






前文连接:持续学习的综述: 理论、方法与应用(一)
摘要
为了应对现实世界的动态,智能系统需要在其整个生命周期中增量地获取、更新、积累和利用知识。这种能力被称为持续学习,为人工智能系统自适应发展提供了基础。从一般意义上讲,持续学习明显受到灾难性遗忘的限制,在这种情况下,学习一项新任务通常会导致旧任务的表现急剧下降。除此之外,近年来出现了越来越多的进步,这些进步在很大程度上扩展了对持续学习的理解和应用。对这一方向日益增长和广泛的兴趣表明了它的现实意义和复杂性。在这项工作中,我们提出了一个全面的持续学习调查,寻求桥梁的基本设置,理论基础,代表性的方法,和实际应用。基于现有的理论和实证结果,我们总结了持续学习的一般目标,即在资源效率的背景下确保适当的稳定性-可塑性权衡和足够的任务内/任务间泛化性。然后,我们提供了一个最先进的和详细的分类,广泛分析了代表性方法如何解决持续学习问题,以及它们如何适应现实应用中的特定挑战。通过对有前途的方向的深入讨论,我们相信这种整体的视角可以极大地促进该领域乃至其他领域的后续探索。
题目:A Comprehensive Survey of Continual Learning: Theory, Method and Application
作者:Liyuan Wang, Xingxing Zhang, Hang Su, Jun Zhu, Fellow, IEEE
机构:Tsinghua University
3 理论基础
在本节中,我们总结了关于持续学习的理论努力,包括稳定性-可塑性权衡和概括性分析,并将它们与各种持续学习方法的动机联系起来。
3.1 Stability-Plasticity权衡
根据2.1节的基本公式,让我们考虑一个持续学习的一般设置,其中一个参数为θ的神经网络需要学习k个增量任务。假设每个任务的训练集和测试集遵循相同的分布Dt, t = 1,…, k,其中训练集
D
t
=
{
X
t
,
Y
t
}
=
{
(
X
t
,
n
,
Y
t
,
n
)
}
n
=
1
N
t
D_t = \{X_t, Y_t\} = \{(X_{t,n}, Y_{t,n})\}_{n=1}^{N_t}
Dt={Xt,Yt}={(Xt,n,Yt,n)}n=1Nt包含Nt个数据标签对。目标是学习一个概率模型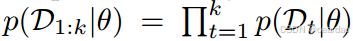
(假设条件独立),该模型可以很好地执行所有任务,表示为
D
1
:
k
:
=
D
1
,
…
,
D
k
D_{1:k}:= {D_1,…, D_k}
D1:k:=D1,…,Dk。判别模型的任务相关性能可以表示为
l
o
g
p
(
D
t
∣
θ
)
=
∑
n
=
1
N
t
l
o
g
p
θ
(
y
t
,
n
∣
x
t
,
n
)
log p(D_t|θ) = \sum_{n=1}^{N_t}log p_θ(y_{t,n}|x_{t,n})
logp(Dt∣θ)=∑n=1Ntlogpθ(yt,n∣xt,n)。持续学习的核心挑战通常来自于学习的顺序性:当从Dk学习第k个任务时,旧的训练集{D1,…、Dk−1}不可获取。因此,以一种平衡的方式捕捉新旧任务的分布至关重要,但却很困难,即确保适当的稳定性-可塑性权衡,过度的学习可塑性或记忆稳定性可能在很大程度上相互妥协(见图2,a, b)。
