







文章目录
前言
在深度学习的世界里,大型神经网络因其出色的性能和准确性而备受青睐。然而,这些网络通常包含数百万甚至数十亿个参数,使得它们在资源受限的环境下(如移动设备和嵌入式系统)运行变得不切实际。知识蒸馏(Knowledge Distillation)技术应运而生,旨在解决这一挑战,通过将大型网络的知识“蒸馏”到更小、更高效的模型中,以实现类似的性能,但以更低的计算成本。
1、什么是知识蒸馏
知识蒸馏(Distilling the Knowledge in a Neural Network)由Hinton等人于2015年提出。知识蒸馏是一种模型压缩技术,其基本思想是通过训练一个较小的模型(学生模型)来模仿一个大型的、已经训练好的模型(教师模型)。与传统的训练方法相比,知识蒸馏不仅仅依赖于硬标签(即真实标签),而且利用教师模型的预测结果(软标签)来传递更丰富的信息。
2、知识蒸馏的原理
通过训练一个小模型来模仿一个预先训练好的大模型,从而将大模型中所含的“暗知识”传递给小模型。在这个过程中,通过最小化损失函数来传递知识,label是大模型预测的类概率分布。为了提供更多信息,引入了“softmax温度”的概念,通过调整温度参数T,可以影响softmax函数生成的概率分布。当T=1时,得到标准的softmax函数,而当T增大时,softmax函数生成的概率分布变得更加柔和,提供了更多关于模型认为哪些类别与预测类别更相似的信息。这种调整温度的方法可以帮助传递大模型中所含的“暗知识”到小模型中。
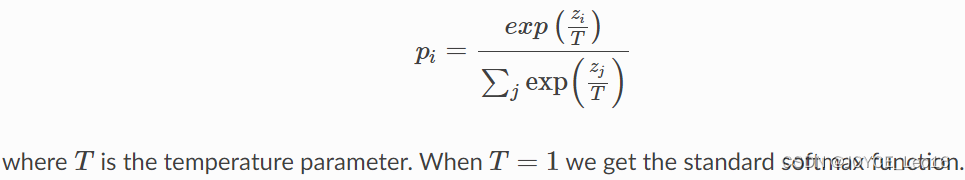
3、知识蒸馏的架构
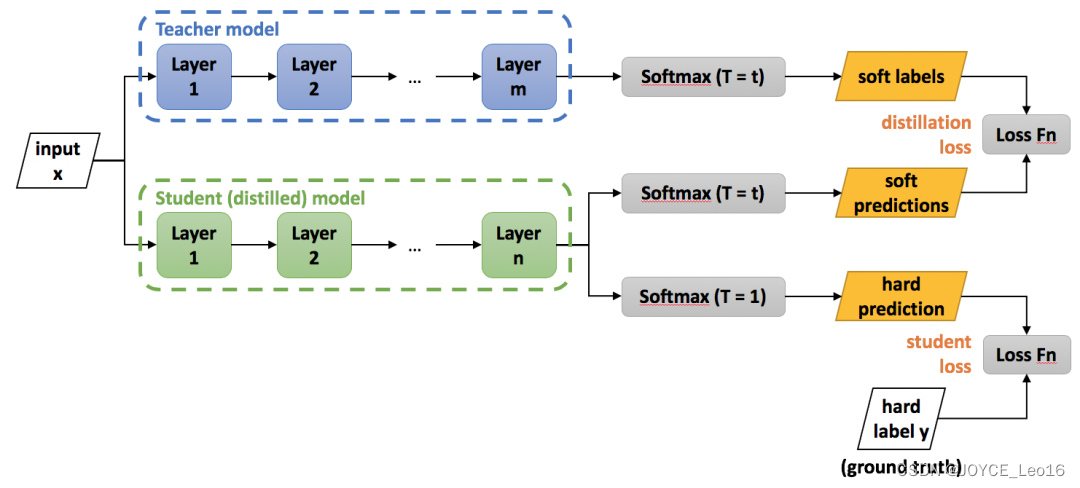
知识蒸馏的两个阶段:
- 教师模型训练(Teacher Model):使用大型且复杂的模型(如深层神经网络)对训练数据进行训练。这个模型作为知识提供者,由于其复杂性和预训练的专业性,它可以提供更准确和丰富的预测结果。
- 学生模型训练(Student Model):通过使用教师模型的输出作为目标,用一个更简单的模型来训练。学生模型通常是一个浅层次的模型,它的结构和参数比较简单,容易训练和部署。
损失函数的构成:

- 蒸馏损失(distillation loss):通过最小化一个损失函数来传递知识,其Label是大模型预测的类概率分布。这个损失函数是基于老师模型的软目标(soft label),用来指导学生模型的训练,使得学生模型能够更好地模仿老师模型的预测行为。
- 学生损失(student loss):学生模型自身的损失函数,通常用来指导学生模型学习正确的标签信息,以便学生模型能够在接受“暗知识”的同时,保持对真实标签(hard label)的准确预测能力。
- 将两个损失函数进行加权求和,以平衡模型学习“暗知识”和准确预测真实标签。这样可以确保学生模型在蒸馏过程中既能够有效地获得来自老师模型的知识,又能够保持对真实标签的准确预测能力。
特点:
- 模型压缩:知识蒸馏允许将复杂模型中的知识压缩到一个更小和更简单的模型中,减少了模型的复杂性和存储需求。
- 提高推理性能:学生模型通过从教师模型学习到的知识来提高自身的推理性能,实现了在相对简单的模型上获得接近复杂模型效果的性能。
- 加速推理:由于学生模型相对较小和简单,它的推理速度更快,可在资源有限的环境中使用,如嵌入式设备或移动设备。
- 知识蒸馏可以被看作是一种迁移学习(利用一个领域的知识来改善另一个领域学习的技术)的形式,将知识从一个模型迁移到另一个模型以改善后者的性能。
总之,通过知识蒸馏可以将复杂模型中的宝贵知识传递给简化的模型,从而在保持性能的同时减少模型的复杂度,使得小模型可以在资源受限的环境中进行高效部署,获得更高的推理效率和速度。
4、应用
知识蒸馏的应用范围广泛,它在许多深度学习领域中都发挥着重要作用,包括但不限于图像识别、自然语言处理和语音识别。以下是一些主要应用场景:
- 移动和边缘计算:在移动设备和边缘设备上运行深度学习模型时,计算资源和电源通常受限。通过知识蒸馏,可以将大型模型的知识迁移到更小、更高效的模型中,从而使得这些模型能够在资源有限的设备上运行,同时保持较高的准确率。
- 实时应用:对于需要实时响应的应用,如视频分析和在线翻译,快速的推理速度至关重要。知识蒸馏可以帮助开发更快的模型,从而减少延迟时间,提高用户体验。
- 模型融合:知识蒸馏也可以用于模型融合,即将多个模型的知识融合到一个模型中。这不仅能提高模型的性能,还能减少部署多个模型所需的资源。
- 隐私保护:通过知识蒸馏,可以在不直接访问敏感或私有数据的情况下,从一个已经训练好的模型传递知识到另一个模型。这对于遵守数据隐私法规特别重要。
结论
知识蒸馏为解决深度学习模型在资源受限环境中的部署和应用提供了一种有效的解决方案。通过将大型模型的复杂性和知识转移到更小、更高效的模型中,它不仅有助于节省计算资源,还保持了模型的性能。尽管存在一些挑战,但随着研究的深入,知识蒸馏有望在未来的深度学习应用中发挥更大的作用。
参考:
Distilling the Knowledge in a Neural Network
https://arxiv.org/pdf/1503.02531.pdf
https://intellabs.github.io/distiller/knowledge_distillation.html
萌即是正义——观其形明其意



















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











