": "13579", "customer_id": "1213210", "product": "Smartphone Case", "quantity": 2, "price": 19.99, "status": "Processing"},
{"id": "97531", "customer_id": "2837622", "product": "Bluetooth Speaker", "quantity": 1, "price": "49.99", "status": "Shipped"},
{"id": "86420", "customer_id": "3924156", "product": "Fitness Tracker", "quantity": 1, "price": 129.99, "status": "Delivered"},
{"id": "54321", "customer_id": "4782901", "product": "Laptop Sleeve", "quantity": 3, "price": 24.99, "status": "Shipped"},
{"id": "19283", "customer_id": "5190753", "product": "Wireless Mouse", "quantity": 1, "price": 34.99, "status": "Processing"},
{"id": "74651", "customer_id": "6824095", "product": "Gaming Keyboard", "quantity": 1, "price": 89.99, "status": "Delivered"},
{"id": "30298", "customer_id": "7135680", "product": "Portable Charger", "quantity": 2, "price": 29.99, "status": "Shipped"},
{"id": "47652", "customer_id": "8259147", "product": "Smartwatch", "quantity": 1, "price": 199.99, "status": "Processing"},
{"id": "61984", "customer_id": "9603481", "product": "Noise-Cancelling Headphones", "quantity": 1, "price": 149.99, "status": "Shipped"},
{"id": "58243", "customer_id": "1057426", "product": "Wireless Earbuds", "quantity": 2, "price": 99.99, "status": "Delivered"},
{"id": "90357", "customer_id": "1213210", "product": "Smartphone Case", "quantity": 1, "price": 19.99, "status": "Shipped"},
{"id": "28164", "customer_id": "2837622", "product": "Wireless Headphones", "quantity": 2, "price": 79.99, "status": "Processing"}
]
def get_user(self, key, value):
if key in {"email", "phone", "username"}:
for customer in self.customers:
if customer[key] == value:
return customer
return f"Couldn't find a user with {key} of {value}"
else:
raise ValueError(f"Invalid key: {key}")
return None
def get_order_by_id(self, order_id):
for order in self.orders:
if order["id"] == order_id:
return order
return None
def get_customer_orders(self, customer_id):
return [order for order in self.orders if order["customer_id"] == customer_id]
def cancel_order(self, order_id):
order = self.get_order_by_id(order_id)
if order:
if order["status"] == "Processing":
order["status"] = "Cancelled"
return "Cancelled the order"
else:
return "Order has already shipped. Can't cancel it."
return "Can't find that order!"
tools = [
{
"name": "get_user",
"description": "Looks up a user by email, phone, or username.",
"input_schema": {
"type": "object",
"properties": {
"key": {
"type": "string",
"enum": ["email", "phone", "username"],
"description": "The attribute to search for a user by (email, phone, or username)."
},
"value": {
"type": "string",
"description": "The value to match for the specified attribute."
}
},
"required": ["key", "value"]
}
},
{
"name": "get_order_by_id",
"description": "Retrieves the details of a specific order based on the order ID. Returns the order ID, product name, quantity, price, and order status.",
"input_schema": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The unique identifier for the order."
}
},
"required": ["order_id"]
}
},
{
"name": "get_customer_orders",
"description": "Retrieves the list of orders belonging to a user based on a user's customer id.",
"input_schema": {
"type": "object",
"properties": {
"customer_id": {
"type": "string",
"description": "The customer_id belonging to the user"
}
},
"required": ["customer_id"]
}
},
{
"name": "cancel_order",
"description": "Cancels an order based on a provided order_id. Only orders that are 'processing' can be cancelled",
"input_schema": {
"type": "object",
"properties": {
"order_id": {
"type": "string",
"description": "The order_id pertaining to a particular order"
}
},
"required": ["order_id"]
}
}
]
db = FakeDatabase()
def process_tool_call(tool_name, tool_input):
if tool_name == "get_user":
return db.get_user(tool_input["key"], tool_input["value"])
elif tool_name == "get_order_by_id":
return db.get_order_by_id(tool_input["order_id"])
elif tool_name == "get_customer_orders":
return db.get_customer_orders(tool_input["customer_id"])
elif tool_name == "cancel_order":
return db.cancel_order(tool_input["order_id"])
def simple_chat():
user_message = input("\nUser: ")
messages = [{"role": "user", "content": user_message}]
while True:
#If the last message is from the assistant, get another input from the user
if messages[-1].get("role") == "assistant":
user_message = input("\nUser: ")
messages.append({"role": "user", "content": user_message})
#Send a request to Claude
response = client.messages.create(
model=MODEL_NAME,
max_tokens=4096,
tools=tools,
messages=messages
)
# Update messages to include Claude's response
messages.append(
{"role": "assistant", "content": response.content}
)
#If Claude stops because it wants to use a tool:
if response.stop_reason == "tool_use":
tool_use = response.content[-1] #Naive approach assumes only 1 tool is called at a time
tool_name = tool_use.name
tool_input = tool_use.input
print(f"======Claude wants to use the {tool_name} tool======")
#Actually run the underlying tool functionality on our db
tool_result = process_tool_call(tool_name, tool_input)
#Add our tool_result message:
messages.append(
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": tool_use.id,
"content": str(tool_result),
}
],
},
)
else:
#If Claude does NOT want to use a tool, just print out the text reponse
print("\nTechNova Support: " + f"{response.content[0].text}" )
