






个人阅读笔记,如有错误欢迎指出!
会议:NDSS 2022 [2009.03561] Local and Central Differential Privacy for Robustness and Privacy in Federated Learning (arxiv.org)
问题:
尽管联邦学习能在一定程度上保护数据隐私,但也存在隐私和鲁棒性漏洞
主要贡献:
首次发现LDP和CDP都可以抵御后门攻击
发现仅在FL的非攻击者上应用LDP可以提高后门攻击的准确性
LDP和CDP可以防止(白盒)成员推断
LDP与CDP均不能防御属性推断攻击
Preliminaries
差分隐私

LDP本地差分隐私:每个参与者向服务器发送更新之前添加噪声。对参与者数据集中的记录进行了限制。各个参与者在其本地运行DP可以使用moments accountant来分配隐私预算


CDP中央差分隐私:服务器应用DP聚合算法。限制了关于特定参与者的信息。服务器截取参与者更新的l2范数,然后聚合截取的更新并将高斯噪声添加到聚合中,来防止过度适应任何参与者的更新。为了跟踪花费的隐私预算,可以使用moments accountant。

moments accountant

方法:
对LDP和CDP进行针对后门的攻击实验
通常使用范数裁剪和弱差分隐私,但二者均不能防御推理攻击
实验设置:数据集EMNIST,CIFAR10,Reddit,Sentiment140
1)所有参与方上部署CDP
2)所有参与方上部署LDP(包括攻击者)
3)仅在非攻击者上部署LDP
4)范数裁剪
5)弱差分隐私
攻击方设置
1)单像素攻击(右下角像素)