一个简单的想法是通过存储一些旧的训练样本或训练生成模型来近似和恢复旧的数据分布,这在第4.2节中被称为基于重播的方法。根据监督学习的学习理论[154],旧任务的性能可以通过重玩更多接近其分布的旧训练样本来提高,但会导致潜在的隐私问题和资源开销的线性增加。生成模型的使用也受到巨大的额外资源开销,以及它们自己灾难性的遗忘和表达能力的限制。
另一种选择是通过在贝叶斯框架中形成持续学习,在更新参数时传播旧数据分布。根据网络参数的先验p(θ),观察到第k个任务后的后验可以用贝叶斯规则计算:
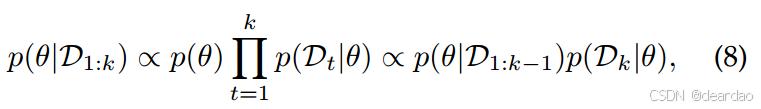
其中,第k-1个任务的后验
p
(
θ
∣
D
1
:
k
−
1
)
p(θ|D_{1:k−1})
p(θ∣D1:k−1)成为第k个任务的先验,从而使新的后验
p
(
θ
∣
D
1
:
k
)
p(θ|D_{1:k})
p(θ∣D1:k)可以仅用当前训练集Dk计算。然而,由于后验通常是难以处理的(除了非常特殊的情况),一个常见的选择是用
q
k
−
1
(
θ
)
≈
p
(
θ
∣
D
1
:
k
−
1
)
q_{k−1}(θ)\approx p(θ|D_{1:k−1})
qk−1(θ)≈p(θ∣D1:k−1)来近似它,同样地,对于
q
k
(
θ
)
≈
p
(
θ
∣
D
1
:
k
)
qk(θ)≈p(θ|D_{1:k})
qk(θ)≈p(θ∣D1:k)。下面,我们将介绍两种广泛使用的近似策略:
第一种是在线拉普拉斯近似,它将
p
(
θ
∣
D
1
:
k
−
1
)
p(θ|D_{1:k−1})
p(θ∣D1:k−1)近似为具有局部梯度信息的多元高斯函数[177],[202],[222],[371],[441]。具体来说,我们可以将
q
k
−
1
(
θ
)
q_{k−1}(θ)
qk−1(θ)参数化,并构造一个近似的高斯后验
q
k
−
1
(
θ
)
:
=
q
(
θ
;
ϕ
k
−
1
)
=
N
(
θ
;
µ
k
−
1
,
Λ
k
−
1
−
1
)
q_{k−1}(θ):= q(θ;ϕ_{k−1})= N(θ;µ_{k−1},Λ_{k−1}^{-1})
qk−1(θ):=q(θ;ϕk−1)=N(θ;µk−1,Λk−1−1),通过对
p
(
θ
∣
D
1
:
k
−
1
)
p(θ|D_{1:k−1})
p(θ∣D1:k−1)的模态
µ
k
−
1
∈
R
∣
θ
∣
µ_{k−1} \in R^{|θ|}
µk−1∈R∣θ∣进行二阶泰勒展开,其中
Λ
k
−
1
Λ_{k−1}
Λk−1表示精度矩阵,而
ϕ
k
−
1
=
{
µ
k
−
1
,
Λ
k
−
1
}
ϕ_{k−1} =\{µ_{k−1},Λ_{k−1}\}
ϕk−1={µk−1,Λk−1},同样地,对于
q
(
θ
;
ϕ
k
)
q(θ;ϕ_k)
q(θ;ϕk),
µ
k
µ_k
µk和
Λ
k
Λ_k
Λk。根据Eq.(8),学习当前第k个任务的后验模式可计算为
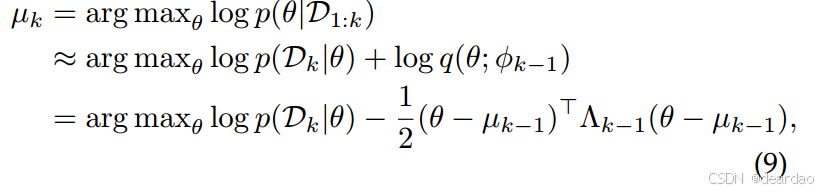
