









正好手上有这些资料。可以提供一些思路。
本文章为技术贴,讨论如何使用人工智能机器学习统计数据并进行分析,无任何导向。请大家理性看待。请多多支持公益事业。
以下是我采集的2024年全年的3D球的数据,包括每期的销售总额和三个数字。
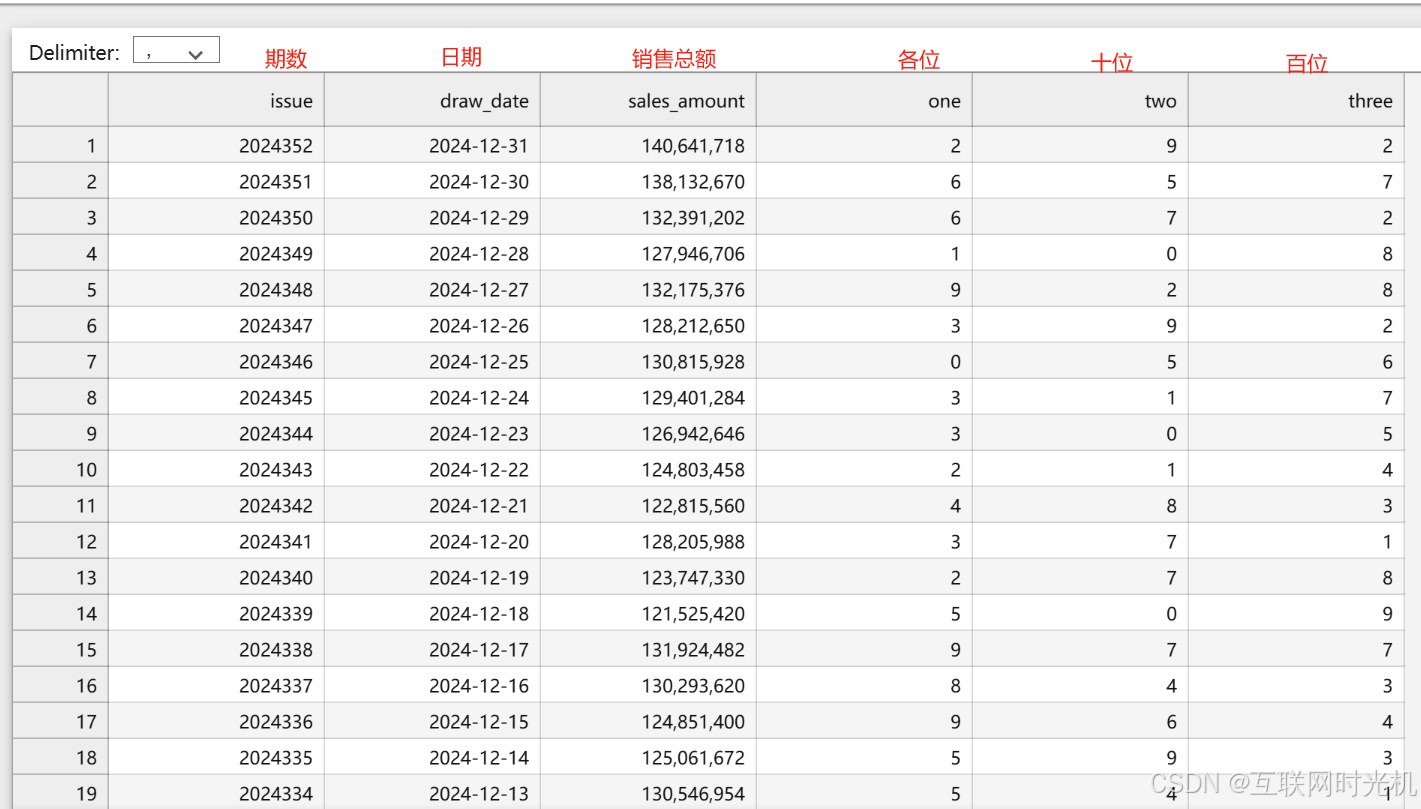
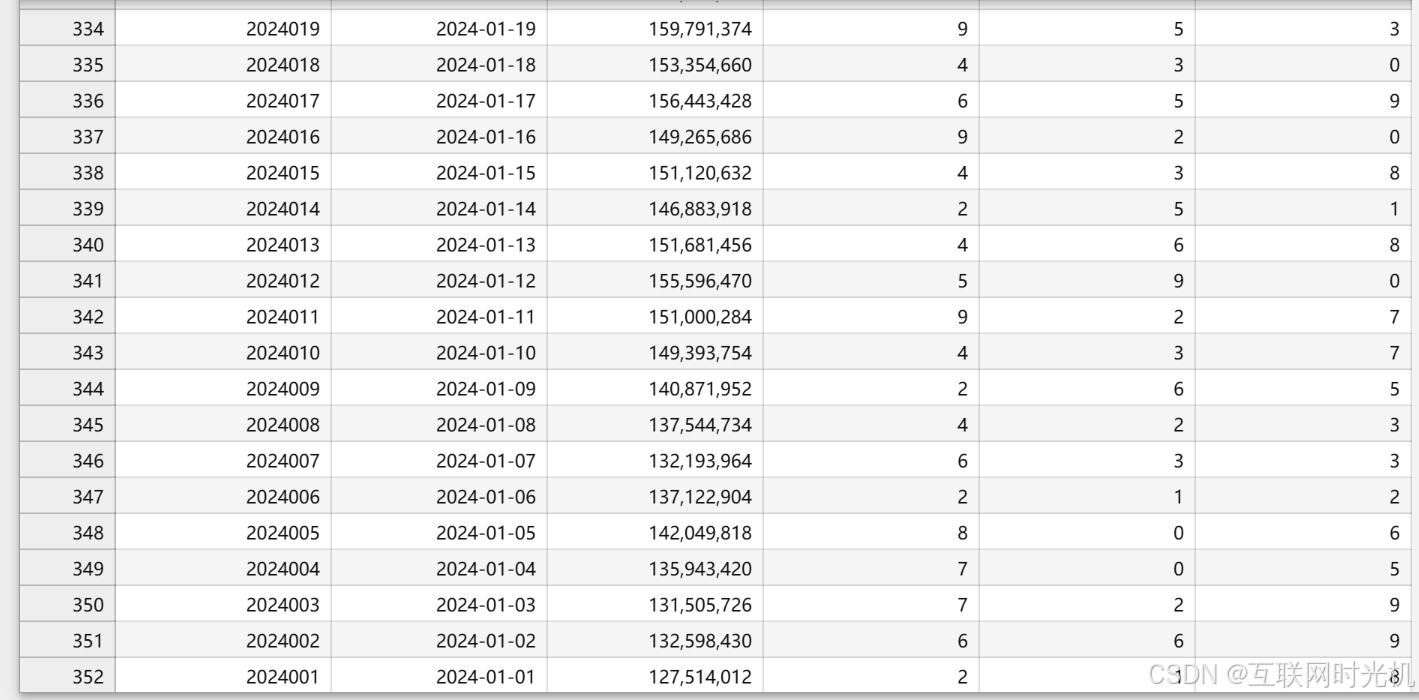
2024年一共是352期。
接下来,我们使用Python代码分析一下规律。
代码如下:
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.family']='simhei'
df = pd.read_csv('3d_2024.csv')
# 转换 draw_date 为日期格式
df['draw_date'] = pd.to_datetime(df['draw_date'])
# display(df)
# 设置图形大小
plt.figure(figsize=(12, 80)) # 你可以根据需要调整大小
# 创建每个数字的趋势图
# 绘制 One 的趋势图
plt.subplot(1, 3, 1) # 1行3列的第1个子图
plt.plot(df['one'], df.index + 1, marker='o',c='r') # 将Y轴的索引放大1.5倍
plt.title('数字 百 的趋势') # 中文标题
plt.xlabel('数字') # 中文 x 轴标题
plt.ylabel('期数') # 中文 y 轴标题
plt.xticks(range(10)) # 设置 x 轴刻度为 0-9
plt.yticks(df.index + 1, df['draw_date'].dt.strftime('%Y-%m-%d')) # 设置 y 轴为开奖日期
# 在点上方显示数字
for i in range(len(df)):
plt.text(df['one'][i], df.index[i] + 1.1, str(df['one'][i]), ha='center', va='bottom')
# 绘制 Two 的趋势图
plt.subplot(1, 3, 2) # 1行3列的第2个子图
plt.plot(df['two'], df.index + 1, marker='o',c='g') # 将Y轴的索引放大1.5倍
plt.title('数字 十 的趋势') # 中文标题
plt.xlabel('数字') # 中文 x 轴标题
plt.ylabel('期数') # 中文 y 轴标题