2)CIFAR10的语义后门

3)Reddit评论数据集的语义后门
攻击者预测的句子包括“伦敦”这座城市,并以预设的单词作为后门。如后门句:1)“伦敦人很有攻击性”,2)“伦敦的天气总是晴朗的”,3)“住在伦敦很便宜”
4)Sentiment140语义后门
攻击者在训练数据中注入后门文本“我感觉很棒”,以使聚合模型将带有后门文本的推文分类为负面推文。
后门攻击
实验结果(攻击为can you really backdoor FL)
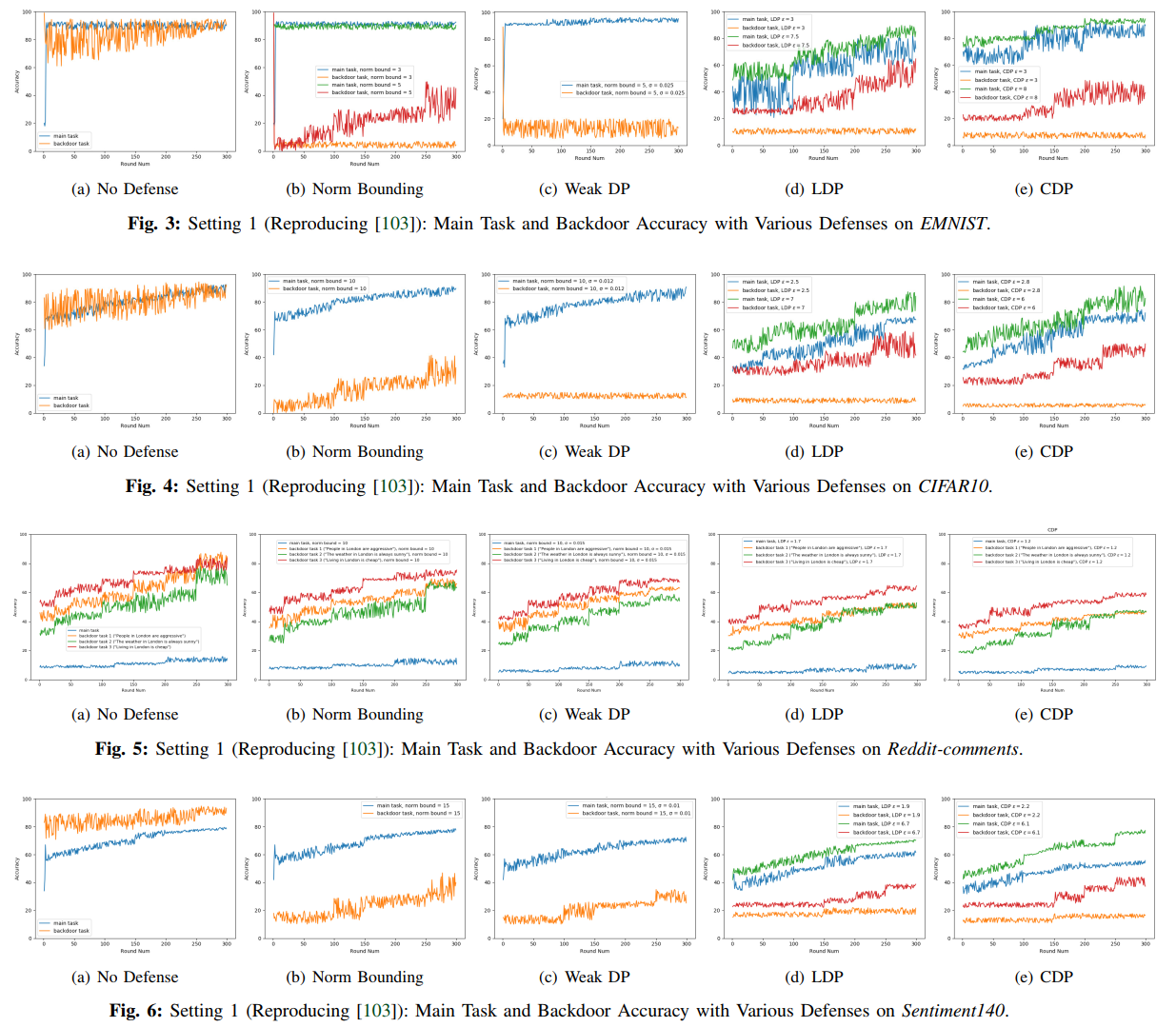
3a 4a 5a 6a无约束攻击,在没有任何来自服务器端的对攻击者约束的情况下完成。即使每轮只有一名攻击者,这种攻击仍能发挥出很好的效果。
3b 4b 5b 6b范数边界。可以在一定程度上抵御攻击,且对模型可用性没有影响。
3c 4c 5c 6c弱差分隐私。效果类似范数边界。但该方法隐私预算很高,不能为参与方提供隐私保护。
3d 4d 5d 6d本地差分隐私。缓解了攻击,但模型可用性较weak-DP差。
3e 4e 5e 6e中央差分隐私。能更好的消除后门攻击,主任务精度和本地差分隐私差不多。
实验结果(增加攻击者数量)
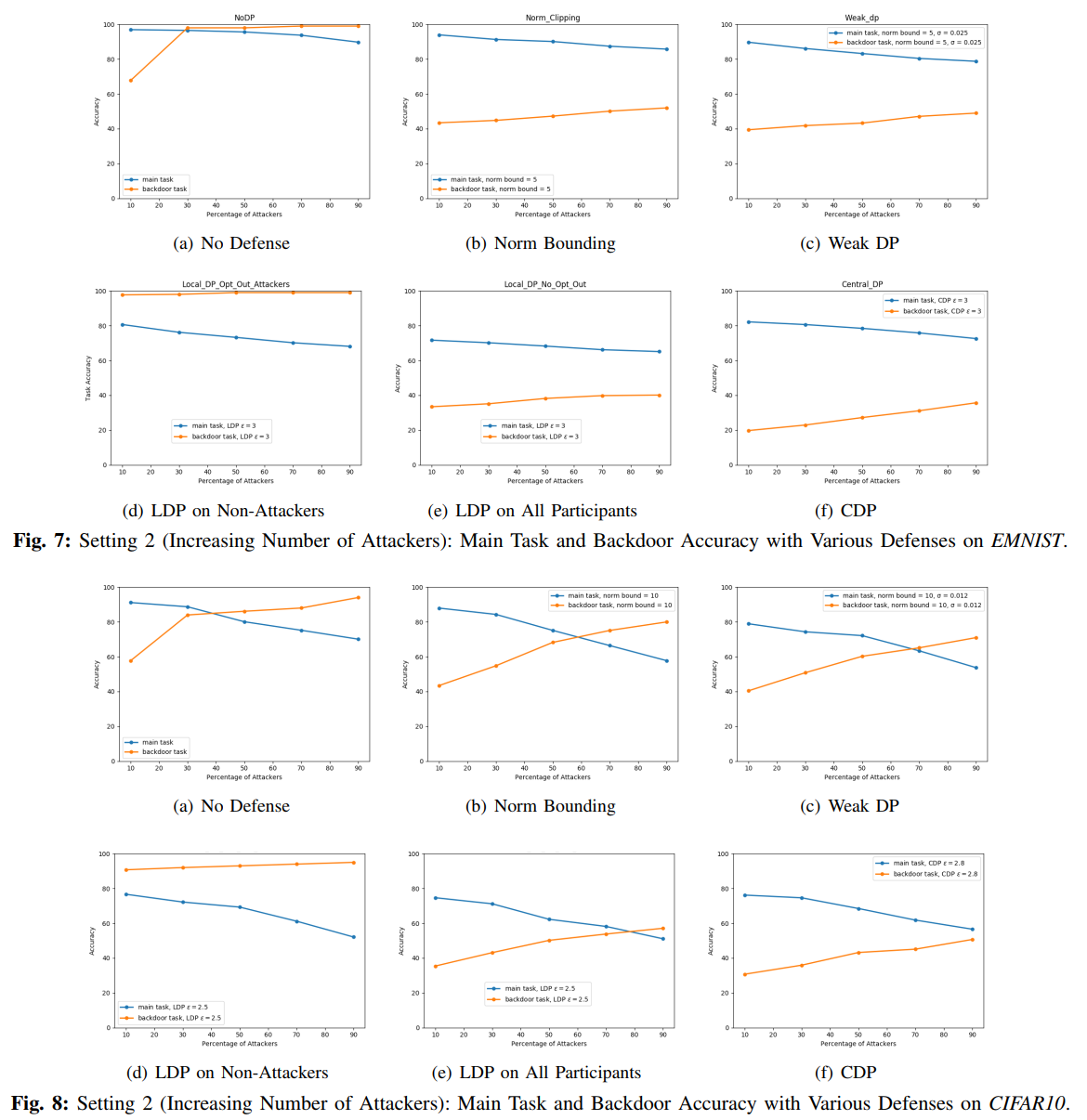

