









与MapTask一样,ReduceTask也分为四种,即Job-setup Task,Job-cleanup Task,Task-cleanup Task和Reduce Task。本文重点介绍第四种——普通Reduce Task。
Reduce Task要从各个Map Task上读取一片数据,经排序后,以组为单位交给用户编写的reduce()函数处理,并将结果写到HDFS上。本文将深入剖析ReduceTask内部各个阶段的实现原理。
Reduce Task整体流程
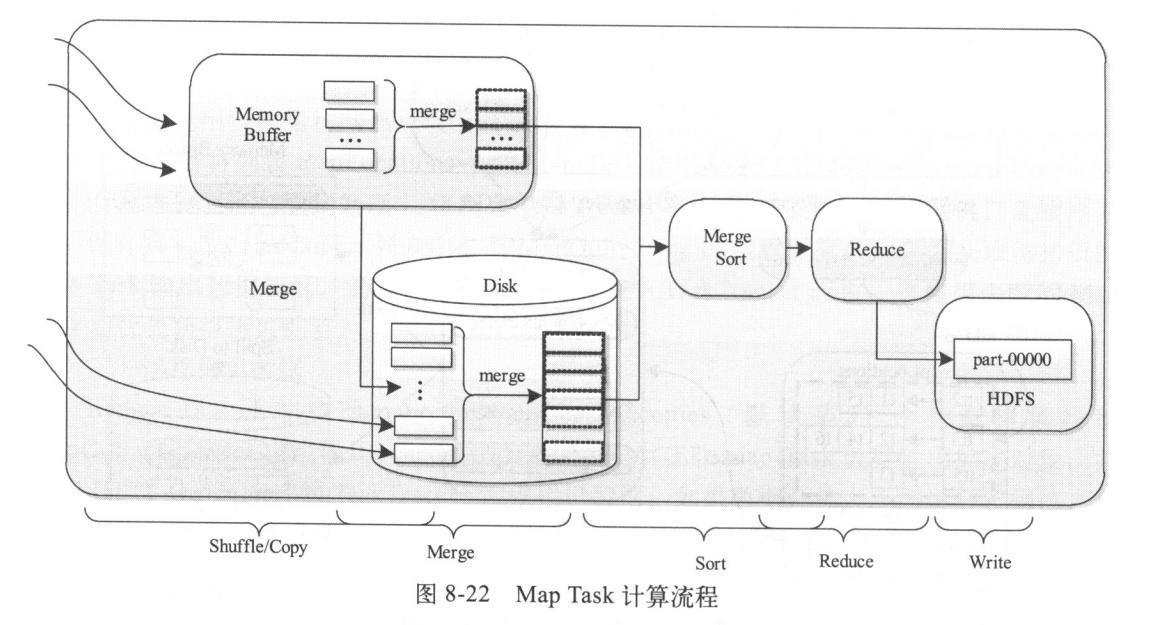
Reduce Task的整体计算流程如图所示,共分为5个阶段
1、Shuffle阶段:也称为Copy阶段。Reduce Task从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直接放到内存中。
2、Merge阶段:在远程拷贝数据的同时,Reduce Task启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或磁盘上文件过多。
3、Sort阶段:按照MapReduce语义,用户编写的reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
4、Reduce阶段:在该阶段中,ReduceTask将每组数据依次交给用户编写的reduce()函数处理
5、Write阶段:reduce()函数将计算结果写到HDFS上
1、Shuffle和Merge阶段分析
在Reduce Task中,Shuffle阶段和Merge阶段是并行进行的。当远程拷贝数据量达到一定阈值后,便会触发相应的合并线程对数据进行合并。这两个阶段均是由类org.apache.hadoop.mapred.ReduceTask的内部类ReduceCopier实现的。
总体上看,Shuffle&Merge阶段可进一步划分为三个子阶段。
(1)准备运行完成的Map Task列表
GetMapEventsThread线程周期性通过RPC从TaskTracker获取已完成Map Task列表,并保存到映射表mapLocations(保存了TaskTracker Host与已完成任务列表的映射关系)中。为防止出现网络热点,Reduce Task通过对所有TaskTracker Host进行“混洗”操作以打乱数据拷贝顺序,并将调整后的Map Task输出数据位置保存到scheduledCopies列表中。
(2)远程拷贝数据
Reduce Task同时启动多个MapOutputCopier线程,这些线程从scheduledCopies列表中获取MapTask输出位置,并通过HTTP Get远程拷贝数据。对于获取的数据分片,如果大小超过一定阈值,则存放到磁盘上,否则直接放到内存中。
(3)合并内存文件和磁盘文件
为了防止内存或者磁盘上的文件数据过多,ReduceTask启动了LocalFSMerger和InMemFsMergeThread两个线程分别对内存和磁盘上的文件进行合并。