从
µ
k
−
1
和
µ_{k−1}和
µk−1和Λ_{k−1}
递归更新。同时,
递归更新。同时,
递归更新。同时,Λ_k
从
从
从Λ_{k−1}$递归更新:
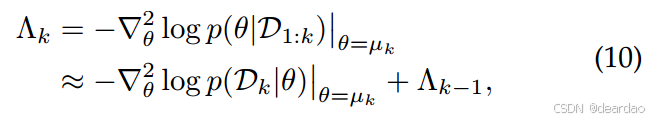
其中右边的第一项是Dk在µk处的负对数似然的Hessian,记为H(Dk,µk)。在实际应用中,由于
R
∣
θ
∣
R^{|θ|}
R∣θ∣的维数很大,H(Dk,µk)的计算效率往往很低,并且不能保证近似的Λk对于高斯假设是正的半定。为了克服这些问题,通常用Fisher信息矩阵(FIM)来近似Hessian:
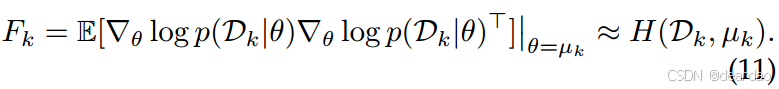
为了便于计算,FIM可以通过对角线近似[177]、[222]或kroneckerfactor近似[293]、[371]进一步简化。然后,通过保存旧模型的冻结副本
µ
k
−
1
µ_{k−1}
µk−1来正则化参数变化来实现Eq.(9),即第4.1节中基于正则化的方法。这里以EWC[222]为例,给出其损失函数:
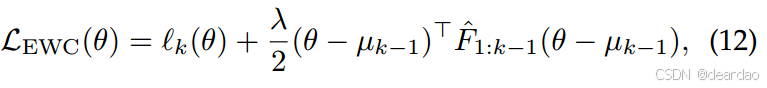
其中, l k l_k lk表示任务特定的损失,FIM F ^ 1 : k − 1 = ∑ t = 1 k − 1 d i a g ( F t ) \hat{F}_{1:k−1} =\sum_{t=1}^{k-1} diag(F_t) F^1:k−1=∑t=1k−1diag(Ft),每个Ft的对角近似diag(·),λ是控制正则化强度的超参数。
二是在线变分推理(VI)[7]、[91]、[206]、[235]、[248]、[280]、[318]、[378]、[410]。有许多不同的方法可以做到这一点,有代表性的一种方法是在当前第k个任务上最小化满足
p
(
θ
∣
D
1
:
k
)
∈
Q
p(θ|D_{1:k})∈Q
p(θ∣D1:k)∈Q的族Q上的以下kl散度:
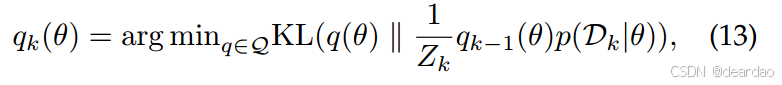
式中Zk为
q
k
−
1
(
θ
)
p
(
D
k
∣
θ
)
q_{k−1}(θ)p(D_k|θ)
qk−1(θ)p(Dk∣θ)的归一化常数。在实践中,可以通过使用一个附加的蒙特卡罗近似来实现上述最小化进行逼近,满足
q
k
(
θ
)
:
=
q
(
θ
;
ϕ
k
)
=
N
(
θ
;
µ
k
,
Λ
k
−
1
)
q_k(θ):= q(θ;ϕ_k) = N (θ;µ_k,Λ_k^{-1})
qk(θ):=q(θ;ϕk)=N(θ;µk,Λk−1)作为多元高斯分布。这里我们以VCL[318]为例,哪个最小化了下面的目标(即最大化它的负数):
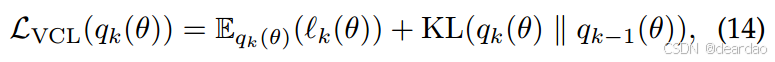
其中KL-散度可以以封闭形式计算,并作为隐式正则化项。特别是,虽然Eq.(12)和Eq.(14)的损失函数形式相似,但前者是一组确定性参数θ的局部近似,而后者是通过从变分分布
q
k
(
θ
)
q_k(θ)
