






 本文指导用户如何在不同平台上安装Blast最新版本,推荐使用SwissProt数据库,提供了从序列到PSSM矩阵的获取步骤,包括Python脚本示例,以及如何处理批量获取矩阵时的命名问题。
本文指导用户如何在不同平台上安装Blast最新版本,推荐使用SwissProt数据库,提供了从序列到PSSM矩阵的获取步骤,包括Python脚本示例,以及如何处理批量获取矩阵时的命名问题。
所需工具:
1.blast最新版本,老版本的blast无法适配现在的数据库版本
自己上网查找安装教程,linux,windows均可
2.SwissProt数据库、nr数据库等。
推荐SwissProt数据库,因为小,nr数据库几十上百G。根据需要选择。
下载下来后,blast建库。 #可能需要
2024/1/23 最新的SwissProt数据库解压后无需建库,可直接被blast识别使用。
3.序列文件,蛋白质序列文件。
文件请注意,一个文件只能包含一条序列,如果包含多个序列,获得的pssm矩阵将属于最后一条序列。
本教程为从序列到pssm矩阵的获取过程,其过程中的软件安装,数据库下载,序列数据等等均可自己上网查找,无严格要求,按需准备。
pssm矩阵介绍:无
单个序列文件获取矩阵:
psiblast -query "/data/10T/fyang/pro/out/145856.fasta" -db /data/10T/fyang/pssm/data/swissprot -evalue 0.001 -num_iterations 3 -out_ascii_pssm /data/10T/fyang/pssm/145856.pssm
#-query 输入序列文件位置
#-db 数据库解压或者建库的位置
#-evalue E值阈值
#-num_iterations 迭代次数一般为3
#-out_ascii_pssm 输出矩阵文件位置,文件名需自己命名,这里为145856.pssm批量获取矩阵的思路:
###python实现,将所有序列合并在一个文件中并且打开open一个临时的文件,每次在临时文件中写入一条序列,获取矩阵后,跳到下一条,依次遍历所有序列。###
上述方法不行,不知有无大佬解答,当for循环中出现open和os.system执行命令psiblast,输出文件只有过程,没有矩阵。
所以需要分步进行,先将所有序列一个一个保存到文件中,再获得矩阵文件然后改名称。详情见代码。
python代码:
'''合并蛋白序列'''
import os
newlines = []
for i in os.listdir():
if i[-2:] == 'py':continue #跳过本py程序
with open(i) as f: #读取文件
lines = f.readlines()
for line in lines:
if line.startswith('>'): #名称行
line = line.strip('\n')
line = line.split(' ')[0] + '-' + i + '\n' #以空格分割后的第一个元素和当前读取的物种的名称i命名
newlines.append(line)
#print(line)
else: #序列行
newlines.append(line)
if not os.path.exists('../mergeout/'):os.makedirs('../mergeout/') #判断是否存在这个文件夹,没有则创建
with open('../mergeout/merge-pro','w') as r: #输出
for line in newlines:
r.write(line)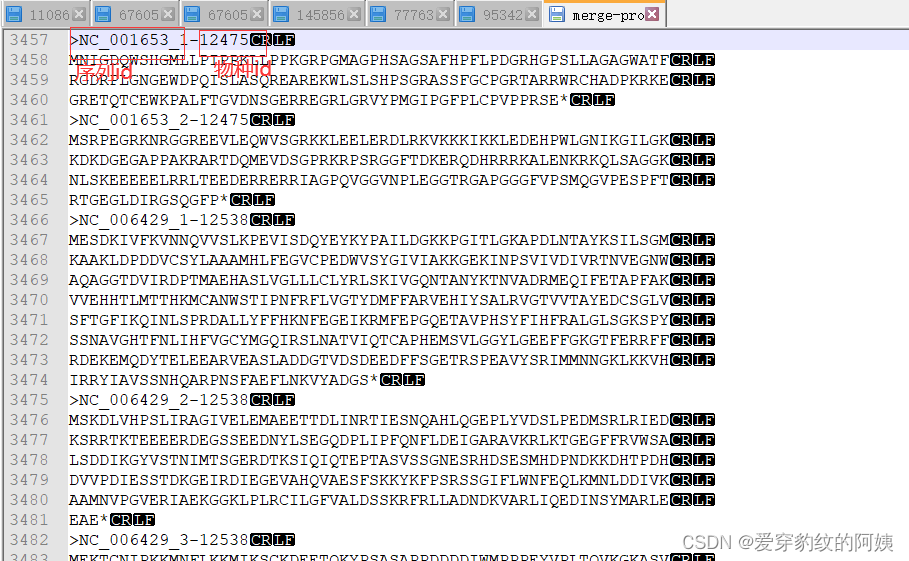
import os
import subprocess
import time
'''
所需文件:merge-pro
'''
def get_Temporaryfile(list): #创建文件,并且在终端打印命令执行blast获得pssm矩阵
for i in list:
#print(str(i)+'/'+str(list.index(i)))
# if list.index(i)%10 == 0:
# time.sleep(10)
filename = i.split('\n')[0]
#print(filename)
fileline = i.split('\n')[1]
#print(fileline)
index = list.index(i)
if not os.path.exists('./Temporary/'):os.makedirs('./Temporary/') #判断是否存在这个文件夹,没有则创建
f = open(r"./Temporary/"+str(index), 'w')
f.write(filename+'\n'+fileline+'\n')
f.close()