plt.xticks(range(10)) # 设置 x 轴刻度为 0-9
plt.yticks(df.index + 1, df['draw_date'].dt.strftime('%Y-%m-%d')) # 设置 y 轴为开奖日期
# 在点上方显示数字
for i in range(len(df)):
plt.text(df['two'][i], df.index[i] + 1.1, str(df['two'][i]), ha='center', va='bottom')
# 绘制 Three 的趋势图
plt.subplot(1, 3, 3) # 1行3列的第3个子图
plt.plot(df['three'], df.index + 1, marker='o') # 将Y轴的索引放大
plt.title('数字 个 的趋势') # 中文标题
plt.xlabel('数字') # 中文 x 轴标题
plt.ylabel('期数') # 中文 y 轴标题
plt.xticks(range(10)) # 设置 x 轴刻度为 0-9
plt.yticks(df.index + 1, df['draw_date'].dt.strftime('%Y-%m-%d')) # 设置 y 轴为开奖日期
# 在点上方显示数字
for i in range(len(df)):
plt.text(df['three'][i], df.index[i] + 1.1, str(df['three'][i]), ha='center', va='bottom')
plt.tight_layout() # 自动调整子图间距
# 保存图片到指定路径
plt.savefig('3D走势图.png')
plt.show() # 显示图形
运行代码

看这个蛇形走位,看起来有规律吗?
就算全宇宙最牛逼的算法和算力也无法发现他的规律吧。
2 统计规律
我们通过这352期的数字,找到个十百位的回归曲线。
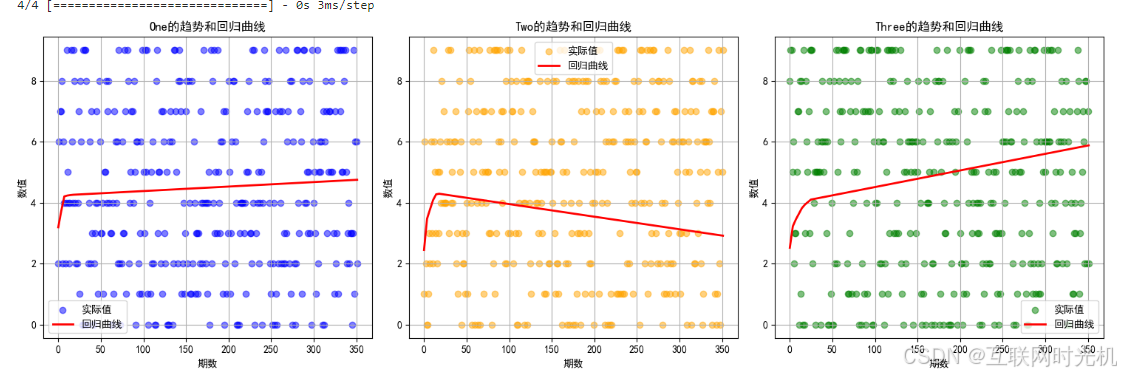
根据数字分布图,可以发现,这条线就基本就是直线了,并且就着4,5,6之间的直线。
并且你会发现,如果统计2004-2024年这10年的数据,这条曲线基本就会变成数字5左右的直线了。
数据量越大,越没有规律了。
不过,我们可以试一下,看看是否可以预测。
3 根据条件预测
预测的前提条件是这样的。
根据2024年的历史规律总结,寻找当上一期出现的某个数字之后,下一期会出现什么数字。
例如:2024351期,2024-12-30,出现的数字是6,5,7,使用代码总结一下,当百位出现6的时候,下一期最多会出现什么数字,当十位出现5时,下一期最多会出现什么数字,当个位出现7时,个位会出现什么数字。