# Start the chat!!
# simple_chat()
下面是一个对话示例:
如您所见,聊天机器人在需要时会调用正确的工具,但实际的聊天回复并不理想。我们可能不希望面向客户的聊天机器人告诉用户它要调用的具体工具!
提示增强
可以通过为聊天机器人提供可靠的系统提示来改善聊天体验。首先要做的就是给 Claude 提供一些背景信息,告诉它自己是 TechNova 的客户服务助理。
下面是系统提示的开头:
system_prompt = """
You are a customer support chat bot for an online retailer called TechNova.
Your job is to help users look up their account, orders, and cancel orders.
Be helpful and brief in your responses.
"""
在向 Claude 提出请求时,不要忘记将此提示输入 system 参数!
下面是添加上述系统提示细节后的对话示例:
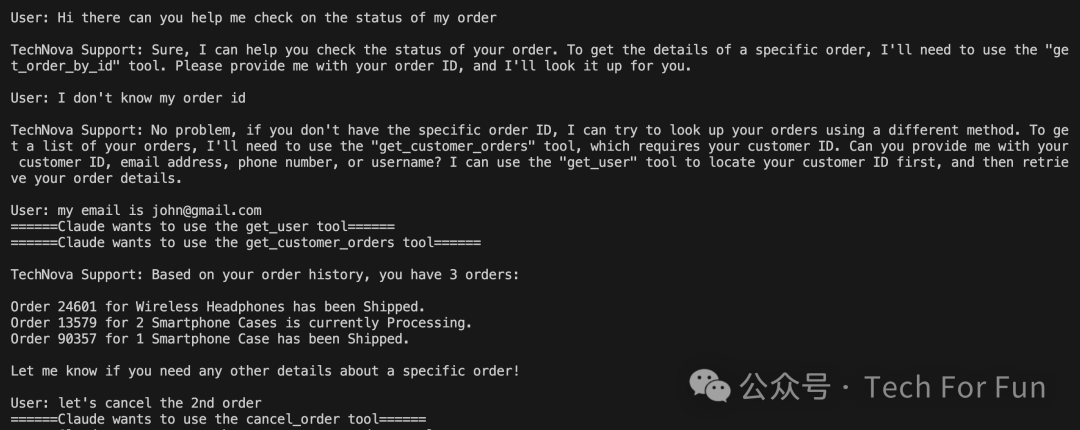
请注意,该助手知道自己是 TechNova 的支持机器人,因此不再向用户介绍其工具。也许还应该明确告诉 Claude 不要引用工具。
注意:=======Claude wants to use the cancel_order_tool======= 行是我们添加到脚本中的日志,而不是 Claude 的实际输出!
如果玩明白这个脚本,你可能会注意到其他问题。一个非常明显也非常棘手的问题在下面的对话中有所体现:

上面的截图显示了整个对话过程。用户请求帮助取消订单,并表示不知道订单 ID。Claude 应该跟进并询问客户的电子邮件、电话号码或用户名,以便查找客户,然后找到匹配的订单。相反, Claude 只是决定调用 get_user 工具,而实际上并不知道用户的任何信息。Claude 编造了一个电子邮件地址并试图使用它,但当然没有找到匹配的客户。
为了避免出现这种情况,我们将更新系统提示,使其包含大意如下的语言:
system_prompt = “”" You are a customer support chat bot for an online retailer called TechNova. Your job is to help users look up their account, orders, and cancel orders. Be helpful and brief in your responses.
You have access to a set of tools, but only use them when needed.
If you do not have enough information to use a tool correctly, ask a user follow up questions to get the required inputs.
