







个人阅读笔记,如有错误欢迎指正。
会议:RAID 2020 raid20-fung.pdf (usenix.org)
问题:
联邦学习具有攻击易感性
创新:
以sybil攻击的角度总结了联邦学习中的攻击方法及分类
提出了防御sybil中毒攻击的方法FoolsGold,该方法基于客户端间贡献相似性进行防御
方法:
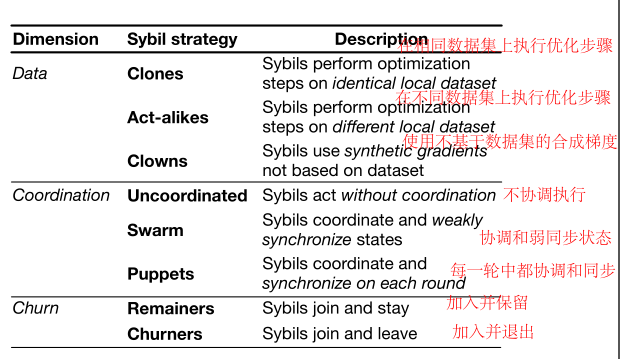
sybil攻击的三个维度:数据分布,协同程度,流失程度
三个维度,攻击方如何发动sybil攻击的初步分类:
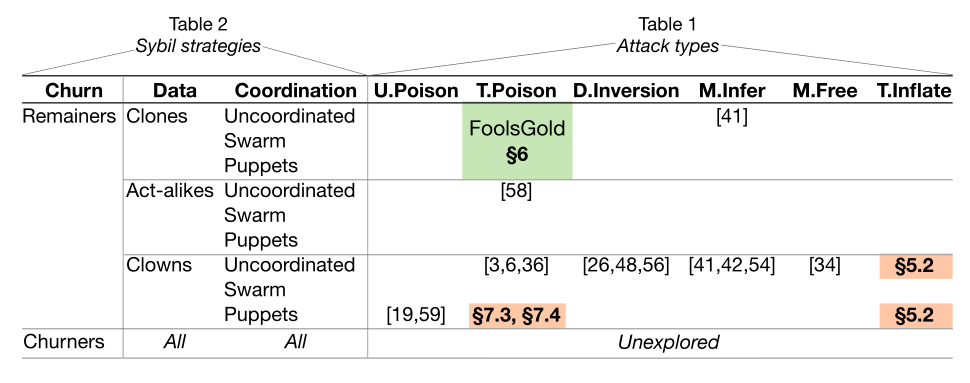
上述策略的组合及其已知的攻击方法:
sybil攻击
训练扩充来攻击FL:当使用典型的收敛启发式方法,sybil可以通过延长训练时间来消耗服务器和客户端上的共享资源
在Multi-Krum防御中,只有当f大于sybil数量时才能有效防御
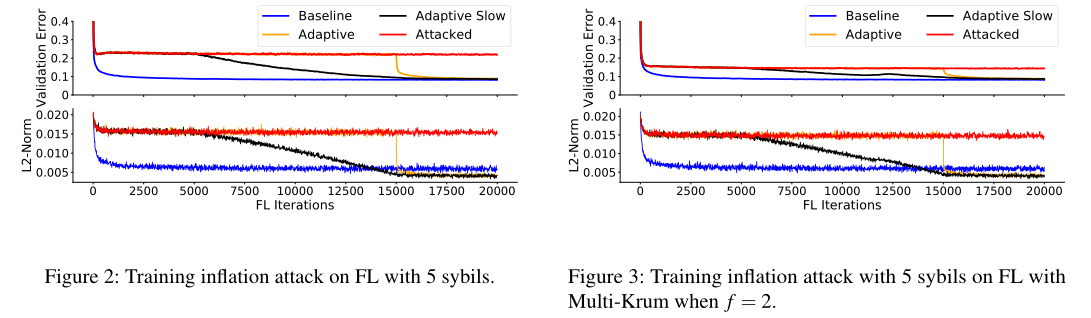
攻击方法:10个良性,5个sybil无目标中毒攻击,使训练无限期继续。模型要么不收敛,要么只有在对手允许的情况下才收敛。
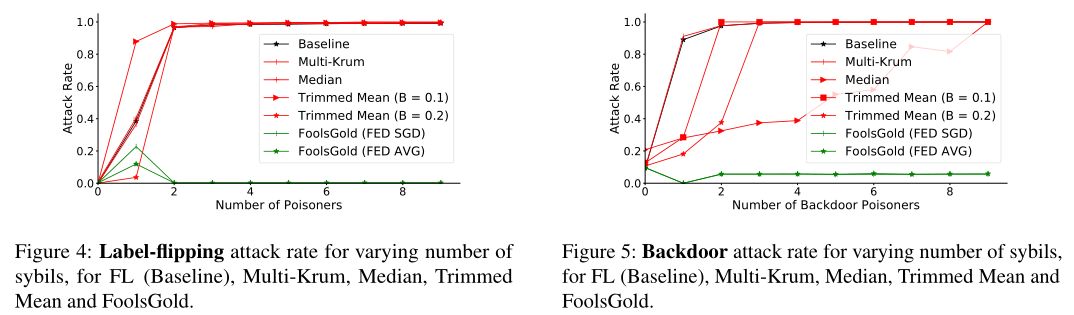
sybil克隆的投毒攻击:使用标签反转攻击和带有白色像素的后门攻击,sybil数量从0增加到9。sybil数量超过阈值,各个现有防御方法都不能抵御攻击,新提出的防御方法能够有效防御
FoolsGold防御
防御算法