#os.system("psiblast -query ./Temporary/"+str(index) + " -db /data/10T/fyang/pssm/data/swissprot -evalue 0.001 -num_iterations 3" + " -out_ascii_pssm /data/10T/fyang/pssm/" + str(filename) + ".pssm > /dev/null 2>&1")
def get_list(): #整理merge-pro文件为一个list,方便遍历
# 打开文件并读取内容
with open('./merge-pro', 'r') as file:
lines = file.readlines()
# 初始化变量a
a_list = []
# 遍历文件内容
current_record = ""
# 遍历文件内容
for line in lines:
line = line.strip() # 去除行首尾的空白字符
if line.startswith('>'):
# 处理上一条记录
if current_record:
# 将当前记录添加到列表
a_list.append(current_record.strip('*'))
# 重置current_record
current_record = line +'\n'
else:
# 将行内容添加到current_record
current_record += line
# 处理最后一条记录
if current_record:
a_list.append(current_record.strip('*'))
#print(a_list)
return a_list
def pssm(): #获得矩阵
for i in os.listdir('./Temporary/'):
filename = i
os.system("psiblast -query ./Temporary/" + str(i) + " -db /data/10T/fyang/pssm/data/swissprot -evalue 0.001 -num_iterations 3" + " -out_ascii_pssm /data/10T/fyang/pssm/pssm/"+str(filename))
#break
def transform_name(): #psiblast没办法和open或者withopen在同一个for循环下,不然会导致输出只有过程。所以需要单独跑出来再改名字。
# 转换名称
old = []
new = []
for i in os.listdir('./Temporary/'):
with open('./Temporary/'+str(i),'r') as f:
a = f.readlines()
filename = a[0].strip('\n').strip('>') +str('.pssm')
#根据自己的需求命名,如果名称中包含>或者\n等符号可能导致rename后的文件无法访问情况。
old.append(i)
new.append(filename)
dict_old_new = dict(zip(old,new))
folder_path = '/data/10T/fyang/pssm/pssm'
for old_name, new_name in dict_old_new.items():
old_path = os.path.join(folder_path, old_name)
new_path = os.path.join(folder_path, new_name)
try:
os.rename(old_path, new_path)
print(f'Renamed: {old_name} -> {new_name}')
except FileNotFoundError:
print(f'File not found: {old_name}')
except FileExistsError:
print(f'File already exists with the new name: {new_name}')
if __name__ == '__main__':
list = get_list()
get_Temporaryfile(list)
pssm()
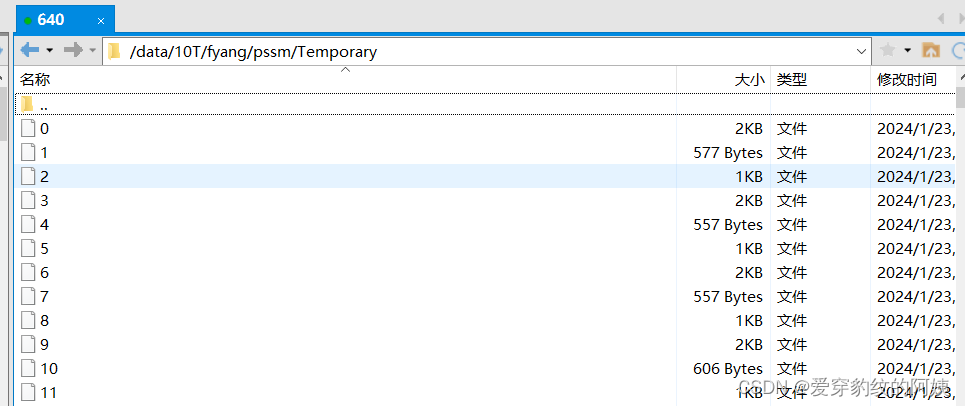
transform_name()分开的序列文件,有多少序列就有多少文件:
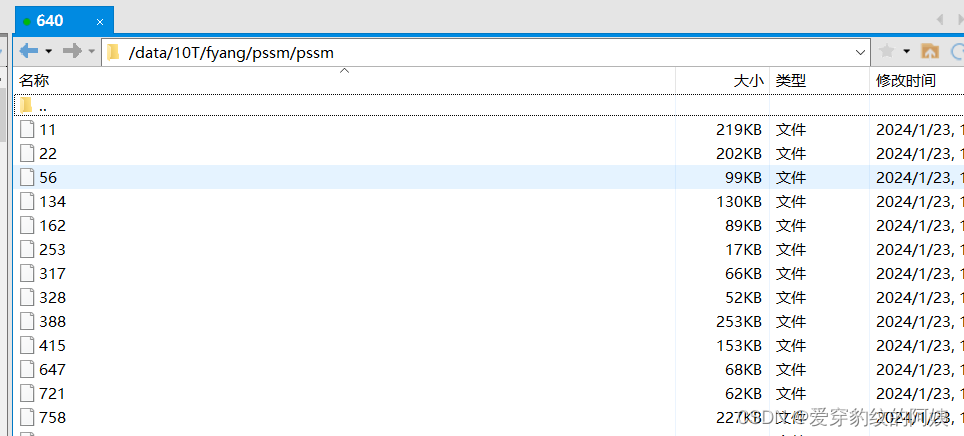
 获得的矩阵,此处还没改名,执行transform方法可以改名。
获得的矩阵,此处还没改名,执行transform方法可以改名。
 ok,教程到此结束,仅供参考,代码繁琐,思路也不是很清晰,仅供学习。
ok,教程到此结束,仅供参考,代码繁琐,思路也不是很清晰,仅供学习。
关于后续的pssm矩阵处理,暂时没有看到相关内容,有看到的大佬,可以评论区分享一下pssm矩阵如何降维到固定维数,归一化以及规格化的教程。

















 788
788

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