接下来,我们将详细剖析每个阶段的内部实现细节
(1)准备运行完成的MapTask列表
TaskTracker启动了MapEventsFetcherThread线程。该线程会周期性(周期性为心跳时间间隔)通过RPC从JobTracker上获取已经运行完成的MapTask列表,并保存到TaskCompletionEvent类型列表allMapEvents中。
而对于ReduceTask而言,它会启动GetMapEventsThread线程。该线程周期性通过RPC从TaskTracker上获取已运行完成的MapTask列表,并将成功运行完成的MapTask放到列表mapLocations中。
为了避免出现数据访问热点(大量进程集中读取某个TaskTracker上的数据),ReduceTask不会直接将列表mapLocations中的Map Task输出数据位置交给MapOutputCopier线程,而是事先进行一次预处理:将所有TaskTracker Host进行混洗操作(随机打乱顺序),然后保存到scheduledCopies列表中,而OutputCopier线程将从该列表中获取待拷贝的MapTask输出数据位置。需要注意的是,对于一个TaskTracker而言,曾拷贝失败的MapTask将优先获得拷贝机会。
(2)远程拷贝数据
Reduce Task同时启动mapred.reduce.parallel.copies(默认是5)个数据拷贝线程MapOutputCopier。该线程从scheduledCopies列表中获取MapTask数据输出描述对象,并利用HTTP Get从对应的Task Tracker远程拷贝数据,如果数据分片大小超过一定阈值,则将数据临时写到工作目录下,否则直接保存到内存中。不管是保存到内存中还是磁盘上,MapOutputCopier均会保存一个MapOutput对象描述数据的元信息。如果数据被保存到内存中,则将该对象添加到列表mapOutputsFilsInMemory中,否则将该对象保存到列表mapOutputFilesOnDisk中。
在Reduce Task中,大部分内存用于缓存从MapTask端拷贝的数据分片,这些内存占到JVM Max Heap Size(由参数-Xmx指定)的mapred.job.shuffle.input.buffer.percent(默认是0.70)倍,并由类ShuffleRamManager管理。Reduce Task规定,如果一个数据分片大小未超过该内存的0.25倍,则可存放到内存中。如果MapOutputCopier线程要拷贝的数据分片可存放到内存中,则它先要向ShuffleRamManager申请相应的内存,待同意后才会正式拷贝数据,否则需要等待它释放内存。
由于远程拷贝数据可能需要跨网络读取多个节点上的数据,期间很容易由于网络或者磁盘等原因造成读取失败,因此提供良好的容错机制是非常必要的。当出现拷贝错误时,ReduceTask提供了以下几个容错机制:
1、如果拷贝数据出错次数超过abortFailureLimit,则杀死该ReduceTask(等待调度器重新调度执行),其中,abortFailureLimit计算方法如下:
abortFailureLimit = max{30,numMaps/10}
2、如果拷贝数据出错次数超过maxFetchFailuresBeforeReporting(可通过参数mapreduce.reduce.shuffle.maxfetchfailures设置,默认是10),则进行一些必要的检查,以绝对是否杀死该Reduce Task
3、如果前两个条件均不满足,则采用对数回归模型推迟一段时间后重新拷贝对应MapTask的输出数据,其中延迟时间delayTime的计算方法如下:
delayTime =10000*1.3的noFailedFetches次方,其中noFailedFetches为拷贝错误次数。
(3)合并内存文件和磁盘文件
前面提到,ReduceTask从MapTask端拷贝的数据,可能保存到内存或者磁盘上。随着拷贝数据的增多,内存或者磁盘上的文件数目也必将增加,为了减少文件数目,在数据拷贝过程中,线程LocalFSMerger和InMemFSMergeThread将分别对内存和磁盘上的文件进行合并。
对于磁盘上文件,当文件数目超过(2*ioSortFactor-1)后(ioSortFactor值由参数io.sort.factor指定,默认是10),线程LocalFSMerger会从列表mapOutputFilesOnDisk中取出最小的ioSortFactor个文件进行合并,并将合并后的文件再次写到磁盘上。
对于内存中的文件,当满足以下几个条件之一时InMemFSMergeThread线程会将内存中所有数据合并后写到磁盘上:
1、所有数据拷贝完毕后,关闭ShuffleRamManager
2、ShuffleRamManager中已使用内存超过可用内存的mapred.job.shuffle.merge.percent(默认是66%)倍且内存文件数目超过2个。
3、内存中的文件数目超过mapred.inmem.merge.threshold(默认是1000)。
4、阻塞在ShuffleRamManager上的请求数目超过拷贝线程数目mapred.reduce.parallel.copies的75%
2、Sort和Reduce阶段分析
当所有数据拷贝完成后,数据可能存放在内存中或者磁盘上,此时还不能将数据直接交给用户编写的reduce()函数处理。根据MapReduce语义,ReduceTask需将key值相同的数据聚集到一起,并按组将数据交给reduce()函数处理。为此,Hadoop采用了基于排序的数据聚集策略。前面提到,各个Map Task已经事先对自己的输出分片进行了局部排序,因此,Reduce Task只需进行一次归并排序即可保证数据整体有序。为了提高效率,Hadoop将Sort阶段和Reduce阶段并行化。在Sort阶段,Reduce Task为内存和磁盘中的文件建立了小顶堆,保存了指向该小顶堆根节点的迭代器,且该迭代器保证了以下两个约束条件:
1、磁盘上文件数目小于io.sort.factor(默认是10)。
2、当Reduce阶段开始时,内存中数据量小于最大可用内存(JVM Max Heap Size)的mapred.job.reduce.input.buffer.percent(默认是0)。
在Reduce阶段,Reduce Task不断地移动迭代器,以将key 相同的数据顺次交给reduce()函数处理,期间移动迭代器的过程实际上就是不断调整小顶堆的过程,这样,Sort和Reduce可并行进行。















 545
545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









