







做模式识别实验遇到的一个问题:每次循环生成的向量维数都是随机的,如何把生成的向量最后合并成一个,用sum=[sum d]合并效率极低,原因在于matlab在循环中动态扩充数组会不断分配新的内存空间,并把原来的所有数据复制过去。
function [output]=dashu(n)
% 验证大数定理
% n是模拟次数
sum_d=[];
for m=1:n
s=randi([-100,100],1,2);
a=min(s);
b=max(s);
while a==b
s=randi([-100,100],1,2);
a=min(s);
b=max(s);
end
c=randi([1,1000],1);
d=randi([a,b],1,c);
sum_d=[sum_d d]
end
x=mean(sum_d);
y=var(sum_d);
output=[x y];
hist(sum_d,20);语法没问题,可是太耗时间,如果1000次要几十分钟,分析报告显示:sum_d=[sum_d d];耗费了96%的时间,后来改为用元胞数组
function [output]=dashu(n)
% 验证大数定理
% n是模拟次数
sum_d{1,n}=[];
for m=1:n
s=randi([-100,100],1,2);
a=min(s);
b=max(s);
while a==b
s=randi([-100,100],1,2);
a=min(s);
b=max(s);
end
c=randi([1,1000],1);
d=randi([a,b],1,c);
sum_d{m}=d;
end
summ=cell2mat(sum_d);
x=mean(summ);
y=var(summ);
output=[x y];
hist(summ,20);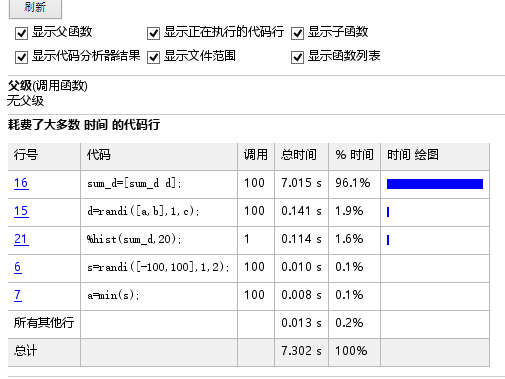
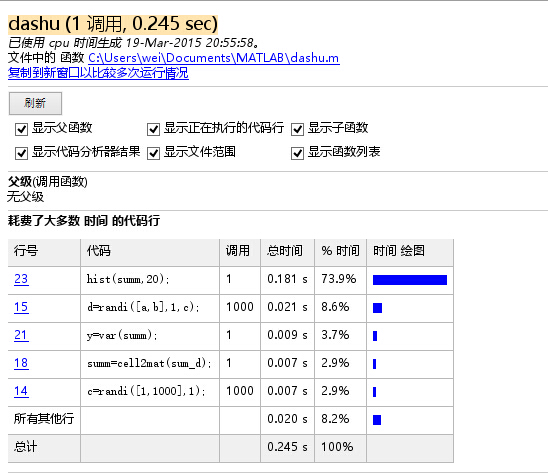
今天发现那份原先代码运行慢的原因并非sum=[sum d]效率低,而是sum=[sum d] 表达式后面没加 分号,导致命令行窗口不断输出这个表达式的运算结果,导致很慢,加了分号后运行很快,甚至比用cell方案更快。















 2243
2243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