7a 8a 9a 10a随着攻击者的增多,后门的准确性得到了提高,实用性也降低了。但是从效用的降低中识别后门攻击并不是完全,在EMNIST和CIFAR10中,即使有90名攻击者,实用程序也仅减少到88%和78%左右。在Reddit中,10310名攻击者(占参与者的20%)的效用从19%下降到16%。在Sentiment140中,20%的参与者是攻击者,主要任务的准确率从80%左右降低到70%左右。
7b 8b 9b 10b减轻了攻击,但与setting1相比可用性有所降低。
7c 8c 9c 10c较范数裁剪更进一步减轻了攻击
7d 8d 9d 10d展示了攻击方不应用LDP的情况下的结果,增强了攻击并提高了后门准确性(对后门防御不利影响)
7e 8e 9e 10e LDP应用于所有参与方,缓解攻击但模型效用较差
7f 8f 9f 10f 应用CDP,总体上减轻了攻击
推理攻击(Comprehensive privacy analysis of deep learning. 白盒成员推理攻击与Exploiting unintended feature leakage in collaborative learning. 属性推理攻击)
成员推理攻击

无防御情况:与本地攻击者相比,全局攻击者可以执行更有效的攻击
范数边界&弱DP:两者对于成员推理攻击的防御均无效
LDP&CDP:LDP减轻了攻击,即使针对最强大的主动攻击(即隔离梯度),LDP也会将CIFAR100数据集的攻击准确率从91%左右降低到53%左右,在本地被动攻击的情况下,它将Purchase100的攻击准确率从68%左右降低到54%,将Texas100的攻击准确度从66%降低到58%。DP总体上也能成功防御成员推理攻击,由于CDP应用于服务器可信的情况下因此不评估全局攻击的情况,CDP在CIFAR100中将针对被动本地攻击者的攻击准确率从73%降低到58%,在Purchase100中将针对主动本地攻击者的准确率从68%降低到55%。在得克萨斯州100,它通过将攻击准确率从62%降低到54%来缓解被动的局部攻击。
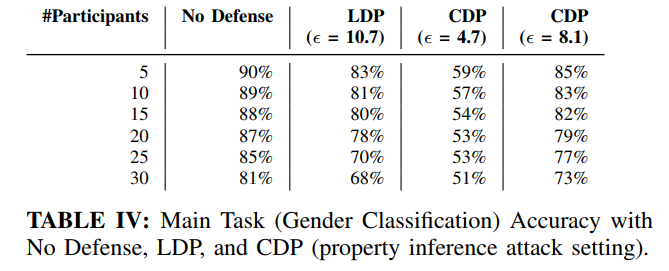
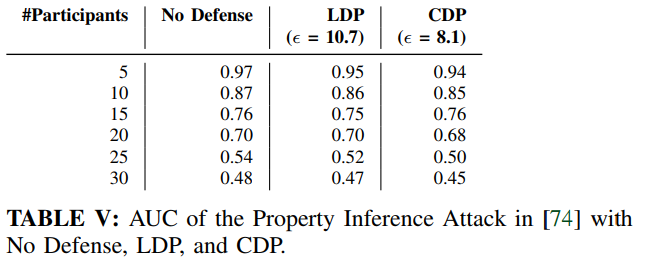
属性推断攻击
CDP和LDP对于属性推断攻击的防御均不成功,AUC没有显著变化。
总结
是一篇实验性质的文章,对LDP和CDP做了比较详细的实验,尤其是仅在非攻击方上使用LDP能提高后门攻击准确率这一发现还是比较有意义的。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