接下来,我们根据代码预测:
输入:第2025026期的结果5,8,8,预测下一期的号码
'''
@date 2024年11月20日
@author liandyao
dy号: liandyao
'''
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 创建 DataFrame
df = pd.read_csv('3d_2024.csv')
# 将数据按期号进行排序以确保顺序
df.sort_values(by='issue', inplace=True)
# 创建特征: 使用过去的值作为输入特征
# 假设有记录过去几期的数据
df['prev_one'] = df['one'].shift(1)
df['prev_two'] = df['two'].shift(1)
df['prev_three'] = df['three'].shift(1)
# 删除缺失值
df.dropna(inplace=True)
# 提取特征和目标
X = df[['prev_one', 'prev_two', 'prev_three']]
y_one = df['one']
y_two = df['two']
y_three = df['three']
# 数据分割
X_train, X_test, y_train_one, y_test_one = train_test_split(X, y_one, test_size=0.2, random_state=42)
X_train, X_test, y_train_two, y_test_two = train_test_split(X, y_two, test_size=0.2, random_state=42)
X_train, X_test, y_train_three, y_test_three = train_test_split(X, y_three, test_size=0.2, random_state=42)
# 构建和训练模型
model_one = RandomForestClassifier()
model_one.fit(X_train, y_train_one)
model_two = RandomForestClassifier()
model_two.fit(X_train, y_train_two)
model_three = RandomForestClassifier()