Do not call any of the tools unless you have the required data from a user. “”"
下面是使用更新后的系统提示与助手对话的截图:
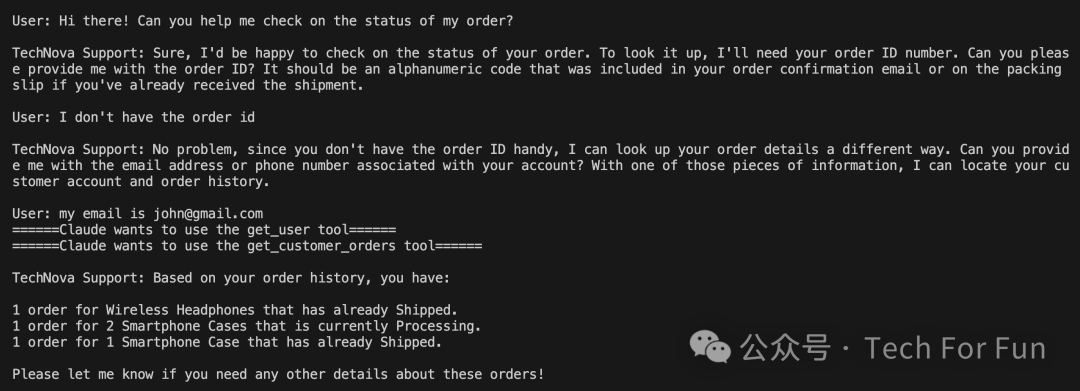
好多了!
Opus 特有的问题
在使用 Opus 和工具时,模型在实际响应用户之前,往往会在 <thinking> 或 <reflection> 标记中输出自己的想法。下面的截图就是一个例子:
这种思考过程往往会带来更好的结果,但显然会带来糟糕的用户体验。我们不想把这种思考逻辑暴露给用户!最简单的解决方法就是明确要求模型以一组特定的 XML 标记输出面向用户的响应。首先更新系统提示:
system_prompt = """
You are a customer support chat bot for an online retailer called TechNova.
Your job is to help users look up their account, orders, and cancel orders.
Be helpful and brief in your responses.
You have access to a set of tools, but only use them when needed.
If you do not have enough information to use a tool correctly, ask a user follow up questions to get the required inputs.
Do not call any of the tools unless you have the required data from a user.
In each conversational turn, you will begin by thinking about your response.
Once you're done, you will write a user-facing response.
It's important to place all user-facing conversational responses in <reply></reply> XML tags to make them easy to parse.
"""
请看一个对话输出示例:
现在,Claude 在面向用户的实际响应周围使用 <reply> 标记进行响应。现在要做的就是提取这些标记之间的内容,并确保这是实际打印给用户的唯一部分回复。下面是更新后的 start_chat 函数,它可以完全做到这一点!
import re
def extract_reply(text):
pattern = r'<reply>(.*?)</reply>'
match = re.search(pattern, text, re.DOTALL)
if match:
return match.group(1)
else:
return None
def simple_chat():
system_prompt = """
You are a customer support chat bot for an online retailer called TechNova.
Your job is to help users look up their account, orders, and cancel orders.
Be helpful and brief in your responses.
You have access to a set of tools, but only use them when needed.
If you do not have enough information to use a tool correctly, ask a user follow up questions to get the required inputs.
Do not call any of the tools unless you have the required data from a user.
In each conversational turn, you will begin by thinking about your response.
Once you're done, you will write a user-facing response.
It's important to place all user-facing conversational responses in <reply></reply> XML tags to make them easy to parse.
"""
user_message = input("\nUser: ")
messages = [{"role": "user", "content": user_message}]
while True:
#If the last message is from the assistant, get another input from the user
if messages[-1].get("role") == "assistant":
user_message = input("\nUser: ")
messages.append({"role": "user", "content": user_message})
#Send a request to Claude
response = client.messages.create(
model=MODEL_NAME,
system=system_prompt,
max_tokens=4096,
tools=tools,
messages=messages
)
# Update messages to include Claude's response
messages.append(
{"role": "assistant", "content": response.content}
)
#If Claude stops because it wants to use a tool:
if response.stop_reason == "tool_use":
tool_use = response.content[-1] #Naive approach assumes only 1 tool is called at a time
tool_name = tool_use.name
tool_input = tool_use.input
print(f"======Claude wants to use the {tool_name} tool======")
#Actually run the underlying tool functionality on our db
tool_result = process_tool_call(tool_name, tool_input)
#Add our tool_result message:
messages.append(
{
"role": "user",
"content": [
{
"type": "tool_result",
"tool_use_id": tool_use.id,
"content": str(tool_result),
}
],
},
)
else:
#If Claude does NOT want to use a tool, just print out the text reponse
model_reply = extract_reply(response.content[0].text)
print("\nTechNova Support: " + f"{model_reply}" )