从每个客户端收集模型更新历史记录
计算特征显著性:本文选取的是输出层的特征
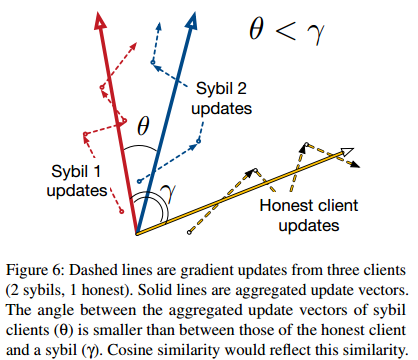
计算客户端基于历史更新聚合后的输出层特征与其余客户端
之间的余弦相似度
将客户端相似度最大的
成对距离记为
赦免机制:由于对诚实的客户和sybils之间的余弦相似度没有足够的保证,诚实的客户可能会被错误地惩罚。引入了一种赦免机制,通过通过和
的比率重新权衡余弦相似度来避免惩罚这些诚实的客户,从而减少误报。
通过沿0-1域反转最大相似分数来找到新的客户端学习率。
通过反logit函数进行归一化(确保所有权重分布在 0-1 范围内)
降低高度相似贡献的学习率
实验:
实验设置:
结果分析:对于大多数攻击,FoolsGold在保持高测试准确性的同时有效地阻止了攻击。当FoolsGold面对更大的sybils数量攻击时,它有更多的信息来更可靠地检测sybils之间的相似性。在只有一个恶意客户端攻击系统的A-1攻击中,FoolsGold表现最差。

出现的问题:假阳性普遍存在,诚实客户端被剔除,降低了诚实客户端的预测准确率
iid场景下:尽管诚实的客户持有统一的训练数据样本,但SGD的随机性引入了他们之间的方差。由于受毒害的数据,sybils的梯度仍然彼此相似,与诚实的客户端不同,即使只有10%的中毒数据,执行有针对性的中毒攻击在全iid和非iid设置下都会产生基本相似的梯度更新,因此FoolsGold仍能够区分。

另设置实验表明,攻击者无法通过操纵其恶意数据分布来破坏FoolsGold,在不同的相关性分布下最高的攻击率都小于1%。
智能扰动攻击:
攻击方式:每个sybil上传的模型天界一个扰动,使得每个sybil的相似度降低,但是总的效果不变,如原来的长传模型为,而添加扰动后,
,
,则
,总的攻击效果不变,但是每个攻击者之间的相似度降低。
防御手段:如果只应用于类型(3)的特征:那些对模型或攻击不重要的特征,那么这种攻击是最有效的。可以通过过滤模型中的指示性特征来减轻攻击。我们不是查看模型中所有特征更新之间的余弦相似性,而是查看基于特征重要性的加权余弦相似性。
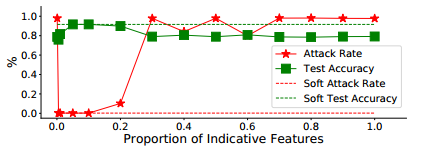
实验设置:分别选取基于不同数量特征的防御模式,当使用所有的相似性特征时(最右边),投毒攻击是成功的,一旦重要特征的比例降至0.1(10%)以下,则智能扰动引起的不相似性将从余弦相似度中去除,中毒向量支配相似性,导致智能扰动策略失败,攻击率接近0。并且,如果重要特征的比例过低(0.01),测试精度也开始受到影响。不同加权方式最优效果相近。
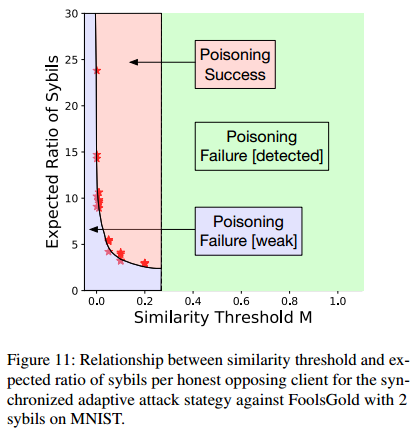
自适应更新攻击:
攻击方式:如果攻击者了解FoolsGold的防御模式,并且能够通过通讯计算彼此的相似度,在一定范围内的相似度阈值以下时才发送中毒模型,就有可能实现攻击。实验显示,在相似度阈值较低且攻击者数量较多时,才能成功投毒。但是这受许多因素影响,需要知道诚实客户端的分布,攻击者很难确定合适的攻击数量以及阈值。















 7537
7537











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