model_three.fit(X_train, y_train_three)
# 预测
y_pred_one = model_one.predict(X_test)
y_pred_two = model_two.predict(X_test)
y_pred_three = model_three.predict(X_test)
# 评估模型
accuracy_one = accuracy_score(y_test_one, y_pred_one)
accuracy_two = accuracy_score(y_test_two, y_pred_two)
accuracy_three = accuracy_score(y_test_three, y_pred_three)
print(f"模型 'one' 的准确率: {accuracy_one:.2f}")
print(f"模型 'two' 的准确率: {accuracy_two:.2f}")
print(f"模型 'three' 的准确率: {accuracy_three:.2f}")
# 输入预测值(最后一行数据,预测未来的值)
input_data = [[5,8,8]] # 使用数字进行预测
predicted_one = model_one.predict(input_data)
predicted_two = model_two.predict(input_data)
predicted_three = model_three.predict(input_data)
print(f"预测下一期的数字 'one' 是: {predicted_one[0]}")
print(f"预测下一期的数字 'two' 是: {predicted_two[0]}")
print(f"预测下一期的数字 'three' 是: {predicted_three[0]}")
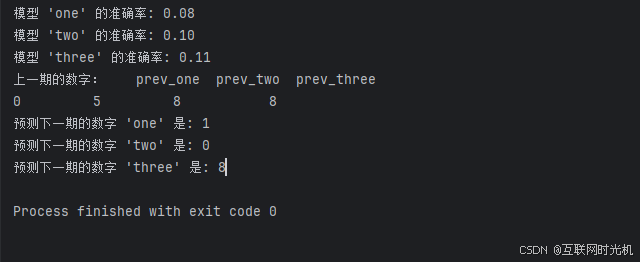
得到的结果:
模型 'one' 的准确率: 0.08
模型 'two' 的准确率: 0.10
模型 'three' 的准确率: 0.11
上一期的数字: prev_one prev_two prev_three
0 5 8 8
预测下一期的数字 'one' 是: 1
预测下一期的数字 'two' 是: 0
预测下一期的数字 'three' 是: 8
大家可以参考一下。
如果中奖了,别忘了回来感谢我,哈哈。


















 1872
1872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