# Start the chat!!
# simple_chat()
下面的截图显示了上述更改的影响:
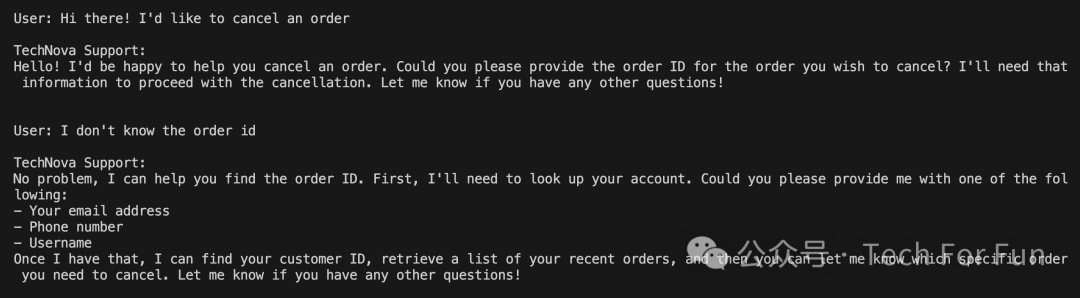
最终版本
这是一段较长对话的截图,其中的脚本版本对输出结果进行了着色处理:
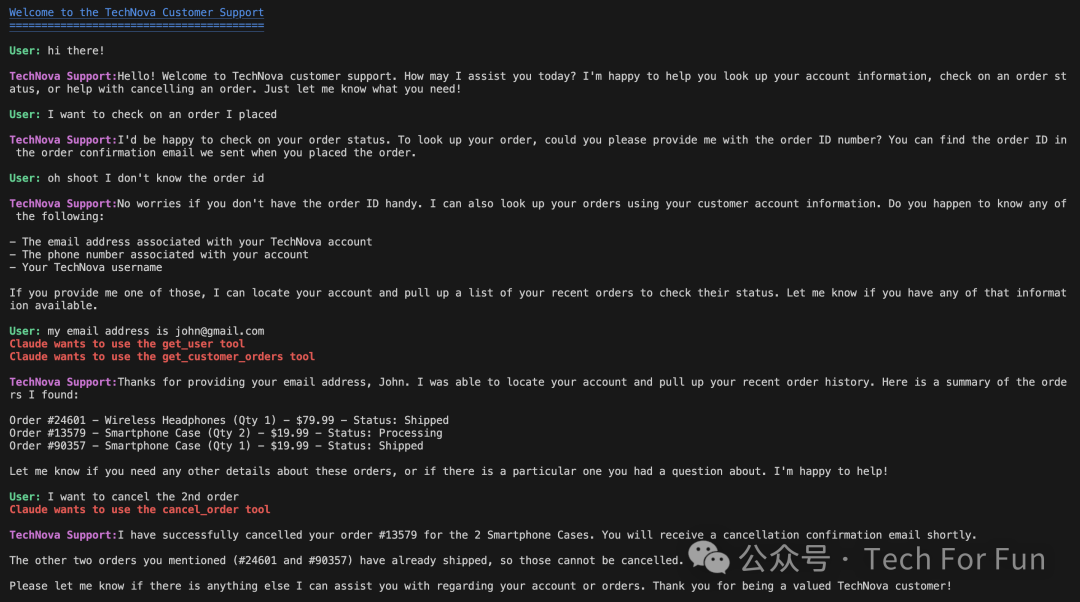
结束说明
这是一个教学演示,用于说明工具使用工作流程。此脚本和提示不适合用于生产。助理会回答 “您可以在订单确认电子邮件中找到订单 ID”,但实际上并不知道这是否属实。在现实世界中,我们需要为 Claude 提供大量关于公司的背景知识(至少这样)。还需要严格测试聊天机器人,确保它在任何情况下都表现良好。另外,让任何人都能轻易取消订单可能不是一个好主意!如果你能获取很多人的电子邮件、用户名或电话号码,取消他们的订单就会变得非常容易。在现实世界中,可能需要某种形式的身份验证。长话短说:这只是一个演示,并不是一个完整的聊天机器人!
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

















 1387
1387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