qk(θ)中抽样计算得到的。这归因于两种近似策略之间的根本差异[318],[420],在特定设置下的性能略有不同。
除了参数空间外,序列贝叶斯推理的思想也适用于函数空间[326],[378],[417],它往往使参数更新更灵活。此外,VI还有许多其他扩展,例如用变分自回归高斯过程(VAR-GPs)改进后测更新[206],构建任务特定参数[7],[232],[244],[280],以及适应非平稳数据流[235]。
本质上,对持续学习的约束,无论是重播还是正则化,最终都反映在梯度方向上。因此,最近的一些工作直接操纵了基于梯度的优化过程,在第4.3节中被归类为基于优化的方法。具体来说,当任务t的一些旧训练样本Mt保存在内存缓冲区中时,鼓励新训练样本的梯度方向与Mt的梯度方向保持接近[66],[281],[411]。它的表达式为 ⟨ ∇ θ L k ( θ ; D k ) , ∇ θ L k ( θ ; M t ) ⟩ ≥ 0 ⟨∇_θL_k(θ;D_k),∇_θL_k(θ;M_t)⟩≥0 ⟨∇θLk(θ;Dk),∇θLk(θ;Mt)⟩≥0,对于t∈{1,…, k−1},从而从本质上保证旧任务的损失不增加,即 L k ( θ ; M t ) ≤ L k ( θ k − 1 ; M t ) L_k(θ;M_t)≤L_k(θ_{k−1};M_t) Lk(θ;Mt)≤Lk(θk−1;Mt),其中 θ k − 1 θ_{k−1} θk−1为学习第(k-1)个任务结束时的网络参数。
或者,也可以在不存储旧训练样本的情况下进行梯度投影[65]、[115]、[146]、[202]、[227]、[258]、[266]、[333]、[380]、[448]、[496]。这里我们以NCL[202]为例,它在在线拉普拉斯近似中使用
µ
k
−
1
µ_{k−1}
µk−1和
Λ
k
−
1
Λ_{k−1}
Λk−1来操纵梯度方向。如Eq.(15)所示,NCL通过在以θ为中心的半径为r的区域内,以距离度量
d
(
θ
,
θ
+
δ
)
=
δ
T
Λ
k
−
1
δ
/
2
d(θ, θ + δ) = \sqrt{δ^TΛ_{k−1}δ/2}
d(θ,θ+δ)=δTΛk−1δ/2最小化任务特定的损失
l
k
(
θ
)
l_k(θ)
lk(θ)来进行持续学习,该区域通过精度矩阵
Λ
k
−
1
Λ_{k−1}
Λk−1考虑先验的曲率:
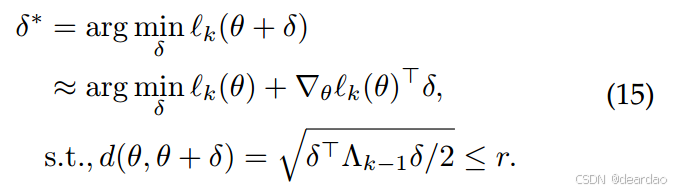
Eq.(15)中这类优化问题的解由
δ
∗
∝
Λ
k
−
1
−
1
∇
θ
l
k
(
θ
)
−
(
θ
−
µ
k
−
1
)
δ∗∝Λ_{k−1}^{-1}∇θl_k(θ)−(θ−µ_{k−1})
δ∗∝Λk−1−1∇θlk(θ)−(θ−µk−1)给出,由此得出学习率Λ的更新规则如下:
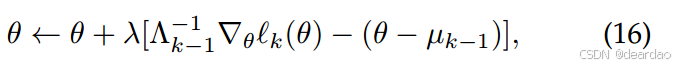
其中,第一项通过预条件
Λ
k
−
1
−
1
Λ_{k−1}^{-1}
Λk−1−1鼓励参数主要在不干扰旧任务的方向上变化,而第二项强制θ保持接近旧的任务解
µ
k
−
1
µ_{k−1}
µk−1。
