







个人阅读笔记,如有错误欢迎指出
Arxiv 2019 [1912.11464] Attack-Resistant Federated Learning with Residual-based Reweighting (arxiv.org)
问题:
联邦学习容易受到后门攻击
创新:
提出一种基于残差的重新加权聚合算法
聚合算法将重复中值回归和加权最小二乘中的加权方案相结合
方法:

1)用重复中值估计回归线
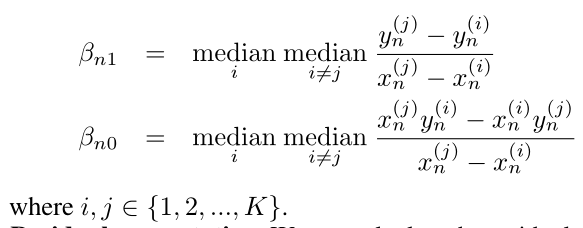
2)计算本地模型中第个参数的残差,由于对于不同的参数
不好比较,因此将
标准化
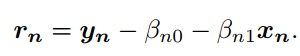
3)参数置信度。其中是
中的第
个参数,
,
,
是超参数本文中定义为2,
是置信空间用
调整,
是
中的第
个对角矩阵
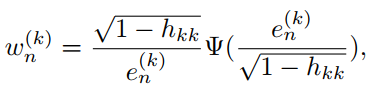
4)极值矫正。若存在非常大的值即使乘很小的权重也足以威胁到全局模型,引入阈值,若置信值低于\
,则用下式矫正
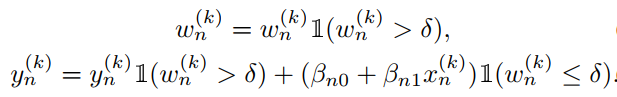
5)本地模型权重。通过衡量每个参数的标准差进行聚合
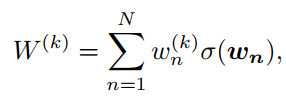
6)全局模型
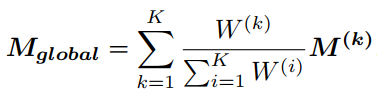
整体算法思路:通过垂直距离(残差)将每个参数重新加权,然后通过累积每个局部模型中的参数置信度来估计每个局部模型的权重