值得注意的是,上述分析主要是基于寻找所有增量任务的共享解决方案,这些增量任务会受到严重的任务间干扰[361],[441],[443]。相比之下,增量任务也可以以(部分)分离的方式学习,这是第4.5节中基于体系结构的方法的主要思想。这可以表示为构造一个参数为
θ
=
∪
t
=
1
k
θ
(
t
)
θ =∪_{t=1}^kθ^{(t)}
θ=∪t=1kθ(t)的连续学习模型,其中
θ
(
t
)
=
{
e
(
t
)
,
ψ
}
θ^{(t)} = \{e^{(t)}, ψ\}
θ(t)={e(t),ψ},
e
(
t
)
e^{(t)}
e(t)是任务特定/自适应参数,ψ是任务共享参数。在某些情况下,任务共享参数ψ被省略,其中任务特定参数
e
(
i
)
e^{(i)}
e(i)和
e
(
j
)
e^{(j)}
e(j) (i < j)可能重叠,以实现参数重用和知识传递。重叠部分
e
(
i
)
e^{(i)}
e(i)∩
e
(
j
)
e^{(j)}
e(j)在学习第j个任务时被冻结,以避免灾难性遗忘[379],[384]。然后,如果给定任务标识
I
D
t
I_{D_t}
IDt,则每个任务可以以
p
(
D
t
∣
θ
(
t
)
)
p(D_t|θ(t))
p(Dt∣θ(t))而不是
p
(
D
t
∣
θ
)
p(D_t|θ)
p(Dt∣θ)执行,其中任务之间的冲突被显式控制,如果省略ψ甚至可以避免:
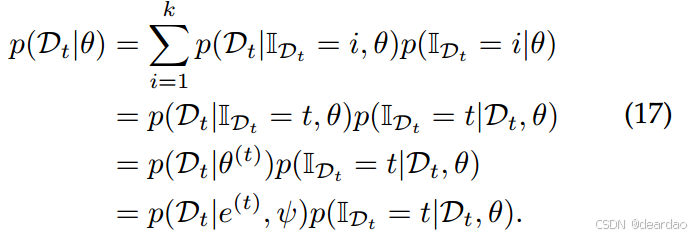
然而,有两个主要的挑战。第一个是由于
θ
(
t
)
θ^{(t)}
θ(t)的逐步分配而导致的模型大小的可扩展性,这取决于
e
(
t
)
e^{(t)}
e(t)的稀疏性、
e
(
i
)
e^{(i)}
e(i)∩
e
(
j
)
e^{(j)}
e(j)(i < j)的可重用性和ψ的可转移性。二是任务同一性预测的准确度,记为
p
(
I
D
t
=
t
∣
D
t
,
θ
)
p(I_{D_t} = t|D_t, θ)
p(IDt=t∣Dt,θ)。除了TIL设置总是提供任务标识
I
D
t
I_{D_t}
IDt[108]、[117]、[379]、[384]外,其他场景一般都要求模型根据输入数据决定使用哪一个θ(t),如式(17)所示。这与分布外(out- distribution, OOD)检测密切相关,其中分布内数据的预测不确定性应该较低,而分布外数据的预测不确定性应该较高[83],[161],[218]。更重要的是,由于任务同一性预测的功能如Eq.(18)(相当于任务分类)需要不断更新,它也遭受灾难性遗忘。为了解决这个问题,第i个任务的分布
p
(
D
t
∣
i
,
θ
)
p(D_t|i, θ)
p(Dt∣i,θ)可以通过合并重播来恢复[139],[161],[223],[244]:
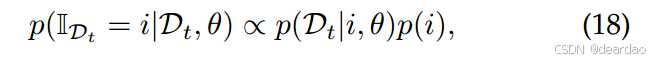
式中边际任务分布在一般情况下
p
(
i
)
∝
N
i
p(i)∝N_i
p(i)∝Ni。
关注微信公众号,获取更多资讯内容:


















 3555
3555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