实验:
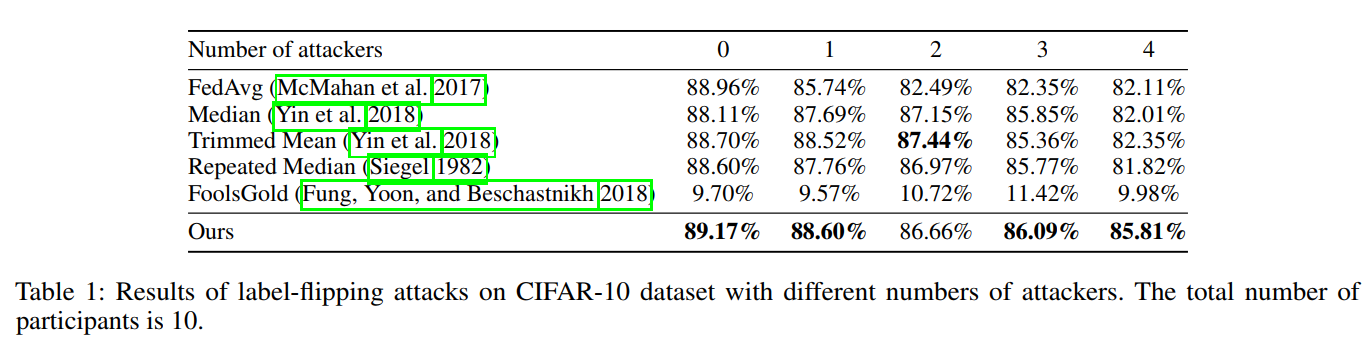

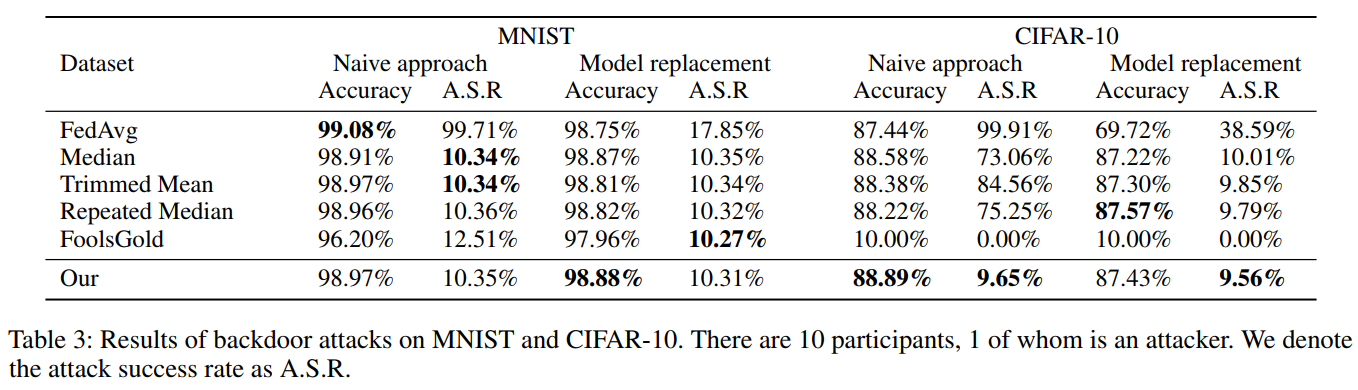
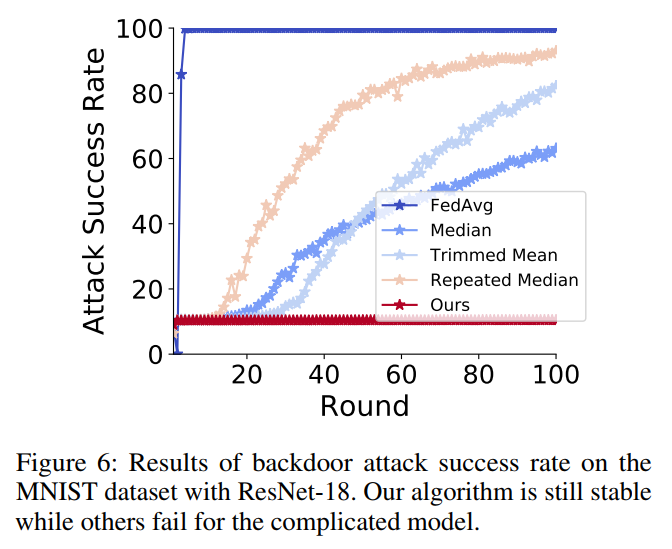
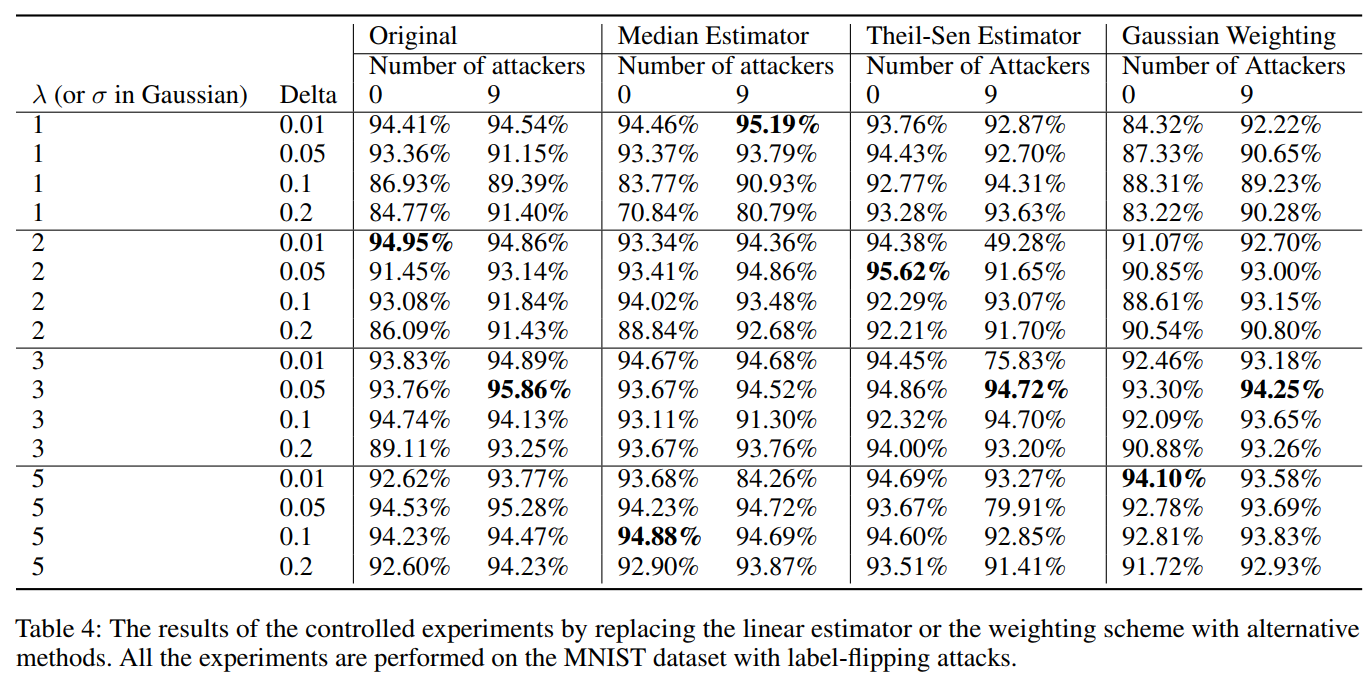
读后感:
优点:
可以防御放大梯度的后门攻击
可以防御标签翻转的后门攻击
局限性:
牺牲了一定的隐私,与安全聚合策略不兼容















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









